
 起点课堂会员权益
起点课堂会员权益你还在死磕 Prompt?真正的高手早就不这么玩了
AI编程工具的革命不仅在于代码生成,更在于全新的工程范式——Harness Engineering。OpenAI的实验揭示:100万行生产级代码的背后,工程师们真正在构建的是AI运行的“环境”。本文深度拆解从Prompt Engineering到Harness Engineering的三阶段演进,剖析LangChain、Stripe等实战案例,揭示为何环境设计能力正成为工程师的新护城河。

最近有不少人问我:现在 AI 编程工具这么多,到底怎么用才算”用对了”?
我想先讲一个数字,你听完可能会有点坐不住。
OpenAI 内部有一个实验项目:3 到 7 名工程师,花了 5 个月时间,交付了一套超过100 万行代码的生产级软件系统。
这不是重点。
重点是——这 100 万行代码里,没有一行是工程师手写的。
你的第一反应可能是:那他们在干什么?调 Prompt?写需求文档?
都不是。
他们花了 5 个月,干了一件在今天看来越来越值钱的事:设计 AI 运行的“环境”。
这件事有个还不算广为人知的名字,叫做Harness Engineering 。
而我今天想聊的,正是这个正在悄悄重塑软件工程师价值的东西。
01 我们是怎么走到这一步的
要理解 Harness Engineering 是什么,得先回头看看这几年我们都在折腾什么。
第一站:Prompt Engineering
大概是 ChatGPT 刚出来那会儿,”Prompt 工程师”这个词突然火了。大家开始研究:怎么写提示词才能让模型给出更好的回答?用角色扮演?加上”深呼吸再回答”?还是祭出”你是一位资深专家”这类万能开场白?
哎,说实话,我当时也跟着研究了一阵子。那种感觉有点像在跟一个健忘又敏感的同事打交道——你得小心措辞,反复交代,还不一定每次都有效。
Prompt Engineering 不是没用,它确实能帮你把单次对话的质量提上去。但它有个根本性的天花板:不稳定、不可扩展、没有记忆、没有系统观。 你优化了一条 Prompt,换个场景可能就失效了。
第二站:Context Engineering
聪明人很快意识到,问题不只是”怎么说”,更是”说之前给它准备什么信息”。于是上下文工程(Context Engineering)开始被重视:RAG 检索增强、历史对话管理、工具调用输出的结构化整合……
这一步的进化是真实的。你不再只是在跟模型”聊天”,而是在动态地组装信息,让它在每一个时刻都能获取当前任务所需的知识。
但问题来了。
你告诉了 AI “知道什么”,却没有任何机制阻止它”做不该做的事”。
一个 Agent 可以知道很多,可以理解很多,但它在执行任务的过程中,没有人拦着它走偏。它会自由发挥,会过度操作,会在你意想不到的地方出问题。
这就是 Context Engineering 的天花板。
第三站:Harness Engineering
这一步的焦点,不再是”说什么”或”知道什么”,而是”在什么样的环境里做事”。
它要构建的,是一个包含约束、反馈、可观测性的完整运行时系统。让 AI Agent 不只是”懂得多”,而是”在一个不容易出错的操场里跑”。
三者不是简单的替代关系,而是嵌套演进的——每一层都在前一层的基础上,补上了它没解决的问题。但 Harness Engineering 是目前这个演进链条上,站得最高的那一层。
02 “马具”这个比喻,为什么这么准
Harness,中文直译是”马具”,就是套在马身上的那套缰绳、鞍具、挽具系统。
乍一听有点奇怪。为什么要用这个词来命名一种工程实践?
