
 起点课堂会员权益
起点课堂会员权益qwen3-0.6B这种小模型有什么实际意义和用途吗?
在大模型喧嚣的背后,小模型正在工业场景中悄然崛起。从端侧部署的隐私计算到RAG系统的智能路由,0.6B级别的微型AI用极致性价比证明了'小即是美'的硬道理。本文将揭示小模型在5大实战场景中如何以低延迟、低成本和高可控性,完成大模型难以企及的'脏活累活'。

很多人觉得只有千亿参数、万亿参数才叫人工智能,只有能通过图灵测试才叫生产力。
在真实的落地业务中,在你看不见的机房深处、边缘网关,甚至是你手里的安卓机内,那些不起眼的小模型,正干着最脏最累、却也最具性价比的活儿。
这类模型不应被视为通用对话的替代品,其核心定位在于特定的工程流水线。在以下五个关键领域中,小模型凭借低延迟、低成本和高可控性,展现出了大模型无法比拟的实际意义。
一、端侧部署与隐私计算的基石
这是最直观的痛点。现在满大街都在喊AI Phone,但现实是手机内存才多大?8G、12G,顶天了16G(这也是为什么iPhone要去提升自己运行内存 (RAM),从8g提升到12g)。跑一个7B或8B的模型,就算你用4-bit量化,光加载权重就得吃掉4G到5G显存(手机上还是统一内存),再加上KV Cache的消耗,推理一旦跑起来,原神卡爆,微信卡死
相比之下,0.6B级别的模型经量化后,体积仅为数百兆,加载至内存几乎无感知。这为极致的本地化与低延迟提供了可能。
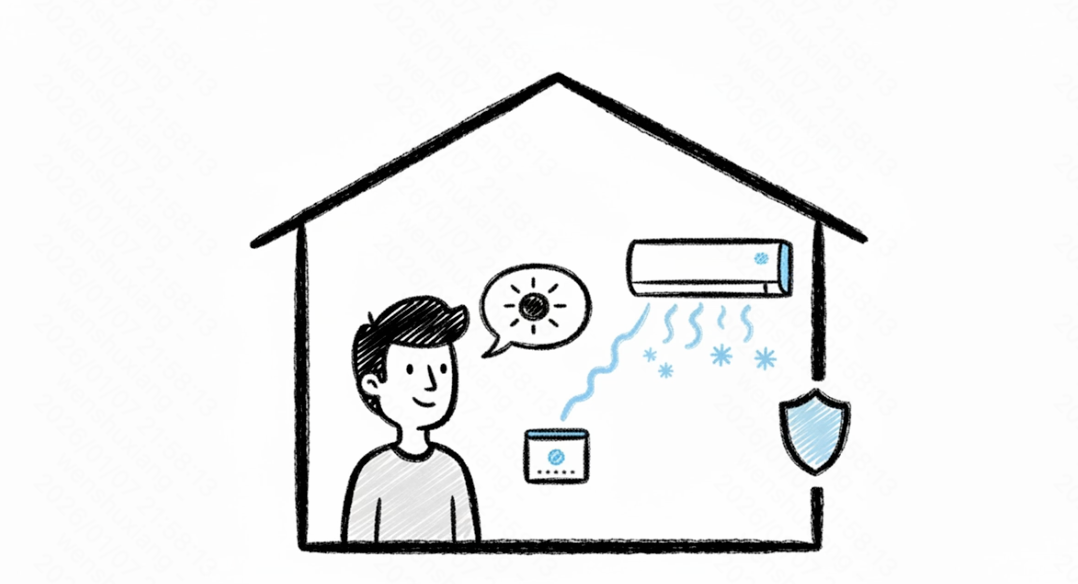
在智能家居中控的实际场景中,通过本地部署微调后的小模型,可专门用于语义意图识别。例如,将用户模糊的口语“我觉得热了”即时解析为“调低空调温度”的指令。由于无需上传云端,不仅规避了网络延迟,更彻底解决了用户隐私数据泄露的风险。
二、投机采样(Speculative Decoding)的推理加速
这是大厂给超大模型提速的“秘密武器”。
Transformer架构的串行生成机制导致了推理速度受限于内存带宽。怎么破?0.6B小模型登场。这招叫Speculative Decoding(投机采样)。
该技术的逻辑在于“协作”:利用0.6B小模型作为“草稿模型”,快速生成后续Token的预测序列(快速猜词);随后由大模型(如70B)进行并行的验证与修正。由于小模型在语法结构和高频词汇上的预测准确率极高,这种协作模式能显著减少大模型的计算次数。

