
 起点课堂会员权益
起点课堂会员权益通用大模型写不好分镜脚本,所以我决定自己精调一个
通用大模型的分镜脚本生成总差一口气?揭秘AI漫剧创作的模型精调实战!从镜头语言缺失到格式混乱,作者亲历从选模型、造数据到效果优化的完整闭环,用开源模型+高质量数据突破Prompt Engineering天花板,带你看懂如何让AI真正学会用镜头讲故事。

上一篇我聊了这个项目的起点——用户输入一句话,AI 自动生成一套完整的漫剧分镜脚本。
有读者留言说想看更多技术层面的东西。这期就来聊一个很多产品经理都听过、但大部分人不太敢碰的话题:模型精调(Fine-tuning)。
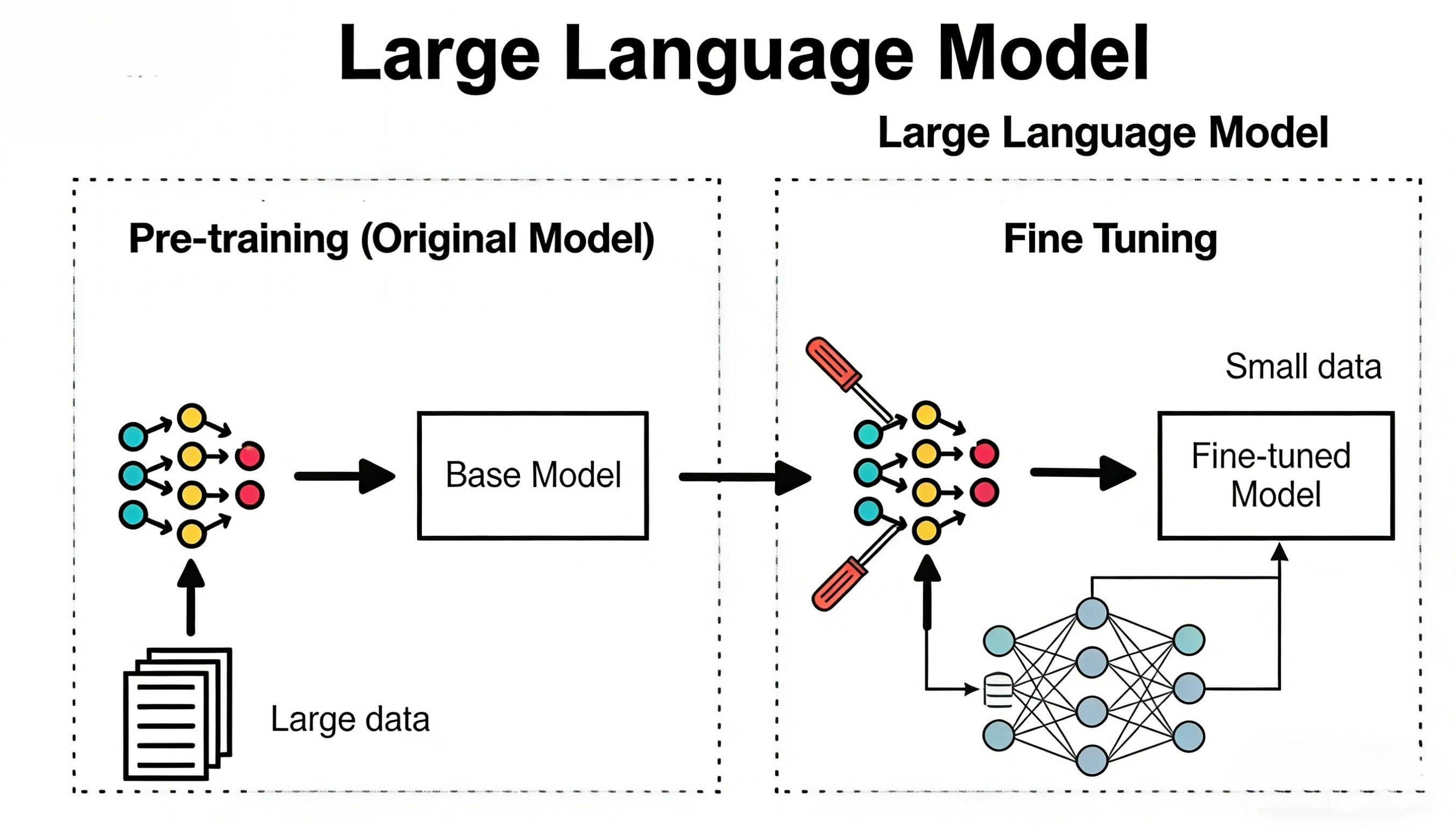
我会从”为什么要精调”讲起,聊聊我从选模型、造数据到踩坑的整个过程。这篇先把全貌拉通,后面几期会挑其中几个点单独展开深聊。
通用大模型到底差在哪?
