
 起点课堂会员权益
起点课堂会员权益一个真实的智能客服RAG,数据准备到检索链路完整拆解
当智能导购系统遇上千款香水SKU的复杂场景,RAG技术的每个决策环节都可能成为用户体验的致命短板。本文深度拆解从数据切分到精排优化的全流程实战经验,揭秘为何用户一句'夏天不想太甜'的简单需求,会因chunk切分策略和question反向生成机制而引发连锁反应。

假设你是一个产品经理。
你们公司是一家香水电商,SKU 上千,从大牌到小众品牌都有。最近要上线一套智能导购——不只是答疑,还要能主动推荐。用户说”我想买一瓶夏天用的香水”,导购要能给出靠谱建议;说”迪奥真我和祖玛珑蓝风铃有什么区别”,要能准确回答;说”男生送女生什么香比较不出错”,也要能接住。
技术团队搭完 RAG 系统,来找你验收。
你开始测:
- 问“夏天适合什么香”——返回了一堆花香调的通用介绍,大模型用这些内容生成了一段像在背品类百科的回答,没有具体推荐,也没有提到季节适配性
- 问“迪奥真我 EDP 100ml 的价格”——型号对了,但价格是半年前的旧数据
- 问“有没有不甜的花香”——返回说“未找到相关内容”
- 搜“狄奥旷野”(把“迪”打成了“狄”)——同样返回“未找到相关内容”

你问技术:”是哪里出了问题?”
技术说:”可能是 Top-K 设小了,也可能是相似度阈值设太高把结果过滤掉了,也可能要加 Reranker,也可能是数据没处理好。”
四个可能,从哪查起?
这篇从头到尾走一遍,把一个真实的智能导购 RAG 完整链路拆给你看。不是调参手册,是让你知道每个环节在做什么决策,以及决策错了会在哪里出问题。
先把整条链路过一遍
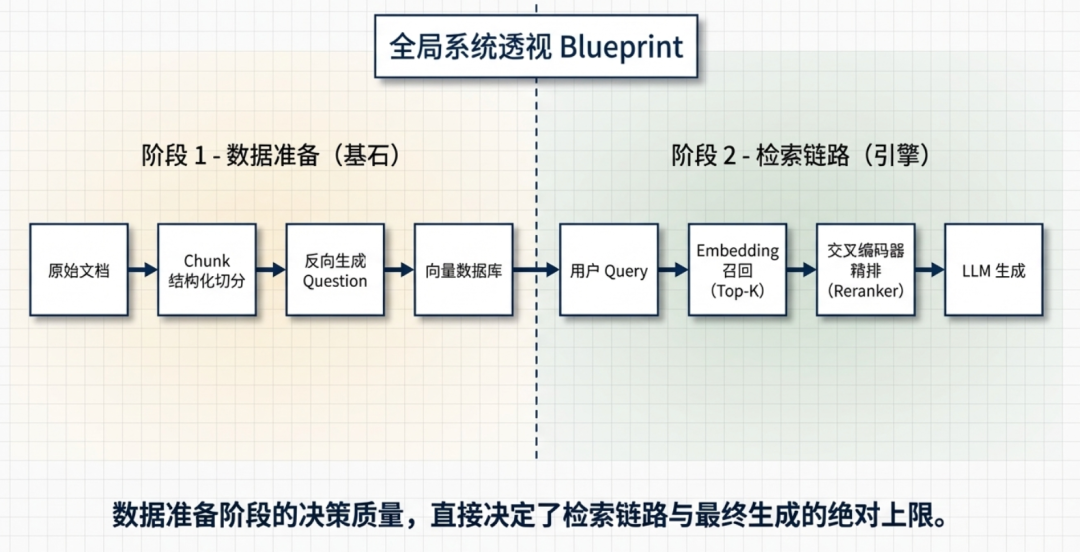
在拆细节之前,先建一张全局图。
一个真实的智能导购 RAG,分两个阶段:
━━━━━━━━━━━━━━━━ 数据准备阶段(提前做好,数据更新时重做)━━━━━━━━━━━━━━━━
原始知识库(产品手册、品牌百科、香调指南)
↓
① 按标题层级切 chunk
↓
