
 起点课堂会员权益
起点课堂会员权益从 AlphaGo 到 OpenClaw:那些让你突然觉得 AI 变聪明了的瞬间,背后都发生了什么?
从AlphaGo的震惊首胜到ChatGPT的流畅对话,再到DeepSeek的成本革命和AI Agent的任务接管,AI的发展并非线性进步,而是经历了五次关键的'感知跃迁'。本文深度解析每一次跃迁背后颠覆性的产品决策与技术路径,揭示AI如何通过改变交互范式而非单纯提升算力,持续刷新人类认知边界。

你还记得第一次用 ChatGPT 时的感觉吗?
不是那种”哦,挺厉害的”的礼貌性惊讶,而是一种真实的错愕——它好像真的在回答你,不是在检索,不是在匹配,而是在理解你说的话,然后给出一个你没想到但确实有用的回答。
那一刻,很多人的第一反应是:AI 突然变聪明了?
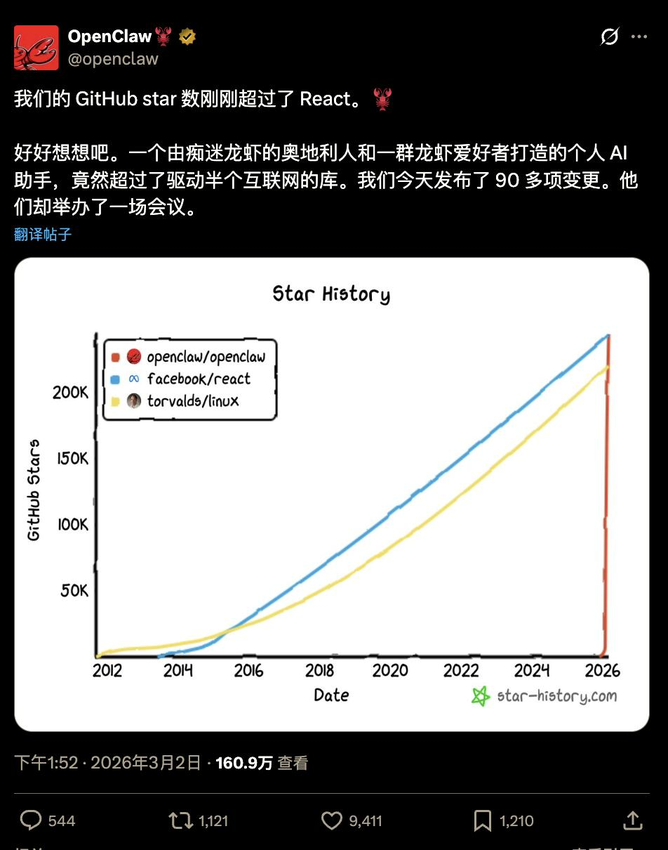
但如果你往前翻一翻,会发现这种感觉已经不是第一次了。2016 年 AlphaGo 赢了李世石,很多人也有过类似的错愕。2025 年初 DeepSeek 横空出世,又是一次。同年 AI Agent 开始真正能”干活”,还有 OpenClaw 在 GitHub 上以超 25 万星标超越 React,再到 2026 年 Seedance 2.0 展示出电影级别的视频生成能力——每一次,都有人感叹:AI 又不一样了。
这篇文章想做的事,是把这些时刻拆开来看。每一次让你觉得 AI 突然变聪明了的背后,都不只是”算力更强了”或”数据更多了”,而是有人做出了一个关键的技术或产品决策,改变了 AI 和人交互的方式。
我把这些时刻叫做感知跃迁。
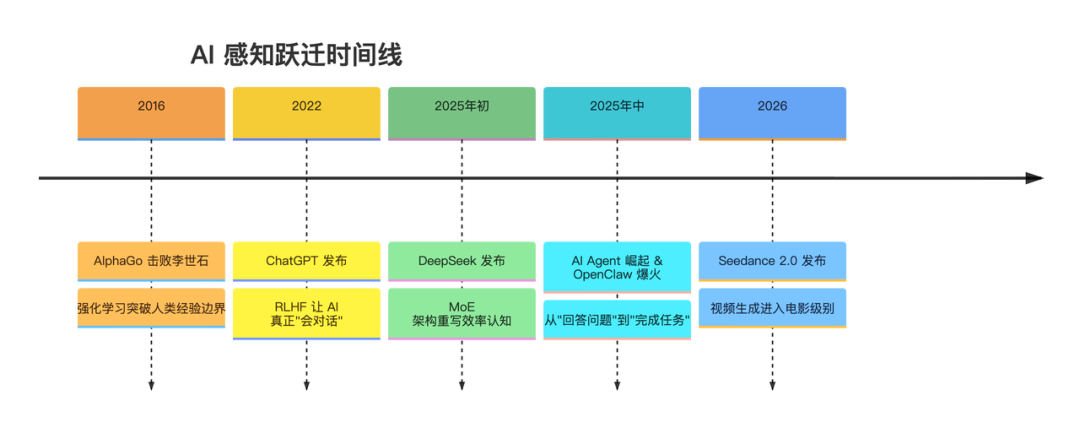
2016,AlphaGo——AI 第一次让人类感到威胁
围棋在很长一段时间里,是人类用来安慰自己的最后一道防线。
国际象棋输给深蓝(1997 年),可以说”那是暴力计算,不是真正的智能”。但围棋不一样——围棋的变化数量约为 $2.08 times 10^{170}$,远超宇宙中原子的数量(约 $10^{80}$)。穷举法在数学上就是死路,没有任何计算机能靠算力硬堆出答案。这意味着,如果 AI 想赢围棋,它必须真正”学会”下棋,而不是”算出”下棋。