在做精调之前,我其实已经用通用大模型(比如 GPT-4、Claude、通义千问)跑了很长一段时间。
效果怎么说呢?”能用,但不好用。”
具体来说,通用大模型在写分镜脚本这件事上,有几个让我非常头疼的问题。
第一,分镜拆分的”镜头感”很弱
一个好的分镜脚本,本质上是在用文字做”导演”的活——什么时候该给远景交代环境,什么时候该切特写强化情绪,什么时候需要一个中景来交代人物关系。这种镜头语言的节奏感,通用模型几乎没有。
它会把故事均匀地切成 N 段,每段的”镜头”基本都是中景。没有远近交替,没有情绪起伏,读起来像流水账。
举个例子,我输入”一个女生下雨天在便利店遇到了初恋”,通用模型的输出大致是这样的:
画面1:女生走在雨中的街道上。
画面2:女生走进便利店。
画面3:女生在货架前看到一个熟悉的身影。
画面4:两人对视。 画面5:两人开始交谈。
每一个画面都是平铺直叙,没有镜头设计。而一个有经验的分镜编剧可能会这样处理:
分镜1 | 远景:雨幕中的便利店,暖黄色灯光从玻璃门透出,一个撑伞的女生身影正朝着光走来。
分镜2 | 特写:女生的手合上雨伞,水珠顺着伞面滑落,指尖微微发红。
分镜3 | 过肩镜头:女生穿过货架时,镜头越过她的肩膀,捕捉到三排货架之外、一个男生侧脸的轮廓。
分镜4 | 双人中景:两人隔着一排饮料货架对视,女生手里的关东煮冒着热气,虚化的背景是便利店的日光灯。
差距一目了然。前者是”把故事切成几段”,后者是”用镜头讲故事”。
第二,画面描述不够”生图友好”
分镜脚本的最终用途是喂给 AI 生图工具。这意味着画面描述必须足够具体、足够视觉化——你不能写”两个人在聊天”,你需要写出人物的姿态、表情、穿着、光线、构图方式。
通用模型写出来的东西,常常太抽象、太文学化,读起来像小说,但放到 Stable Diffusion 或者 Midjourney 里生不出想要的画面。
第三,输出格式不稳定
我需要模型输出结构化的分镜脚本——包含镜头编号、景别、场景描述、画面描述、旁白文案等字段。通用模型有时候格式对,有时候又开始自由发挥,加一些不需要的解释性文字,或者把字段顺序搞乱。这对下游的自动化处理是致命的。
这三个问题叠加在一起,让我意识到一件事:靠 Prompt Engineering 能解决 70% 的问题,但剩下的 30% 是通用模型的能力边界,prompt 写得再好也过不去。
这就是我决定做精调的原因。
什么是精调?先把概念讲清楚
“精调”这个词在 AI 圈子里被用得很泛,我先给产品经理们做一个通俗但准确的解释。
你可以把一个预训练好的大模型想象成一个刚从综合大学毕业的新员工。他什么都懂一点——能写文章、能翻译、能写代码、能聊天——但在任何一个专业领域都不够精。
精调就是给这个新员工做岗前培训。
你不需要从头教他认字、学语法,那些通识能力他已经有了。你要做的是给他看大量的”好例子”——在我这个场景下,就是大量优秀的分镜脚本——让他学会:原来分镜脚本应该这样写,镜头应该这样切,画面应该描述到这个粒度。
从技术上说,精调就是在一个已有的大模型基础上,用你自己的专业数据集继续训练,让模型在你的特定任务上表现得更好。
这里有几个关键词需要区分:
- 预训练(Pre-training) 是从零开始训练一个模型,需要海量数据和算力,花费数百万甚至上亿美元。这不是我们要干的事。
- 精调(Fine-tuning) 是在已有模型基础上,用少量专业数据做进一步训练。成本低得多,几百到几千条数据就可以看到效果。
- Prompt Engineering 是不改模型本身,只通过设计输入提示词来引导模型输出。零成本,但有天花板。
三者的关系可以这样理解:Prompt Engineering 是”跟员工说清楚需求”,精调是”培训员工”,预训练是”培养一个新人”。大多数情况下你应该先试 Prompt Engineering,不够了再考虑精调。
选择基座模型:我是怎么做决定的
精调的第一步是选择一个基座模型(Base Model)——也就是你要在谁的基础上继续训练。
我最终选择的是开源模型路线。原因很现实:
- 成本可控。 闭源模型的精调(比如 OpenAI 的 Fine-tuning API)虽然用起来简单,但按 token 计费,数据量一上去费用不低。而且每次调参都要烧钱,不适合反复实验。开源模型你可以本地跑(如果有卡的话),或者用云端 GPU 按时计费,整体灵活得多。
- 可控程度高。 开源模型能让你深入到训练的每一个环节——学习率、训练轮数、数据配比……你能精确控制整个过程。闭源 API 精调更像一个黑箱,你把数据传上去,它给你一个模型,中间发生了什么你不太知道。
- 迭代效率高。 做精调不是一次就能成的,你需要反复调整数据、参数、评估效果、再调整。开源模型让你能快速跑实验,一天可以试好几个版本。
在具体选哪个开源模型上,我对比了几个主流选项:
- Qwen(通义千问) 系列是阿里开源的模型,中文能力强,社区活跃,文档完善。对中文分镜脚本这种场景来说,天然的中文理解能力是很大的加分项。
- GLM(智谱) 系列也是国内团队出的,中文表现同样不错,工具链比较成熟。
- LLaMA(Meta) 系列是目前全球最流行的开源模型之一,生态最丰富,各种精调工具和教程都是基于它做的。但它原生是英文模型,中文能力需要额外适配。
我最终的选择逻辑是:先看中文能力,再看生态和工具链。 因为我的场景是生成中文分镜脚本,模型对中文的理解能力是第一优先级。如果一个模型中文都说不好,你精调再多数据也很难让它写出好的中文描述。
具体选了哪个、为什么、中间怎么评估的,这个话题展开来能聊很多,我打算后面单独写一篇详细讲。
训练数据:精调的成败关键
做过精调的人都知道一句话:数据质量决定精调效果的 80%。
模型的基础能力已经很强了,精调不是在教它”学会说话”,而是在教它”怎么说这种话”。你给它看的示例,直接决定了它学会的”说话方式”。
这就带来一个很现实的问题:高质量的分镜脚本数据从哪来?
市面上并没有一个现成的”分镜脚本数据集”可以直接拿来用。你搜不到的。短视频行业虽然体量巨大,但分镜脚本这种东西要么是内部文件不对外,要么质量参差不齐。
所以我走的是自己构造数据的路线。
大致的思路是这样的:
第一步:建立”好脚本”的标准。 在造数据之前,你得先定义清楚什么是好的分镜脚本。我从镜头设计、画面描述精度、叙事节奏、格式规范这几个维度列了一套评价标准。这一步很多人会跳过,但其实它决定了你后续所有数据的质量上限。
第二步:用”人工 + AI”的方式批量生产。 纯手写效率太低,纯 AI 生成质量不够。我的做法是先用一个强模型(比如 Claude 或 GPT-4)根据我设定的规则生成初稿,然后人工逐条检查、修改、筛选。通过的留下,不通过的要么修改要么扔掉。
第三步:多样性比数量重要。 我发现一个反直觉的规律——500 条覆盖不同故事类型、不同情绪、不同镜头风格的数据,效果远好于 2000 条同质化的数据。模型需要的是”丰富的好例子”,不是”大量重复的例子”。
第四步:数据格式要严格。 精调数据本质上是一组”输入-输出”的配对。输入是用户的一句话描述,输出是完整的分镜脚本。格式必须统一且严谨,任何格式不一致都会让模型学到”错误的习惯”。
这套数据构造的方法论,我后面会单独写一篇展开讲,包括具体怎么设计 prompt 让 AI 生成高质量初稿、人工审核的 checklist 长什么样、数据量和效果之间的关系曲线等等。
精调前 vs 精调后:效果对比
说了这么多,最实在的还是效果。
同样的输入:”一个退休教师收到学生们写的一封信”,来对比一下精调前后的输出差异。
精调前(通用模型 + Prompt Engineering):
画面1:一位老人坐在家中的沙发上。
画面2:门铃响了,老人去开门。
画面3:门口放着一封信。
画面4:老人打开信,开始阅读。
画面5:老人的眼眶湿润了。
画面6:老人看着窗外,陷入回忆。
精调后:
分镜 1 | 远景 | 客厅 午后的阳光透过纱帘洒进一间朴素的客厅,墙上挂着几张泛黄的班级合照。一位头发花白的老人坐在木质摇椅上,膝盖上摊着一本翻了一半的书,眼镜滑到了鼻尖。 旁白:退休第三年,日子像那本书一样,翻到哪页都差不多。
分镜 2 | 中景 | 玄关 老人站在门口,低头看着脚边的一个牛皮纸信封。信封上没有寄件人地址,只有用黑色马克笔写的三个字——”周老师”。老人弯腰捡起信封,手指在封口处停顿了一下。 旁白:这个称呼,我已经很久没有听到了。