② 每个 chunk 用大模型反向生成 5 个用户可能问的 question
↓
③ question + chunk 一起入向量库
━━━━━━━━━━━━━━━━ 查询阶段(用户每次提问都走)━━━━━━━━━━━━━━━━
用户提问
↓
④ 向量化(bge-m3)
↓
⑤ 召回 Top-K 个最近邻 question
↓
⑥ 通过 question 找回对应的 chunk 原文
↓
⑦ Reranker 精排,取 Top-5
↓
⑧ 把 Top-5 的 chunk 原文喂给大模型
↓
生成最终回答
这条链路里有很多决策点。我们从最上游开始拆。
数据准备:切错了,后面全白搭
很多人搭 RAG 的时候,把大量精力放在调检索参数上,却忽略了一件事:
数据准备阶段的决策质量,直接决定了后面所有环节的上限。
怎么切 chunk
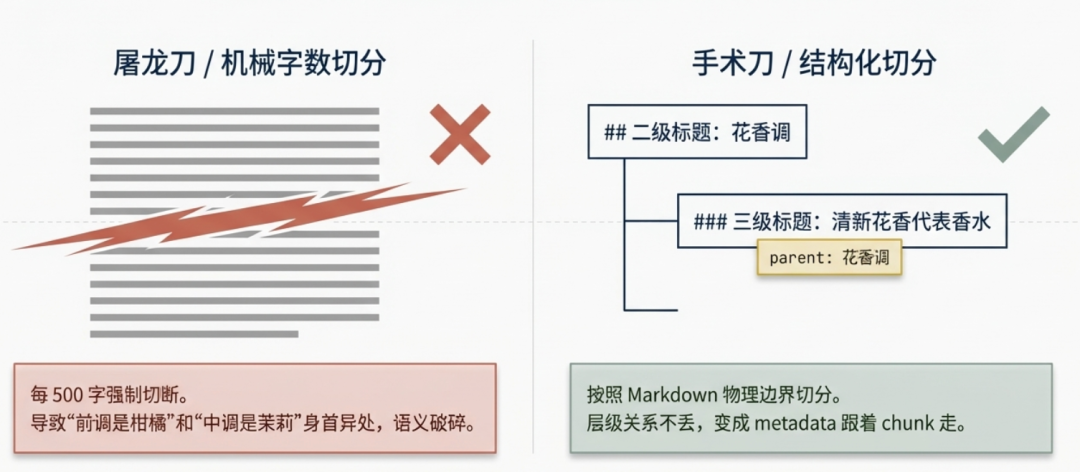
最直觉的切法是按字数切:每 500 个字切一刀,超了就断。
很多框架默认也是这种切法,不做任何设置的话大模型给你的就是这个。
这个切法的问题是它只管字数,不管语义。一段介绍香水前中后调的内容可能被切成两半,”前调是柑橘”在一个 chunk,”中调是茉莉”在另一个 chunk——两个 chunk 单独拿出来都不完整,检索出来的结果天然就是碎的。
更好的切法是按文档结构切,也就是按 Markdown 标题层级:
# 香水品类百科(忽略,太大)
## 花香调 ← 切一个 chunk
### 清新花香代表香水 ← 切一个 chunk
### 浓郁花香代表香水 ← 切一个 chunk
## 东方调 ← 切一个 chunk
### 东方调适合什么场合 ← 切一个 chunk
## 香水浓度指南 ← 切一个 chunk
### EDP vs EDT 有什么区别 ← 切一个 chunk
## 是二级标题,### 是三级标题,每个标题下的内容天然是一个独立的知识点。这样切出来的每个 chunk,内部主题是统一的,不会出现”前半段讲花香调,后半段讲使用方法”的情况。
这里经常有人问:三级标题不是在二级里面吗,为什么要分开切?
