
 起点课堂会员权益
起点课堂会员权益你的AI产品,真的需要那么大的模型吗?
大模型产品的落地难题正在困扰越来越多团队:高昂的API账单、难以忍受的响应延迟、敏感数据的合规风险...这些看似分散的痛点背后,都指向同一个关键解法——模型蒸馏。本文通过K12教育产品的实战案例,揭秘如何让AI在特定场景下实现『小体积大智慧』,用1/10的成本获得更精准的效果。

一、开篇:账单、延迟、和那句”数据不能出去”
你花了不少时间,终于把大模型接进了产品里。
上线那天,团队里气氛挺好,老板也点了头。但没过多久,新的问题一个接一个冒出来——
用户开始抱怨,说”怎么这么慢,等半天才出结果”;技术同学发来一张截图,是这个月的 API 账单,数字后面跟了好几个零;企业客户那边更直接,开口第一句话就是:”我们的学生数据,绝对不能传到外部服务器。”
这三个问题,表面上看起来各不相同,但背后指向同一个根源——你用的模型,对这个场景来说,太大了。
很多人容易陷进一个误区:大模型 = 好产品。仿佛只要接了最顶级的模型,产品质量就有了保障。但现实是,模型越大,推理越慢、成本越高、部署越难。对绝大多数 AI 产品来说,用户真正需要的不是”全球最强的模型”,而是”在这个场景下,足够好、足够快、足够便宜的模型”。
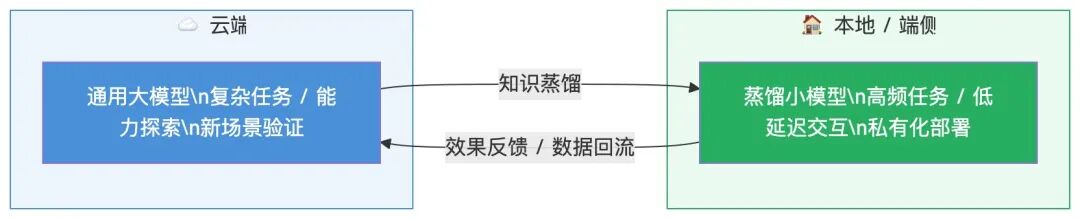
今天想聊的这项技术,叫模型蒸馏。它不是让 AI 变笨的技术,而是一门让 AI 学以致用的艺术——用更小的体积,承载更多的智慧。
二、What:蒸馏到底是咋回事?
先不说技术,讲个场景。
假设你要学厨艺,有两种方式。
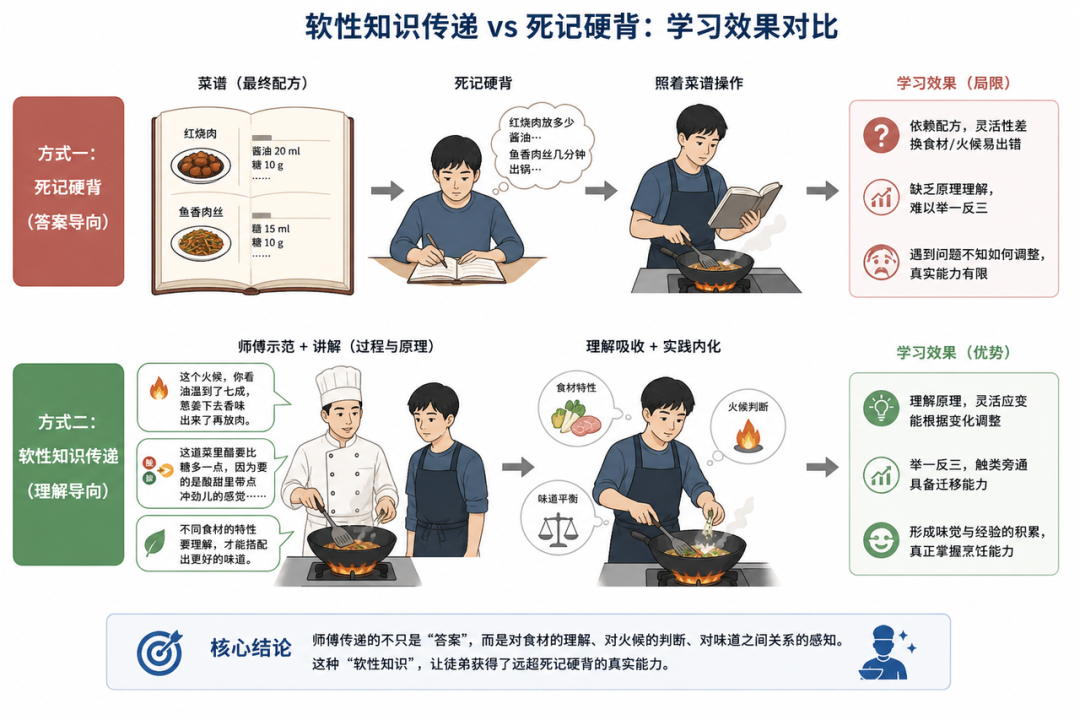
模型蒸馏的原理,和这个完全一致。
在 AI 的世界里,传统训练方式就像第一种:模型看到一道题,对着标准答案学,”这张图是猫,那张图是狗”,只学结果,不学过程。而蒸馏不同——它让一个小模型(学生模型)去学习大模型(教师模型)输出的概率分布,也就是大模型”思考时的犹豫”。
举个例子,识别一张模糊的图片,大模型不会只说”这是猫”,它会说:”这是猫的概率是 78%,是狐狸的概率是 17%,是其他动物的概率是 5%。”这个概率分布,就是大模型对这张图片的理解方式,它包含了大量关于类别间相似性的隐性知识。
这就是蒸馏里的关键概念——软目标(Soft Label),对应的是传统训练里只有 0 和 1 的硬目标(Hard Label)。
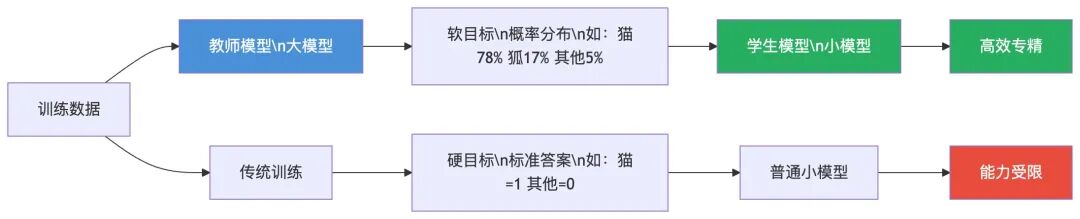
用一句话来总结:蒸馏传递的不是答案,而是思考方式。小模型不是大模型的残次品,而是针对特定场景精准培养出来的”专科高手”。
这也解释了为什么 DeepSeek 能用 37B 参数的模型蒸馏出 7B 的小模型,性能却能硬刚别家 70B 的模型——因为它学的是大模型的推理逻辑,而不是在死背答案。
三、Why:产品经理为啥必须关心这件事?
行,道理讲完了,咱说说更实在的。
大模型是天花板,但不是地基。
