
 起点课堂会员权益
起点课堂会员权益PM 如何看懂 Harness Engineering:把 Agent 的运行问题讲清楚
当AI客服Agent从简单问答进阶到复杂业务处理时,传统的Prompt调优已力不从心。Harness Engineering正成为新一代AI系统的关键框架,它将信息输入、工具调用、执行编排等能力系统化组织,让Agent真正具备业务流程的执行力与可靠性。本文从产品经理视角,拆解Harness的五大核心能力与落地检查清单,揭示AI系统从'会回答'到'能办事'的进化密码。
最近 review 一个 AI 客服 Agent 时,我一直在想一个问题:
为什么我们花了几个月调 Prompt、换了几版模型、加了知识库,效果时好时坏,但只要场景一复杂——比如要 Agent 接订单、判断退款资格、跨系统跑流程——它就不稳定?
后来我意识到,这不是 Prompt 的问题,也不只是模型的问题。是 Agent 周围那一整套运行系统的问题。
这套系统最近有了一个名字:Harness Engineering。
这篇文章是我作为 PM,重新理解这个新概念后整理的笔记——不讲技术细节,只回答一个问题:当 Agent 真的进入业务流程,PM 应该如何看懂它的运行系统?
Harness 到底是什么?
要理解 Harness Engineering,最好先把它跟 Prompt、Context、Memory 放在一起看。
Prompt 是任务指令,Context 是当前决策的信息环境,Memory 是跨任务或跨会话的状态沉淀,Harness 则是把这些能力组织起来的系统级运行环境。
