
 起点课堂会员权益
起点课堂会员权益ChatGPT背后那个”幽灵”,到底是什么
Transformer 架构的诞生彻底改写了 AI 领域的游戏规则。从 ChatGPT 到 Sora,从 AlphaFold 到 ViT,看似毫不相关的技术突破背后都藏着相同的 DNA。本文将带你穿越 RNN 与 CNN 的旧世界,揭示注意力机制如何突破长程建模的困境,并探索这种『关系处理机器』是如何从语言领域溢出,重塑我们对世界的认知方式。

最近有个问题我被问了很多次:
“ChatGPT 到底是怎么工作的?”
每次我都想认真回答,但又不知道从哪里开始。直接讲神经网络,太抽象;讲”大语言模型”,像在说废话;讲 Transformer,对方通常会点点头,然后礼貌地换个话题。
所以我决定写这篇文章。
不是要给你一份技术手册,而是想聊聊一件我觉得很多人忽视了的事:Transformer 不只是一种神经网络架构,它代表了一种思维方式的跃迁。
你现在用的 ChatGPT,看到的 Sora 生成视频,听说的 AlphaFold 解开蛋白质折叠之谜——这些看起来毫不相干的技术突破,背后共享同一个名字。
2017 年,Google 的一篇论文,标题叫《Attention Is All You Need》。
就这一篇,重写了整个 AI 领域的游戏规则。
理解它,不需要你会写代码,不需要你懂矩阵运算。你只需要愿意跟我一起,想清楚一件事:在 Transformer 出现之前,AI 是怎么”读”世界的?它又做对了什么,才让一切不同?
这篇文章会沿着这条线走下去:旧世界的困境 → 注意力机制的核心 → 两种不同的使命 → 从语言到万物 → 革命的代价与未来。
我尽量不让你觉得自己在上课。
旧世界的围墙:在 Transformer 出现之前
要真正理解一场革命,得先感受一下被推翻的那个旧世界有多憋屈。
患了失忆症的”朗读者”
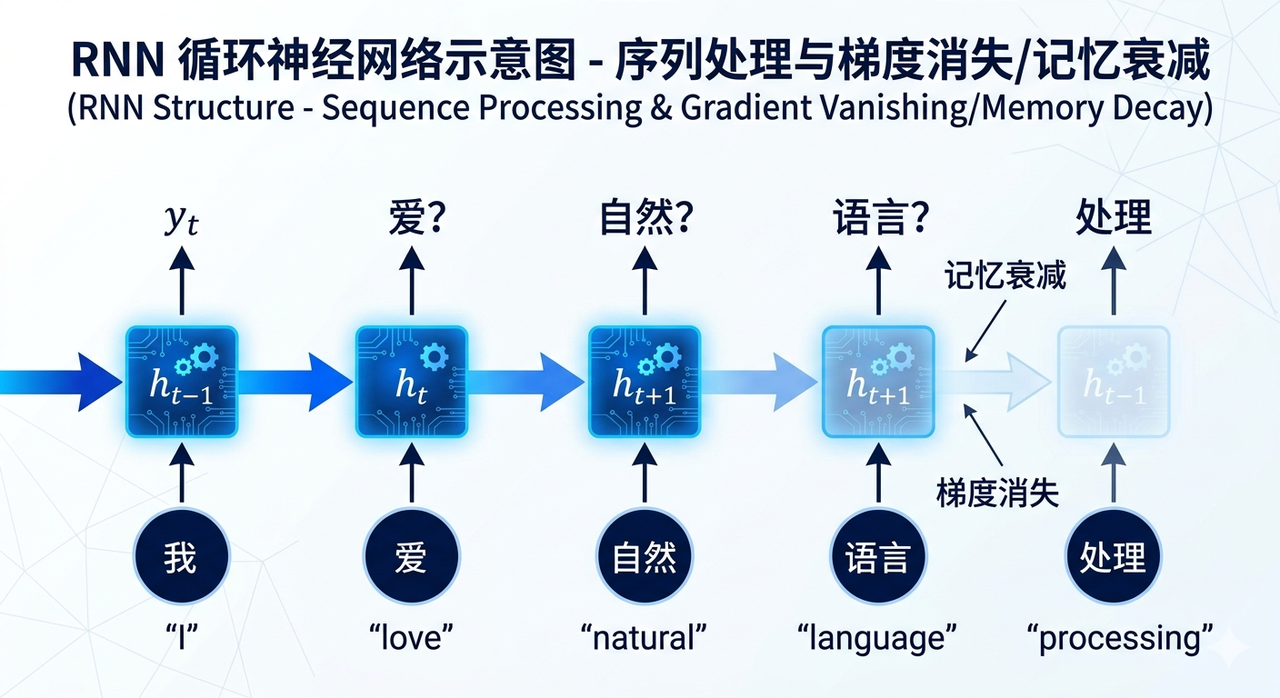
在 Transformer 出现之前,处理语言最主流的工具叫 RNN(循环神经网络)。
它的工作方式,是严格的逐字推进。
想象一个朗读者,每次只能看一个词,读完之后,把”对这个词的记忆”带到下一个词,然后继续。读完第二个词,再把”融合了前两个词的记忆”带到第三个词……就这样一路往前走。
听起来好像还行?
