
 起点课堂会员权益
起点课堂会员权益医疗AI数据的标注困境:谁来充当“老师”?
医疗AI正面临一场前所未有的‘开蒙’困境。当顶级医学专家的智慧成为训练AI的唯一‘燃料’,标注一张CT影像的成本堪比主任医师会诊费,行业如何突破专家资源稀缺、标注周期漫长、意见分歧巨大的‘三座大山’?本文从医学影像迷雾、病理切片天书到RLHF专家反馈机制,深度拆解医疗AI最难攻克的‘数据死结’,并带来产品经理视角的破局之道。

引言:AI的“开蒙”难题与医学圣殿的门槛
在人工智能的发展长河中,数据被比作推动机器进化的“燃料”。然而,当通用人工智能(AGI)的浪潮席卷至医疗这一垂直领域时,人们赫然发现,简单的燃料堆砌已不足以驱动精密的手术刀。训练一个通用的视觉大模型,其过程类似于教导幼儿园小朋友辨认日常生活中的“猫”和“狗”。由于这些生物的视觉特征根植于人类数百万年的共同演化经验中,任何具备基本视觉能力的普通人都能胜任这一“教学”工作。这种“常识红利”使得通用数据的标注能够通过劳动密集型的“数据工厂”或众包平台快速实现规模化。
然而,训练一个医疗大模型或辅助诊断系统,其本质不再是常识的迁移,而是人类文明中最顶尖、最复杂的职业知识的转录。这一过程更像是带教一名医学院的研究生,甚至是在培养一名能够独立判断生死的临床主治医师。在这种语境下,机器的“老师”必须由具备深厚医学功底、丰富临床经验的专业人士——通常是主任医师或资深病理学家——亲自充当。
在当前“百模大战”的竞争格局下,算力可以通过购买高端GPU集群(如NVIDIA DGX系统)来解决,算法可以通过开源社区和顶尖人才的招募来优化,但高质量的、经过专家级认证的医疗“教材(标注数据)”却成了制约行业发展的战略性短缺资源 。这种高昂的“老师”成本,不仅体现在金钱的直接投入上,更体现在对极度稀缺的医疗智力资源的争夺上。究竟是谁,以及这种高不可攀的成本结构,是如何卡住医疗AI向深水区迈进的“脖子”的?本报告将从技术、经济、管理及行业趋势等多个维度,深度剖析这一医疗AI领域的核心痛点。
通识与专业的绝对鸿沟:为什么普通标注员在医疗领域全面失效
通用数据标注行业的繁荣建立在任务简单化的基础之上。在自动驾驶或社交媒体内容审核中,标注员每天的工作是在高对比度的图像中框选汽车、行人,或者根据语境判断一段话是否包含负面情绪。这种任务被称为“低认知门槛标注”,其特征是高共识性与高重复性。
