
 起点课堂会员权益
起点课堂会员权益RAG 落地手记一:知识入库这一步,决定了问答效果的上限
RAG技术看似链路清晰,实则暗藏玄机。当文档解析错位、切片切断语义、召回偏离重点时,再强大的模型也无法给出准确答案。本文将深入拆解RAG落地过程中最容易被忽视的前置环节,揭示知识工程如何决定AI问答系统的成败,带你看懂从混乱文档到精准答案的关键跃迁。

很多人第一次接触 RAG,会觉得它的链路很清楚:上传文档、切片、向量化、检索、再让大模型生成答案。
这条链路没有错,但真正落地时,问题往往不出在“大模型会不会回答”,而是出在更前面:文档有没有被正确解析,知识有没有被合理切分,正确内容有没有被召回。
我后来慢慢意识到,RAG 的第一步不是向量化,而是先判断这些知识能不能被系统正确理解。
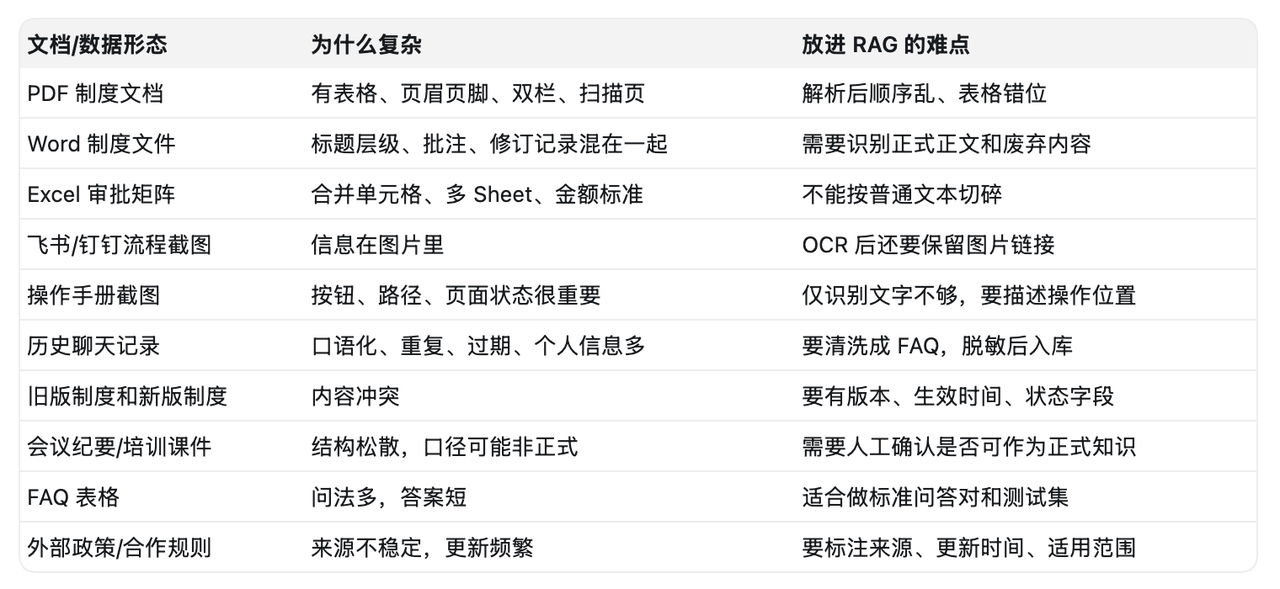
真正进入知识库的,也不只是几份规整的 PDF。更多时候,它们是制度 Word、Excel 审批表、飞书/钉钉流程截图、历史问答、培训课件、旧版文件和聊天记录的混合体。
所以,RAG 落地的第一个判断,不是“我选哪个大模型”,而是“这些资料经过处理后,还能不能保留原本的业务含义”。