问题在于,这个朗读者患了某种特殊的短期失忆症。
当他读到一段话的第 50 个词时,他对第 1 个词的记忆,已经被后来 49 次的”覆盖和稀释”弄得模糊不清了。这在技术上叫做梯度消失——信号在漫长的序列传递中,像电话游戏一样,一层一层衰减,到最后几乎什么都剩不下。
这带来了一个很实际的问题:模型根本没办法建立”长距离依赖”。
比如这句话:”The cat, which had been sitting by the window all afternoon, finally fell asleep。”
“fell”这个词,在语法上和语义上,都应该对应最开始的”cat”。但对于 RNN 来说,”cat”和”fell”之间隔了那么多词,这条线索早就断了。模型只能靠最近几个词来猜下一个词,对整体逻辑的把握几乎为零。
还有一个更要命的问题:顺序依赖导致无法并行。
既然必须逐字处理,第二个词就必须等第一个词处理完,第三个词再等第二个……整个计算过程是一条串行的流水线。GPU 再厉害,也没法同时处理所有词——它被迫排队。
这就是为什么用 RNN 训练长文本,既慢又效果差。
后来有人用 LSTM(长短期记忆网络)打了一些补丁,试图让模型”主动决定记住什么、忘记什么”。有用,但治标不治本。串行的架构问题在那儿,长程建模的天花板就在那儿。
