
 起点课堂会员权益
起点课堂会员权益没有评测集,迭代就是拍脑袋:“三分法”构建AI的导航系统
智能客服上线后算法与运营团队的矛盾暴露出AI产品迭代的关键问题——缺乏统一的评测标准。本文深度拆解如何构建高质量的AI评测集,从定义业务范围、数据标注规范到搭建自动化流水线,揭秘如何用‘导航系统’解决团队自说自话的困境,实现模型迭代的科学决策。

智能客服上线一个月,算法同学说“准确率又涨了2个点”,运营同学却说“用户投诉更多了”。
——没有统一的测评集,大家都在自说自话。
本质:评测集是AI产品的“导航系统”
很多人做AI产品,迭代全凭感觉:今天用户骂得多了,赶紧改一版;明天准确率报表涨了,就上线。这其实也反映了一个事实:
没有评测集,迭代就是拍脑袋。评测集就是你的导航系统。
告诉你当前在哪、该往哪走、走没走对。
一个好的评测集应该做到:
- 覆盖全面:包含各种用户真实问法,而不是只有标准问法
- 标注一致:每条样本的正确答案有明确定义,不同人标注结果一致
- 持续更新:线上新出现的badcase要回流到评测集
- 自动化:每次模型更新,自动跑一遍评测集,输出准确率、召回率、F1
有了这个“导航系统”,算法改完模型不用等上线就知道效果好坏,产品做AB测试也有了基准。
三步法:从零到一构建高质量评测集
第一步:定义范围与标准(划定“考试范围”)
这一步的目标是明确“考什么”以及“答案是什么”。
(1) 划定业务范围
与业务方(客服团队、运营)共同确定必须覆盖的用户意图。
我们当时定义了12个一级意图,比如:
- 查询订单状态
- 申请退款
- 咨询商品信息
- 投诉破损
- 查询积分
- ……
原则:先覆盖高频意图(占80%流量),低频意图后期慢慢补。
(2) 制定标注规范
为每个意图制定清晰、无歧义的标注规范。例如:

关键:规范要写出来、培训到位、定期对齐。我们每周开一次标注对齐会,讨论争议案例。
第二步:收集与标注数据(准备“考题与标准答案”)
目标是获取贴近真实用户的数据,并为它们打上正确的标签。
