
 起点课堂会员权益
起点课堂会员权益当每一次生成都要花钱:从Sora之死看AI时代的产品新逻辑
AI视频生成的商业逻辑正在经历残酷洗牌。OpenAI突然关停Sora的背后,是每天烧掉1亿人民币却只收回零头的经济灾难;而中国可灵和即梦的涨价策略,则展示了B端商业场景的惊人盈利能力。本文深度拆解两种商业模式的生死分野,揭示AI产品必须面对的五大成本革命。
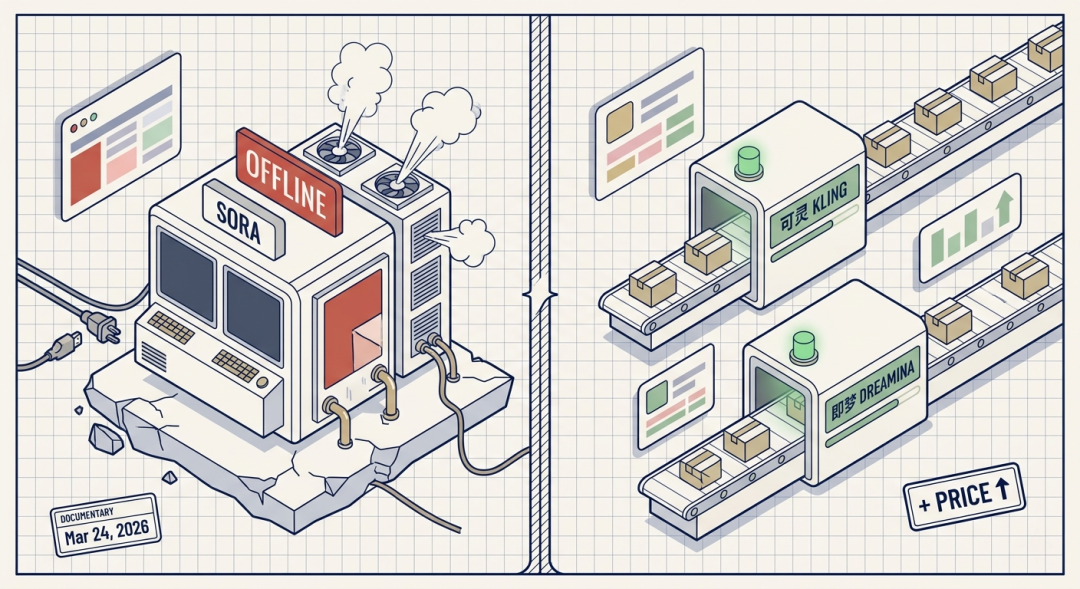
最近刷到一条旧闻的二次讨论——OpenAI在3月24号正式宣布关停Sora。
这个事情发生已经有一段时间了,但我最近反复看到各种角度的讨论,突然冒出了一些新的想法。不是关于”AI视频技术多厉害”,而是一个更底层的疑问:
为什么一个技术公认最强、热度公认最高的产品,会因为“赚不到钱”被自己的亲爹拔管? 而同一时间,中国的可灵和即梦却在闷声数钱——甚至敢在Sora关停当天直接涨价?
想来想去,我觉得答案不只是”Sora运气不好”这么简单。 它其实揭示了一个正在发生的巨大范式转换——AI产品和传统互联网产品,在底层的成本逻辑上是完全不同的两个物种。 如果我们还用做传统互联网产品的思维来做AI产品,结局很可能就是下一个Sora。
所以今天这篇文章,我想聊的核心是:当AI时代每一次生成、每一次对话、每一个功能都有实实在在的算力成本时,我们做产品的思路到底应该怎么变?