戴着固定”观察窗”的视察员
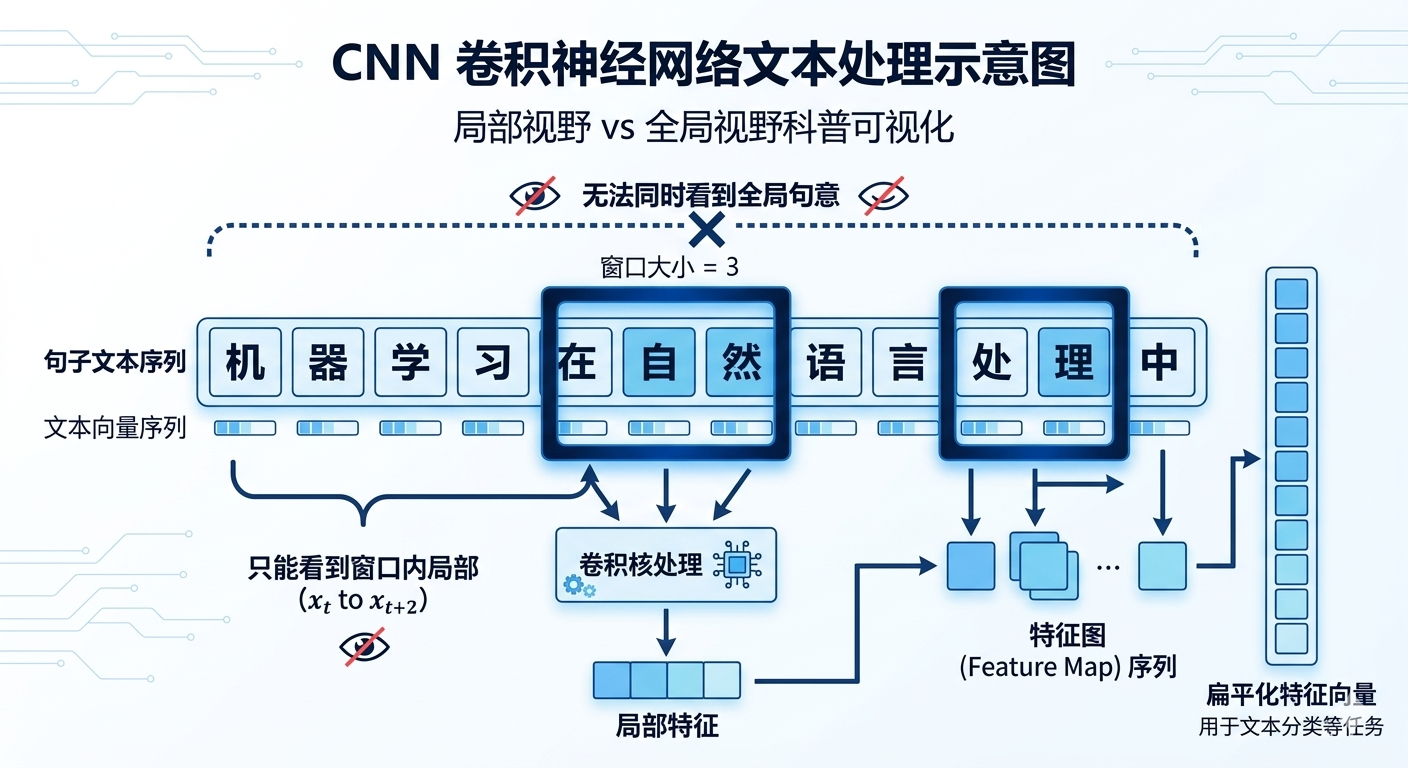
还有另一条技术路线,用 CNN(卷积神经网络) 来处理语言。
CNN 本来是图像领域的利器。它的核心操作是用一个固定大小的”卷积核”,像扫描仪一样在图像上滑动,捕捉局部特征——比如边缘、纹理、形状。
把这个逻辑迁移到语言上,就是用一个固定大小的”窗口”在句子上滑动,捕捉局部的词组关系。
但问题也很明显:这个窗口是固定的,视野是有限的。
想把”窗口”扩大,看到更远的词之间的关联?需要堆很多层,计算量指数级上涨,效果还不稳定。更麻烦的是,CNN 天生对位置顺序不敏感——它关心的是”这个区域有没有某种模式”,而不是”这个词在第几位”。
语言这种东西,顺序就是意义的一部分。”我欠你的”和”你欠我的”,词一样,顺序不一样,意思天差地别。CNN 对这种事,处理起来很别扭。
所以到 2017 年之前,整个领域面对的是同一堵墙:
串行计算的低效,和长程建模的无力。
不是没人努力,而是在这个框架下,努力的空间越来越小了。
注意力的宇宙:Transformer 做对了什么
2017 年那篇论文的标题,《Attention Is All You Need》,今天读起来仍然像一句宣言。
它在说:你们之前所有的努力方向,可能都走偏了。
抛弃顺序,拥抱全局