一、文档解析错,后面全白做
文档解析是最容易被低估的一步。
比如一份差旅报销标准表,原本是很清楚的几列:城市级别、住宿上限、交通标准、发票要求。人看一眼就懂,但如果用普通 PDF 文本提取工具,可能会被解析成一串混在一起的文字。
城市、金额、规则、备注全挤在一行里。这样的内容一旦进入向量库,后面的 Embedding、检索、Rerank 再怎么调,也很难救回来。
原因也不复杂。很多通用 PDF 工具更擅长“抽文字”,但不擅长理解复杂版面。表格、双栏、页眉页脚、扫描件、印章、水印,都会让系统把原本有结构的信息读乱。
这一步我更倾向于按资料类型分开处理:

这里有一个很关键的原则:不要急着把所有内容都变成普通文本。
有些内容本来就是表格,就应该保留表格结构;有些内容本来就是截图,就应该保留图片 URL;有些流程图只靠 OCR 识别文字不够,还需要补充“这张图表达了什么”。
对于金额、比例、审批权限、合同条款这类高风险内容,解析后也不能直接入库。我一般会把它们标成“需业务确认”的知识,交给财务、HR、运营或法务确认口径后再入库。RAG 不是替业务部门解释制度,而是把已经确认过的知识更稳定地交付给用户。

图注:基于知识问答场景抽象的模拟结果,用于说明问题定位思路。