我们先来看看 Sora 到底是怎么死的
先看一笔让人窒息的账
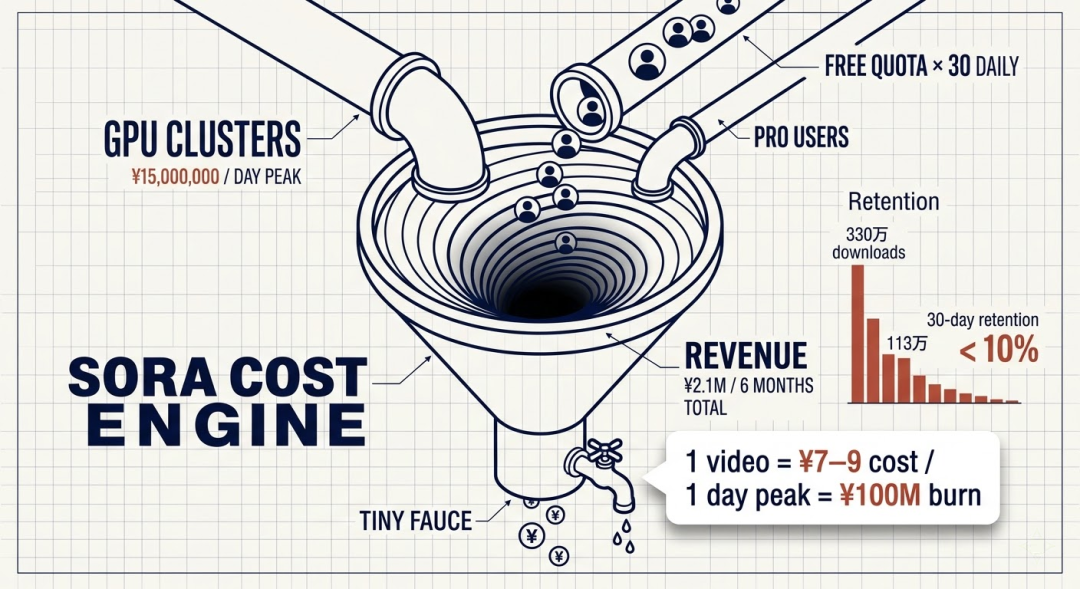
Sora每生成一个10秒的高清视频,用户端大约等一两分钟就能出片,但后台的算力消耗是实实在在的。折算下来,生成一个10秒视频的算力成本在0.5到2美金之间,取中位数大概1美金出头——换成人民币,差不多7到9块钱一条10秒短视频。
你可能觉得七八块钱也不贵。但问题出在规模上。
Sora在流量巅峰期,每天有数百万人在使用,而且很多人不止生成一条。叠加起来,高峰时期一天的推理成本高达1500万美金,折合人民币超过1个亿。
而从2025年9月App上线到2026年3月关停,整整半年时间,Sora在应用内购的总收入是多少呢?
210万美金。大约1500万人民币。 这还是用户实打实付出去的钱,一分成本都还没扣。
光峰值那几周的烧钱,就已经是这半年总收入的几百倍。整个生命周期赚到的钱,连一天的算力账单都覆盖不了。
不仅仅是烧钱,用户的留存率也不行
更要命的是用户数据。Sora独立App上线初期下载量非常猛——2025年11月下载量达到330万次的峰值。但到2026年2月就暴跌到113万,三个月跌了66%。
30天留存率跌到个位数。意味着100个人下载了Sora,一个月后只有不到10个人还在用。
留存率低的主要原因是普通用户没有持续生成视频的刚需。大多数人的使用路径是这样的:下载 → 生成一段”孙悟空大战变形金刚”的搞笑视频 → 发到社交平台 → 收获点赞 → 删掉App。整个过程就像玩了一次新奇的游戏,新鲜劲过了就走。
这种”一次性游玩”的用户行为,与OpenAI给出的免费额度策略产生了致命的错配。Sora曾经对所有用户开放每天30次免费生成(Pro用户高达100次)。理论上,免费额度是诱饵,让用户尝到甜头后转化为付费会员。但现实是:被猎奇视频吸引来的用户,30条免费额度足够他们玩腻、发完朋友圈、然后卸载——既没转化为Pro会员,也没形成持续使用习惯,徒然消耗了大量算力。
更要命的是背后的数学。按照ChatGPT Plus每月20美金的订阅价格,用户只要一个月生成超过16条视频,消耗的算力成本就已经超过他付的钱。 而大部分Pro用户远不止生成16条。这意味着:免费用户在亏钱,Pro用户也在亏钱;拉新越多,亏损越深。
这完全是传统互联网”先免费圈用户,以后再想办法赚钱”的打法。在互联网时代,这个逻辑是成立的——因为多一个用户几乎不增加成本。但在AI时代,每一个免费用户的每一次生成,都在消耗实打实的GPU电费和算力。用户越多,亏得越多。