Transformer 最根本的一个决定,是彻底抛弃了”逐字处理”的顺序结构。
它不再让模型一个词一个词地读,而是把整个句子的所有词同时扔进去处理。每个词不再是”接力棒传递链上的一环”,而是同时出现在同一张桌子上的与会者。
这个改变有多激进?打个比方:
RNN 的方式,是让你把一本书从第一页读到最后一页,合上书之后,凭记忆回答问题。
Transformer 的方式,是把这本书摊开放在你面前,让你同时看到所有页面,然后回答问题。
哪种方式更容易理解书的整体结构和远距离联系?答案不言而喻。
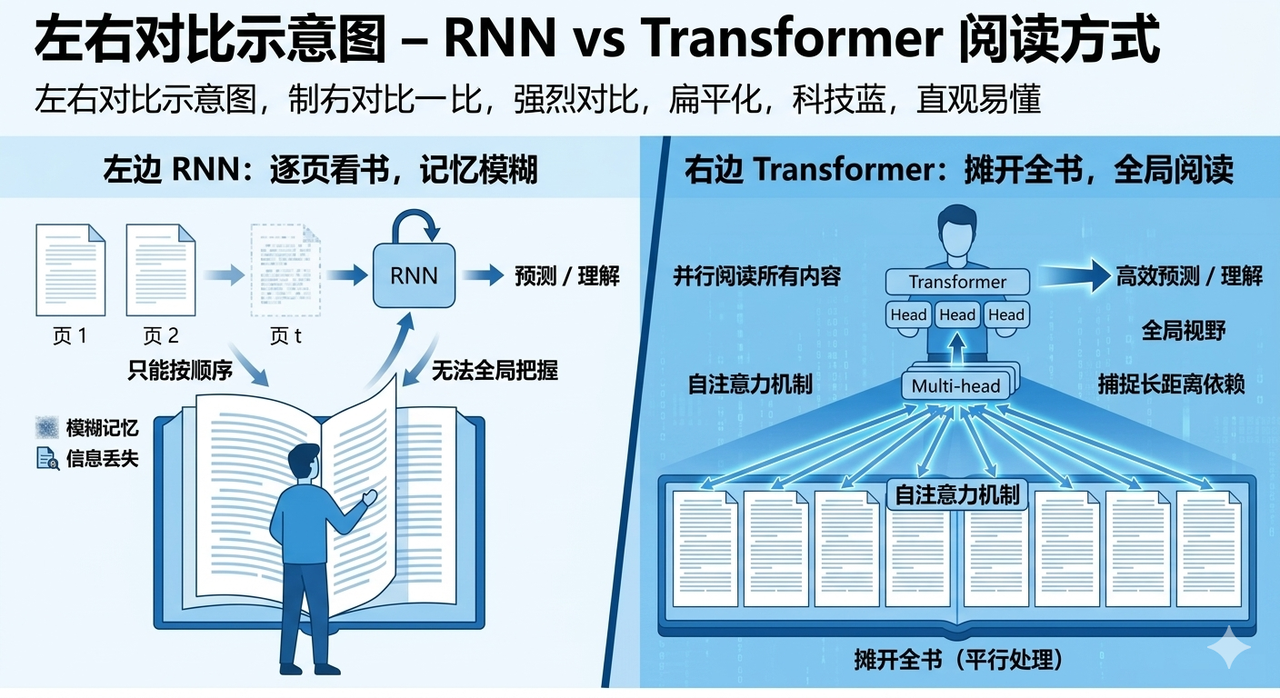
但随之而来的问题是:同时出现的这些词,怎么知道彼此之间谁和谁更相关?
这就是自注意力机制(Self-Attention)要解决的事。
自注意力:每个词召开的”内部研讨会”
我用一个场景来解释自注意力。
想象一场公司内部研讨会,主题是”重新理解每个人在这个团队中的角色”。
每个人都要做三件事:
- 提出自己的问题(Q,Query):”我需要从这个团队中获取什么信息来重新定义自己?”
- 展示自己的标签(K,Key):”我能提供什么?我的专长标签是什么?”
- 准备自己的内容(V,Value):”如果有人真的觉得我和他相关,他能从我这里获取的具体内容是什么?”