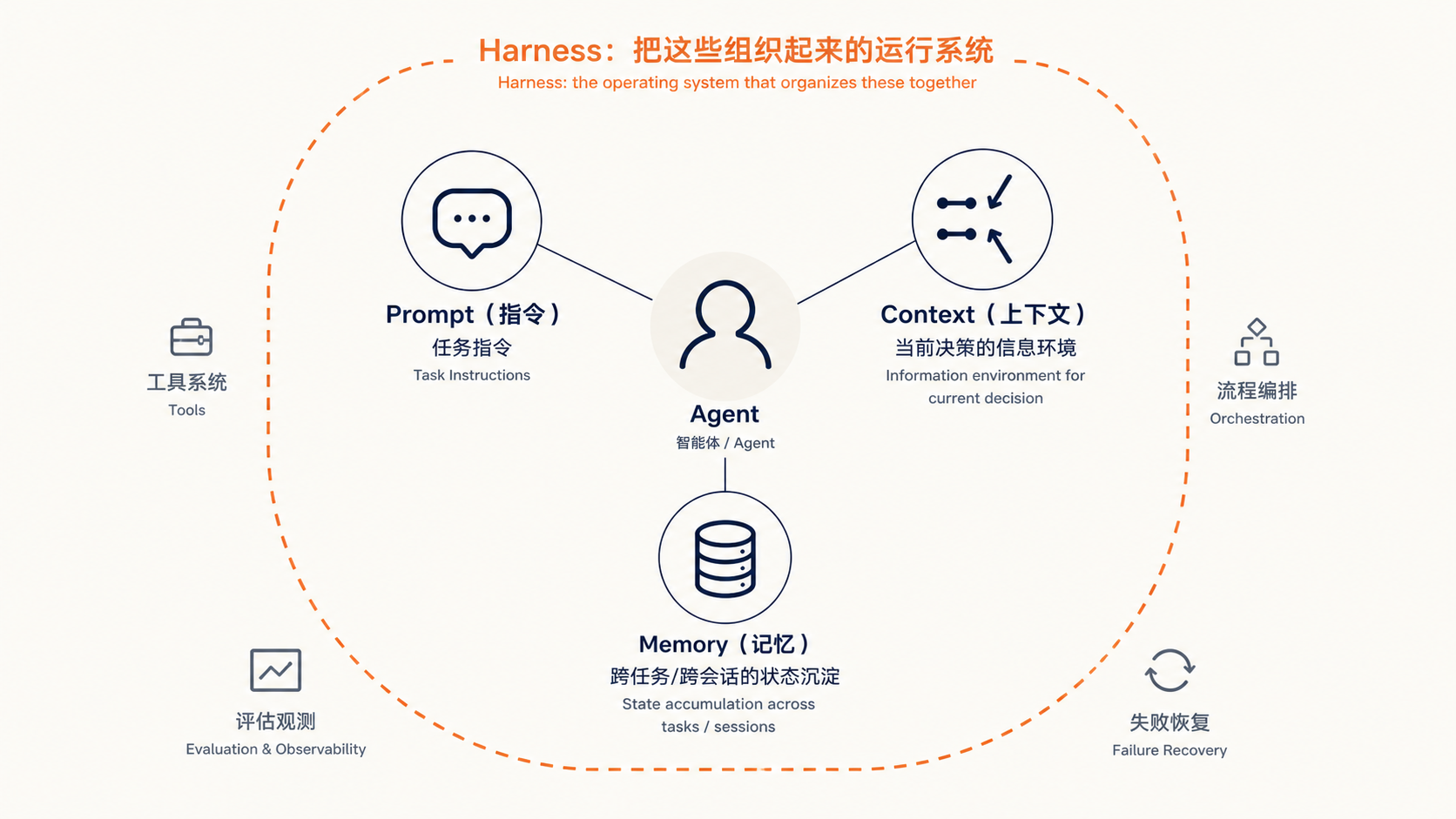
这套能力并不全是新东西,新的地方在于:当 Agent 成为执行主体后,原本分散在产品、工程、测试、运营里的约束,需要围绕 Agent 的运行过程重新组织。
这里还有一个容易被忽略的点:这些关注点的变化,并不是工程师主动选择出来的,而是模型能力扩展后被推出来的。
模型只能输出几百字时,”怎么说”是工程主战场;上下文窗口扩到几十万 token 时,”该看到什么”才值得专门讨论;模型能调用工具、影响真实业务系统后,”运行边界”和”失败兜底”才成为绕不过去的问题。
模型能触达的东西越来越多,配套的工程约束就必须越来越清楚。也正因为这套约束还在被快速重组,Harness 现在还不是一个完全标准化的术语
OpenAI、Anthropic、LangChain 在不同文章里使用这个词时,侧重点并不完全一样;它和 Agent Framework、Agent Runtime、Orchestration Layer 这些说法也会有重叠。
所以这篇文章不把 Harness 当成严格定义,而把它当成一个观察视角:当 Agent 从回答问题走向执行任务时,系统需要哪些运行约束、评估机制和失败恢复。
▲ Prompt、Context、Memory 不是被 Harness 取代,而是被 Harness 组织起来,和工具、流程、评估、失败恢复一起构成 Agent 的运行系统。