但免费额度还不是根本原因。根本原因有两个:
第一,Sora追求的效果太完美了。 它的底层目标是做一个”世界模拟器”——为了让水花溅起来符合流体力学,要额外消耗一大块算力;为了让光线追踪到每一个光子的反射路径,又要吃掉一大块;物体碰撞要遵循牛顿力学。这些物理级别的模拟占了推理成本的绝大部分,但对于绝大多数商业场景来说——拍一个15秒的带货视频、做一个30秒的短剧片段——这些物理细节根本用不上。
第二,用户群体完全错配。 Sora吸引来的是一大波C端猎奇用户,而不是持续付费的专业创作者。30天留存率不到10%就说明了一切——这些用户不创造商业价值,但每一条生成都在烧钱。
说白了,Sora同时犯了两个错:技术端追求极致效果导致成本居高不下,商业端沿用传统互联网免费策略导致收入远远兜不住成本。两头挤压,中间就是一个巨大的亏损黑洞。
最后一根稻草
Sora的团队负责人Bill Peebles在2025年10月就公开承认了——“这个经济模型完全不可持续。”
但真正让OpenAI下决心拔管的,不只是Sora本身的亏损,更紧迫的是来自竞争对手的压力。2026年OpenAI正在冲刺IPO,估值号称数千亿美金,但与此同时,Anthropic正在凭借更强的编程能力、代码生成能力和Agent功能,疯狂抢夺OpenAI的企业级客户。 用户正在向Anthropic流失,而这直接关系到OpenAI最核心的收入来源。
每天给Sora烧掉的GPU资源,如果节省下来用于支撑GPT-5.5、GPT-5.6以及后续产品的迭代,去强化那些被Anthropic超越的编程和Agent能力,产出的商业价值可能是现在的几十倍甚至上百倍。
用Sam Altman自己的话说:“我们需要把算力和产品力集中到下一代自动化研究和企业服务上。” 翻译一下就是——Sora这个坑太大了,不填了,必须把资源抢回来守住基本盘,去跟Anthropic抢客户、去推下一代大模型。
连迪士尼10亿美金的投资都泡汤了——据报道,迪士尼是在关停公告前一天才被紧急通知的,钱一分没到账。
同一赛道,可灵和即梦为什么活得好?
Sora关停的同一天,字节跳动旗下的即梦平台做了一件很有意思的事——取消了折扣,直接涨价。
一个在拔管,一个在涨价。为什么差距这么大?
我仔细看了可灵和即梦的模式,发现它们的关键选择可以总结为两种完全不同的商业模式:
模式一:快手的”专科诊所”模式
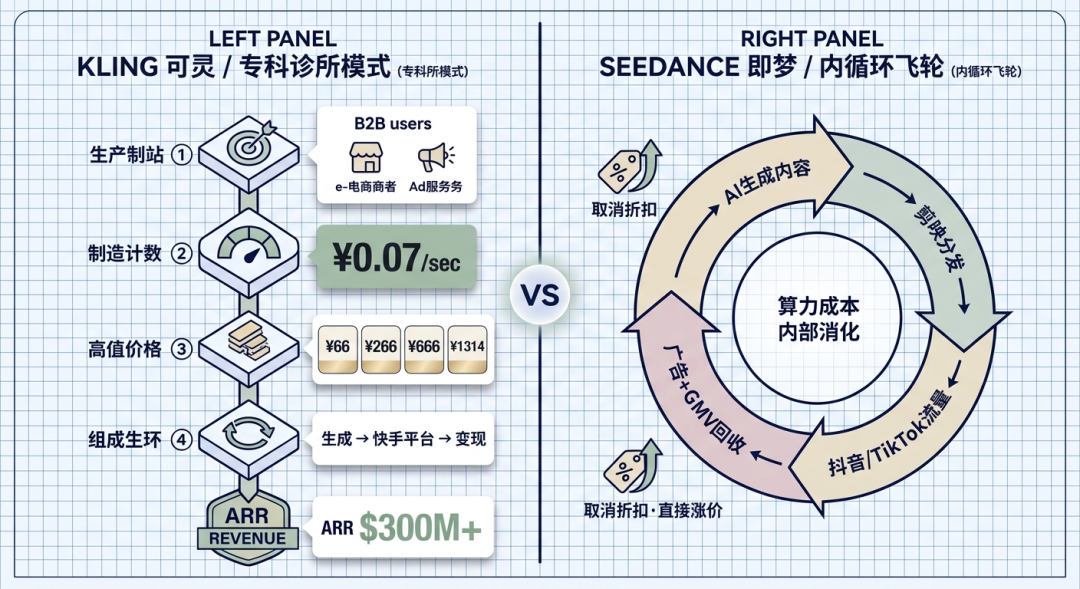
可灵AI到2026年1月,年化收入已经超过3亿美金,折合人民币超过20亿。 预计2026年还能翻一倍。
它是怎么做到的?