每个人拿着自己的”问题(Q)”,去和在场所有人的”标签(K)”一一比对:你的标签和我的问题有多契合?契合度高的人,在我心里的”权重”就高。
最后,每个人把所有人的”内容(V)”,按照权重加权求和——权重高的人贡献更多,权重低的人贡献更少——得到一个新的自我表示。
这个新的自我表示,已经融合了整个团队的上下文信息。
翻译回语言处理:句子里的每个词,都和其他所有词计算了一遍关联度,然后根据关联度的强弱,重新定义了自己在这个语境下的含义。
这就是为什么 Transformer 能处理长距离依赖——”cat”和几十个词之后的”fell”,在自注意力的计算里,它们之间的关联可以被直接建立,不需要通过中间所有词”接力传递”。
多头注意力:同时开多场研讨会
理解了自注意力之后,多头注意力(Multi-Head Attention)就很容易懂了。
单次自注意力,是大家在同一个维度上讨论问题。但语言是多维度的:一句话同时包含语法关系、语义关联、指代关系、情感倾向……
多头注意力的做法,是同时开多场侧重点不同的研讨会。
第一场关注语法,第二场关注语义,第三场关注”这里的’它’到底指代谁”……每场研讨会独立进行,最后把所有场次的结论综合起来,形成对这句话更立体、更丰富的理解。
这就是”多头”的含义——多个注意力”头”,并行捕捉不同维度的关联。
位置编码:给思维注入秩序
但等一下,有个问题。
既然所有词都是同时进入处理的,模型怎么知道”狗咬人”和”人咬狗”是不同的两句话?
并行处理的代价,是天然丧失了对位置顺序的感知。
Transformer 的解决方案,叫位置编码(Positional Encoding)。
在把每个词送入模型之前,给它打上一个”位置坐标”——这是第1个词,这是第2个词,这是第17个词……这个位置信息被编码成一段数字,和词本身的语义信息叠加在一起,送进模型。
模型因此同时知道”这个词是什么意思”和”这个词在什么位置”。
“狗”在第一位和”狗”在第三位,对模型来说,这是两个不同的输入——尽管词是同一个词。
顺序感,就这样被”外挂”式地注入了并行处理的系统。
大厦的地基:残差连接与层归一化
Transformer 不只有注意力机制,还有两个让整个架构能”做深”的工程设计。
残差连接(Residual Connection),说白了是一句提醒:”不管你做了多少复杂的变换,别忘了你的出发点是什么。”
每一层处理完之后,把这一层的输出和这一层的输入直接相加,确保原始信息不会在层层变换中被丢失。这个设计让梯度能顺畅地流回早期层,是 Transformer 能堆到几十层甚至上百层的关键。
层归一化(Layer Normalization),则像是每一层处理完之后,把数据”整理一下队形”——让各层的数据分布保持稳定,不要出现某些数值爆炸、某些数值消失的情况。它让训练过程更平稳,收敛更快。
这两个设计,是支撑 Transformer 这座”思维大厦”能稳稳建高的地基。
双生引擎:编码器与解码器的分工哲学
理解了注意力机制,下一个问题是:这些机制是怎么组合在一起,干不同的活的?
答案就在 Transformer 的两个核心组件里:编码器和解码器。
编码器:全知全能的”复盘者”
编码器的任务,是极致理解。
给它一段输入文本,它用双向的自注意力——同时看前文和后文——把整段文本的含义压缩成一套富含上下文的向量表示。
打个比方:编码器像一个做完了整个项目、拿着全部资料坐下来复盘的人。他不是在读第一份文件的时候就开始输出结论,他是在看完所有材料之后,才对每一份文件的意义形成完整判断。
这种”全知全能”的视角,让编码器非常擅长深度理解类任务:
- 这句话是什么情感倾向?
- 这段文本里,哪个空格应该填什么词?
- 这两句话,意思是相同的还是矛盾的?