因为切分的判断标准不是”这个标题在第几级”,而是”这段内容能不能独立回答一个问题”。## 花香调 讲的是这个大类是什么,### 清新花香代表香水 讲的是具体推荐哪些——两段内容回答的是不同的问题,就应该是不同的 chunk。层级关系不丢,变成 metadata 跟着 chunk 走,但内容本身要独立。
具体操作上,## 的 chunk 只包含它自己那段正文,不往下吞 ### 的内容:
## 花香调
以花卉香气为主的香水大类,分清新和浓郁两种风格……
↓ chunk A(只有这段正文)
### 清新花香代表香水
祖玛珑青柠罗勒、宝格丽绿茶……适合夏天……
↓ chunk B
### 浓郁花香代表香水
香奈儿5号、迪奥真我……适合秋冬正装场合……
↓ chunk C
chunk B 和 chunk C 的 metadata 里记着 parent: 花香调,层级关系没有丢,只是不混在同一个 chunk 里。需要往上追溯的时候,通过 metadata 找得到。
这不只是格式问题,是语义完整性的保障。
chunk 不能切太大
bge-m3 是这套链路里负责把文本转成向量的 Embedding 模型——chunk 入库的时候要过它一遍,用户提问的时候也要过它一遍。
chunk 太大会出两个问题。
第一个是工程上的:在本地测试的时候,chunk 切得比较粗,有些块包含了整个二级标题下的所有内容,token 数达到两三千,直接 OOM,模型跑不动。bge-m3 的理论上下文上限是 8192 个 token,但这是上限,不是建议值。chunk 越大,内存压力越高,推理越慢。而且 bge-m3 超限有时只是悄悄截断,向量质量变差了你可能都察觉不到,排查起来很隐蔽。
第二个更要命:语义过长之后,向量对”这段内容到底在说什么”的表达能力会下降。一个 chunk 里同时讲了春夏秋冬四个季节的推荐,向量只能把它压缩成一个”花香调综述”的模糊表示——用户问”夏天适合什么”,这个向量能召回,但召回之后下游不知道该摘哪段,回答质量就塌了。
经验值:chunk 控制在 300-500 token 是比较安全的范围。产品知识库这类场景,一个三级标题下的内容通常在 450-700 字符左右,换算成 token 基本落在这个区间内。偶尔遇到确实偏长的,再手动拆一层就好。
chunk size 是整条链路最上游的决策。切错了,后面加再多的精排也补不回来。
我们做 demo 的时候就踩过这个坑——最初按二级标题切,把”花香调”整个板块作为一个 chunk 入库,token 数接近 2000。上线测试后发现:用户问”有没有适合夏天的玫瑰香”,这个大 chunk 确实被召回了,精排也给了高分,但它里面同时涵盖了春夏秋冬所有季节的推荐,大模型拿到之后不知道该摘哪段,生成的回答东一句西一句,像在念目录。后来把切分粒度细化到三级标题,每个 chunk 只讲一个具体品类,平均 token 数控制在 400 左右,同样的问题直接命中了”清新花香·夏季推荐”那个 chunk,回答质量明显提升。问题不是检索判断错了,是喂进去的 chunk 本身主题太散。
为什么要反向生成 question
切好 chunk 之后,还有一个容易被忽略的问题:
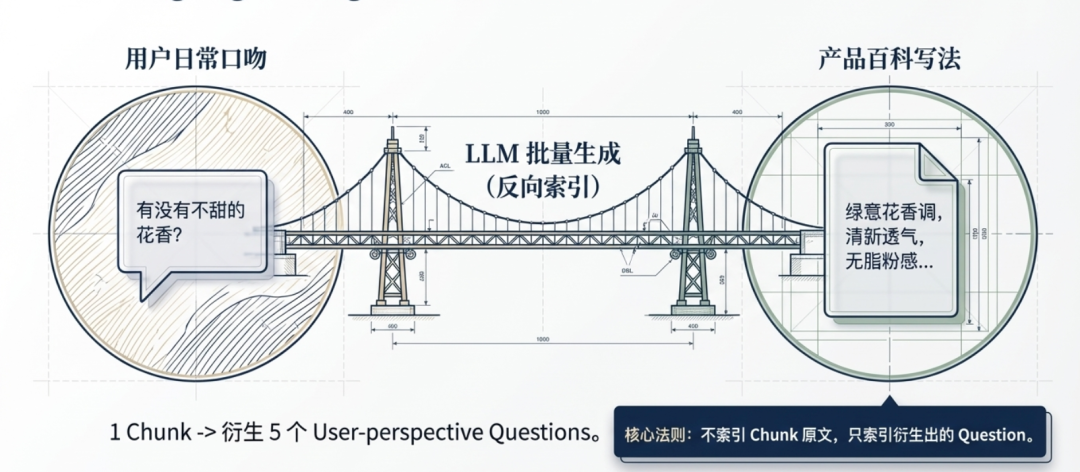
用户说话的方式,和知识库里写的方式,天然不在同一个语言空间里。
举个例子:
用户说: “有没有那种夏天用的,闻起来清爽不腻的香水?”
文档写: “柑橘调和水生调香水,挥发性高,适合高温季节使用,清新透气,不易产生厚重感。”
意思是一回事,但说话方式完全不同。如果直接用向量检索,用户这句口语和文档里的描述,向量算出来的相似度分数会偏低,低到可能根本召回不到——一个是用户的日常口吻,一个是产品百科的写法。
解法是:不索引 chunk 原文,索引 chunk 对应的“用户可能会怎么问”。
做法是每个 chunk 入库之前,先让大模型基于这段内容生成 5 个用户视角的问题。
chunk 原文:
“柑橘调和水生调香水,挥发性高,适合高温季节使用,清新透气,代表香水:祖玛珑青柠罗勒、宝格丽绿茶……”
大模型生成的 5 个 question:
① “夏天适合什么香水?”
② “有没有清爽不腻的香水推荐?”
③ “天热了香水选什么味道好?”
④ “柑橘调和水生调有什么区别?”
⑤ “祖玛珑青柠罗勒适合什么季节?”
入库结构变成:
question_1 ──┐
question_2 ──┤
question_3 ──┤→ 指向同一个 chunk_id → chunk 原文
question_4 ──┤
question_5 ──┘
用户提问时,检索命中的是最近邻的 question,然后通过 question 找回对应的 chunk 原文喂给大模型。
用“问题匹配问题”,比“问题匹配文档”在向量空间里距离近得多。
这个做法还带来了另一个好处:同一份香水品类百科里的 10 个 chunk,各自生成了主题不重叠的 question。用户问”夏天适合什么香”,只会命中柑橘调和水生调那个 chunk;东方调的 chunk、香水浓度指南的 chunk,对应的 question 和用户的问题向量距离很远,根本不会进候选池。
用户拿到的只是和他问题真正相关的内容,不是整份产品文档。
用户提问之后,系统在干什么
数据准备好之后,每次用户提问,链路是这样走的:
用户:”夏天适合什么香?不想太甜的那种”
↓
bge-m3 把这句话转成向量
↓
向量召回 Top-20(语义匹配)
BM25 关键词召回(字面匹配,精确型号/SKU靠这路兜底)
两路并行,合并候选
(更完整的系统在这一步之前还有意图路由——判断这个问题要不要进 RAG、
还是直接调订单接口或其他系统;这是另一个话题)
↓
命中:
“夏天适合什么香水?” → chunk_id: 021
“有没有清爽不腻的香水推荐?” → chunk_id: 021
“天热了香水选什么味道好?” → chunk_id: 021
“有没有不甜的花香?” → chunk_id: 034
… 还有其他候选
↓
通过 chunk_id 拿回 chunk 原文
↓
bge-reranker-v2-m3 并行对候选打分排序
↓
取 Top-5 的 chunk 原文
↓
喂给大模型(我们用的是 Qwen3-30B)生成最终回答
接下来把两个关键节点单独拆:Top-K 和 Reranker。
召回多少条,是个真问题
Top-K 是一个看起来很简单的参数——召回几条候选。
但它背后是一个真实的 trade-off:
这个 trade-off 没有”正确答案”,只有”在你的场景下哪个代价更可接受”。
智能导购场景的经验值:召回 Top-20,精排取 Top-5。
先粗筛把范围收窄,再从里面挑出最好的那几条。
那精排靠什么来做?