第一,精准定位谁来用。 可灵从一开始就不追求”让所有人做导演”这种乌托邦口号。**它瞄准的是电商商家、广告公司、短剧工作室这些B端专业用户。**这些人有明确的商业目的:生成带货视频能帮他们省下几万块真人拍摄成本,生成短剧片段能让他们快速试错,所以他们愿意持续付费。
可灵的定价体系是这样的:黄金会员66元/月,铂金266元/月,钻石666元/月,黑金1314元/月。这些价格对于有商业回报预期的专业用户来说,完全可以接受。
第二,成本控制到位。可灵每秒视频生成成本大约0.07美金,折合人民币5毛钱一秒。 和Sora的9块钱10秒(大约9毛一秒)相比,便宜了将近一半。而且可灵已经实现了推理层面的毛利率转正——每生成一条视频至少不亏钱。
可灵3.0通过API调用的价格大约是每秒0.075美金,它不需要一个”能模拟整个物理世界”的通用模型,只需要一个在短剧和电商场景深度优化的专用模型。效果在这些场景里完全够用,成本却只有通用方案的几分之一。
第三,免费额度控制得聪明。 可灵给免费用户每天66积分,够生成几个低分辨率、带水印的短视频。想要高清无水印?付费订阅。这个免费额度足以让你尝到甜头,但不会让你白嫖到公司亏钱。
第四,嵌入了快手自己的生态。 创作者用可灵生成内容,直接发到快手平台上,获得流量分发和商业变现。创作-分发-变现是一条完整的闭环。
模式二:字节跳动的”内循环飞轮”
字节的策略更狠——Seedance 2.0几乎不单独对外卖,而是直接嵌入自己的超级流量生态里。
它的运转逻辑是这样的:Seedance生成的带货切片、引流短剧、转场特效 → 通过剪映分发给千万创作者 → 创作者把内容发到抖音和TikTok → 算法推荐产生播放量 → 播放量转化成广告费和电商成交额。
算力成本在字节内部就消化掉了。 Sora需要向用户收费来覆盖成本,但Seedance不需要,因为它的算力成本最终通过广告和电商GMV来回收。这就像一个工厂的电费——你不需要让员工掏电费,因为员工生产的产品卖出去就能把电费赚回来。
即梦敢取消折扣涨价的逻辑也很简单——C端猎奇用户走掉没关系,B端愿意掏钱的专业创作者留下来就行。
当然,它们也不是没有挑战
这里值得提一句的是,即使是活得好的产品,算力约束也是真实存在的。字节的即梦在使用高峰期经常出现几小时的排队等待,用户体验并不完美。Seedance 2.0的生成成本据说也已经接近每秒1块钱人民币的量级——虽然商业模式能支撑,但如果用户量继续暴涨,算力瓶颈是当下视频生成领域要面对的主要问题。
这恰恰印证了我想说的核心观点——在AI时代,算力成本是一个真实的物理约束,不是靠烧钱就能突破的。即使是赚钱的产品,也必须时刻在成本和效果之间做取舍。
这不只是Sora一家的问题——AI产品的五个底层逻辑变化
聊到这里你可能觉得,这是视频大模型的事,跟做其他AI产品的人有什么关系?