三、RAG系统中的“路由器”与“清洁工”
在检索增强生成(RAG)系统中,无差别地调用昂贵的大模型处理所有请求,是资源管理的极大浪费。小模型在此场景下可担任高效的语义路由器(Semantic Router)。
在接入层,微调后的小模型可快速将用户Query分类:闲聊类直接回复,攻击类拦截,仅将复杂的专业问题转发至大模型。这不仅降低了API调用成本,更大幅减少了系统平均响应时间。
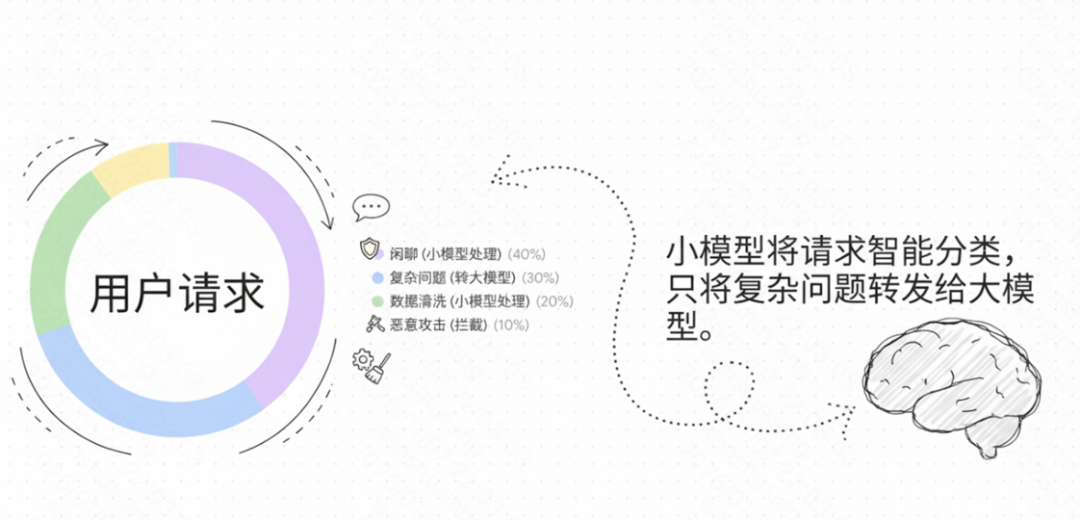
此外,在数据清洗环节,面对包含大量HTML标签或噪声的原始数据,小模型具备基础的阅读理解能力,能比正则表达式更精准、比大模型更经济地提取正文。
四、垂类微调与数据质量验证
小模型是极低成本的数据探针(用来在训练前测试训练集or测试集)。
在训练大模型前,先利用0.6B模型对数据集进行试跑。如果小模型的Loss下降规律且具备泛化性,则证明数据质量可靠;反之则说明数据存在缺陷。这种方法避免了直接在大模型上试错带来的高昂算力和时间成本。
同时,在特定窄领域任务上,专用优于通用。例如在Text-to-SQL任务中,经过全量微调的0.5B模型,其准确率往往优于未微调的8B通用模型。
五、合成数据(Synthetic Data)的规模化生产
随着高质量自然文本的枯竭,合成数据成为未来的趋势。利用最强模型(如Claude Opus/gemini)生成少量高质量“种子数据”,再利用小模型进行批量扩充,是目前的主流方案。
通过结合Outlines等工具,可以对0.6B模型的输出施加严格的结构化约束(如JSON 格式)。这使得小模型能够充当高效的数据结构化工厂,从非结构化文本中批量提取实体或改写文本风格,既保证了数据的多样性,又控制了生产成本。
总结
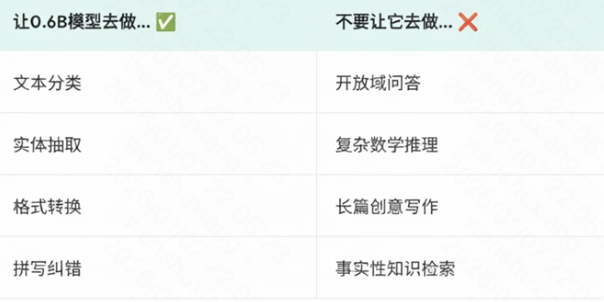
0.6B的知识是匮乏的,但语言能力(语法、断句、逻辑、格式化)是完备的。使用它的秘诀在于扬长避短:
- 别让它做:开放问答、复杂推理、长篇创作、事实检索。
- 让它做:文本分类、情感分析、实体抽取、格式转换、意图识别、纠错。
本文由 @卡萨丁AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