但你仔细想想,这个比喻其实精准到有点过分。
我们大多数人对”AI 辅助开发”的想象,是这样的:让 AI 这匹马跑得更快。更强的模型、更长的上下文窗口、更复杂的 Prompt 技巧……本质上都是在”催马”。
但 Harness 的逻辑完全相反。
它不关心马跑多快,它关心的是:跑道设计得对不对、缰绳有没有套好、方向有没有偏。 目标是让这匹马在复杂的地形上,既能发挥速度,又不会冲出赛道、踩进坑里。
这背后有个更古老的工程哲学支撑,叫控制论(Cybernetics)。
控制论的核心问题,从来不是”怎么让执行单元更强”,而是”怎么设计一个能够自我调节的系统”。
举个很具体的例子:蒸汽机时代,工人们靠手动调节阀门来控制蒸汽压力——执行者是人,靠经验和直觉操作。后来有人发明了离心调速器,它能根据转速自动调节进气量,不需要人在旁边盯着。这不是”更强的工人”,这是“更好的系统设计”。
再往后,Kubernetes 的声明式编排做的也是同一件事。你不告诉系统”先启动这个容器,再检查那个端口,失败了重试三次”——你只告诉它”我要这个服务保持三个副本的健康状态”,剩下的事,系统自己搞定。
从手动拧阀门,到设计调速器,到声明式编排,再到今天的 Harness Engineering——工程师的核心工作,一直在从“执行”向“设计系统”迁移。
这次的迁移,只是比以往任何一次都彻底一些。
我个人觉得,很多工程师对 AI 时代的焦虑,本质上不是技术跟不上,而是对这种角色转变感到不适应。写代码这件事给人的掌控感太强了,而”设计环境”这件事,反馈周期更长,成就感也更隐性。但这不代表它不重要,恰恰相反——
它正在变得比写代码本身更值钱。
03 Harness 到底长什么样
好,概念聊完了,来点干货。
一套完整的 Harness 系统,大概由四个部分构成。我不想用文档式的方式逐条列给你,咱们换个角度——想象一下,一个 AI Agent 在你的代码仓库里”上班”,它的一天是怎么过的。
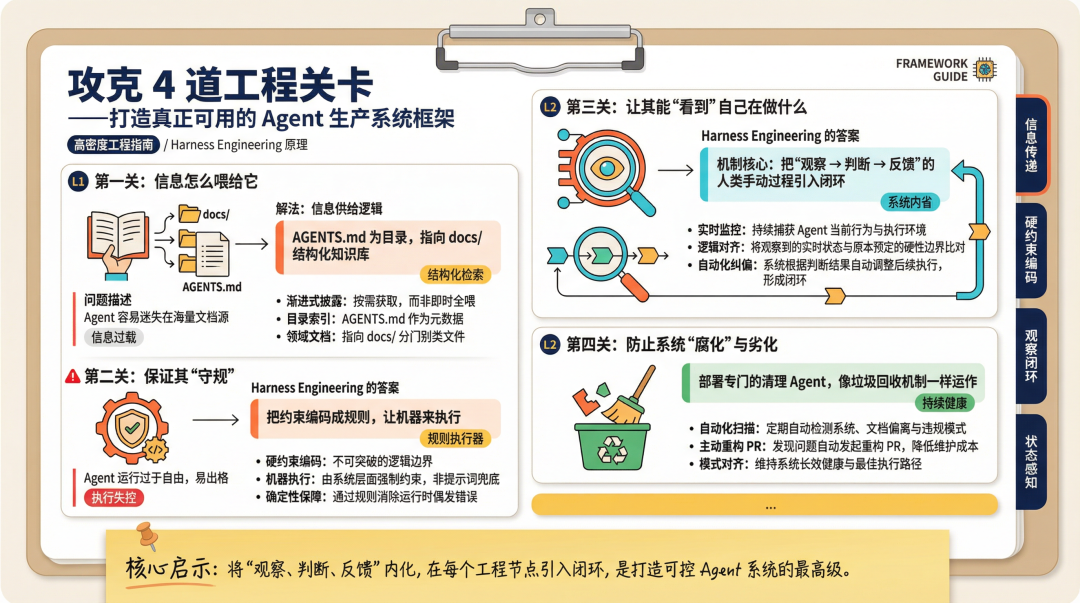
第一关:信息怎么喂给它
Agent 早上”上班”,第一件事是搞清楚今天要干什么、有哪些约束、项目背景是什么。
很多团队的做法是:写一个超级长的AGENTS.md文件,把所有规范、背景、注意事项一股脑塞进去,然后扔给 Agent。
这个思路的问题在于:信息太多,等于没有信息。
更好的做法叫做渐进式披露——AGENTS.md只是一个精简的目录,指向结构化的知识库(比如docs/目录下分门别类的文档)。Agent 在执行具体任务时,才去按需检索对应的上下文,而不是在开始时就把所有东西都装进脑子里。
这背后有一个很重要的原则:Agent 看不见的,对它就不存在。
所以上下文工程的核心,不只是”给它更多信息”,而是”在正确的时机,给它正确的那一块信息”。同时,还需要把那些只活在聊天记录、口头同步、老员工脑子里的团队知识,转化为版本化、机器可读的仓库文档。这件事说起来简单,做起来是真的很考验团队。
第二关:怎么让它不做”出格”的事
Agent 开始干活了。它在写代码、改文件、调用工具。这时候问题来了:谁来拦着它别踩红线?