关系非常大。因为Sora的死,和可灵/即梦的活,共同揭示了一个正在影响所有AI产品的根本变化——
传统互联网时代,产品的边际成本趋近于零。AI时代,每一步操作都有实实在在的生成成本。
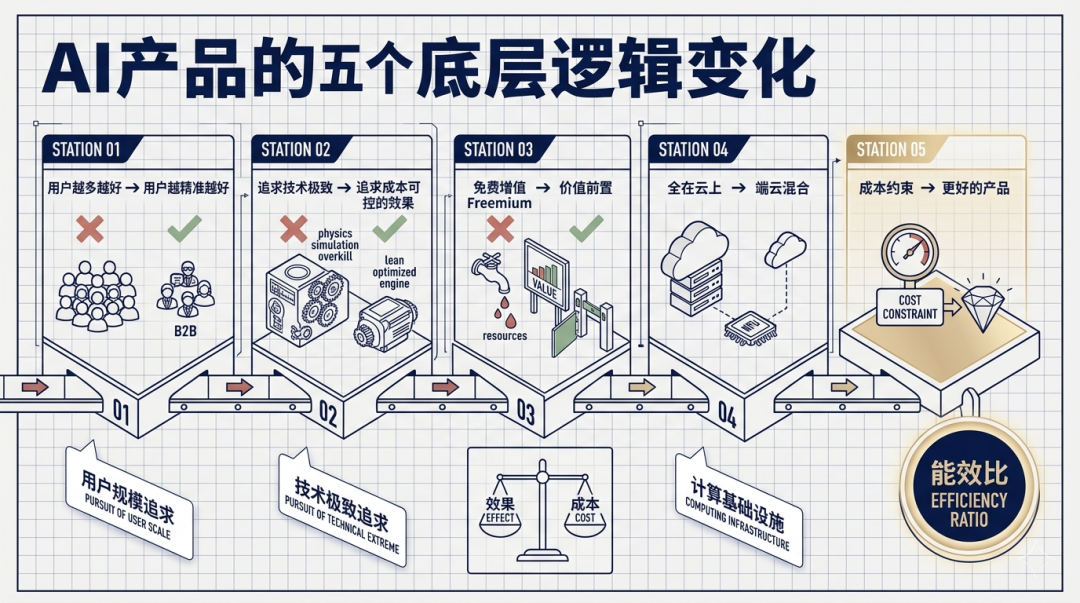
这两句话看起来简单,但展开来想,**它会颠覆我们习以为常的几乎所有产品设计逻辑。**具体体现在五个维度:
第一个变化:从”用户越多越好”到”用户越精准越好”
以前做互联网产品,我们追求DAU、MAU,追求增长曲线。因为多一个用户几乎不增加成本,但多一个用户意味着更多的数据、更高的广告价值、更好看的融资故事。所以那个时代的产品策略就是”不管三七二十一先拉来用户再说”——拼多多的百亿补贴,美团的红包大战,本质上都是这个逻辑。
但AI产品呢?每一个用户的每一次操作,都在消耗GPU。 一个不付费的用户在Sora上生成10条视频,OpenAI就要掏出大概90块人民币的算力费。用户越多,亏得越多。
这意味着AI产品的核心指标不再是DAU,而是每单位算力产生的收入。用户不是越多越好,而是越精准越好。 可灵和即梦敢涨价,正是因为它们想清楚了一件事:要服务那些有明确商业回报预期的B端用户,而不是猎奇的C端玩家。
第二个变化:从”追求技术极致”到”追求成本可控的效果”
Sora的悲剧不是功能做太多了,而是它追求的效果太完美了。
为了让水花溅起来符合流体力学,要额外消耗一大块算力。为了让光影追踪到每一个光子的反射路径,又要吃掉一大块。这些”物理级真实感”在技术上确实惊人,但对于拍一条15秒的带货视频或者一个30秒的短剧片段来说,根本用不上。
反过来看可灵和Seedance怎么做的——它们聪明地避开了“模拟整个物理世界”这条路,转而聚焦在几个有限场景:短剧的室内场景和微表情、电商的固定货架和衣服质感。 物理边界极度缩减之后,模型砍掉了大部分无用计算,成本直接降了一个量级。
这给做AI产品的人一个很重要的启示:不是技术上能做到的都应该做。要在“效果足够好”和“成本可承受”之间找到那个平衡点。
顺带一提,斯坦福大学人类中心AI研究所的2025年AI Index报告有一组数据——通用大语言模型的推理成本在2022年11月到2024年10月之间降了大约280倍。这听起来很乐观对吧?但同一时期企业的AI总支出反而涨了320%。因为降价带来了更多使用量——每个AI Agent完成一个任务要调用大模型10到20次,RAG架构每次查询要塞入几倍的上下文……单价降了,但用量涨得更快。
所以,依赖“未来成本会降”来解决今天的亏损问题,是不靠谱的。成本控制必须在产品设计阶段就想清楚。
第三个变化:从”免费增值”到”价值前置”
互联网的经典模式是Freemium——先让你免费用,等你用习惯了再收费。这个模式的前提是免费用户的边际成本几乎为零。
但在AI产品上,每一个免费用户都在实打实地消耗算力。 Sora给免费用户每天30次生成机会,结果就是——用户是拉来了一大波,但每天在疯狂烧钱,留存又极低。