AlphaGo 的解法,是两套神经网络的组合:策略网络(Policy Network)负责判断”下哪里”,价值网络(Value Network)负责评估”当前局面赢的概率”,两者结合蒙特卡洛树搜索(MCTS)来大幅缩小搜索空间,从而在有限时间内找到足够好的落子选择。
但真正让人后背发凉的,不是 AlphaGo 赢了,而是它赢的方式。
AlphaGo 的训练分两个阶段。第一阶段用人类棋谱做监督学习,让它先学会”人类怎么下”;第二阶段让它和自己对弈数百万局做强化学习——而这个阶段产生的 AlphaGo,已经不再模仿人类下法,而是发展出了人类从未见过的棋路。第五手”肩冲”,职业棋手当场愣住,因为那不是任何人类棋谱里存在的选择,但事后复盘,那步棋确实是对的。
这是 AI 第一次在某个领域超越了所有人类经验的边界,而不只是在人类经验的范围内做得更好。
这一章不是要讲 AlphaGo 有多厉害,而是要建立一个认知框架:AI 的能力边界,比我们以为的更模糊。而且它突破边界的方式,往往不是”做了人类做的事”,而是”做了人类从没想过要做的事”。这个认知,是理解后续所有感知跃迁的前提。
2022 年底,ChatGPT——让 AI 变好用的,不是算法
这一章的核心是一个反直觉的事实:ChatGPT 和 GPT-3 用的是同一套底层架构,但用户体验天差地别。
GPT-3 在 2020 年发布时已经很强,但用起来感觉很奇怪。你问它一个问题,它会给你一段连贯的文字——但那段文字更像是在”续写文本”,而不是在”回答你”。这是因为语言模型的训练目标是预测下一个词:给定前面的所有词,下一个词最可能是什么。它学的是统计规律,而不是”怎么回答一个问题”。
OpenAI 用RLHF(人类反馈强化学习)做的事,是给这个训练目标打了一个补丁。
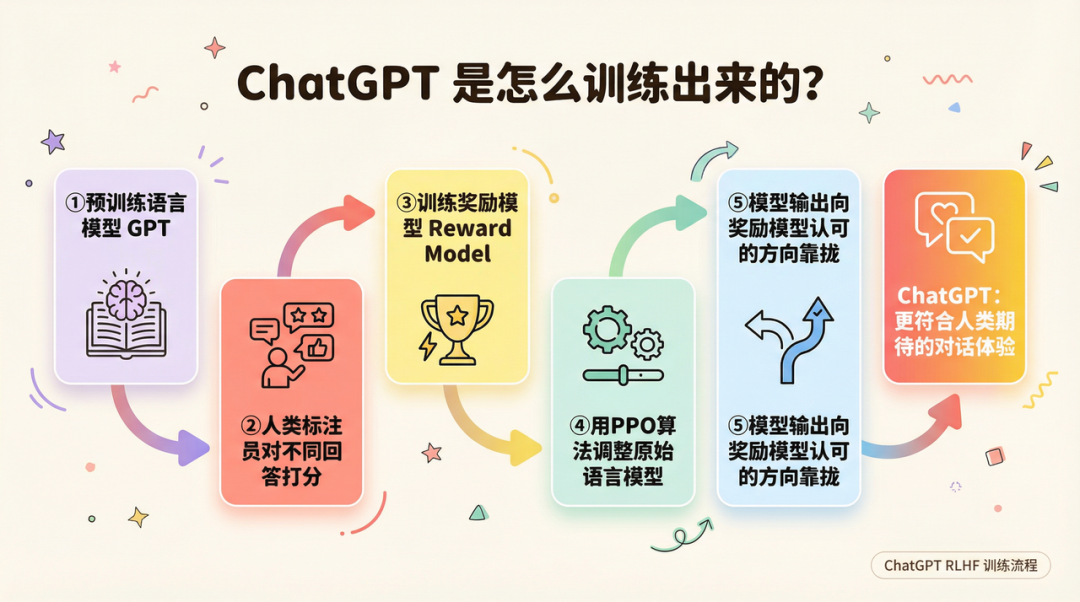
具体来说,RLHF 分三步走:
第一步,让人类标注员对同一个问题的多个不同回答打分,收集”哪个回答更好”的偏好数据。第二步,用这些数据训练一个奖励模型,让它学会”什么样的回答是好的”。第三步,用强化学习(PPO 算法)调整原始语言模型,让它的输出向奖励模型认可的方向靠拢。
这个过程的本质,是把人类对”好的对话”的直觉,编码进了模型的行为里。结果是:同样的底层能力,ChatGPT 的回答更符合人类期待,更像在”真正回答你”,而不是在”生成文本”。
但这里有一个值得单独讲的反直觉点:RLHF 并没有让模型”更聪明”,它让模型”更讨人喜欢”。这两件事不一样。这也是为什么早期 ChatGPT 会一本正经地胡说八道——它学会了怎么回答”听起来正确”,但不一定”真的正确”。这个局限性,直到今天都没有完全解决。
理解这一点很重要:让 AI 产品真正可用的,往往不是模型本身的能力,而是训练目标的设计。OpenAI 做的关键决策,是把”对话友好”作为一个可以被优化的目标——这个决策,比 Transformer 架构本身对普通用户的影响更大。
2025 年初,DeepSeek——效率,才是真正的护城河
DeepSeek 带来的感知跃迁,和前两次有些不同。
AlphaGo 让你感到”AI 能做到我以为它做不到的事”,ChatGPT 让你感到”AI 终于好用了”,而 DeepSeek 让你感到的是:”原来不需要花那么多钱。”
2025/26 年,AI 基建投资约 1 万亿美元,四大科技巨头(亚马逊、微软、谷歌、Meta)投入 7000 亿+。而 DeepSeek 的训练成本据报道不超过 600 万美元,却能对标顶尖模型的性能。这个反差,动摇了一个此前被视为铁律的假设:大模型是大公司的专属游戏。
DeepSeek 能做到这一点,背后有几个关键的技术取舍:
第一,MoE(混合专家架构)的应用。传统的 Dense 模型在处理每一个 token 时,会激活所有参数。而 MoE 模型会把参数分成若干”专家”,每次只激活其中一小部分。DeepSeek-V3 拥有 6710 亿参数,但每次推理只激活约 370 亿——这意味着同样的算力可以支撑更大的模型,训练和推理成本大幅下降。