如果给一个直观定义:
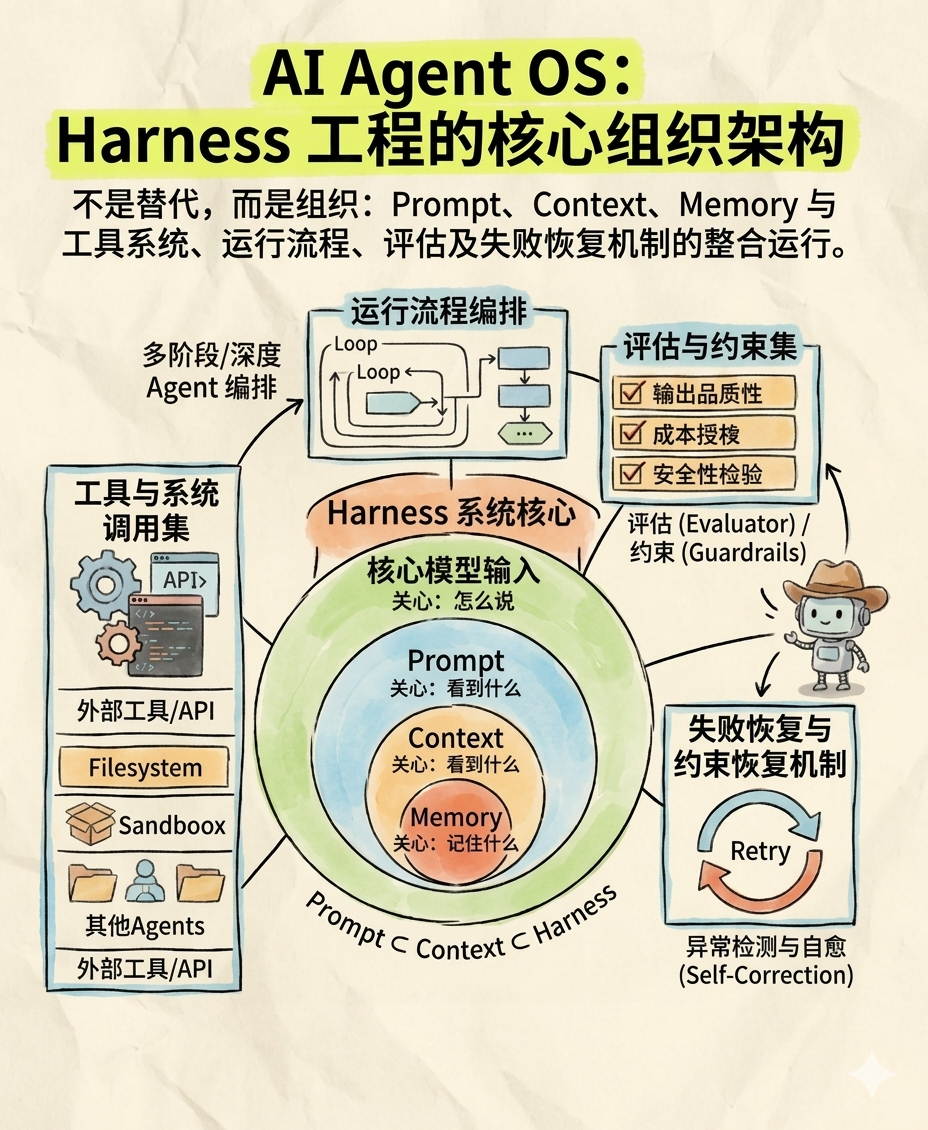
Harness 是围绕 Agent 搭建的运行系统。它把 Prompt、Context、Memory、工具调用、流程编排、评估观测、失败恢复这些原本散落的能力组织起来,让 Agent 不只是”会回答”,而是能在一定约束下持续完成任务。
从 PM 评估角度,可以先把 Harness 拆成 5类能力来看:
- 信息输入(Prompt + Context + Memory)—— 决定 Agent 看到什么、记住什么
- 工具系统 —— Agent 可调用的搜索、数据库、浏览器、业务 API;含权限边界(哪些只读、哪些能写、哪些必须用户确认)
- 执行编排 —— 任务怎么拆、按什么顺序走、什么时候回看
- 评估与观测 —— 结果是否符合标准、过程是否可追踪、质量能否归因
- 约束与失败恢复 —— 异常时是重试、降级、转人工,还是终止
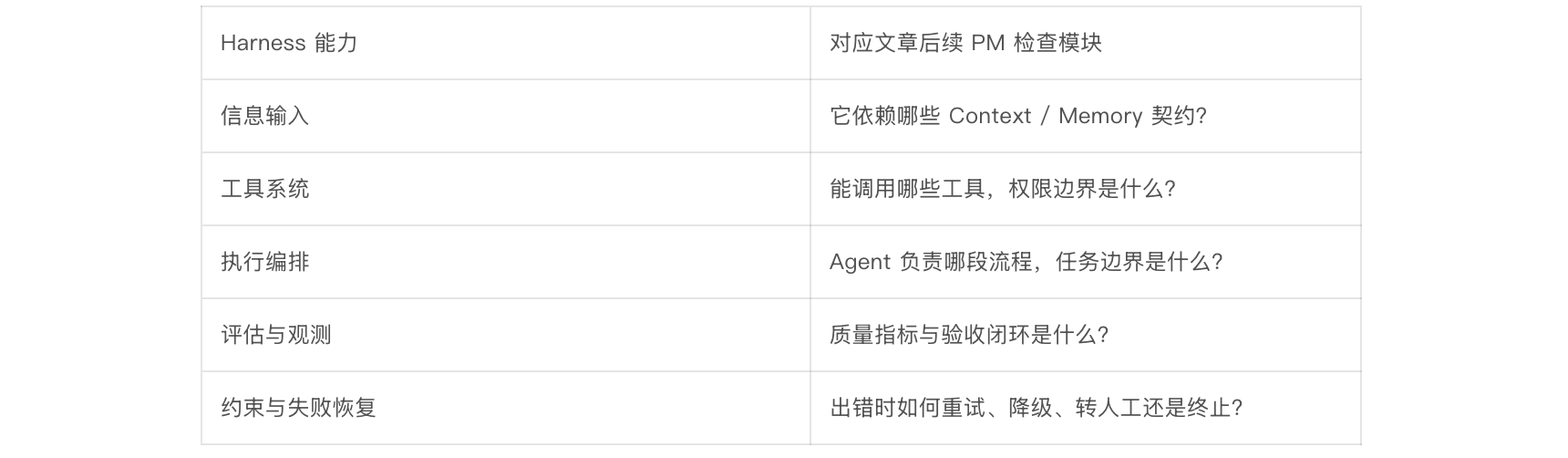
这 5类能力和后文的 PM 检查模块并不是两套东西,而是一组能力和一组问题的对应关系(这里先做个与后续文章内容的映射):
一个客服 Agent 为什么会引用错知识库?
我们先用一个具体例子来看 Context 和 Harness 的关系。
很多人第一次看到 Context,会自然翻译成”上下文”。这个翻译没有错,但在 Agent 场景里,它比聊天窗口里的前后文更大。