向量排好了,为什么还要再排一遍
很多人第一次听到 Reranker 会问:向量检索不是已经按相似度排好了吗,为什么还要再排一遍?
因为向量检索的排序和“真正的相关性”之间有一个系统性的偏差。
要理解这个偏差,需要先知道 Embedding 模型是怎么工作的。
先说向量检索为什么会有偏差
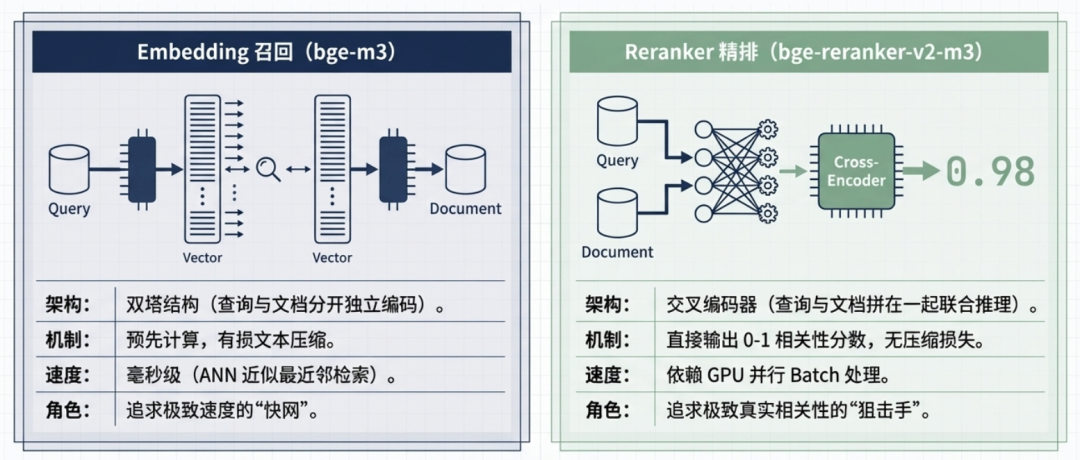
bge-m3 这类 Embedding 模型,用的是”双塔”结构:
查询 ──→ [Encoder] ──→ 向量 A
→ 算余弦距离 → 0.87
文档 ──→ [Encoder] ──→ 向量 B
查询和文档分开编码,各自压缩成一个固定长度的向量,然后算两个向量之间的距离。
这个结构好在一个字:快——文档向量可以提前算好缓存,用户发问时只需要算一个查询向量,然后做 ANN 近似最近邻检索,几毫秒就能从几万条里找到候选。
但它有个代价:原始文本被压缩成了向量,信息是有损的。模型没有机会看到”用户说的’不甜’和文档里的’清新透气’在这个语境下是对应关系”——只能靠训练时学到的统计规律来判断。
Reranker 是怎么补这个偏差的
bge-reranker-v2-m3 用的是”交叉编码器”结构:
[查询 + 文档拼在一起] ──→ [Cross-Encoder] ──→ 相关性分数 0.93
查询和文档拼在一起送进模型,联合推理,直接输出一个 0-1 的相关性分数。
中间没有向量这一步,模型能直接看到”用户说的词对应文档里哪个位置””这段话整体上有没有在回答用户的问题”——信息没有压缩损失,打出来的分更接近真实相关性。
为什么不慢?要拆开两件事来看。
工程侧:Reranker 是并行跑的。 50 个候选不是一条一条串行等结果,而是批量打包送进 GPU 并行推理。实际跑下来延迟没有想象中那么高。
业务侧:智能导购的召回数量本来就不需要很多。 客服场景有一个硬要求——要快,用户不会等。所以召回数量通常控制在 Top-20 而不是 Top-50,候选池小,Reranker 的压力也更小,整体链路延迟更低。
但这里藏着一个 trade-off:
召回数量少(Top-20)
→ Reranker 处理的候选少,延迟低
→ 代价是:万一对的 chunk 排在第 21 位,就永远捞不到了
召回数量是召回率和响应速度之间的旋钮,不是越多越好。