Harness Engineering 的答案是:把约束编码成规则,让机器来执行。
具体怎么做?把你团队的架构分层原则、依赖方向要求、代码风格规范,写成自定义的 Linter 规则。Agent 每次提交代码,Linter 自动扫描,违规就报错,不通过就不能合并。
这不是什么新鲜事,传统团队也在用 Linter。但 Harness Engineering 对这件事有一个额外的要求,细节藏在里面:
Linter 的错误输出格式,要为 AI 优化。
传统 Linter 的报错是给人看的,告诉你哪一行违反了什么规则。但如果错误信息里还包含了修复建议,Agent 就能直接读懂报错,自行修复,再提交,再检查——这个”违规 → 检测 → 修复”的闭环,就在 Agent 内部自动完成了,根本不需要人介入。
更进一步,一些团队还会用基于 LLM 的语义审计 Agent,来处理那些确定性规则覆盖不到的情况——比如”这段代码逻辑上是否与我们的产品规范一致”这类语义层面的问题。确定性规则兜底,语义 Agent 补充,两者配合。
第三关:让它能看到自己在做什么
这一关很多团队容易忽视,但我觉得它可能是整个 Harness 系统里最能拉开差距的环节。
你有没有想过:Agent 执行了一堆操作之后,它怎么知道自己做对了?
如果它只能看到代码文件本身,它无法判断”我写的这段逻辑,在真实运行时是否按预期工作”。
反馈回路要解决的就是这个问题:把系统的运行时状态暴露给 Agent。
实践层面,这意味着:
- 把日志、指标、追踪数据通过本地可观测性栈开放给 Agent 查询——它可以直接跑 LogQL 查日志,用 PromQL 查指标,而不是等人类去 Grafana 里捞数据再告诉它结果。
- 集成浏览器自动化工具,让 Agent 能打开它刚写好的前端页面,截图,验证功能是否符合预期——它自己测自己的代码。
- 甚至建立 Agent 对 Agent 的自动化代码评审循环。一个 Agent 写代码,另一个 Agent 审代码,提出意见,循环迭代,人类只在关键决策节点介入。
这整套机制的核心思想,是把原本需要人类手动完成的”观察 → 判断 → 反馈”过程,设计成系统自动运转的闭环。
第四关:防止系统自己”腐化”
这一关是很多人没想到的。
Harness 建好了,是不是就可以高枕无忧?
不是的。
有两个熵增的来源会慢慢腐蚀你的系统:
- 文档和规则会漂移。你的 AGENTS.md 写于三个月前,现在项目架构变了,文档还没更新——Agent 拿着过时的信息在干活,出了问题你还不知道从哪查起。
- AI 生成的代码会复制现有模式,包括坏模式。如果你的代码库里有一段写得很糟糕的历史遗留代码,Agent 在生成新代码时,很可能参照它的风格继续写。日积月累,“AI 技术债”就这么悄悄堆起来了。
解决方案是部署专门的清理 Agent——定期自动扫描文档漂移、检测模式违规、发起重构 PR,像垃圾回收机制一样,持续维持系统的健康状态。
这个思路本质上是把”技术债治理”这件原本依赖人的自觉和精力的事,变成了一个系统级的自动化任务。
04 四个公司的真实战场

光讲理论不够有说服力,来看看真实的案例。
OpenAI:最难的事,不是生成代码
前面提到的实验已经说明了结论,但我想强调一下 OpenAI 工程师自己总结的那句话:
“最困难的挑战,不在于让 AI 生成代码,而在于设计环境、反馈回路和控制系统。”
这句话值得反复读。它意味着,AI 生成代码这件事本身,已经不是瓶颈了。瓶颈在环境设计。
LangChain:不换模型,只改环境,排名从第30跳到第5
这个案例是我觉得整个 Harness Engineering 讨论里,数据最直接、最有冲击力的一个。
LangChain 在 Terminal Bench 2.0 基准测试上,对他们的 Agent 系统做了一次优化——没有换模型,没有改 Prompt,只是优化了 Agent 的运行环境:完善文档、增强验证、改进追踪。
结果?排名从第 30 位跳到第 5 位,得分从 52.8% 提升至 66.5% 。
你用同样的马,换了一套更好的马具,就跑出了完全不同的成绩。
Stripe:工业级的 AI PR 流水线
Stripe 的 Minions 体系,是目前我见过的最接近”工业生产”级别的 Harness 实践。
每周合并超过 1300 个 AI 编写的 PR 。支撑这个数字的,是三个关键设计:
- 预热 devbox 隔离环境:每个 AI 任务都在独立的预热好的沙箱里运行,互不干扰,安全可控。
- Toolshed 中心化工具访问:所有 Agent 通过统一的工具层访问外部系统,不允许野路子直连。
- 确定性节点与 Agent 节点混合的蓝图模式:不是把所有决策都交给 Agent,而是把需要严格可预测性的步骤做成确定性节点,把需要灵活判断的步骤交给 Agent——混合编排,取长补短。
Anthropic:16个 Claude 并行,2 周造出 C 编译器
这个案例验证的是另一个维度:多 Agent 协作的可行性。
16 个 Claude 代理并行工作,历时 2 周,花费 2 万美元 API 成本 ,构建了一个能编译 Linux 内核等复杂系统的 C 编译器。
这不只是”AI 会写代码”的证明,更是”在精心设计的 Harness 下,多 Agent 并行协作完成高复杂度工程任务”的可行性验证。
每个案例背后指向的,都是同一个结论:环境设计,才是真正的杠杆所在。
05 工程师的角色,真的不一样了
说到这儿,可能有人会问:那我作为一个普通工程师,应该怎么办?