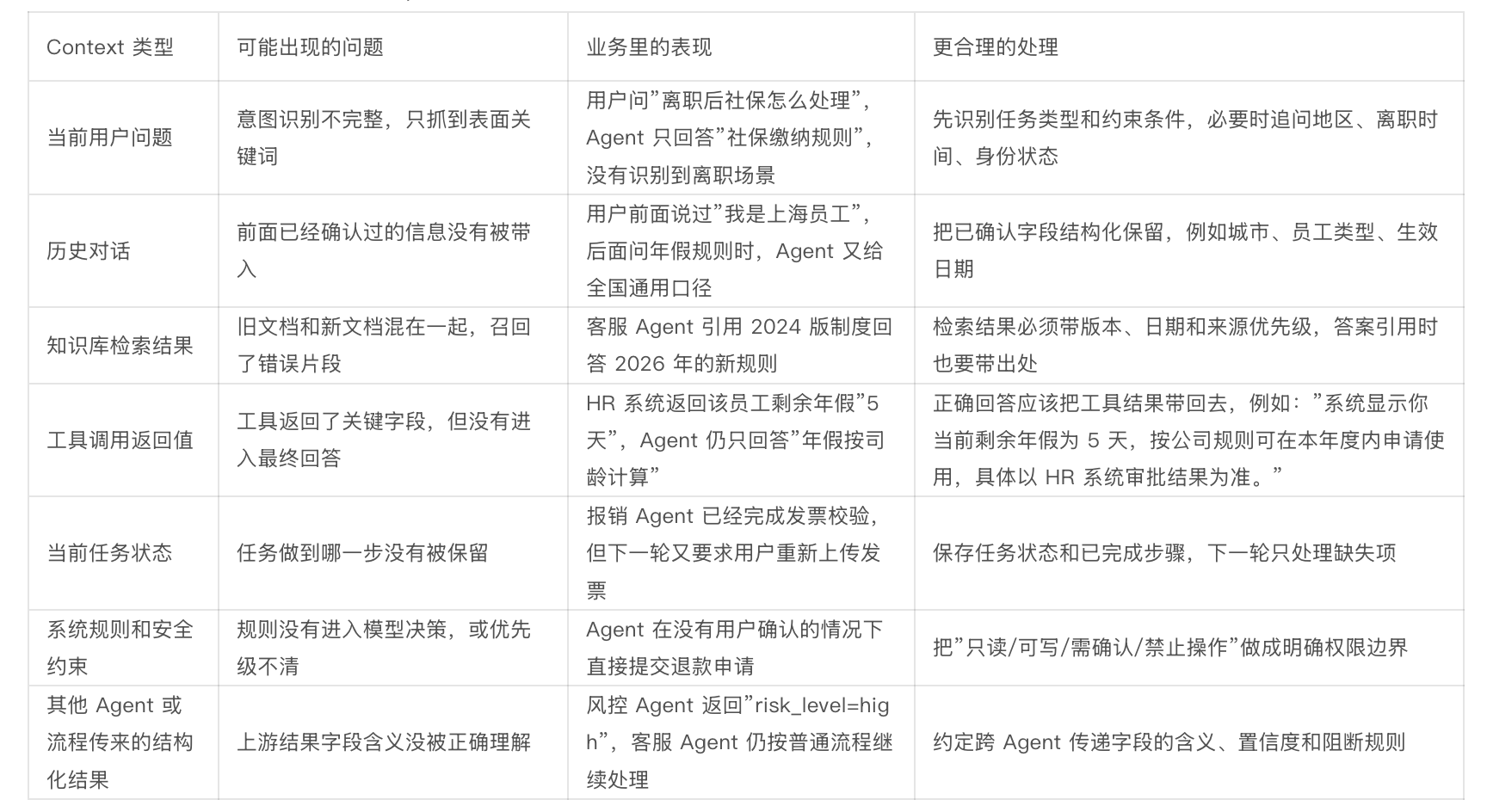
Context 更像是模型做当前决策时能看到、能使用、会受影响的全部信息环境。它可能包括:
- 当前用户问题
- 历史对话
- 知识库检索结果
- 工具调用返回值
- 当前任务状态
- 系统规则和安全约束
- 其他 Agent 或流程传来的结构化结果
每一类 Context 都可能出问题,而且问题长得不太一样:
回到客服 Agent 引用错知识库这个例子,它可能不是单点问题,而是一条链路问题:Prompt 没限定回答口径,Context 召回了错误文档,Memory 沿用了旧状态,Harness 又没有把版本校验、引用检查和失败兜底做成系统机制。
这里还要区分一个细节:
给 chunk 加 version_id、status=current、access_level、visible_dept 这类标签,本身更像 Context Engineering / RAG 治理。它让信息可以被筛选、追溯和权限过滤。
Harness 要做的,是确保系统真的使用这些标签。比如检索时强制过滤 status=current,回答时必须带出处,权限不匹配时必须拒答或转人工,失败 case 要能回流到评估样本里。
换句话说,版本号、状态、权限标签本身属于 Context 治理;Harness 要做的是把这些治理规则变成运行时约束:检索时必须过滤,引用时必须带出处,权限不匹配时必须拒答或转人工(兜底策略)。
这几个层次的责任不一样:
- Prompt 管“怎么说”