BERT,就是一个纯编码器架构的代表模型。Google 用它刷新了 NLP 领域几乎所有的基准测试,因为它能真正”理解”输入文本的深层含义。
解码器:严守因果的”即兴演讲者”
解码器的任务,是序列生成。
但它有一个严格的限制:在生成第 N 个词的时候,它只能看到已经生成的前 N-1 个词,绝对不能偷看后面还没生成的内容。
为什么有这个限制?因为在真实的生成场景里,后面的词本来就还不存在——模型在逐字生成,每一步只能基于已有的历史。允许它”偷看未来”,训练时是在作弊。
这个限制,在技术上通过掩码注意力(Masked Attention)实现——强制把未来的词遮住,让模型看不到。
想象一个戴着眼罩、只能看到左边的即兴演讲者。他不知道自己下一句会说什么,只能根据已经说过的话,一个词一个词地往下走。但他依然能讲出逻辑流畅的故事——因为他在每一步都在做最合理的下一步预测。
GPT 系列,就是纯解码器架构的代表。ChatGPT 背后的逻辑,本质上就是一个被训练得极其强大的”下一个词预测器”。每次它给你回复,都是在反复问自己:”基于到目前为止的所有内容,下一个最合理的词是什么?”
编码器-解码器:专业的”翻译官”
当编码器和解码器组合在一起,就形成了最初 Transformer 论文里的完整架构。
工作流程是这样的:编码器先读懂整个源序列(比如一句中文),生成一套完整的理解表示;然后解码器拿着这套理解,在它的指导下,一个词一个词地生成目标序列(比如对应的英文翻译)。
解码器在每一步生成时,不只看已生成的词,还会通过交叉注意力(Cross-Attention)向编码器的输出”询问”:源序列里,哪些信息和我当前生成的这个词最相关?
这是一种真正意义上的”先理解,再表达”。
T5、BART 是这一架构的代表。它们擅长的任务,都是需要”精确转换”的:机器翻译、文本摘要、问答系统……先把源语言吃透,再用目标语言精确表达出来。
范式溢出:从语言到万物序列
说到这里,Transformer 的核心逻辑已经讲清楚了。
但我觉得真正让这个架构变得不同凡响的,不是它在语言领域有多强,而是它背后隐藏的一个更深的洞见:
Transformer 的本质,是处理”序列关系”。而数学上,万物皆可表示为序列。
一旦你接受这个视角,它的应用边界就开始以你意想不到的速度扩展。
图像:把一张照片”读”成一段文字
2020 年,Google 提出了 Vision Transformer(ViT),做了一个听起来有点奇怪的事:
把一张图片切成 16×16 像素大小的小块,把这些小块按顺序排列,然后用完全相同的 Transformer 架构来处理它们。
每个小块,就像一个”词”。整张图片,就变成了一个”句子”。
结果,这个思路在大规模图像分类任务上,打败了此前统治图像领域十年的 CNN 架构。
哎,这件事有点意思——不是说 CNN 不好,而是说 Transformer 这套”注意力”逻辑,比我们以为的适用范围广得多。它处理”狗”和”猫”之间的语义关系,和处理图像左上角与右下角之间的空间关系,用的是完全相同的数学结构。
蛋白质:解开生物学半个世纪的谜题
这个应用案例,我觉得是 Transformer 溢出语言领域之后,影响最为深远的一个。
蛋白质由氨基酸链组成。给定一条氨基酸序列,它在三维空间里会折叠成什么形状?这个形状决定了蛋白质的功能,也是药物设计、疾病研究的核心基础。
这个问题,生物学家研究了 50 年,一直没有可靠的计算预测方法。
AlphaFold 2 的核心,正是把氨基酸链当成一个序列,用 Transformer 的注意力机制来学习氨基酸之间的空间关联——哪两个氨基酸在三维空间里彼此靠近,哪些区域会形成螺旋结构。
它的预测精度,直接达到了实验测量的水平。
科学界把这个突破称为”50年来最重大的生物学进展之一”。
一个原本为翻译语言设计的数学框架,解开了生物学半个世纪的谜题。这件事本身,就足够让人沉默一会儿。
更大的图景
今天,Transformer 或其变体,已经出现在代码分析、音频生成、视频理解、分子设计……几乎所有你能想到的 AI 应用领域。
我觉得这不只是”一种技术很好用”的故事。它在说明:我们可能找到了一种足够底层的数学语言,能够描述不同模态数据之间的”关系结构”。