(1)数据来源
最佳来源是脱敏后的真实用户日志。我们拉了过去30天的对话记录,去掉了敏感信息(姓名、电话、地址),然后按意图分层采样。
冷启动期没有足够日志怎么办?可以用以下方式:
- 人工撰写:客服团队每天写10条常见问法
- 大模型生成:基于种子问法,让大模型批量生成同义句
(2)数据增强
我们用大模型做了同义句扩展。比如基于“我要退款”这个种子,生成了:
- “怎么退货”
- “不想买了怎么办”
- “钱能退回来吗”
- “取消订单退钱”
每个意图扩展了 X 条同义问法,评测集从 X 条扩充到 X 条。
(3)标注与质检
我们组建了一个3人标注团队,核心原则:标注和审核角色分离。
- 标注员:负责给每条用户问句打意图标签
- 质检员:随机抽取20%的标注结果复核,不一致的退回重标
- 仲裁员:标注员和质检员争执不下的,由产品经理或业务专家最终裁定
这样做的好处:避免“自己标注、自己检查”导致的质量盲区。
我们用了 Label Studio 作为标注工具,免费、开源、支持多人协作。
第三步:分层与切片(设计“试卷结构”)
一个笼统的评测集只能给出一个模糊的总分,而一个分层切片的评测集能告诉你具体哪里好、哪里差。
我们划分了三个子集:
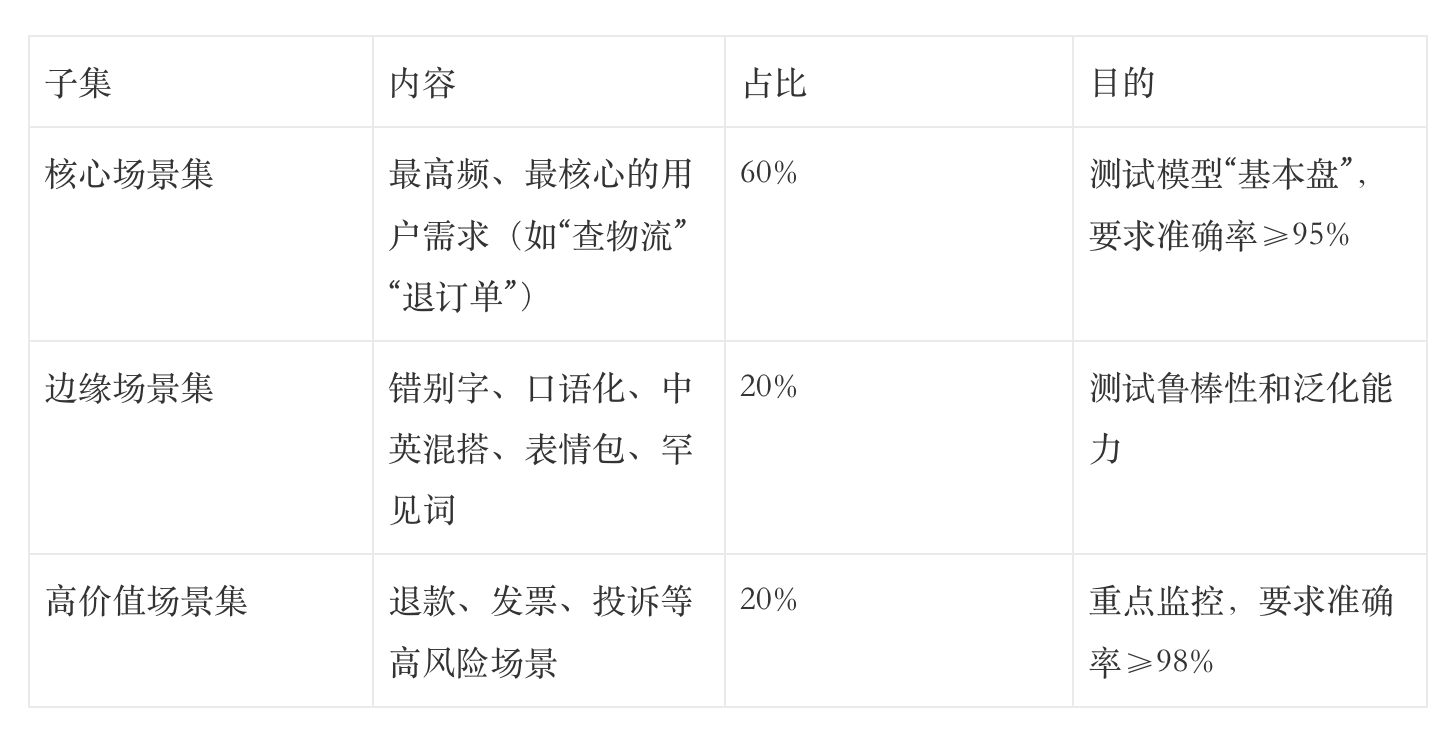
通过这种切片分析,我们可以清晰地发现:“模型在核心场景上表现稳定,但在处理口语化表达时准确率明显下降 ,需要优化。”
自动化评测流水线
有了评测集,我们搭了一套CI/CD流水线:
代码提交 → 烟囱测试(10条核心用例)→ 通过 → 模型训练 → 跑全量评测集 → 指标对比基线 ↓ 不通过 ↓ 下降超过阈值 阻断上线 阻断上线 ↓ 达标 自动部署上线
每次评测结果自动发送到企微群,附带详细报告:
- 整体准确率变化(+X% / -X%)
- 每个意图的准确率明细
- Top 10 错误样本(方便人工分析)
落地遇到的三个坑
坑一:标注标准不一致
两个标注员,一个认为“退钱”和“退款”是同一个意图,另一个认为应该分开。