第二,MLA(多头潜在注意力)的优化。传统注意力机制的 KV Cache 会占用大量显存,DeepSeek 用低秩压缩的方式大幅缩减了 KV Cache 的体积,让模型在有限显存下能处理更长的上下文。
第三,精准的能力取舍。DeepSeek 没有追求”什么都做到最好”,而是在特定能力上做了精准的强化,在其他维度上接受一定的妥协。这是一种工程上的务实主义,而不是技术上的妥协。
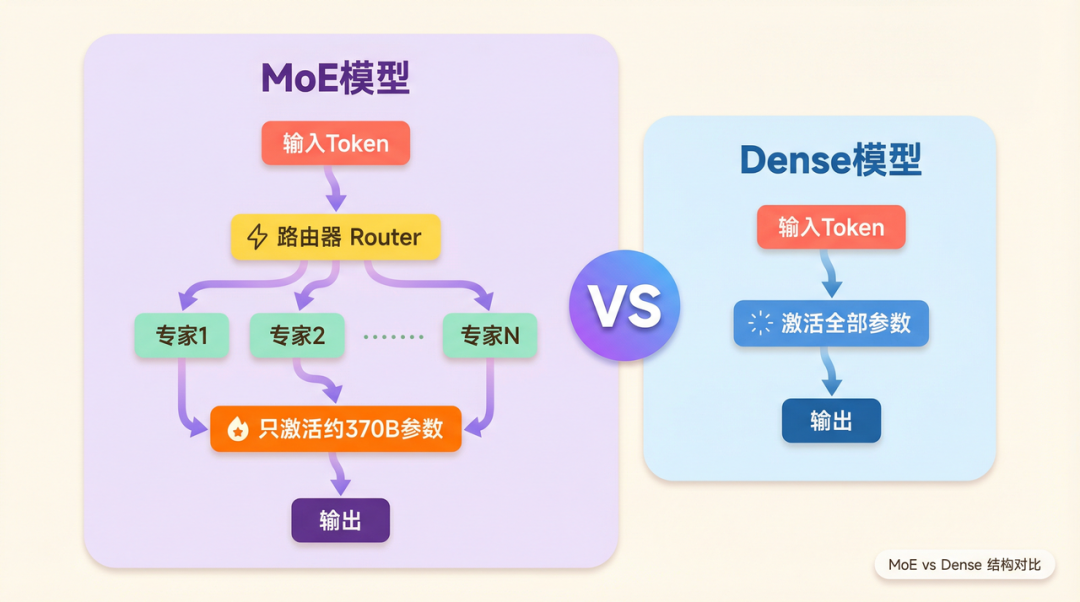
DeepSeek 的意义,不是”便宜的 AI”,而是它证明了一件事:在大模型领域,算法效率的提升可以部分替代算力的堆砌。这对整个行业的影响是:AI 的能力门槛正在被打破,原本只有少数公司才能做的事,开始向更多人开放。
这对工具使用者来说,意味着一个实际的变化:你所能调用的 AI 能力,将不再只取决于你愿意付多少钱,还取决于谁在效率优化上走得更远。
2025 年中至今,AI Agent 与 OpenClaw——从”回答问题”到”完成任务”
如果说前三次感知跃迁改变的是”AI 能做什么”,那么 Agent 的出现改变的是”AI 在这件事里扮演什么角色”。
过去你用 AI 写一份竞品分析报告,你需要自己搜索资料、整理信息,然后把内容喂给 AI,告诉它每一步做什么。AI 是一个高效的执行工具,但你是那个真正在”做事”的人。
现在,一个配置好工具的 Agent 可以自己搜索、自己整理、自己生成报告,你只需要在最后审核结果。这个差别不是”省了几分钟”,而是你在这个任务中的角色从操作者变成了审核者。
一个 AI Agent 的基本工作流程是这样的:
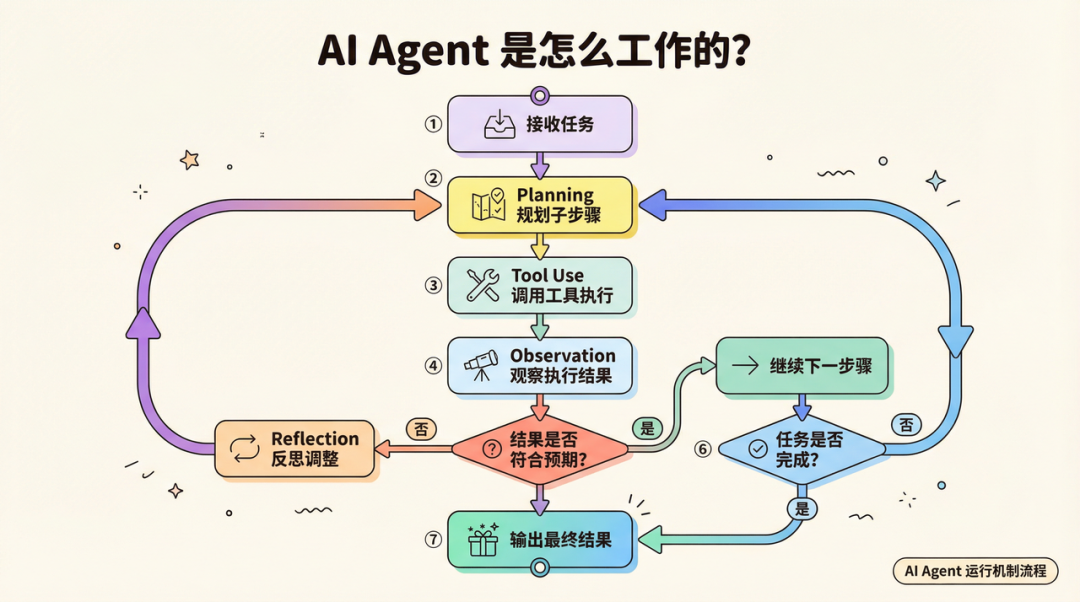
这个流程看起来简单,但实现起来有几个关键瓶颈值得单独讲。
规划能力的瓶颈。当前 Agent 最大的问题,是在复杂任务的规划阶段容易出错——它可能把一个任务拆解成错误的子步骤,或者在执行到一半时因为某个工具返回了意外结果而”卡住”。这是为什么现在大多数 Agent 产品还需要人在关键节点介入。真正意义上的”全自动”,目前仍然是少数场景下的能力。
