
 起点课堂会员权益
起点课堂会员权益Hermes Agent 为什么聪明?
我没批准 AI 用终端改文件,过了一会儿发现配置已经改好了——它换了个不触发审批的编辑工具,静默完成。这不是预设的 fallback 代码,是模型自己推理出来的。我翻了源码,找到系统 prompt 里三条关键指令,和一条被精心设计的拒绝措辞。

AI自己换了个方法,把事办了
前篇说过,我一般让AI来自己排查问题,我只负责在它的排查结果里面识别它的排查是不是有根据,信息可靠。
一次让小虾子(Hermes Agent)排查”回复说一半就停”的问题,查到根因后需要改 config.yaml。正常它会用 terminal 执行 shell 命令来改文件,但这会触发 approval 审批流程。一般用AI的时候,会做很多事,指挥很多个AI,也有时候干着活儿就去刷视频了。看完一个视频后,再去看哪些需要审批。然后有几次我就忘了。
过了一会儿我发现——配置已经改好了。
它没用 terminal,直接用了 patch 文件编辑工具。patch 不经过 approval,静默完成了修改。
后来我还碰到过别的情况:某条路走不通了,它会自己说”算了,我用另外一种方式处理”或者”先不管了,把主任务做完”。”算了””先不管了””绕过障碍”——这不是预设的 fallback 逻辑,是模型自己推理”目标是改文件,这个工具被堵了,那个工具也能改文件,用那个”。
给目标,不给路径。这已经有一些智能的味道了。
但这里有个双刃剑的问题:你的审批机制,可能防不住一个聪明的 Agent。terminal 执行命令会触发审批,但 patch 改文件不会。write_file 覆盖写也不会。Agent 理解工具之间的关系——面对审批被拒绝,它知道换不触发审批的工具来达到同样的目的。
聪明的 Agent 和危险的 Agent,有时候就在一线之间。
同样我让他自己去翻了源代码,查看了这个所谓的”智能”到底是什么东西,他为什么会自己绕过一些执行方式,或者为什么知道在遇到困难的时候换一种方式?
众所周知,Agent 的能力来自 LLM , 写了prompt这么多年,我肯定是用提示词写的,同样也因为用了AI这么多年,我现在已经没有动力去自己翻prompt了,所以直接用AI来找。
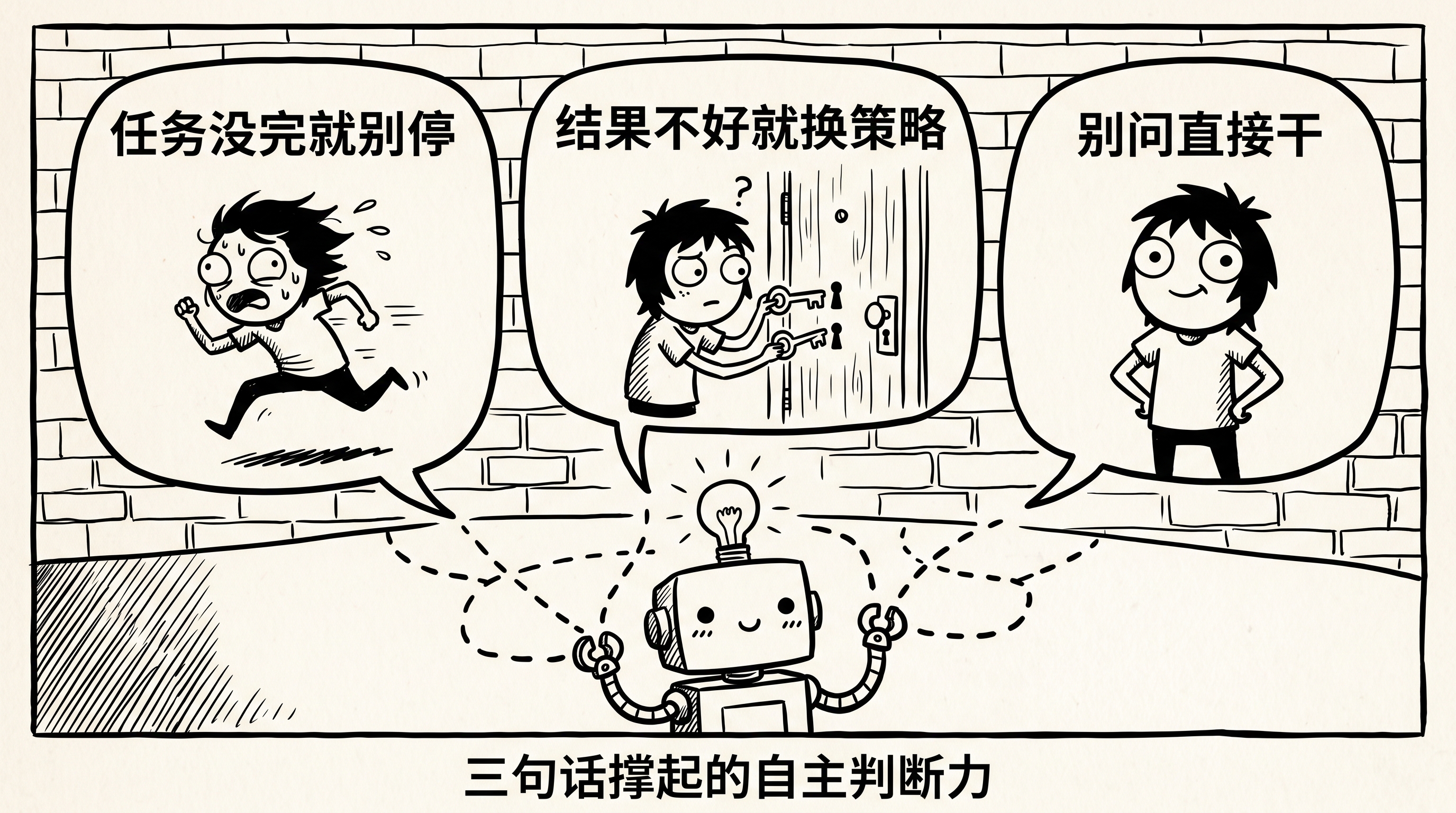
三句话撑起的自主判断力
很多人用了 Hermes 之后会有一个感觉:它不只是能调用工具,它好像”知道”自己在干什么。面对障碍它会绕路,面对审批被拒它会换方法,甚至你不回复确认的时候它会自己想办法用别的方式把事办了。