二、文本切片错,答案就断了
文档解析之后,下一步是切片,也就是把长文档拆成一个个 chunk。
很多系统默认会按固定字数切,比如 500 字一段、800 字一段。这个方法简单,但在制度、流程、审批规则这类场景里,很容易把一个完整规则切断。
举个例子,一条年假制度可能包含三部分:

如果按固定长度切,可能第一段只有适用范围,第二段才是年假天数,第三段是申请流程。用户问“年假有几天”,系统只召回第一段,就会出现回答不完整的问题。
这不是模型没理解,而是它拿到的上下文本来就缺了一块。
所以我现在更认可“语义切片”的思路:一个 chunk 最好能回答一个完整问题。
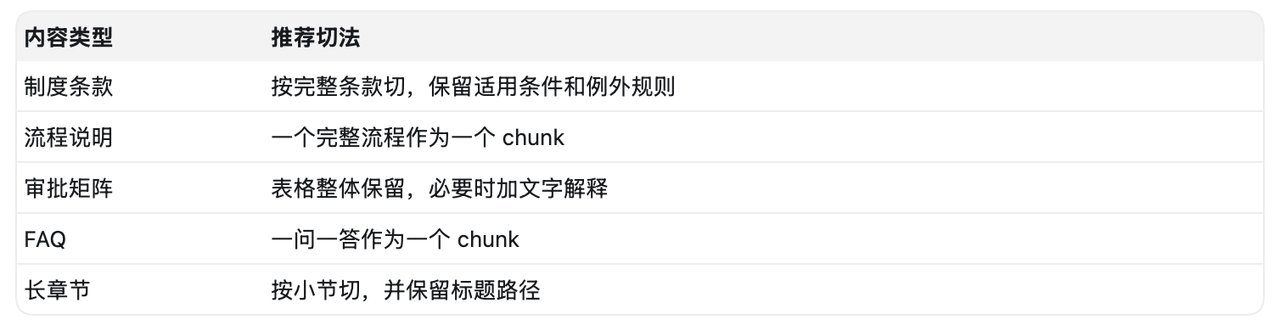
比如“年假规则”这个 chunk,不一定要很长,但至少要保留:适用范围、工龄天数、申请方式、来源章节。这样用户问的时候,系统召回到这一段,就能直接支撑一个完整答案。
当然,语义切片并不是没有成本。它比固定字数切分更贵,贵的不是“切分”这个动作本身,而是它需要系统理解文档结构和业务含义,并且会牵动后续的向量化、检索、重排和生成链路。