AI时代可能需要一个反过来的逻辑:先让用户看到价值,再开放使用。
不是”先免费用再付费转化”,而是 “先展示这东西能帮你省多少钱、赚多少钱,然后你付费使用”。
目前行业里做得好的AI产品,大多数在用一种混合模式——基础订阅费打底,附带一定的使用额度,超出部分按量付费。比如可灵的标准版大约50块人民币月费,包含一定积分,超额使用再加购。这样既保证了收入可预期,又把成本控制在可承受范围内。
第四个变化:从”全在云上”到”端云混合”
为了降低推理成本,越来越多的AI计算在往终端设备走。2026年市面上带NPU(神经网络处理器)芯片的手机和电脑越来越多——苹果的M系列芯片、高通的骁龙8系列、联发科天玑系列,都内置了AI运算单元。
这意味着什么?**意味着以后不是所有AI功能都需要联网传到云端去跑大模型。**简单的任务——比如语音转文字、照片美化、基础的文本摘要——可以直接在你的手机或电脑本地完成,不需要消耗云端算力。只有真正需要大模型能力的复杂任务,才上传到云端。
这对产品设计的影响是:未来的AI产品可能需要考虑模型的分级适配——哪些功能在端侧跑小模型,哪些功能调用云端大模型,中间怎么无缝衔接。不同手机芯片的算力不同,同一个功能在高端机和中端机上可能要用不同的模型版本。这本身就是一个新的产品设计课题。
行业里管这个叫”模型路由”——一个智能分发系统,自动判断每个请求应该发给本地小模型还是云端大模型。简单任务走本地,复杂任务走云端。据分析,这种策略平均能降低40%到50%的推理成本。
第五个变化:因为每一步都花钱,反而倒逼出更好的产品——兼论AI产品为什么存在
这是我个人觉得最有意思的一点。
表面上看,”每个功能都有成本”是一种约束、一种限制。但换个角度想——正因为有了成本约束,产品团队反而被迫去想清楚“用户到底最需要什么”。
以前互联网做产品,功能不花钱,堆就是了。堆错了也没什么损失,大不了下个版本去掉。但AI时代每个功能背后都有推理账单,堆一个没用的功能就是实实在在的亏损。
这种压力反而催生出更精准的产品设计。
有一组数据特别说明问题:某AI设计工具做了A/B测试,发现完全由AI自动生成的设计稿,用户采纳率只有12%。但如果用户自己画个草图、让AI在这个基础上优化呢?采纳率飙到81%。
为什么?因为全自动模式下,AI要消耗大量推理成本去”猜”用户想要什么——猜错了用户就不用,等于白白烧了算力。而用户先给方向再让AI执行,AI的工作量缩小了一半,出来的结果反而更贴合需求。
成本更低,效果更好。这不是一个折中方案,这是最优解。
推而广之,AI时代做产品的核心思路可能是:让人做人最擅长的事(定方向、做判断、给创意),让AI做AI最擅长的事(执行、渲染、批量生成)。 人脑20瓦搞定决策,GPU几千瓦搞定干活。各自在自己效率最高的区域工作。
但这里还有一个更深层的问题:如果用户直接去调用最顶级的大模型API(比如Claude Opus 4.6或者GPT-5.4),理论上可以完成几乎任何任务。那为什么还需要AI产品存在?