放射影像中的视觉迷雾与认知盲区
进入医疗影像领域后,这种基于常识的标注逻辑瞬间崩塌。以胸部CT影像为例,一张包含数百个层面的断层扫描图像,对于普通人而言仅仅是灰度不同的黑白影调。在这些阴影中寻找一个早期的磨玻璃结节(GGO),其难度不亚于在一座巨大的森林中寻找一片特定的树叶。
磨玻璃结节通常表现为肺内局灶性密度增高影,其密度不足以掩盖其中的支气管影或血管影 。对于普通标注员,他们无法区分什么是正常的血管断面影,什么是由炎症引起的机化灶,什么是具有恶变倾向的早期腺癌 。真实案例研究显示,即使是受过初步培训的非专科人员,在处理复杂的胸部影像时,其误诊率和漏诊率高得惊人,根本无法产出可供AI学习的“正例”。
研究数据表明,即使在放射科专业人员内部,对于病变识别的一致性也受到病变类型的极大限制 。下表展示了在针对成年人胸部X光片(CXR)的诊断研究中,观察者间的一致性(Kappa系数)分布:
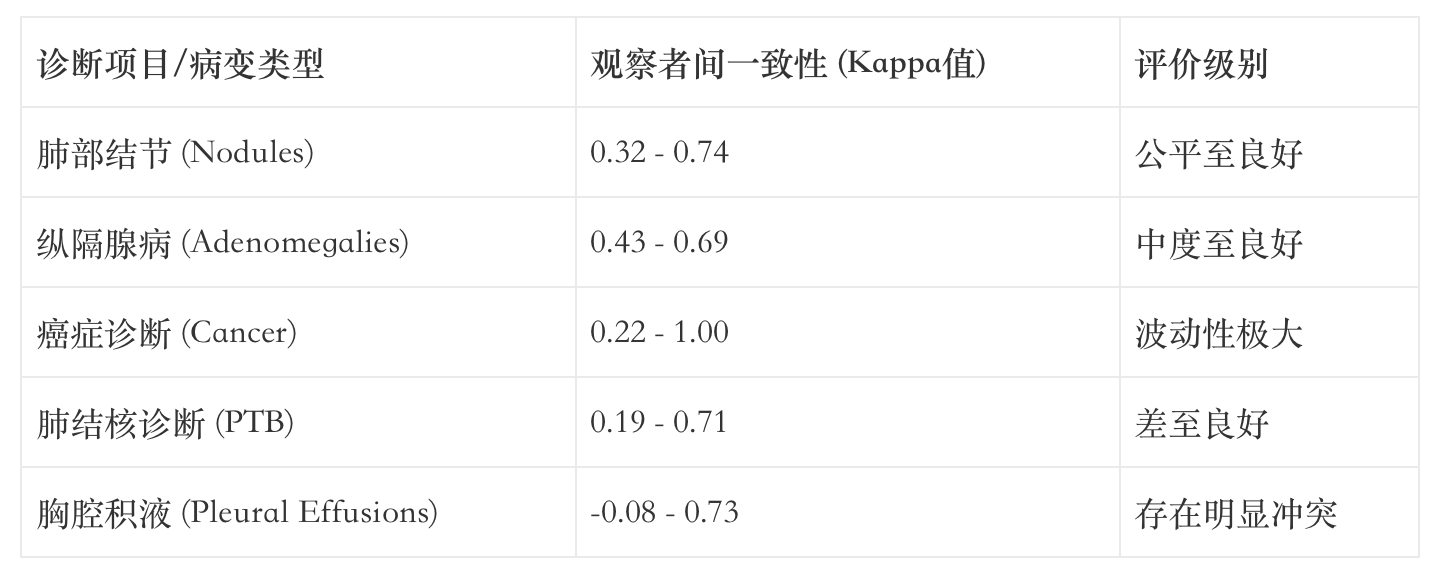
数据揭示了一个残酷的现实:普通标注员甚至无法达到Kappa系数0.0(随机水平)以上的稳定表现,其产出的标注结果在模型训练中被视为“纯噪声” 。AI面临着“无师可拜”的窘境,因为错误的数据输入只会导致错误的逻辑生成,即所谓的“垃圾进,垃圾出(Garbage In, Garbage Out)”。
病理切片的“天书”:微观世界的深渊
如果说放射影像还存在某些宏观结构可循,那么病理切片的标注则是对人类认知极限的挑战。一张全切片图像(WSI)的大小通常在几个GB到几十个GB之间,其分辨率之高,使得标注者可以观察到每一个细胞核的形态。
在细胞级别寻找癌细胞,不仅需要医学背景,更需要长时间的专科阅片训练。病理医生需要识别细胞核的异型性、核浆比、核分裂象以及组织结构的紊乱程度 。普通标注员面对数以万计的细胞,完全无法分辨什么是正常的炎症细胞浸润,什么是高度分化的肿瘤组织。此外,病理切片在制作过程中可能产生组织折叠、染色不均、刀痕等伪影,普通人极易将这些伪影误判为病理特征,从而给AI模型埋下致命的隐患 。
下表对比了通用图像标注与医疗病理标注在技术维度上的差异:
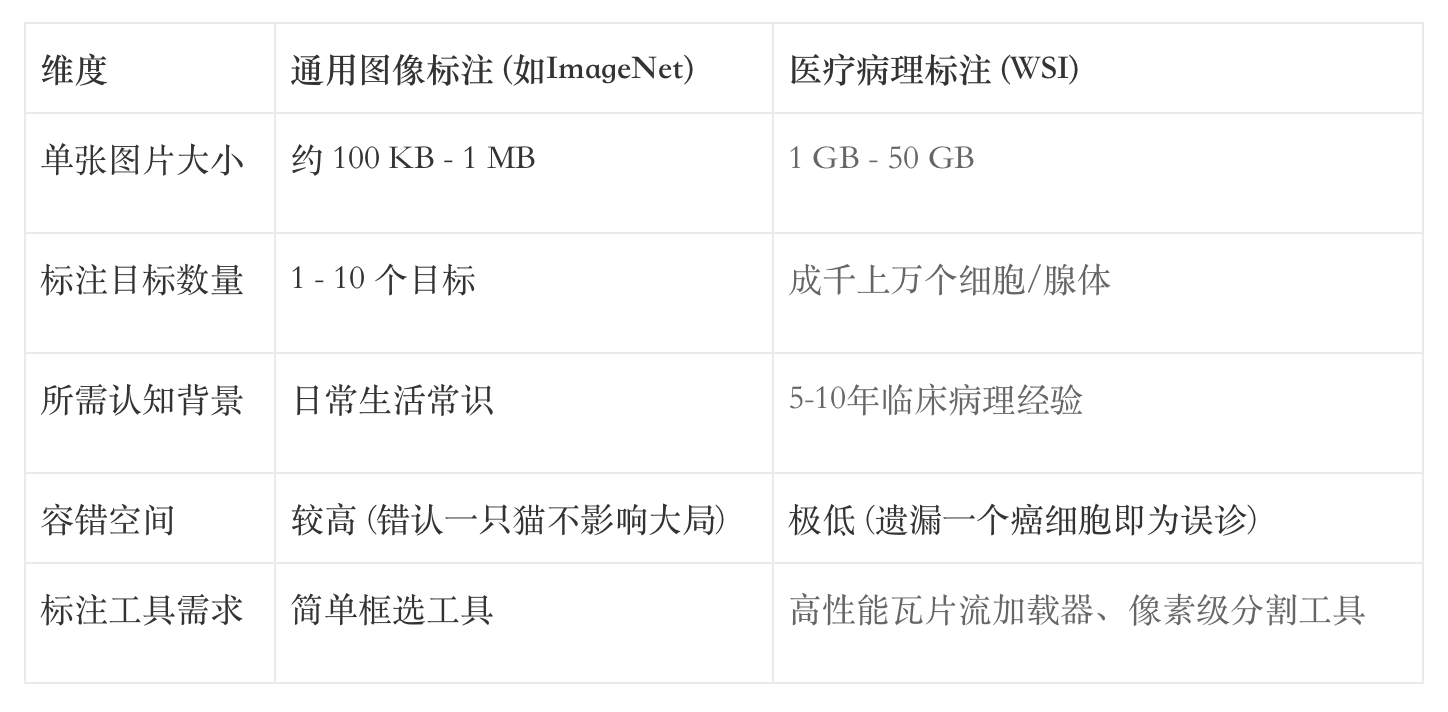
这种极度的不可读性导致了标注人员的断层。在医疗AI的研发链路中,普通标注员已实质性“下岗”,而能够胜任“老师”角色的专家却分身乏术。
拆解医疗RLHF:这里的“H”是极度稀缺的专家资源
在生成式AI(AIGC)时代,RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)成为了决定大模型成败的“点睛之笔”。正是通过这一环节,ChatGPT才从一个生硬的概率预测机器变成了一个能够理解人类意图、言语得体的人机交互接口。
医疗RLHF的底层逻辑:从“像人”到“像专家”
通俗而言,RLHF的过程包含三个阶段:模型给出多个备选答案;人类老师根据好坏进行打分或排序;模型根据得分调整自己的参数,学习“什么是更好的回答”。
但在医疗领域,“更好”的标准被极度泛化且严苛化。一个回答不仅要流畅,更要符合临床指南、具备科学依据,并且绝对安全。谷歌在开发Med-PaLM 2时,其RLHF过程不仅关注回答的准确性,还引入了九大评估轴心,包括科学共识、推理逻辑、知识召回、偏见以及潜在伤害程度 。
医疗“H(人类)”反馈的极高门槛
在通用模型训练中,普通大学毕业生经过短期培训就能对AI生成的诗歌或代码进行打分。但在医疗大模型中,评估者必须是具备执业资格的主治医师甚至主任医师。这是因为:
- 容错率为零的行业底线:通用AI写首诗写烂了只是个笑话,但医疗AI如果对用药建议给出“幻觉(Hallucination)”,比如将禁忌症药物建议给特定患者,那将直接导致医疗事故 。因此,每一个打分的专家都承担着巨大的职业风险和道德压力。
- 细粒度的错误识别:医生不仅要判断答案是否正确,还要指出模型在推理链条中的哪一步发生了断裂。例如,模型在诊断某类罕见病时,虽然得出了正确结论,但如果中间引用的实验室指标解读错误,专家必须给予低分,以纠正模型的“瞎猫碰到死耗子”行为 。
- 多维度的安全评估:Med-PaLM 2的评估显示,专家在打分时会特别关注“危害的可能性”。即使是一个看似正确的建议,如果缺乏必要的警示语(如“请在医生指导下使用”),也可能被判为不合格 。