正是因为候选池小,每一个进来的 chunk 都不能太烂——这也是为什么前面说的 question 索引在客服场景里特别有价值。它从源头提高了召回精准度,让 Top-20 里”对的东西”的密度更高,不需要靠堆数量来保证覆盖。
原始知识库(几万条)
↓ Embedding 召回(毫秒级,Top-20)
候选池(20条)
↓ Reranker 并行精排(取 Top-5)
最终上下文(5条)
↓ 喂给大模型
两步走不是”因为贵所以省着用”,而是两种模型的能力边界不同,各司其职:Embedding 负责快速缩小范围,Reranker 负责在小范围内精确打分。
但 Reranker 也有一个限制要注意
Reranker 对输入长度是有限制的。如果 chunk 切得太长,拼上查询之后超过模型的上下文窗口,内容会被截断,打分结果失真。
这也是为什么前面强调”chunk size 要控制好”——不只是影响 Embedding 阶段,Reranker 也会受影响。两个环节对 chunk 长度的要求方向一致:不能太长。
还有两道容易混淆的阈值
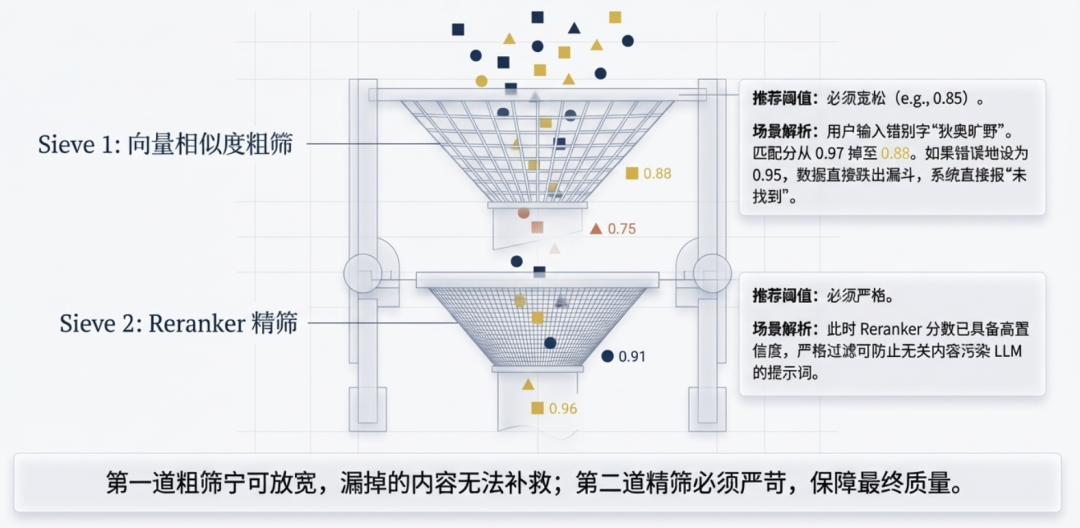
整条链路里其实有两道阈值过滤,很多人只知道其中一道。
第一道:向量召回阶段
Embedding 模型算出余弦相似度(0~1),可以在这里设一个下限,比如 0.6 以下的候选直接丢掉,不进候选池。
这道过滤的逻辑是:连语义都不沾边的东西,不需要浪费 Reranker 的推理资源去打分。
但这道阈值不能设太高——向量相似度本身是有损的,”语义相关但说法不同”的内容在压缩后的向量空间里分数往往不高。设太严,那些”意思对但向量距离稍远”的候选会被提前过滤掉,Reranker 根本看不到它们。
第二道:Reranker 精排之后
交叉编码器打的分信息量更完整,更接近真实相关性。在这里设阈值,过滤掉”进了候选池但打分不够高”的 chunk,只把高分的喂给 LLM。
两道阈值的关系:
向量召回(余弦相似度 ≥ 0.6)→ 候选池(20条)
↓
Reranker 打分(≥ 0.85)→ 最终上下文(5条)
↓
喂给 LLM
第一道是粗筛,宁可放宽,不能太严——漏掉的东西后面补不回来。第二道是精筛,可以卡得相对严一些——Reranker 的分数更可信,在这里过滤质量更有保障。