答案就在成本里。
顶级模型每次调用的成本很高。但一个做得好的AI产品,可以通过工程化手段——在特定领域里达到接近顶级模型的效果,同时把成本大幅降下来。
怎么降?除了前面提到的模型路由和端云混合,还有:
- 开源模型微调: 用开源模型(比如Qwen、Llama)在特定领域做精调,在那个领域内效果不输顶级模型,但成本只有零头。
- 工作流编排: 把一个复杂任务拆成多个步骤,每个步骤用最合适(也最省钱)的模型来处理,而不是全程调用最贵的那个。
- Prompt工程+缓存: 优化输入prompt减少token消耗,对重复查询做语义缓存避免重复计算。
可灵本质上就是这个逻辑——它不需要一个”能模拟整个物理世界”的通用模型,只需要一个在短剧和电商场景深度优化的专用模型。效果在这些场景里完全够用,成本却只有通用方案的几分之一。
AI产品存在的核心价值,就是在特定领域里实现“效果够好+成本够低”的最优组合。 这才是用户选择你而不是直接去用顶级模型API的理由。
真正能活下来的AI产品,可能恰恰是那些最清楚自己不做什么的产品。 它们不追求全能,而是在一个明确的领域里,用最高的效率解决最刚性的需求。用户为它买单,不是因为它什么都能做,而是因为它在他们最需要的那个点上,做到了”效果够好、价格能接受”。
回到Sora——它的死带来了什么
最后说说Sora的死对行业的影响。
短期来看,中国的AI视频玩家直接受益了。可灵和即梦在Sora退场后拿到了更多的市场空间和用户关注度。Seedance 2.0在今年春节期间的热度远超预期。可灵在全球视频生成榜单上已经稳居前两名。
中期来看,Sora的死加速了整个行业从“炫技”到“赚钱”的转向。 投资人不再只看技术demo多酷炫,而是开始问”你的单位经济学算清楚了吗”。连OpenAI自己也在调整战略——把ChatGPT、编程工具Codex和浏览器Atlas合并成一个聚焦企业生产力的”超级应用”,明确表示不再追求”moonshot式的内部创业”。
长期来看,Sora的死可能标志着一个时代的分水岭——从“技术驱动”到“成本驱动”的转变。以后做AI产品,第一个要回答的问题不再是“我们能做什么”,而是“在可承受的成本下,我们该做什么”。
这听起来似乎没那么酷了?但我觉得恰恰相反。
互联网时代那种”什么都免费、什么都要做、先烧钱再说”的狂飙突进,本质上是靠投资人的钱撑出来的幻象。当每一步都有成本的时候,产品人才真正需要回答一个最朴素的问题——用户到底愿意为什么买单?
能回答好这个问题的产品,才是真实的产品。
给自己的几个思考
写完这篇文章,我给自己列了几个还在想的问题,也分享给大家:
如果未来端侧算力越来越强(手机NPU、PC端的AI芯片),会不会出现”端侧+云端”混合的全新产品形态?这对产品的设计和定价模式会产生什么影响?
互联网时代大家比的是谁功能多、谁体验好。AI时代大家可能要比谁的“成本效率”最高——在同样的推理预算下,谁能给用户创造更多价值? 这会不会催生出一个全新的竞争维度?
如果每个功能都有成本,那用户在选择”用还是不用”某个AI功能时,是不是也会变得更理性?免费时代用户可以随便试,付费时代用户会更清楚地知道自己要什么。这会不会反过来让整个市场变得更健康?
这些问题我还没想透,但我觉得值得每一个做产品的人去琢磨。
Sora的死不是AI的失败。它是旧思维的葬礼,新逻辑的序章。
而那个新逻辑的核心,说到底就是三个字——能效比。
不管是一个产品功能的推理成本对比它创造的价值,还是人脑20瓦对比GPU几千瓦的分工效率,还是垂直化方案对比通用化方案的商业回报——归根到底,在资源有限的世界里,赢到最后的永远是效率最高的那个方案。
本文由 @ChenXiaowu 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