语言是关系。图像是关系。蛋白质的空间结构是关系。
一切都是关系,而 Transformer,正是一台处理关系的机器。
革命的代价与未来的曙光
没有任何革命是免费的。
Transformer 带来了范式跃迁,也带来了两个巨大的代价。
数据饥渴与算力黑洞
数据饥渴。
Transformer 的能力,来自在海量数据上的预训练。GPT-3 的训练数据量,超过 4500 亿个 Token,差不多是整个可索引互联网文本的一个相当大的切片。
更令人担忧的是,随着数据规模的增加,模型会出现所谓的”涌现能力”——一些新的能力在某个规模阈值之后突然出现,而不是线性增长。这意味着,要获得质变,你必须先撑过一个巨大的量变。
这本身就是一种垄断性壁垒。能获取、清洗、处理互联网级数据的组织,全球屈指可数。
算力黑洞。
训练 GPT-4 级别的模型,据估算花费超过 1 亿美元,消耗的电力可以支撑一个小城市运转数周。
“人人都能训练大模型”——这句话,在今天的 Transformer 架构下,几乎是一个笑话。算力的集中,正在把 AI 的前沿研究,锁进少数几家超级公司的高墙里。
架构在演进,瓶颈在松动
好在,这个领域从来不缺聪明人在想办法。
混合专家(MoE)架构,是目前最主流的效率突破方向。核心思路是:不要让所有参数都参与每一次计算,而是把模型分成很多”专家组”,每次只激活其中少数几个与当前任务最相关的专家。
DeepSeek V3 是这个方向上的一个里程碑案例——用相对更少的激活参数,支撑了千亿级的模型总参数量,把训练成本打下来了一个数量级。
注意力机制的优化,则在解决另一个瓶颈:长序列的内存和计算开销。标准的自注意力,计算量随序列长度的增长是平方级的——序列翻倍,计算量变成四倍。MLA(多头潜在注意力)、滑动窗口注意力等技术,在试图把这个增长曲线压平。
还有更激进的新架构探索。Mamba 等状态空间模型(SSM),试图在保持 Transformer 建模能力的同时,把长序列处理的复杂度降到线性级别。目前它和 Transformer 的混合架构,已经在一些任务上展现出令人期待的潜力。
这些努力的方向,都指向同一个目标:让强大的模型,不再只是少数人的玩具。
一个值得认真对待的观点
我想在这里放一个有点颠覆性的视角。
我们今天谈论的很多 AI 应用范式——RAG(检索增强生成)、Agent(智能体)、各种工具调用框架——它们本质上是什么?
是在弥补当前模型能力的不足。
RAG 是因为模型的上下文窗口不够大、记忆不够长;Agent 框架是因为模型单步推理能力有限,需要把任务分解成多步;工具调用是因为模型没有实时访问外部信息的能力……
这不是批评这些技术——它们在今天的条件下,是聪明而必要的工程解法。
但它意味着:随着 Transformer 及其后继者的基础能力不断增强,这些上层建筑的形态,会持续演变,甚至某些会消失。
当模型的上下文窗口扩展到足够长,当推理能力强到某个阈值,今天我们认为理所当然的很多应用范式,可能会被重写。
这不是坏事。这就是基础能力提升之后,整个生态重新排列组合的样子。
尾声:理解这个时代的语法
1665 年,牛顿发现了万有引力。
此后两百多年,无论是计算行星轨道、设计桥梁,还是理解潮汐涨落,物理学家用的都是同一套数学语言——因为它足够底层,能描述足够多的现象。
我有时候在想,Transformer 是不是正在扮演类似的角色。
不是因为它完美,而是因为它触碰到了某种更底层的东西:用”关系强度”来动态定义意义,用”全局关联”来代替”顺序记忆”。这套逻辑,在语言里成立,在图像里成立,在蛋白质里成立,在代码里成立。
当一种架构能同时理解语言、图像、蛋白质折叠和音乐节奏,我们是否正在接近某种统一的智能语法?
我不知道答案。
但我觉得,在这个 AI 正在重写几乎所有行业规则的时代,理解 Transformer 在做什么,不应该是工程师的专利。
它是我们这个时代的元模型。
理解它,就是理解这个时代的语法。
本文由 @酸奶AIGC 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