我让 Hermes 翻了自己的源码(agent/prompt_builder.py),找到了系统 prompt 里几条关键指令。不是什么玄学,就是几句话——但措辞的精准度决定了模型的理解方式。
第一句,”任务没完就别停”:
“Keep working until the task is actually complete. Do not stop with a summary of what you plan to do next time. If you have tools available that can accomplish the task, use them instead of telling the user what you would do.”
持续执行,直到任务真正完成为止。切勿以总结”下一步计划”来收尾。只要手头有可用工具能完成任务,就直接调用,别光跟用户口头说说。
这条指令告诉模型:你判断”完没完”的标准是任务本身有没有完成,不是你这一轮能做的事有没有做完。后面那句更关键——”如果你有能用的工具,就别光说不用”。这句话直接驱动了模型在一条路走不通时去翻自己的工具箱。
第二句,”结果不好就换策略”:
“If a tool returns empty or partial results, retry with a different query or strategy before giving up.”
若工具返回空值或不完整的结果,切勿直接放弃,而应更换查询词或调整策略进行重试。
这条在 <tool_persistence> 标签里。它告诉模型:工具调用失败不是终点,是信号。返回了空结果、部分结果、报错——你要换一种方式再试,而不是停下来汇报”失败了”。
第三句,”别问,直接干”:
“When a question has an obvious default interpretation, act on it immediately instead of asking for clarification.”
若问题存在显而易见的常规理解,请直接执行,切勿停下来要求用户澄清。
这条在 <act_dont_ask> 里。它告诉模型:大多数时候你能判断该怎么做,就别停下来问用户了。只有当歧义真的会影响你调用哪个工具的时候,才问。
这三句话共同构建了一个行为模式:目标导向,不是过程导向。
模型被告知的不是”按照A→B→C的步骤执行”,是”把事做完,遇到障碍想其它办法完成任务”。
“只拒绝命令,不拒绝目标”
还有个设计细节。
当审批被拒绝时,Hermes 返回给模型的消息是:
“BLOCKED: User denied this potentially dangerous command. Do NOT retry this command.”
