
 起点课堂会员权益
起点课堂会员权益如何通俗地理解 RAG?
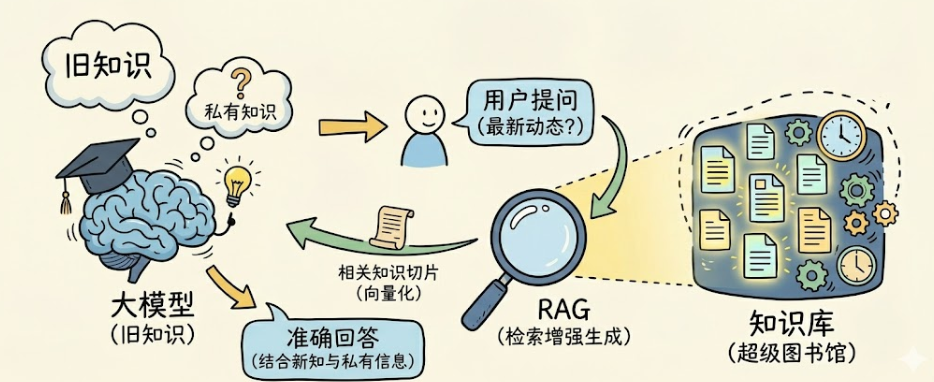
RAG(检索增强生成)是大模型解决‘知识滞后’与‘私有数据缺失’两大痛点的关键外挂。其核心逻辑是将企业私有文档‘切片’并转化为‘向量’存储于外部知识库;当用户提问时,系统先通过向量相似度检索出最相关的知识片段,再将其作为上下文‘喂’给大模型。
作为当前最热门的大模型应用技术之一,RAG 几乎是现在各种大模型应用的标配。特别是如果你做 AI 产品经理,工作中或多或少都会碰见它。那么,我们到底该怎么通俗地理解 RAG 呢?
我们先从大模型本身的原理聊起。
大家都知道现在的模型越来越牛了,像最近大家常讨论的 Claude Opus 4.6、GPT 5.2、Gemini 3.1 pro 以及国内的 GLM 5 等,能力极其强大。
但归根结底,它们强大的基础是基于「海量数据训练」。模型从全网大量数据中学习规律和知识,然后把这些规律和知识转化为数字(也就是我们常说的「参数」)存储下来。当你提问时,它再根据这些学过的规律和知识来生成回答。
但从这个原理来看,大模型有两个天然的弱点:
知识更新永远慢半拍。 从抓取数据到训练完毕再到上线,中间往往有几个月的真空期。也就是说,当我们能使用大模型时,也就是大模型上线时,它具备的知识和规律往往是几个月前的。你要问它当下的最新动态,它是不知道的。
缺乏私有化领域的知识。 大模型学习的是公网数据,它根本接触不到企业内部的私有数据或是你个人的专属知识。
简单总结就是:大模型能力虽强,但信息更新不及时,且没有你的私有知识。
为了解决这些问题,RAG 登场了。
RAG 的英文全称是 Retrieval Augmented Generation,直接翻译过来叫「检索增强生成」。它本质上是大模型的一种应用技术,是专门为大模型打辅助的。
它的核心原理很简单:既然大模型没这部分知识,那我们就先建一个外部的「知识库」。当用户提问时,系统先去知识库里把相关的知识「检索」出来,然后把相关知识给到大模型,让大模型结合这些现成知识来作答。这就叫用检索现成知识来增强大模型的生成能力。
OK,接下来我们详细拆解一下 RAG 的原理。
第一步:处理数据与知识切片
首先,我们得搞定知识库。通常我们需要把企业内部的 PDF、Word 文档或者网页等资料收集起来,然后构建知识库。
你可能会想,直接把这些资料一股脑全塞给大模型不就行了吗?还真不行。一方面,大模型每次能接收的上下文长度是有限制的,没法一次接收太多资料,即便能接收,也会因为token过多导致成本更高;另一方面,如果给的信息太长且无关内容太多,大模型也会抓不住重点,回答质量就会变差。
所以,「切片」技术应运而生。简单来说,我们不是把一整篇长文档直接扔进去,而是像切蛋糕一样,把它切成一小块一小块的「知识切片」,我们只挑选跟用户问题「最相关」的那一小块给大模型。
第二步:向量化与检索
那么问题来了,怎么在海量切片里找到最相关的呢?这时候我们要用到数学里的「向量」概念。
在不考虑长度的情况下,两个向量的夹角越小,两个向量越相似。而两个向量夹角越小,则夹角的余弦值越大。所以,我们可以用向量夹角的余弦值来表示两个向量之间的相似程度。余弦值越大,则两个向量越相似。
基于这个原理,我们可以把知识切片转化为向量,把用户问题也转化为向量,然后计算每个知识切片向量与这个用户问题向量夹角的余弦值。然后,我们找到余弦值最大的知识切片,这个就是与用户问题最相关的知识切片。
第三步:构建提示词与生成回答
拿到了最相关的知识切片后,我们并不是直接把它扔给用户,而是把用户的问题和检索到的知识切片组合在一起,给到大模型。大模型的提示词(Prompt)可以这么构建:「请你根据我提供给你的【知识库资料】,来回答用户的【问题】。注意,请不要编造不存在的事实,如果资料里没提,请直接回答不知道。」
这样,结合这些相关的知识切片,大模型就能很好地回答用户问题,从而避免幻觉。
总而言之,RAG 就像是给大模型外挂了一个可以随时更新、随时查阅的超级图书馆。
这就是对于 RAG 的通俗理解啦!
本文由人人都是产品经理作者【产品经理伯庸】,微信公众号:【AI文如刀】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。









比较通俗易懂