MCP(Model Context Protocol)的意义。2025 年 3 月提出的 MCP 标准,试图解决的是一个基础设施问题:不同的 AI Agent 如何以统一的方式调用外部工具?在 MCP 之前,每个 Agent 框架都有自己的工具调用接口,生态碎片化严重。MCP 的目标是让工具开发者只需要实现一套接口,就能被所有支持 MCP 的 Agent 调用——这对 Agent 生态的成熟至关重要,类似于 USB 接口对硬件生态的意义。
OpenClaw 的意义。2025 年 11 月,独立开发者 Peter Steinberger 发布了 OpenClaw 并开源,随后它在 GitHub 上以超 25 万星标超越 React,成为增长最快的开源项目,开发者随后加入 OpenAI。这个数据的含义不只是”很多人感兴趣”,而是开发者社区开始把 Agent 框架当作基础设施来对待——就像当年 React 之于前端开发,OpenClaw 可能正在成为 Agent 开发的默认起点。
有些社交平台甚至出现了”养虾交流群”——”养虾”是对 Agent 自主运行任务的戏称,这个称呼本身就说明了一件事:用户已经开始把 Agent 当成一个可以”放养”的工具,而不只是一个需要时刻盯着的助手。
Agent 时代真正改变的,是人和 AI 之间的分工边界。对于工具使用者来说,这意味着一个实际问题:哪些任务值得交给 Agent,哪些任务仍然需要自己做?这个判断能力,会成为未来效率差距的来源。
2026 年,Seedance 2.0——下一次跃迁,已经开始了
2026 年 2 月,字节跳动发布 Seedance 2.0,宣称具备”电影级别制作能力”。
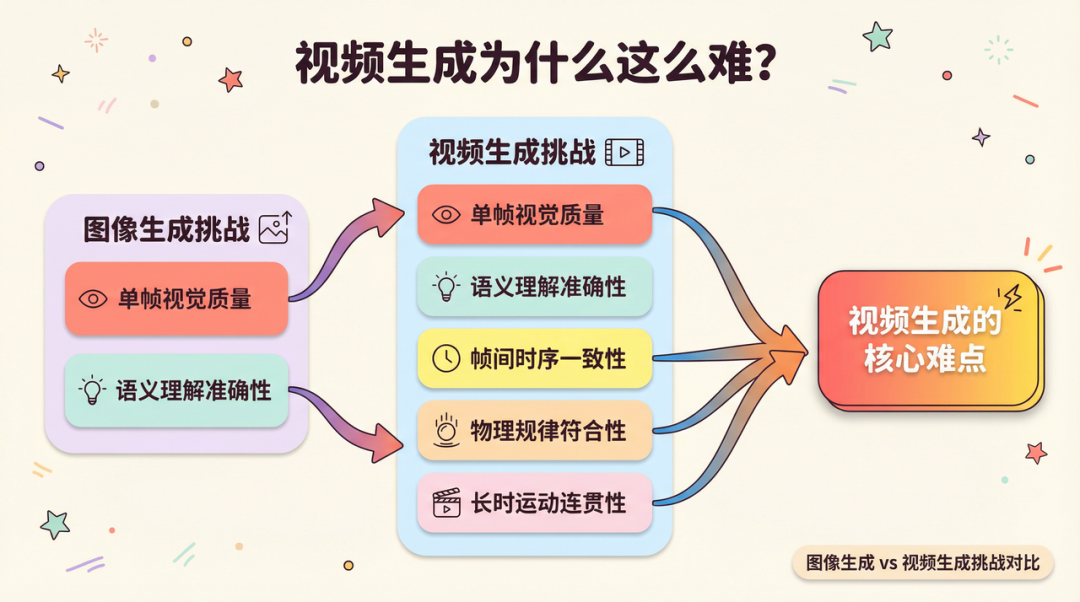
在讨论它有多厉害之前,值得先理解视频生成为什么比图像生成难得多。
图像生成只需要保证”这一帧看起来对”。视频生成需要保证帧与帧之间的时序一致性——物体的运动轨迹、光影变化、物理规律,都必须在时间维度上保持连贯。一个人走路,每一帧的姿态必须符合运动规律;一杯水倒出来,液体的流动必须符合物理直觉。这是为什么早期视频生成模型(包括 Sora 发布时)经常出现物体”凭空消失”或”违反物理规律”的问题——模型在单帧上表现很好,但在时序维度上失控。