我先说一个让人有点不舒服的观察。
现在市面上有一种声音,说 AI 编程工具会让初级工程师”弯道超车”——不用打基础,直接用 Agent 生成代码,效率比老工程师还高。
我觉得这个判断,短期内可能是对的,但长期来看很危险。
原因很简单:Harness Engineering 需要的那种能力——系统抽象能力、架构判断力、对代码质量的直觉——这些东西,是从大量手动开发经验里提炼出来的。
如果一个工程师从来没有手动写过一个稳健的系统,没有踩过那些经典的坑,他凭什么设计出一套能管住 AI 的 Harness?
这就是所谓的“学徒缺口” ——当传授经验的手动开发过程被跳过,年轻工程师会丧失建立正确直觉的机会。他们可以用 Agent 生成代码,但他们没有能力判断生成的代码是否真的好,也没有能力设计防止它变坏的系统。
这不是在劝你拒绝 AI 工具。恰恰相反,我觉得最好的学习路径,是把手动做和用 Agent 做这两件事,放在一起对比:
先手动完整实现一个功能,然后用 Agent 做同样的事,仔细看看它做了什么、哪里做对了、哪里做得很糟糕。这个对比过程,是建立直觉最快的方式。

对于已经有经验的工程师,有几件事现在可以开始做:
- 维护一个 AGENTS.md 文件。 不需要一开始就写得很完整,从最基本的项目结构和规范开始。每次 Agent 犯了一个你觉得不应该犯的错,就把对应的规则补进去。这个文件会越来越好用,同时也是你在给自己的项目建立”机器可读的记忆”。
- 养成用 Agent 做探索类任务的习惯。 调研新技术、读陌生代码库、起草文档初稿——这些任务的共同特点是:验证成本相对低,你能快速判断 Agent 给的东西是不是靠谱。先在这些场景里积累对 Agent 能力和局限的直觉。
- 把”人类什么时候介入”这件事想清楚。 不是 Agent 叫你看你才看,而是你主动设计检查点,在关键决策节点介入,其他时候让 Agent 自己跑。这是”掌舵者”和”被 Agent 打断者”的本质区别。
06 下一站在哪里
Harness Engineering 还在快速演进中,但它指向的下一个方向已经隐约可见。
当单个 Agent 的”马具”问题基本解决之后,下一个问题是:多个 Agent 之间怎么协作?
这就是 Protocol Engineering 或者说 Agent Infrastructure 正在试图回答的问题——智能体之间的互操作协议,比如 Model Context Protocol(MCP);跨 Agent 的共享状态与工具管理;本质上是在构建一套 AI 操作系统 。
这个方向距离普通工程师的日常实践还有一段距离,但它在告诉我们:软件工程的竞争维度,正在从”谁的工程师代码写得更好”,迁移到“谁能设计出更好的 Agent 运行环境”。
我想用一个问题来结束这篇文章,不是结论,只是一个值得认真想的问题:
当“设计环境”的能力比“写代码”的能力更值钱,我们今天培养工程师、评价工程师、招募工程师的方式——是不是该认真想想了?
这个问题没有标准答案。但你越早开始思考,可能就越不会被它打措手不及。
本文由 @酸奶AIGC 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