- Context 管“看到什么”
- Memory 管“哪些信息要保留、继承和更新”
- Harness 管“系统如何组织这些信息与动作,并尽量保证它别看错、别乱用,错了还能被发现”
这也是为什么,到了 Agent 阶段,产品经理只问”提示词怎么写”往往是不够的。
PM 为什么需要理解 Harness?
对 PM 来说,理解 Harness 不是为了多掌握一个技术名词,而是为了把 Agent 的运行问题转译成产品边界、协作机制和验收标准。
如果把 Prompt、Context、Memory、Harness 这些概念落到 PM 自己的工作里,会发现关心的事情其实很不一样。
这些不是纯工程问题。它们会反过来影响产品边界、用户体验、权限设计、运营流程和交付标准。
举个具体场景:当工程师跟你说”我们打算给这个 Agent 加一个评估模块”时,PM 不应该只问”什么时候上线”。
不是加了 Harness 就自然解决质量问题,而是当团队决定把评估、观测、回流做进 Harness 时,PM 要参与定义这些机制服务什么产品目标。
pm应该思考:
- 这个评估是上线前的一次性验收,还是要做成长期运行时的观测?两种 Harness 形态在投入和产品边界上完全不同。
- 当评估在运行时发现 Agent 输出有问题,系统应该直接降级、转人工,还是只记日志让人事后看?这决定评估和失败恢复怎么联动。
- 评估过程对终端用户是有感还是无感?比如 Agent 在自我核对答案时,用户应该看到“处理中”还是看到一段“我正在确认引用来源”的解释?