所以我更倾向于按价值分层处理:高频、高价值、高风险的内容,比如报销标准、审批矩阵、代理商分润规则、合同条款,值得精细切;普通说明类文档可以先用规则切分,再通过后续 BadCase 慢慢优化。
尤其是涉及金额、假期天数、分润比例、处罚规则的 chunk,不能只看技术切得是否完整,还要看业务口径是否准确。必要时需要让制度 owner 或相关部门确认:这个 chunk 能不能独立作为答案依据。
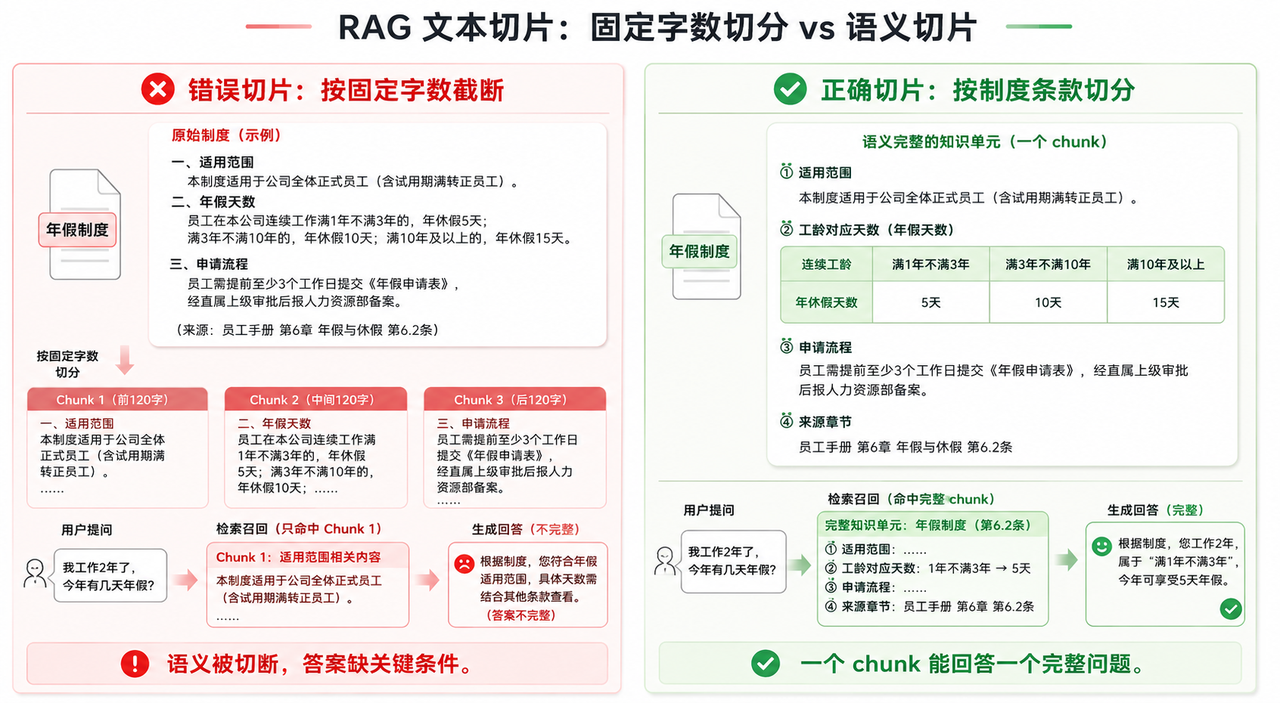
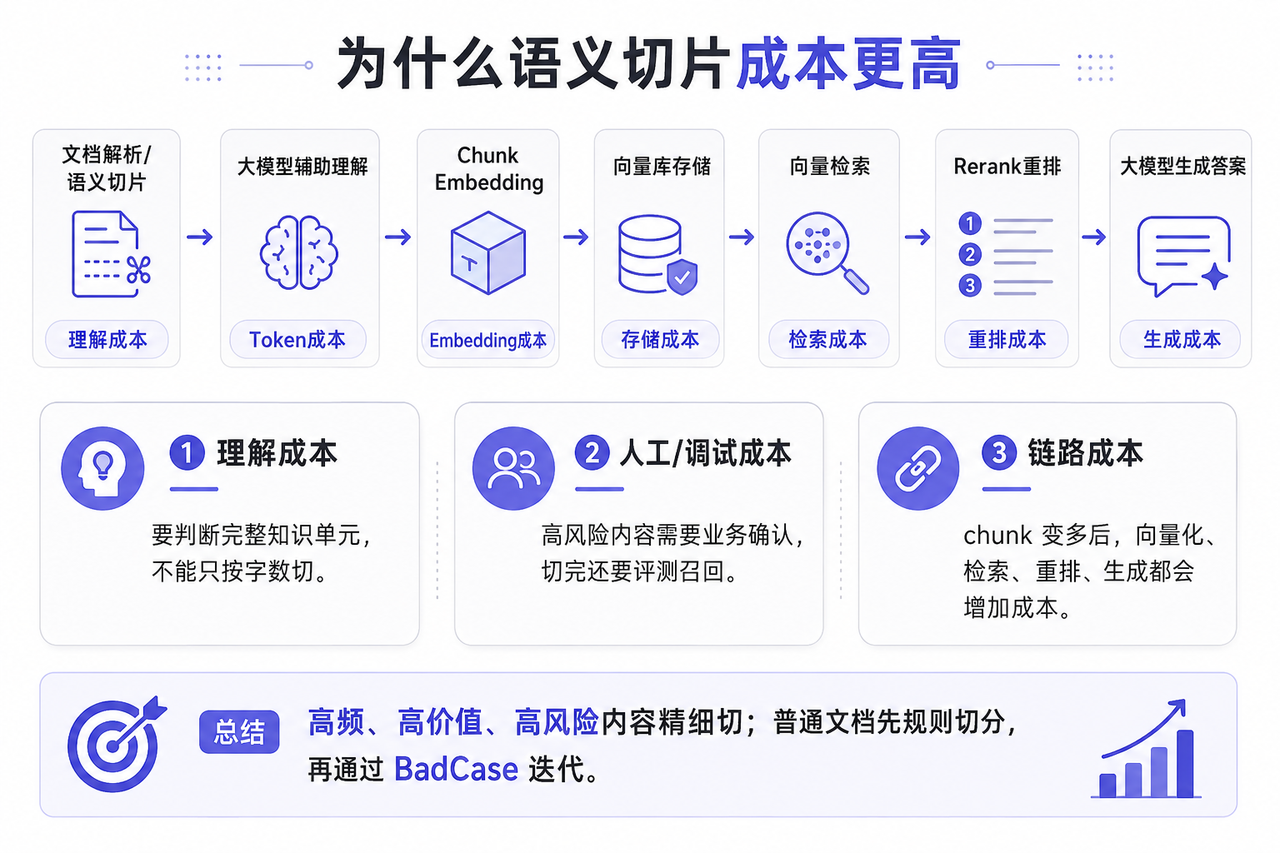
图注:以下为基于知识问答场景抽象的模拟结果,用于说明问题定位思路。
三、正确答案在库里,但没有被召回
很多 RAG 问题最让人困惑的地方在于:资料明明在知识库里,系统就是答不出来。
这时不能只看最终答案,要往前看召回结果。
这里有一个常见参数:similarity_top_k。如果翻成中文,可以理解为“初步召回数量”。
用户问一个问题时,系统会先从知识库里找出最相似的前 K 条内容。比如 K=3,就是只拿最相似的 3 条;K=10,就是先拿 10 条候选内容。
问题在于,正确答案不一定总排在前 3。
比如用户问:
忘记打卡怎么办?