上线之后碰到一个高频问题,一开始没想到根因在这里——最初把阈值设在了 0.95,分数低于这个值的候选直接过滤掉,不喂给大模型。用户把”迪奥旷野”打成”狄奥旷野”,或者把”祖玛珑”写成”祖码珑”,匹配分会从正常的 0.97 掉到 0.88 左右,直接被阈值卡掉,系统返回”未找到相关内容”。但其实知识库里有完整的产品信息,只是因为一个错别字就彻底召回失败了。后来把阈值从 0.95 松到 0.85,错别字场景的召回率明显回升。排查这类问题要分开看两道阈值——第一道卡掉的话候选池就是空的,第二道卡掉的话候选池有内容但没喂给 LLM,表现一样都是”未找到相关内容”,但根因不同。
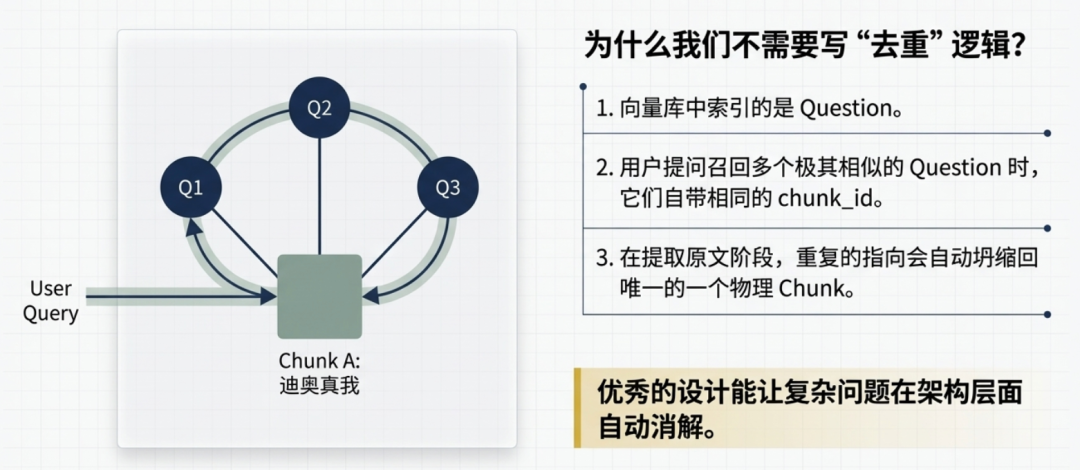
为什么我们没有专门做去重
有些 RAG 方案里会专门做一步去重——候选池里有 4 个 chunk 来自同一份文档,只留分数最高的那个,其余丢掉。
我们这套不需要写这个逻辑,但不是因为不存在重复的问题,而是去重已经在取原文那一步自动发生了。
回想一下索引结构:向量库里存的是 question,每个 question 带着它对应的 chunk_id。用户提问之后,召回的是最近邻的 question,同一个 chunk 的 5 个 question 可能有 3 个都被召回:
命中的 question chunk_id 去重问题在数据准备阶段就从结构上解决了,而不是靠检索阶段打补丁。
这背后是两种不同的设计思路:一种是数据随便切,靠后面各种过滤规则来兜底;另一种是在数据准备阶段就把结构做干净,让检索只做检索该做的事。
我们选的是后者,后期调起来省心很多。chunk_id 去查——相同的 id 只取一次,chunk_021 不管被多少个 question 命中,原文只进一份候选池。这一步天然就完成了去重,不需要额外写逻辑。
当然也有例外:不同 chunk 偶尔会生成语义相近的 question,这些 question 可能指向不同的 chunk,召回进来之后内容上确实有一定重叠。我们的处理方式是 Top-K 设宽松一点,让 Reranker 来排——重复度高的内容分数相近,Reranker 精排之后自然会被挤掉,最终进大模型的 5 条候选里不会有太多重复。
这是两种不同的设计思路:一种是数据随便切,靠后面各种过滤规则来兜底;另一种是在数据准备阶段就把结构做干净,让检索只做检索该做的事。我们选的是后者,后期调起来省心很多。
七、回到开头那四个问题
现在可以回答文章开头的四个验收问题了。