解法:先制定《标注规范文档》,所有标注员培训+考试,通过才能上岗。每周开标注对齐会,讨论争议案例。
坑二:测试集过拟合
有一次模型在测试集上准确率涨了3%,但上线后用户反馈没变好。一查发现,算法把测试集中的某个高频样本偷偷加入了训练集。
解法:测试集由产品经理保管,算法团队拿不到原始数据,只能看到评测结果。
坑三:评测集增长太快
半年后测试集涨到了5000条,每次跑评测需要30分钟,影响迭代效率。
解法:定期对测试集做“瘦身”——删除重复的、过时的、低价值的样本,保持核心样本2000条以内。
行业其他评测集方案参考(选读)
除了自建,行业内也有一些通用的基准测试集和创新理念,可以作为补充参考:
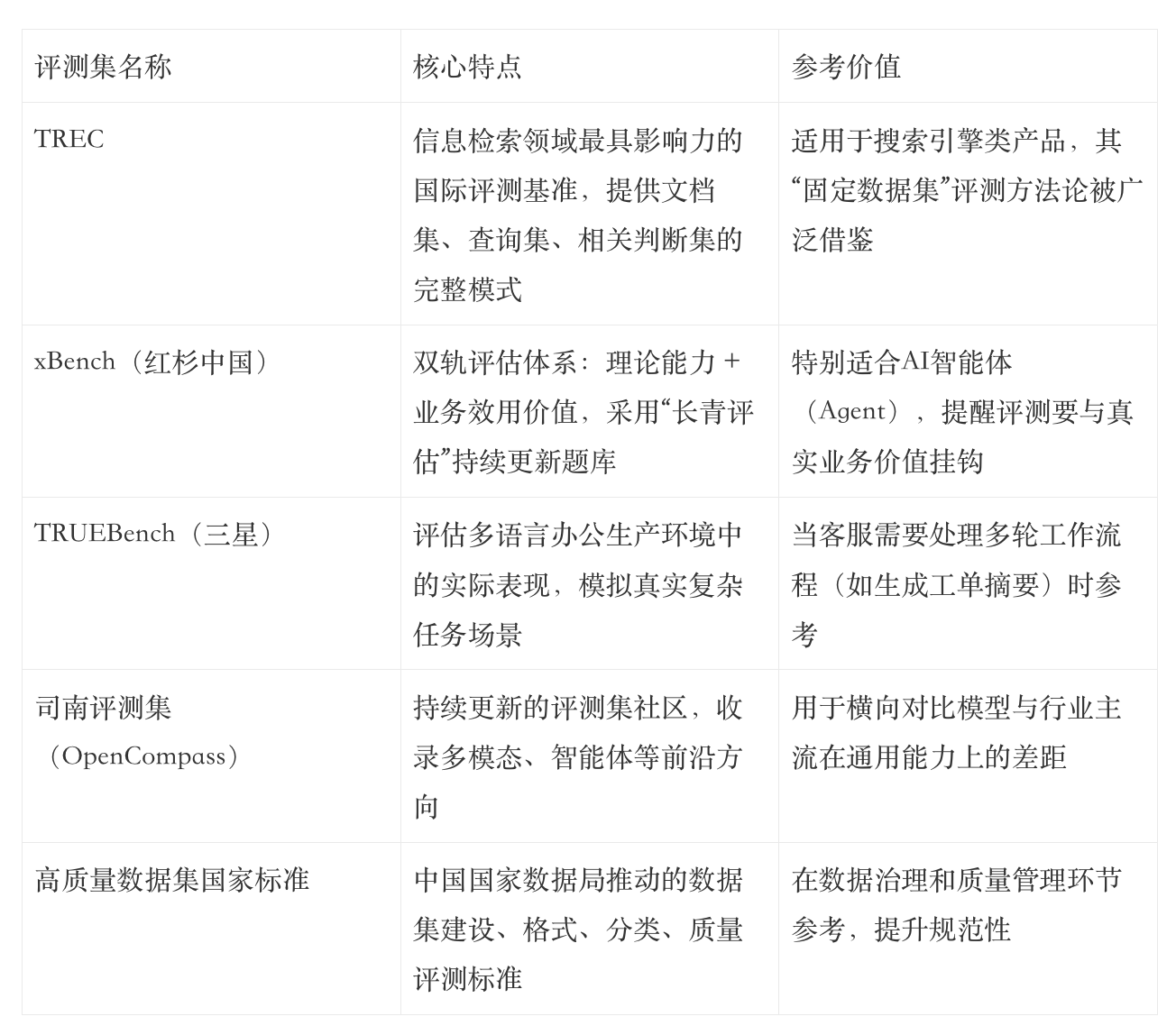
这些不是必须的,但可以拓宽思路。
优化方向:评测集依然搞不定的场景
- 主观性问题:用户问“你觉得哪个好吃”,答案没有对错,评测集无法给出唯一标准。解法:这类问题直接转人工或走推荐系统,不放入评测集。
- 多轮对话评测:单轮评测好做,多轮需要评测“流程是否顺畅”“是否在合理轮次内解决”。我们后来引入了人工盲测(让真人同时对比两个版本的多轮效果),但成本高,还在探索自动化。
- 生成式答案评测:如果答案是大模型生成的(而非检索的),很难用脚本自动判断对错。解法:先用检索式,等评测集成熟了再尝试生成式。
结语:评测集不是“做完就扔”的
做了这么多,我最大的体会是:
评测集是一个活的东西。它需要持续维护、持续更新、持续和业务对齐。有了它,算法、产品、运营才能坐在一张桌子上说话。
我们的最终成果:
- 一套统一的测试集,覆盖 多个意图、多个真实问法变体
- 自动化评测流水线,每次模型更新30min出报告
- 算法、产品、运营共用同一套指标,有需求走迭代(产品经理基本功时刻)
本文由 @嘻嘻李 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