文档里真正相关的内容可能叫:
考勤异常补卡申请流程
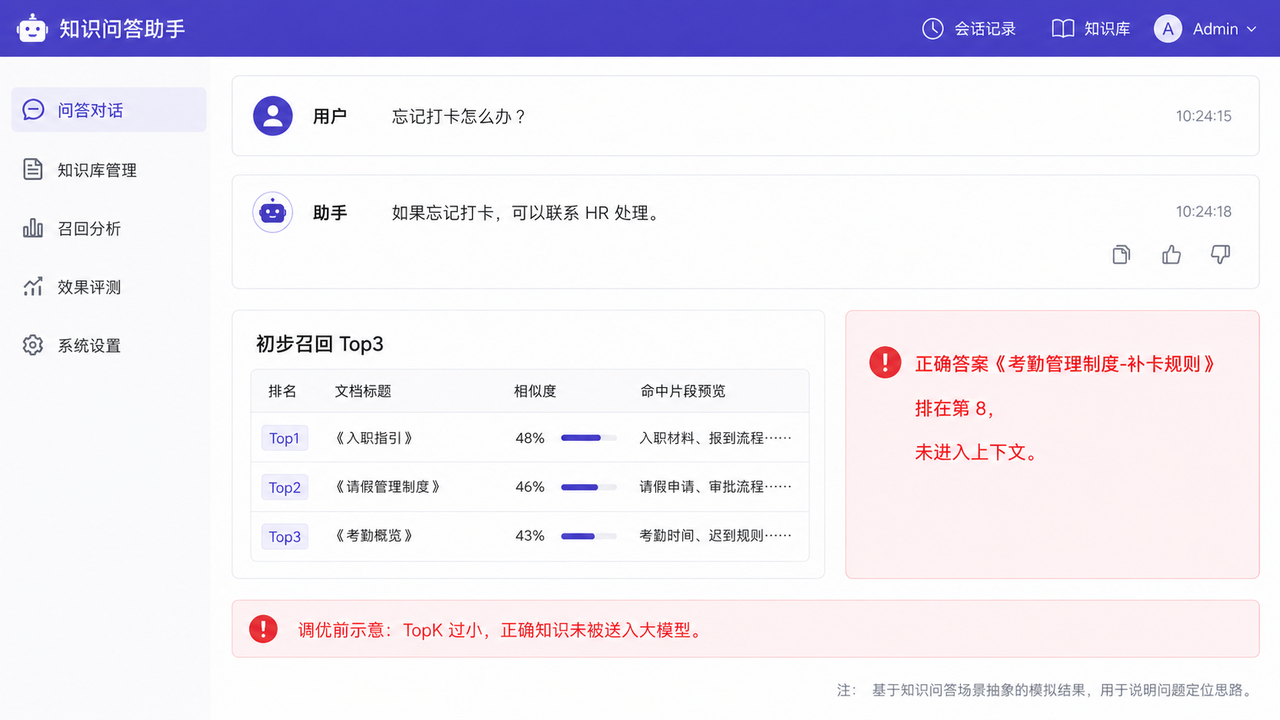
用户说的是口语,文档写的是制度语言。如果只召回 Top3,系统可能拿到的是《入职指引》《请假管理制度》《考勤概览》,而真正的《考勤管理制度-补卡规则》排在第 8。
这时大模型根本没有看到正确资料,后面自然答不准。
解决思路通常不是单点调一个参数,而是组合处理:
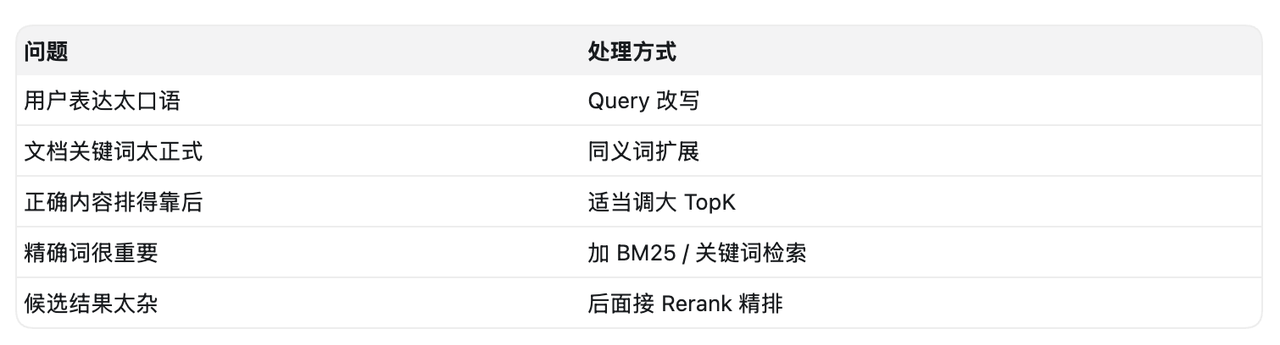
所以,similarity_top_k 不是越大越好,也不是越小越好。它本质上是在“别漏掉正确答案”和“别引入太多噪音”之间找平衡。
四、召回多了,还要 Rerank 精排
如果把 TopK 调大,就能解决所有问题吗?也不是。
