
 起点课堂会员权益
起点课堂会员权益企业效率要变天!GPT-5.4深夜发布:不只是更聪明,是真能干活了!
OpenAI深夜突袭发布GPT-5.4,标志着AI进化史迎来关键拐点:从“最强问答者”正式跃迁为“原生电脑操控者”。此次升级的核心不在于学术基准的微小提升,而在于模型首次具备了看屏幕、点鼠标、敲键盘的全链路执行能力,在OSWorld等桌面操作测试中甚至超越了人类平均水平。
OpenAI深夜突袭,GPT-5.4正式登场。
和以往升级不同,这一次最引人注目的不是某个benchmark的小幅提升,而是一个关键能力的出现:
GPT-5.4成为OpenAI首个原生支持“电脑操控”的通用模型。
这意味着,AI会看屏幕、会点鼠标、会敲键盘,它正在从“最强回答器”加速进化成“真正能干活的数字员工”。
对企业来说,这是工作流自动化的又一次跃迁。
对打工人来说,更直接的问题只有一个:AI这次真的开始碰电脑了。
01 GPT-5.4:能干活的数字员工
OpenAI把GPT-5.4定义为“面向专业工作的最强模型”,并让它取代GPT-5.2 Thinking,成为 ChatGPT里的默认推理模型,同时还推出了更慢、更贵、算力更高的 GPT-5.4 Pro。
和OpenAI自家上一代相比,GPT-5.4的关键词不是“更聪明”,而是“更像一个能干活的执行层”。
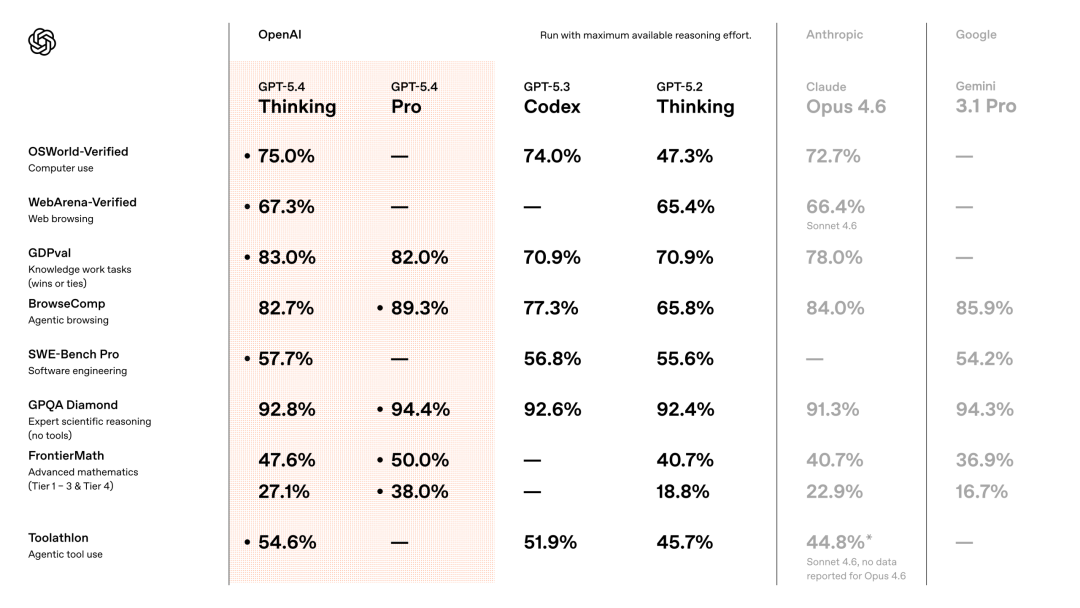
从公开数据看,GPT-5.4并没有在所有高难学术基准上对前代形成碾压。
真正拉开差距的是带工具、带环境、带工作流的任务,比如:OSWorld、BrowseComp、GDPval、Office/文档/表格类任务。
在OSWorld-Verified这类桌面操控测试里,GPT-5.4达到75.0%,高于GPT-5.2的47.3%,也略高于人类的72.4%。
再把GPT-5.3放进来,会看得更清楚:GPT-5.3-Codex在Terminal-Bench 2.0这种终端操作基准上做到77.3%,在SWE-Bench Pro做到56.8%;而GPT-5.4在Terminal-Bench 2.0上是75.1%,在SWE-Bench Pro是57.7%。
也就是说,OpenAI这次的优化方向,明显偏向专业场景的完成度。
GPT-5.4不只是比GPT-5.2更强,而是把GPT-5.3里分散出去的聊天、编码、代理能力,也重新收口到了主线旗舰。
有用户在社交媒体Reddit上发帖:“So far it’s more agentic for sure”,表示最直接的感受就是agentic感更强。
还有测试者在社交媒体X上说,拿自己常用benchmark去试,第一感觉是后端编码能力很强,表示“strong at backend coding”。
这表明,OpenAI终于把“会看界面、会点按钮、会写代码、会跨应用完成任务”的能力,从单独工具能力,推进到了主力通用模型层。
对企业来说,这会直接降低模型选型和流程编排的复杂度,自动化流程跑得更流畅了。
对于打工人来说,也不用再那么频繁地在“聊天模型、代码模型、深度推理模型”之间切来切去,工作流会更顺。
02 直逼竞争对手,综合完成度最高
如果把目前市面上最能打的大模型放在一起,GPT-5.4的表现如何呢?