这意味着,医疗AI的RLHF环节,其实质是在将顶尖专家的脑电波“数字化”。这种“H”的含金量,决定了模型能否跨越从“玩具”到“工具”的鸿沟。
扼住行业喉咙的成本:医生标注制约发展的“三座大山”
作为产品经理,在制定产品路线图时,必须面对由数据端传导而来的巨大财务与管理压力。这被业界形象地称为阻碍医疗AI起飞的“三座大山”。
第一座大山:高昂的经济成本与回报率难题
经济成本是医疗AI最直观的壁垒。数据标注本质上是知识的购买。在通用数据标注领域,标注员的时薪可能只有人民币几十元,但在医疗领域,我们是在购买主任医师的“门诊时间”。
根据北京市相关医事服务费标准,一名主任医师的专家组会诊费用可达每人次80元,而如果是针对疑难病理切片的读片会诊,由副主任和主任医师组成的专家组单次费用为140元 。在AI训练中,一个模型往往需要数以万计的标注样本。如果按此临床价值进行折算,标注1万张高质量病理切片的直接专家成本将超过百万级别。
此外,企业往往无法承担顶级专家长时间从事枯燥标注工作的机会成本。对于主任医师而言,他们更愿意将时间花在复杂手术、科研攻关或高层决策上。因此,为了吸引这些“老师”,企业不仅要支付高额的标注费,还要在学术成果冠名、联合研发权等方面给予额外补偿。
第二座大山:极长的时间周期与“碎片化”困局
医生是一个超负荷运转的职业。三甲医院的专科医生每天面临海量的看诊、手术和行政工作。他们能够参与AI标注的时间极其碎片化,通常只能利用下班后或周末的休息时间。
这种时间上的不可控性导致了医疗AI迭代周期的漫长。下表展示了典型医疗AI项目的开发时间分布:
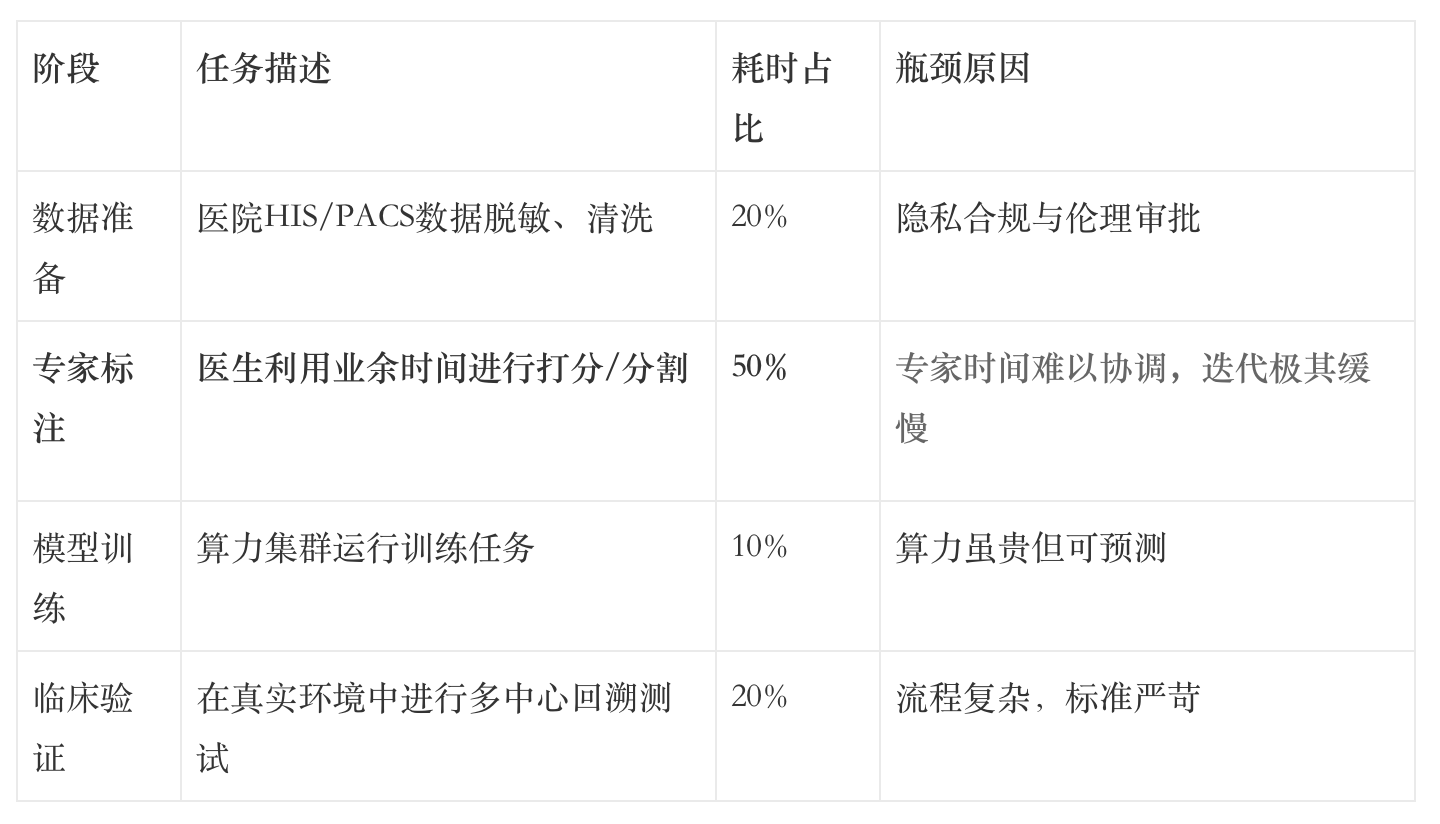
这种缓慢的节奏与科技行业“唯快不破”的信条严重冲突。当一个算法在算力平台上只需3天就能完成训练,却需要等待3个月才能获得专家的标注反馈时,企业面临着极大的资金沉没风险。
第三座大山:专家意见的分歧与“金标准”的消失
这是医疗AI标注中最具迷惑性、也最让AI PM头疼的问题:即使是顶级专家,也会产生分歧。这在行业内被称为“观察者间变异(Inter-observer variability)”。
在一项针对食管癌(EC)靶区勾画的研究中,四位经验丰富的放射肿瘤科医生对同一组多模态影像(CT、PET/CT等)进行标注 。结果显示,在某些复杂病例中,医生之间勾画的肿瘤边界存在显著差异。即便引入了多模态影像来辅助诊断,其一致性(CIgen)仍无法达到100% 。