初步召回数量变多以后,正确答案更容易进入候选集,但无关内容也会一起进来。直接把一堆候选内容全部塞给大模型,模型反而可能抓错重点。
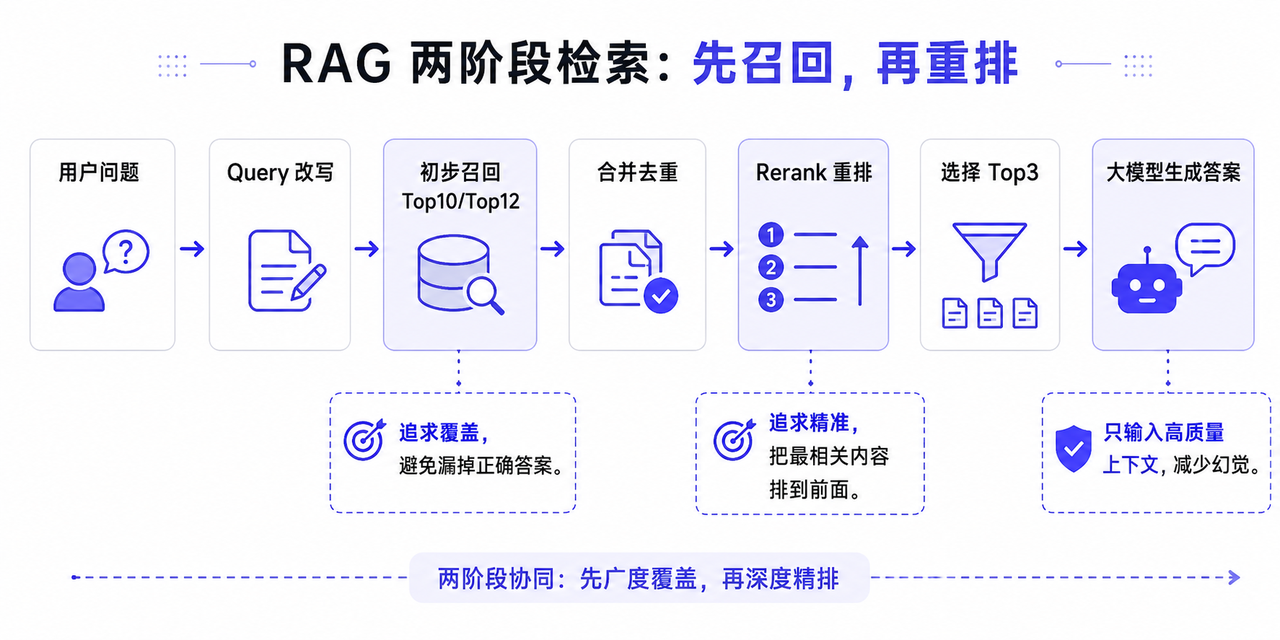
所以更稳的方式是两阶段检索:
第一阶段,召回追求“别漏”。
第二阶段,Rerank 追求“排准”。
可以理解成:

还是“忘记打卡怎么办”这个问题。
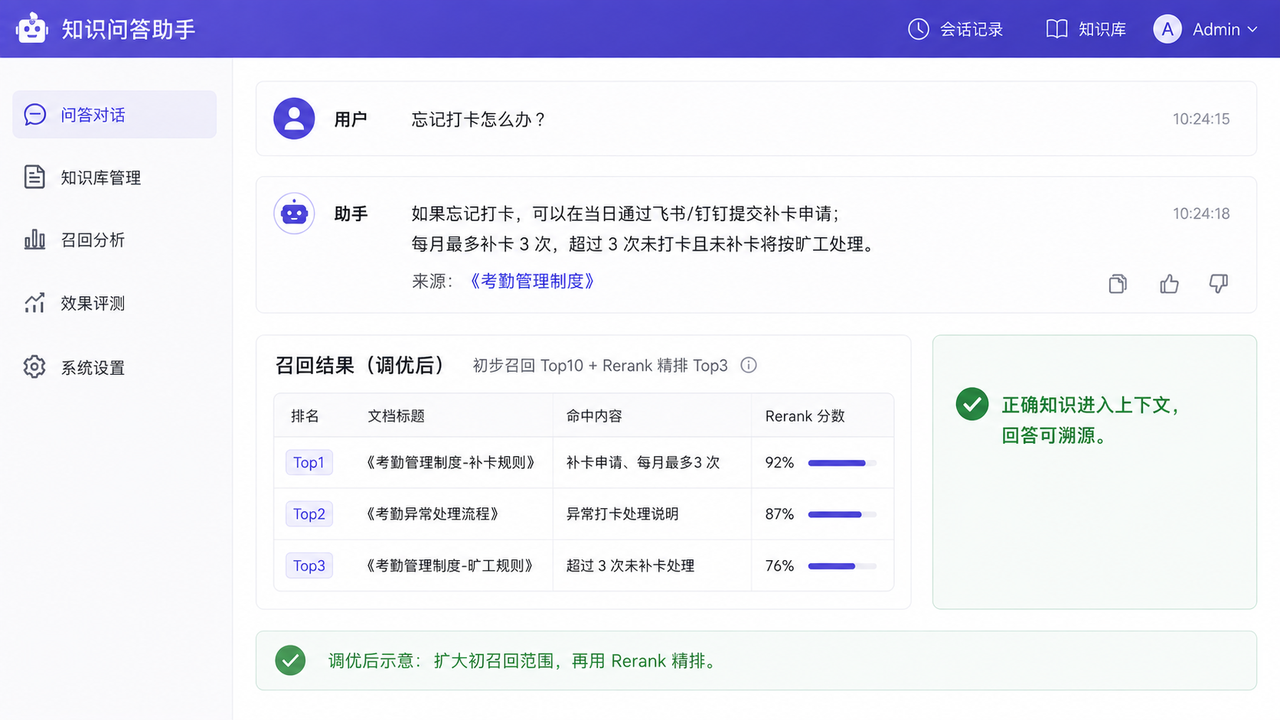
调优前,系统可能只拿到 3 条不够相关的内容。
调优后,可以先召回 10 条,再通过 Rerank 把《考勤管理制度-补卡规则》排到第一,只把最相关的 3 条交给大模型。
这样做的好处是:召回阶段不轻易漏掉答案,生成阶段也不会被太多噪音干扰。