- 失败 case 回流到哪里:提示词、知识库、工具权限,还是任务流程?这是 Harness 闭环的入口,也决定了产品迭代的节奏。
- 这套评估的产品成本谁来扛?业务方是否愿意为它的合格样本投入标注时间?长期没人维护的指标,会反过来稀释 Harness 的可信度。
能把这些问题问出来,PM 才不是在旁边”听工程方案”,而是在把 Harness 的工程能力转译成产品质量标准。
用 5 个模块检查一个 Agent 的 Harness
为了避免把 Harness 讲成一个抽象概念,可以把它转成一组 PM 能使用的检查问题。这不是标准答案,更像一个当前阶段的评估框架。
1. 这个 Agent 的任务边界是什么?
Agent 最怕任务边界模糊。这里的”边界”不是一句”它负责回答还是执行”就能说清楚,最好放到具体业务流程里判断。
比如做一个售后客服 Agent,用户说:”我这个订单能不能退款?”
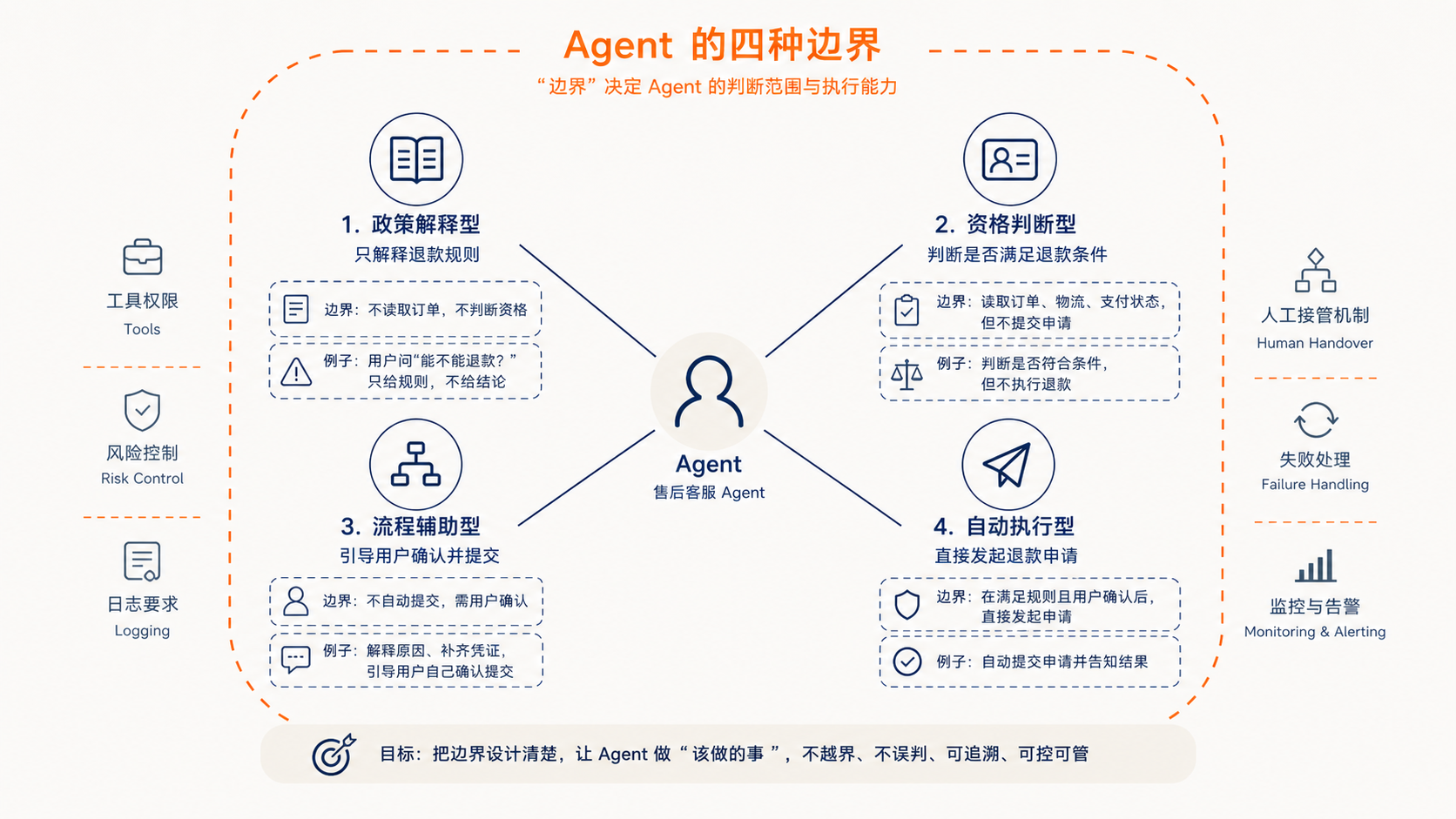
这个 Agent 至少可能有四种边界:
- 政策解释型:只解释退款规则,不读取订单,不判断资格。
- 资格判断型:读取订单、物流、支付状态,判断是否满足退款条件,但不提交申请。
- 流程辅助型:帮用户整理退款原因、补齐凭证,引导用户自己确认提交。
- 自动执行型:在满足规则且用户确认后,直接发起退款申请。
这四种看起来都叫”退款 Agent”,但产品边界完全不同。它们需要的工具权限、风险控制、日志要求和人工接管机制也不一样。
所以 PM 不仅是关注”这个 Agent 能不能帮用户退款”,也需要关注:
- 它在退款链路里负责哪一段:解释规则、判断资格、辅助提交,还是自动执行?
- 哪些节点必须用户确认,哪些节点必须人工客服接管?