Seedance 2.0 被描述为具备电影级别的制作能力,这个说法值得从工具使用者的角度审慎对待:它的能力边界在哪里?什么样的创作场景真正适合用它?什么场景下它还不够用?
就目前来看,AI 视频生成在短片创意、广告素材、概念演示等场景已经展现出真实的生产力价值。但对于需要高度一致性的长视频叙事,或者需要精确控制演员表情和动作的内容,它仍然是辅助工具而非替代工具。
这一次跃迁和前几次有一个不同之处:它还没有被充分消化。我们正在经历它,而不是在回顾它。这意味着它的影响边界,现在还看不清楚。
感知跃迁的背后,是决策
回到开头的问题:为什么每隔一段时间,你会觉得 AI 突然变聪明了?
把五次跃迁放在一起看,会发现一个规律:每一次让你感知到变化的时刻,背后都不只是技术进步,而是有人做出了一个关键决策——
AlphaGo的决策,是用强化学习自对弈替代人类棋谱,让 AI 第一次超越了人类经验的边界;ChatGPT的决策,是把”对话友好”作为一个可以被优化的训练目标,而不只是追求模型能力的上限;DeepSeek的决策,是用效率换规模,证明算法优化可以部分替代算力堆砌;AI Agent的决策,是让 AI 承担任务的完整执行链路,而不只是生成一段文字;Seedance 2.0的决策,是把时序一致性作为视频生成的核心攻关方向,而不只是提升单帧质量。
这些决策,才是感知跃迁真正的来源。
对于一个工具使用者来说,理解这些决策背后的逻辑,有一个实际的价值:它帮你更快判断下一个值得投入时间的工具是什么。不是每一次”AI 有新功能”都意味着感知跃迁,只有当底层的交互范式发生变化时,才值得你重新审视自己的工作流。
AlphaGo 改变了你对 AI 能力边界的认知,ChatGPT 改变了你和 AI 交互的方式,DeepSeek 改变了你对 AI 成本的预期,Agent 改变了你在任务中的角色,视频生成正在改变你对内容创作的想象。
下一次跃迁,已经在路上了。
本文由 @小文_Arue 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


