
 起点课堂会员权益
起点课堂会员权益AI产品意图识别:从“调个大模型”到系统工程的认知跃迁
意图识别正成为AI产品的关键命门,但90%的团队都在用错误方式对待它。从通用聊天机器人到功能型AI,意图识别从不是简单的Prompt工程,而是决定产品生死的地基设计。本文将揭示分层意图架构如何同时解决响应速度、准确性与成本控制三大痛点,并给出产品经理必须掌握的三大决策原则与实战方法论。

做 AI 产品这两年,我发现一个有意思的现象。
几乎所有团队在立项阶段都会聊到“意图识别”,但十个团队里有九个,都把它当成一个写 Prompt 调大模型就能搞定的小模块。等产品真正上线、能力堆到二三十个以上,用户开始疯狂吐槽“这 AI 怎么这么笨”的时候,才发现自己掉进了一个系统工程的深坑。
今天就把这套我反复踩过坑、也反复验证过的方法论完整讲一遍。
一、先想清楚:为什么意图识别是 AI 产品的”新地基“
传统软件时代,产品的入口是功能菜单,用户自己导航到目标功能。AI 时代变了,入口变成了自然语言。
这个变化的含义,很多人没真正理解。
它意味着产品必须先“听懂”用户想干什么,才能决定调用什么。意图识别因此从一个 NLP 模块,升格成了 AI 产品的路由中枢。它的质量直接决定三件事:用户能不能到达正确的功能(准确性)、用户多久能拿到响应(速度)、整个系统的算力成本(经济性)。
所以当我看到有人还在说“意图识别就是写个 Prompt 调大模型”的时候,我基本可以判断这个团队还没真正做过复杂场景的 AI 产品。这话在 Demo 阶段成立,在生产环境会迅速崩溃。
二、复杂度的真相:能力空间乘以用户期待
我见过一个特别好的类比,是用婴儿哭闹来讲意图识别的复杂度。
刚出生的婴儿,哭闹意图就三种:饿了、不舒服、拉臭臭。谁都能猜对。等孩子长到三四岁,哭闹可能有几十种原因,甚至还会“伪装”——明明是想要糖,哭得像是摔疼了。这时候连亲爹亲妈都要犹豫。
AI 产品完全一样。
小场景下(比如单一查询工具),能力数量少,用户表达收敛,Prompt 加大模型足够了。但当产品挂载了几十上百个能力,同一个意图有 N 种说法,用户还期待 ” 秒回 ” 的时候,单靠大模型既慢又贵,边界意图还频繁误判。
复杂度不是线性增长的,是乘法关系:能力数量乘以表达多样性乘以用户容错阈值。

三、为什么豆包”看起来很准“,而你的功能型 AI ”显得很笨“
这是个值得展开的关键问题,因为它揭示了一个被严重低估的真相:体验和技术,根本不是一回事。
很多团队盯着豆包、Kimi 这类通用 AI 的意图识别效果,觉得人家模型强、算法牛,自己怎么追都追不上。但实际上,通用 AI 的体验优势,一半来自模型能力,另一半来自一个被忽视的设计——它永远不会“哑火”。
聊天型 AI 就算意图识别错了,照样能用聊天形式回复你,提供人文关怀,体验不会断。
功能型 AI 不一样。一旦路由到对应功能,功能查不到结果或者接口出错,回复瞬间变得极其生硬:“抱歉,没有查询到相关结果”。用户的感知就是——这 AI 真笨。
这里有个我特别想强调的优化方案:不管挂载什么功能,都先输出一段基于知识库的聊天内容,再触发功能调用。
举个例子,用户问“百亿补贴有什么”。
错误做法是直接调用活动接口,拉一个商品列表给用户。一旦接口超时或者没数据,用户看到的就是空白。
正确做法是先讲 ” 百亿补贴是我们本期的核心促销活动,规则是 XXX,当前有 X 场正在进行 “,然后再把活动入口和商品列表拼接上。
知识库永远在线,功能接口可能宕机。前置聊天就是产品的“安全气囊”。