分镜 3 | 特写 | 手部 一双布满皱纹的手缓缓展开信纸,纸上密密麻麻的字迹——有工整的钢笔字,也有歪歪扭扭的圆珠笔字,有些段落旁边还画着小表情。阳光照在纸面上,映出不同颜色墨水的深浅。 旁白:二十七个人的笔迹,我居然每一个都还认得出来。
分镜 4 | 近景 | 面部 老人的脸部特写,眼镜片后面泛着泪光,但嘴角是往上扬的。背景虚化成一片暖黄色的光斑。 旁白:(无,留白)
差异体现在几个层面:
- 镜头设计上, 精调后的版本有明确的远景→中景→特写→近景的递进关系,而不是六个平行的”中景”。
- 画面描述上, 精调后每个画面都有足够的视觉细节——”牛皮纸信封””黑色马克笔””不同颜色墨水的深浅”——这些细节是生图工具需要的”燃料”。
- 叙事节奏上, 精调后懂得用”留白”制造情绪——最后一个分镜旁白留空,让画面本身说话。这种”导演式”的思维,是通用模型学不会的。
- 格式上, 精调后的输出严格遵循”镜头编号 | 景别 | 场景”的结构,不会出现格式混乱的问题。
精调过程中踩过的坑
精调听起来很美好,但实际操作中坑不少。这里先分享几个最典型的,后续会单独写一篇完整的”踩坑指南”。
坑一:数据太少,模型过拟合。
一开始我只准备了不到 100 条数据就开始训练,结果模型确实”学会了”——但学得太死了。它开始逐字复制训练数据里的描述,换个输入还是那几句话的变体。这就是过拟合:模型不是在”理解”规律,而是在”背”答案。
解决办法很简单也很痛苦:补数据,增加多样性。
坑二:学习率设太高,把模型”教废了”。
精调的学习率(Learning Rate)如果设太高,模型会在你的小数据集上”剧烈震荡”,反而把原来会的东西也忘了。有一次我设了一个偏高的学习率,结果模型连正常对话都不会了,只会输出分镜脚本格式的内容——你问它今天天气怎么样,它也给你一个”分镜1 | 远景 | 天空”。
坑三:评估标准不清晰,调了半天不知道有没有进步。
精调不像分类任务有一个明确的准确率指标。分镜脚本的”好”和”不好”很多时候是主观判断。一开始我没有建立清晰的评估体系,每次训练完都是凭感觉看效果,结果经常出现”好像比上次好了?又好像没有?”的迷茫。
后来我建了一套评测集——固定 30 个输入,每次训练完跑一遍,从镜头多样性、描述精度、格式准确率、叙事流畅度四个维度打分。有了量化标准之后,迭代效率立刻上了一个台阶。
给产品经理的几点建议
写到这里,我想给正在看的产品经理们几点实际建议:
第一,不要一上来就想着精调。 Prompt Engineering 能解决的问题,就不要动精调。精调的时间成本和技术门槛远高于写 prompt。先把 prompt 优化到极致,确认确实过不去了,再考虑精调。
第二,精调的核心不是”训练技术”,而是”数据质量”。 很多人觉得精调很难,其实训练本身有大量现成的工具和教程,门槛没那么高。真正难的是构造出高质量的训练数据。如果你的数据质量不行,用再好的训练框架也白搭。
第三,精调不是一锤子买卖。 不要期望一次精调就得到完美的模型。它是一个”数据→训练→评估→改数据→再训练”的循环过程。建立清晰的评估标准、保持快速迭代的能力,比追求一步到位重要得多。
第四,开源模型的门槛在降低。 两年前做精调可能确实需要比较强的技术背景,但现在有大量的工具(像 LLaMA-Factory、Swift 等)把流程简化了很多。产品经理未必需要自己动手,但至少应该理解这个过程,这样和技术团队沟通时才能做出合理的判断。
下一步预告
这篇我把精调的全貌拉了一遍——为什么要做、基座怎么选、数据怎么造、效果怎么样、踩了什么坑。
接下来几期,我会从这里面挑几个点深入展开:
- 训练数据的构造方法论:怎么从零建立一个高质量数据集?”人工 + AI”的工作流具体是什么样的?
- 基座模型的选择与对比:我实际测试了哪些模型?它们在中文分镜脚本场景下的表现差异有多大?
- 精调踩坑完全指南:过拟合、灾难性遗忘、数据泄漏……那些精调路上的经典陷阱
同时,后面还会聊到图像生成的部分——分镜脚本有了,配图怎么搞?Nana Banana 和国产生图模型之间有什么区别?
我们下期见。
本文由 @zNONOz 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