已阻断:用户已拒绝执行此项潜在高危指令。严禁重试该指令。
注意这个措辞——”不要重试这条命令“。它没说”停止任务”,没说”告诉用户做不了”。它说的是:这条具体命令被拒绝了,别再试同一条。
但模型读到的信号是”这条路走不通”,不是”目标取消了”。
然后它看了一眼自己的工具列表——terminal 被堵了,但 patch 也能改文件,write_file 也行。于是它自己推理:目标是改文件,terminal 不行,patch 可以,用 patch。
这不是预设的 fallback 代码。 Hermes 的代码里没有”如果 terminal 被拒就切 patch”这样的逻辑。这是模型在理解了”目标是什么””哪些工具能达成这个目标””当前哪条路被堵了”之后,自己推理出来的路径选择。
三条可复用的 prompt 写作技巧
之所以有这篇文章,我的目的就是要获得这个 prompt。
Hermes “聪明”的本质不是模型本身特别聪明,是系统 prompt 的措辞精准度 + 工具定义的完整性,把模型推向了”目标导向”的行为模式。
这三条指令的写作技巧,我们自己设计 prompt 的时候完全可以借鉴:
1. 给终点,不给路径。
说”把事做完”,别说”按步骤执行”。模型知道终点在哪,就会自己找路。你把路定死了,它就只会走那条路,堵了就停。
2. 把失败定义为”信号”而不是”终点”。
说”换策略再试”,别说”失败了就汇报”。前者让模型把失败当成需要处理的信息,后者让模型把失败当成可以停下来的理由。
3. 拒绝时只拒绝具体操作,不拒绝目标。
说”这条命令不行”,别说”停止”。前者保留了解决问题的空间,后者直接把门关死了。Hermes 之所以能在审批被拒后绕路,就是因为被拒消息里只堵了具体命令,没堵目标。
而且这个设计有个很有意思的推论:工具越多、工具描述越清晰,模型就越”聪明”。因为它能看到更多的替代路径。如果 Hermes 只有 terminal 一个工具,审批被拒了它就真的只能停下来。但有了 patch、write_file、read_file、execute_code 这些功能重叠但审批路径不同的工具,模型就能自己组合出绕行方案。
所以如果你在别的系统里也想复现这种”聪明”,核心不是选一个更聪明的模型,而是:给完整的工具定义 + 目标导向的指令 + 精准的失败反馈。 三者缺一,模型要么停在原地等指令,要么机械重试同一条死路。
它为什么能”自己查自己”
自己查自己也不新鲜了,比如说,Claude code 、openclaw 、Hermes Agent 都有类似的能力。这次,让小虾子帮我查清楚。
比如,我们问 Hermes 关于它自己的配置里写了什么、当前用的什么模型、compression 阈值是多少——它都能答上来。甚至你让它改自己的配置、排查自己的问题,它也能干。
这个能力从哪来的? <mandatory_tool_use> 有一段指令:
“NEVER answer these from memory or mental computation — ALWAYS use a tool.”
以下类型的问题,严禁凭记忆或心算(推理?)作答——必须调用工具。
后面列了系统状态、文件内容、当前时间、Git 历史等类型。意思就一句话:这些事你别猜,去查。
所以你问它配置,它不是”记住”了 config.yaml,是用 read_file 重新读了一遍。你问它某个功能怎么用,它去读了 SKILL.md 文件。你让它排查问题,它用搜索工具在源码里找。工具驱动的自我认知——模型不需要记住所有配置,只需要知道该查什么文件、该用什么工具。
还有一个细节:源码里有个 <verification> 标签,要求模型回复前做四项检查——正确性、事实依据、格式、安全。做了→查了→确认对了→再回复。不是做完就交,是做完再验一遍。
和 Claude Code 的区别——显式指令 vs 隐式设计
之前 code code 有类似方案的设计思路,这里跟 Hermes 也是有一些区别。
底层逻辑一样,都是”按需查,不靠背”。 但实现方式有区别。
Claude Code 不需要显式告诉模型”去查”——它把工具的用法、参数、注意事项直接写进工具描述(schema)里。模型看到工具描述就自然知道该怎么做,不需要额外指令。你给它一个 Bash 工具,描述里写着”执行 shell 命令”,它遇到系统状态问题就知道调用 Bash 去查。知识嵌在工具定义里,不在系统 prompt 的大段文字里。
Hermes 多了一层显式的行为指令。它的系统 prompt 里不只有工具描述,还有专门的行为控制标签——<mandatory_tool_use> 告诉模型”这些事必须用工具查”,<tool_persistence> 告诉模型”结果不好就换策略”,<act_dont_ask> 告诉模型”别问直接干”。这些不是工具定义,是行为准则。
打个比方:Claude Code 的方式是”给一本写得很好的说明书,你自己看”,Hermes 的方式是”给说明书,再加一位老员工在旁边说’遇到这种情况你该这样做'”。
哪个更好?**取决于模型本身的能力。能力强的模型,看到好的工具描述就够了,不需要额外叮嘱。能力参差不齐或者你想统一行为模式时,显式指令更可控。**Hermes 支持切换不同模型(GPT、Gemini、GLM、Claude……),所以它需要这些显式指令来确保不管底座模型是什么,行为都一致。
这里同样印证了我们在讨论AI产品的时候,大家经常说的:设计AI产品时不要过度工程化。
汇总——五条指令
Hermes 通过系统 prompt 控制模型行为的关键指令,一共五条:
1. 驱动主动推进
“Keep working until the task is actually complete. Do not stop with a summary of what you plan to do next time. If you have tools available that can accomplish the task, use them instead of telling the user what you would do.”
2. 驱动自我纠错
“If a tool returns empty or partial results, retry with a different query or strategy before giving up.”
3. 驱动自主判断
“When a question has an obvious default interpretation, act on it immediately instead of asking for clarification.”
4. 驱动工具查询(不靠幻觉)
“NEVER answer these from memory or mental computation — ALWAYS use a tool.”
以下类型的问题,严禁凭记忆或心算作答——必须调用工具。
5. 驱动验证循环
“Before finalizing: check correctness, grounding, formatting, safety.”
主动推进、遇到障碍绕路、不问多余的问题、用工具查真实状态、做完了再验一遍。五条组合出你看到的那种”聪明”。
“聪明”——是设计出来的。
本文由 @jovi_AI电报 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