当AI面对两个完全相反的“专家意见”时,它会陷入逻辑混乱。为了解决这一问题,产品经理不得不引入更复杂的“多医生会诊”打分机制。通常采用“STAPLE算法”或“大多数原则”来生成最终的“金标准(Ground Truth)” 。
只有当 $H$ 超过一定阈值(如0.75)时,该点才被认为是金标准。这意味着对于每一条数据,企业都要支付3-5倍的专家费用,这无疑进一步推高了成本,扼住了行业发展的喉咙。
破局之路:作为AI Product Manager视角的解决方案
面对“高成本、慢周期、不一致”的标注困局,作为AI产品经理,绝不能仅仅依靠向老板申请更多预算。我们必须从技术手段、流程优化以及行业协作三个层面构建破局之路。
人机协同(AI预标注):让专家从“绘图员”变为“判卷老师”
传统的标注流程中,专家需要手动划定每一个病灶的边缘,这种体力活极大地消耗了他们的精力。现在的先进平台(如“飞智标”)已经引入了人机协作工具链,通过AI预标注(AI Pre-labeling)引擎,实现流程提效 。
具体逻辑如下:
- AI初筛:先用一个已有的初级模型对海量原始数据进行“预加工”,自动框选出可能的结节或癌变区域。
- 专家修正:专家只需要在AI生成的结果基础上进行“点击、确认、微调” 。
- 效率飞跃:根据真实案例,集成30余种AI预标注引擎后,标注流程提效可达21%,整体人力节约50%,特定模态(如音频、图像)的效率提升甚至能达到100% 。
这种方式改变了专家的工作习惯,从“白手起家”变成了“批改作业”,极大地降低了他们的排斥心理。
建立“三级查房式”的分级标注体系
医院成熟的人才梯队——“规培生-主治医师-主任医师”——为AI标注提供了现成的管理模板。我们不必让顶尖专家处理所有数据。
- L1级:基础清洗(医学生/规培生)。通过与医学院校合作,建立产学研实训基地 。由医学生负责剔除低质量影像、完成解剖结构的粗略勾画以及标准化术语的清洗。这部分成本较低,且有助于学生学习。
- L2级:核心标注(高年资主治医师)。负责对初步筛选的数据进行病理分类、病灶分割和初步评分。这是数据的核心产出层。