第一条线是Anthropic Claude Opus 4.6。
它在agentic coding和computer use上仍然极强,Anthropic官方和第三方给出的成绩是Terminal-Bench 2.0达到65.4%,OSWorld达到 72.7%。
而OpenAI给GPT-5.4的公开成绩是Terminal-Bench 2.0为75.1%,OSWorld-Verified为75.0%。
如果接受双方各自公开结果,GPT-5.4目前在“终端操作+桌面操作”这组指标上略占上风。
虽然两家在得分上不相上下,但OpenAI正在往Anthropic擅长的Agent区域逼近,甚至开始反超,对于Anthropic来说是一个非常危险的信号。
第二条线是Google Gemini 3。
Google官方主打的是学术推理、长上下文、多模态和agentic coding。Gemini 3 Pro在一些整理表里,GPQA Diamond在91.9%左右,Humanity’s Last Exam(无工具)在37%–38%左右。
对比来看,GPT-5.4在GPQA 92.8%、HLE无工具约39.8%,在“普通旗舰模型”层面大致已经压过Gemini 3 Pro。但GPT-5.4最鲜明的优势并不是“考试分数碾压”,而是把专业工作、工具使用、电脑操控这几件事,做成了一个更完整的组合。
第三条线是 xAI Grok 4/ Grok 4 Heavy。
xAI更强调极限推理和考试型基准,比如在Humanity’s Last Exam上打到50%以上,把它包装成前沿学术推理能力的突破。
这个分数比GPT-5.4常规版在HLE上的40%左右明显高,也高于GPT-5.4 Pro在同一基准上的42%–43%区间。
Grok公布的重点依然是frontier intelligence,而不是“文档、表格、演示文稿、浏览器、桌面界面、工具系统”这一整套专业工作流闭环。
所以Grok更像“高天花板推理机”,GPT-5.4更像“高完成度工作机”。
总的来说,GPT-5.4不一定在每一项“考试题”上都是第一,但它在“把工作做完”这件事上,组合能力是最完整的。
如果企业真正想落地数字员工,GPT-5.4这类“综合完成度”的模型可能是更好的选择。
03 价格涨了,但定价逻辑变了
GPT-5.4虽好,但大家关注的还是它的价格。
GPT-5.4 API标准价,从GPT-5.2的$1.75/百万tokens、输出$14/百万tokens,涨到了$2.50/百万tokens、输出$15/百万tokens。GPT-5.3 Chat和GPT-5.3-Codex的价格暂时未变。
拿现在最流行的OpenClaw来计算,如果是“读一点上下文、调一次工具、给一段几百字总结”这样的轻度任务,一次的成本约为8美分(0.55元人民币)。
假设把OpenClaw当主力Agent 用,比如:连续多轮思考、调多个工具、读文件、再整理输出,一天100次,那么每天的花费约为$22.5(155元人民币),一个月下来可能要四、五千人民币。
总的来说,GPT-5.4更贵了,但相较于GPT-5.2 / 5.3这一代模型,它不只是更强,而是开始变得更像一个真正能接工作流的数字员工
OpenAI的逻辑很清楚,它卖的已经不是更便宜的聊天机器人,而是更贵、也更能干活的生产力机器。只要单位任务完成率、token效率和人工接管次数下降,企业会接受更贵的模型。
对市场来说,真正重要的从来不是发布会上的高分和漂亮口号。GPT-5.4能不能落地,还要看企业试点和真实工作流里的表现。
但至少从这次发布来看,OpenAI已经不满足于做最强聊天模型,而是在押注下一代企业生产力入口。
本文由人人都是产品经理作者【AI新智能】,微信公众号:【世界模型工场】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