图注:以下为基于知识问答场景抽象的模拟结果,用于说明问题定位思路。
图注:基于场景抽象的复盘图,用于说明 RAG 检索调优思路。
五、用户说人话,文档说制度话
还有一类问题也很常见:用户的表达方式和文档里的表达方式不一致。
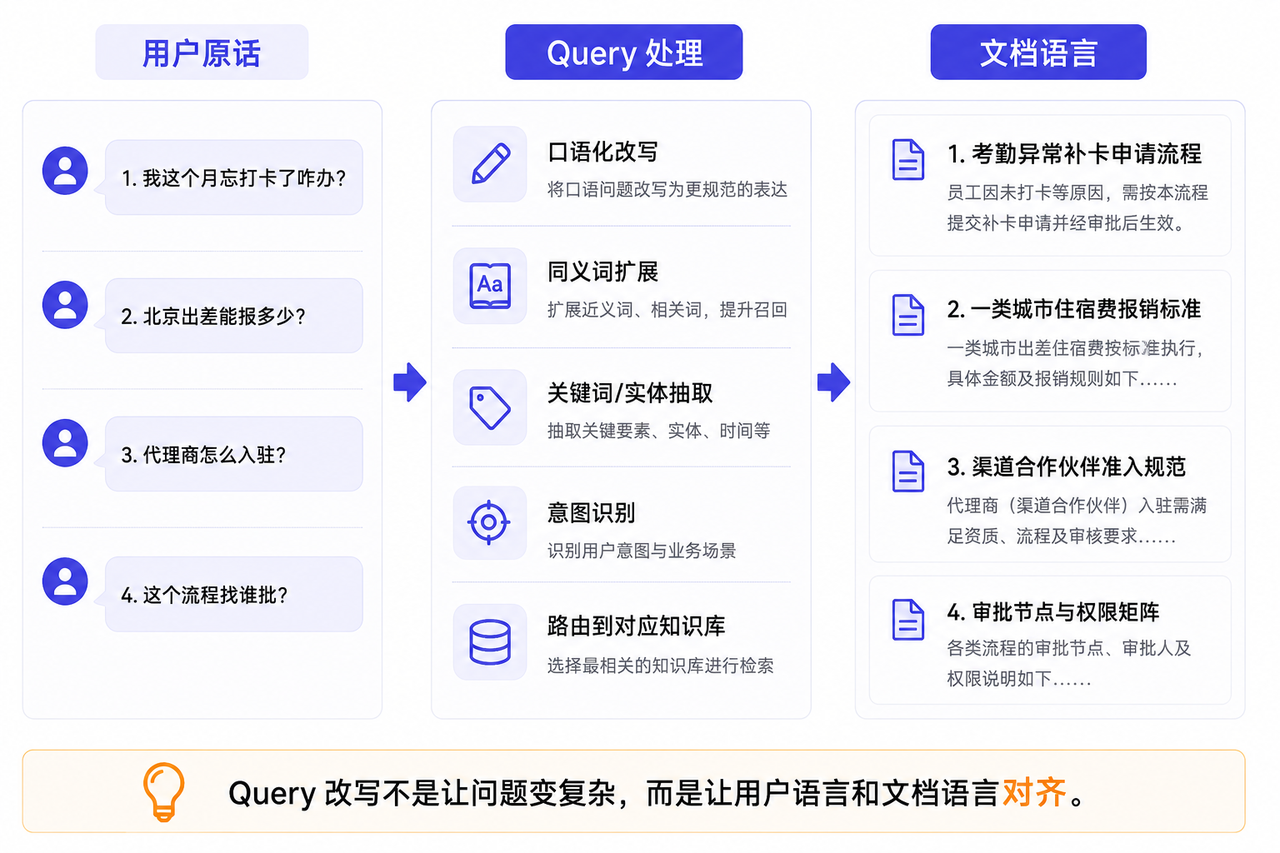
这就是典型的“用户语言”和“文档语言”不一致。
这时可以在检索前加一层 Query 处理,把用户的口语问题改写成更适合检索的问题。

Query 改写不是为了让问题变复杂,而是为了让系统更容易找到正确资料。
在一些更复杂的场景里,还可以做实体抽取。比如从用户问题里识别出地点、制度类型、金额、角色、动作,再决定去哪个知识库、用什么检索方式。
这一步看起来不起眼,但很实用。因为 RAG 的问题往往不是“知识不存在”,而是“用户问法和知识写法没有对齐”。
结尾:RAG 前半段的本质是知识工程
RAG 的效果,不是从大模型开始决定的。
很多时候,答案不准不是模型不聪明,而是它拿到的上下文本来就不对:文档解析错了,表格结构丢了,切片切断了,正确资料没召回,或者召回了一堆噪音内容。
所以我后来更愿意把 RAG 的前半段叫做“知识工程”。
先把知识处理成系统能理解、能检索、能追溯的形态,再谈模型生成,才有意义。
如果说大模型决定了回答的表达能力,那么知识入库这一步,决定了它能不能站在正确的资料上回答。
这也是我觉得 RAG 落地最容易被低估、但最值得花时间打磨的一步。
本文由 @肥源 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