- L3级:专家复核与仲裁(主任医师)。仅针对疑难病例、多方意见不一的矛盾数据进行最终裁决 。这种漏斗式的结构,可以将主任医师的时间利用率提高10倍以上。
目前,已有标注平台成功培养了超过2,000名具备医学、化学等专业背景的职业标注员,形成了覆盖全球的专业人才网络 。
高质量开源与联邦学习:打破“数据孤岛”的最后防线
最后,单打独斗的时代已经结束。医疗数据的神圣性决定了其不能像普通商品一样自由买卖。
- 联邦学习(Federated Learning):这是目前最被看好的技术方案。如NVIDIA在亚洲推动的案例所示,通过DGX-2超级计算机和NVIDIA FLARE框架,模型可以在不离开医院防火墙、不接触原始患者隐私的前提下,在多家医疗机构(如中国医药大学附设医院)之间巡回训练 。这解决了“数据拿不出”的难题。
- 标准化体系建设:当前医学人工智能标准化进程仍处于萌芽阶段 。作为PM,应积极推动建立统一的医学数据标准和基准数据集(Benchmarking),避免重复建设。
- 高质量开源呼吁:随着Med-PaLM 2等领先模型的发布,行业正形成一种共识:开源部分经过专家标注的“金标准”数据(如MedQA或MultiMedQA数据集),可以作为全行业的“公共设施”,降低整体准入门槛 。
结语:在知识的灰度中锻造救命的良医
医疗数据的标注困境,本质上是医学这门学科的严谨性与神圣性对硅基文明的“考验”。医学不是一堆像素的集合,它是经验、逻辑、伦理与责任的深度交织。
作为医疗AI的从业者,我们必须清醒地认识到:专家标注的这种高成本、高门槛,并不是制约发展的“坏事”,它其实是一道坚实的防火墙。正是因为有了这些顶尖“老师”近乎苛刻的纠错与打分,未来的AI才能在危急时刻给出那个“救命”的判断。
短期内,专家资源的稀缺和标注成本的昂贵会带来阵痛,但这也迫使我们去开发更智能的算法、更高效的平台。正如古话所云,“名师出高徒”,只有攻克了这一座座由顶尖医生智力资源构成的“大山”,我们才能教出真正能在临床上救死扶伤、造福人类的“好AI”。这条路虽然崎岖,却是通向智慧医疗时代的必经之路。
本文由 @壮年女子AIGC版 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