- 它是否可以读取订单、支付、物流、售后历史?哪些只能读,哪些可以写?
- 当规则不明确、金额过高、用户情绪异常、命中风控时,它应该暂停还是升级?
- 它输出的是“处理建议”、“可执行方案”,还是“已经触发的业务动作”?
任务边界越清楚,后面的工具权限、验收标准和失败处理才越容易定义。
2. 它可以调用哪些工具?不能调用哪些工具?
Agent 一旦能调用工具,问题就不再只是”回答质量”。
它可能搜索网页、读取知识库、调用数据库、操作页面、发送消息、创建工单、提交表单。每多一个工具,Agent 的能力上限会提高,风险也会增加。
PM 不需要替工程师设计每个接口,但需要和团队一起确认:
- 哪些工具是必要的?
- 哪些工具只能读,不能写?
- 哪些动作需要用户确认?
- 哪些调用需要留日志?
- 工具失败时,Agent 是重试、换路径,还是停止?
工具不是越多越好。真正重要的是:工具调用是否服务于任务,权限边界是否清楚,结果是否能被追踪。
3. 它依赖哪些 Context / Memory 契约?
很多 Agent 的问题不是”不聪明”,而是”看错了信息”或”记错了状态”。
Context 关注当前任务需要哪些信息进入模型视野;Memory 关注哪些信息应该被保留、继承和更新。
这里的重点不是重新列一遍 Context 来源,而是把信息契约定义清楚。PM 可以追问:
- 这个任务需要哪些背景信息?
- 知识库内容有没有版本区分?
- 用户偏好、历史操作、任务进度哪些需要记住?
- 哪些只是临时信息,不应该进入长期记忆?
- 当任务中断后,系统如何恢复到正确状态?
这里尤其要避免一个误区:不是记得越多越好。
好的 Memory 不是把所有东西都存起来,而是知道什么应该被保留,什么应该被遗忘,什么只在当前任务里有效。
4. 它的质量指标与验收闭环是什么?