这个设计成本不高,但对体验的提升是数量级的。除此之外,追问也是提升意图准确度和提升体验的重要途径,此处先不展开。
不过,入口真的没出来,也会有点小尴尬。这里应注意提示词工程里的回复文案设定,不要指出入口又没有,可以适当将表达模糊些:
四、落地的两步基础动作
讲完认知,聊聊具体怎么做。
第一步:能力分类。
这是产品经理最不该外包的工作。你需要把产品所有能力穷举出来,按用户视角(不是工程视角)划分意图,明确每个意图的触发边界和反例。
我见过太多团队犯的错,是用后端模块结构倒推意图分类。结果就是用户说人话、系统按 API 分类——必然错位。
第二步:意图标签与模型训练。
每个意图整理一个问题集合(建议每类不少于 100 条真实或拟真 Query),从中抽离意图标签,训练专用意图识别模型。这里用 BERT 或者 Embedding 相似度就够了,不必动用大模型。
五、真正的解法:分层意图识别架构
这才是兼顾准确性、速度、成本的工程化答案。
整个架构分三层。
第一层是规则层。 设计正向规则和逆向规则,综合计算执行度。如果用户 Query 和预设规则完全匹配,100% 判定命中,直接走规则流程。这一层能消化 60% 左右的请求,毫秒级响应,零成本。
但规则有个诅咒:规则越宽,命中率越高,误判率也越高。结果是产品看起来“反应快”,但“经常猜错”——这比慢一点更糟。所以规则设计必须保持克制。
第二层是 BERT 或 Embedding 模型层。 规则层执行度低的请求进入这一层,输出意图和置信度。这一层能处理 35% 左右的请求,几十毫秒响应,低成本。
第三层才是大模型兜底。 只有前两层都搞不定的复杂或模糊意图,才会落到大模型处理。这部分占比大约 5%。
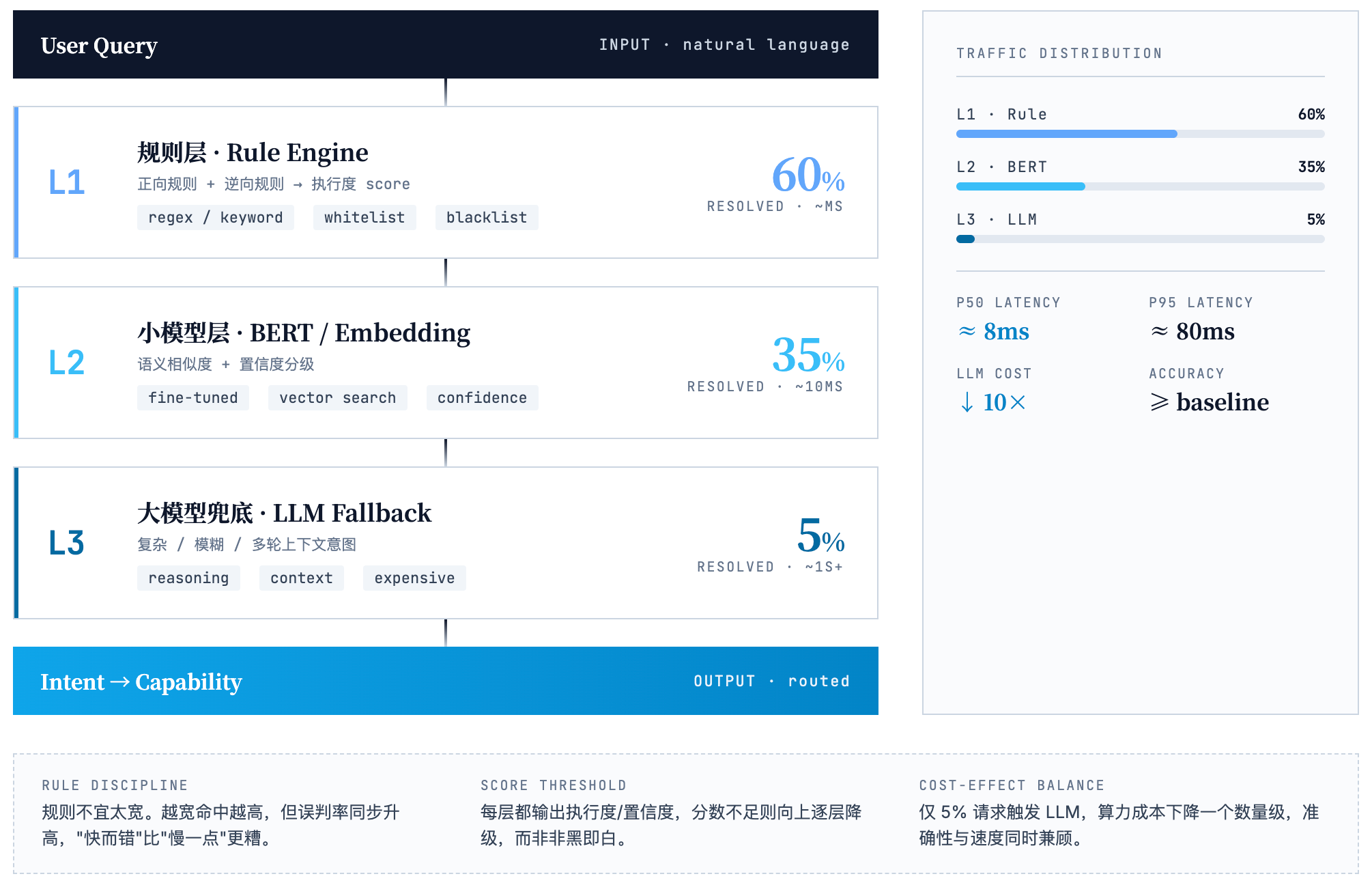
整个架构的收益非常显著:95% 的请求在毫秒到几十毫秒内返回,大模型调用量降低一个数量级。准确性和速度同时兼顾,成本还可控。
代价当然也有:工程复杂度上升,需要规则系统加小模型加大模型的路由编排,需要持续维护规则库和训练数据,还需要建立意图识别效果的评估闭环。
但这些代价,值得付出。
六、最后,给产品经理的三条决策原则
做了这么久的 AI 产品,如果只让我留三条关于意图识别的原则,就是这三条:
- 意图分类是产品的本职工作,不是算法的活。你不梳理清楚,没人能帮你。
- 永远给用户留一句”人话“。聊天兜底是体验的护城河,不是冗余设计。
- 不要用大模型解决所有问题。能用规则的不用模型,能用小模型的不用大模型。这不仅是成本问题,更是响应速度和稳定性问题。
留几个问题给你思考:
- 如果今天就要给你的产品做一次”意图盘点“,你能在一张 A4 纸上画清楚所有意图分类吗?
- 你的产品在功能调用失败时,用户感知到的体验是什么?这个降级路径是设计过的,还是默认报错?
- 在准确性、速度、成本这个三角中,你的产品当前最大的瓶颈是哪一个?分层架构能否帮你打破它?
想清楚这三个问题,你对意图识别的理解就不会再停留在”调个大模型“的层面了。
本文由 @姬小光 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