问“夏天适合什么香”——回答像在背百科,没有具体推荐
问题出在 chunk 切太粗或 question 生成没有覆盖季节维度。向量检索召回了花香调的通用介绍,方向没错,但粒度不够——大模型拿到的是泛泛的品类内容,不是”夏季清新推荐”这个具体子集,生成的回答自然也是泛泛的。这不是调 Top-K 或加 Reranker 能修的,要回去把 chunk 切细、把 question 补全。
问”迪奥真我EDP100ml 的价格”——价格是旧数据
这不是检索问题,是知识库本身的数据过期了。RAG 的优势是”改知识库比重新训练模型便宜得多”——更新产品价格,重新入库就行。这是数据运维问题,不是链路设计问题。
问“有没有不甜的花香”——未找到相关内容
问题出在 question 覆盖不够。”不甜”是用户才会说的描述方式,文档里不会这么写,生成 question 时可能没覆盖到这类表达。解法是扩充每个 chunk 的 question 数量,或者专门针对用户口语描述做数据增强。根因还是数据准备阶段,不是检索参数。
搜“狄奥旷野”(错别字)——返回空结果
问题出在 Reranker 的相似度阈值设太高。一个错别字让匹配分从 0.97 掉到 0.88,直接被阈值过滤掉。知识库里有内容,但没机会进场。解法是把阈值从 0.95 松到 0.85 左右,在精准度和容错性之间找到平衡。
问题出在 Reranker 的相似度阈值设太高。一个错别字让匹配分从 0.97 掉到 0.88,直接
四个问题,四类不同的根因。没有一个是靠”调一个参数”能解决的。
这也是这篇想说的核心:
RAG 系统的质量,不是由某一个环节决定的,而是由整条链路上每个决策的对齐程度决定的。调参是最后一步,不是第一步。
最后说一句
上面这套链路是为智能导购设计的:知识库相对固定,精度要求高,值得投入做 question 索引,值得加 Reranker。
如果你搭的是个人知识库,同一套架构,但每个环节的取舍逻辑完全不同——笔记本身就是碎片,不一定需要按标题切;个人用延迟要求低,Reranker 可以不加;知识随时在更新,生成 question 的维护成本可能得不偿失。
同一套系统,目标不同,决策就不同。这是另一篇的话题了。
本文由 @ChenXiaowu 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