如果一个 Agent 的验收标准只是”回答看起来还不错”,那后续很难稳定迭代。
PM 需要把成功标准拆成可验收的质量维度,而不是停留在主观感受上。可以从这些维度开始定义:
- 任务完成率(Task Completion Rate):Agent 是否完成了目标任务,而不是只生成了一段看似合理的文本。
- 答案准确率 / 事实一致性(Accuracy / Factual Consistency):关键事实是否与知识库、业务系统或人工标注答案一致。
- 引用可追溯率(Citation Coverage):需要引用制度、文档、订单或工具结果时,是否给出了可追溯来源。
- 流程合规率(Policy Compliance):是否遵守业务规则、权限边界和格式要求。
- 工具调用成功率(Tool Call Success Rate):工具是否在正确时机被调用,返回结果是否被正确使用。
- 人工接管率与接管原因(Human Handoff Rate):哪些场景需要转人工,转人工是否发生在正确节点。
- 异常恢复率(Recovery Rate):工具失败、信息缺失、规则冲突时,系统能否重试、降级或给出明确兜底。
对于不同类型的 Agent,成功标准也不一样。
知识库问答可能更看重准确率、引用可追溯率和拒答准确率;报告生成可能更看重结构完整度、证据覆盖率和事实一致性;流程型 Agent 可能更看重任务完成率、工具调用成功率、权限合规率和异常恢复率。
也就是说,”成功”不是一个形容词,而是一组需要提前定义的验收指标。
同时,指标不能只停留在看板上。PM 还要把验收闭环提前放进产品设计里:
- 是用户验收,运营验收,还是系统自动验收?
- 哪些结果需要人工复核?
- 哪些指标可以自动观测?
- 过程日志是否能回放?
- 出问题后能不能定位是模型、工具、上下文还是流程的问题?
- 失败样本进入哪里:人工复核、产品需求池,还是提示词、知识库和工具链路的迭代?
5.出错时是重试、降级、转人工,还是终止?
真实任务里,失败不是异常,而是常态。
搜索结果不准、接口超时、文档版本混乱、用户输入不完整、模型误解指令,这些都会发生。
所以 PM 需要提前定义:
- 哪些错误可以自动重试?
- 哪些错误需要换一种工具或路径?
- 哪些情况必须转人工?
- 哪些动作应该直接终止?
- 用户看到的失败提示是什么?
- 系统是否保留失败原因,方便后续分析?
这部分很像传统软件里的异常处理,但在 Agent 场景里更复杂,因为错误可能来自模型、工具、上下文、流程设计,也可能来自用户输入。
如果没有失败恢复机制,Agent 每次出错都只能”重新来一遍”。这对真实产品来说是不够的。
一个可落地的 Harness 描述示例
如果把上面的内容落到需求文档里,可以不用一上来写很复杂的系统架构,先把关键约束描述清楚。
仍然以售后退款 Agent 为例,一个最小可用的描述可以这样写:

这段描述不是工程实现方案,但它能把产品边界、工具权限、运行约束、状态恢复、失败兜底和评估回流先钉住。工程同学后续怎么拆服务、怎么做日志、怎么接评估平台,才有明确的产品约束。
Harness 要做到什么程度,取决于任务风险
Harness 的价值是真实的,但它的实施成本同样真实。这里不建议把问题说成”要不要 Harness”,因为只要 Agent 进入产品系统,多少都会有运行边界、工具约束和结果校验。
更值得 PM 判断的是:当前任务需要多完整的 Harness。
比如内部知识查询助手,通常可以先把任务边界、知识库版本、引用溯源和人工反馈做好;它未必一开始就需要完整的状态机、自动评估平台和复杂的失败恢复链路。但如果是自动审批、售后处理、代码修改或业务流执行这类跨多轮、有写操作、会影响真实业务结果的 Agent,就需要更完整的运行约束和人工接管机制。
所以 PM 真正要判断的,不是给项目贴一个”有没有 Harness”的标签,而是根据任务风险、链路长度、工具依赖和验收难度,决定这套运行系统要做到什么完整度。
Harness Engineering 的价值,可能不在于提供一个标准答案,而在于提醒产品经理:当 Agent 进入真实流程,产品定义不能只停留在”它要回答什么”,还要进一步说明”它如何运行、如何被约束、如何被验证,以及失败时如何被接住”。
所以,PM 理解 Harness,不是为了把工程实现细节全部接过来,而是为了把 Agent 的运行问题转译成产品边界、验收标准和协作机制。一个 Agent 能不能落地,不只看它能不能生成一个好答案,还要看它的边界、上下文、工具、评估和失败恢复是否可控。
本文由 @肥源 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