对产品经理来说,关心蒸馏的原因不是技术情怀,而是它直接影响产品的成本、体验、合规和市场。有四个现实压力,迟早你都得面对。
成本压力:账单会让老板沉默三秒
以目前市面上主流大模型的定价来看,顶级模型的推理成本是轻量模型的 15 到 20 倍。对于一个日活用户数量可观、每次交互要消耗大量 token 的产品,这个差距意味着每个月几十万甚至更多的开销差异。
早期靠融资补贴算力成本,这条路走得通。但商业化阶段,你必须面对这个问题。蒸馏出一个专属小模型后,推理成本通常可以降低 60% 到 90%,这不是技术指标,这是产品能不能持续活下去的关键。
速度压力:用户等不了两秒
Nielsen Norman Group 早就有研究结论:超过 1 秒的响应延迟,会打断用户的思维流;超过 10 秒,用户注意力完全流失。大模型的推理天然慢,而蒸馏后的小模型推理速度通常可以提升 3 到 10 倍。
对于实时对话、内容批改、输入联想这类场景,速度本身就是核心产品体验——不是加分项,是及格线。
合规压力:数据不出门是红线
教育、金融、医疗、政务类产品,数据合规不是”最好能做到”,而是”必须做到”。用户数据、学生数据不能传输到外部云端服务器,这是监管要求,也是客户的硬性条件。
通用大模型的云端 API,在这类场景下根本无法使用。蒸馏出的小模型可以完整部署在客户内网,甚至单台普通 GPU 服务器上。这不是技术选择,而是打开特定市场的前提条件。
场景专注压力:通用不等于精准
通用大模型”啥都懂一点”,但对垂直场景的细粒度理解未必精准。一个在特定场景上蒸馏过的小模型,因为训练数据来自真实业务,对领域内的判断反而可能比通用大模型更准。
这四个压力,不是同时爆发的,但迟早都会找上门。提前想清楚蒸馏这条路,是产品经理应该有的前瞻性。
四、How:一个K12教育产品的蒸馏实践
光说道理没用,咱来说个具体的。
我们团队在做一款面向 K12 教育场景的 AI 产品。产品逻辑说起来不复杂:学生在平台上做测试,AI 负责批改,然后把一个班里哪个知识点大多数同学没掌握好这件事,整理清楚反馈给老师,老师根据这个来决定明天要重点讲什么内容。
听起来挺顺的,但真正做起来,问题可不少。
发现问题:大模型在这里”水土不服”
产品上线初期,我们直接调用通用大模型来完成批改和知识点判断。但很快,三个问题浮出水面。
第一个问题,慢。学生提交测试之后,老师那边收到反馈要等好一阵子。这在课堂场景下是不能接受的——老师下课前想看今天的情况,等不了那么长时间。
第二个问题,贵。一个班 40 个学生,每人做 20 道题,大模型逐题批改,调用次数一算,成本就上去了。如果平台上有几十个学校、几百个班级同时在用,账单会是什么样子,想想就头大。
第三个问题,不够准。通用大模型对”二次函数”和”一元二次方程”在初中课标里的层级关系,理解得并不精确。它知道这两个概念,但不知道在河南省人教版八年级下册里,这两个知识点的教学顺序和考察侧重是什么。这种”通而不精”的问题,在 K12 场景里会直接影响老师的教学决策。
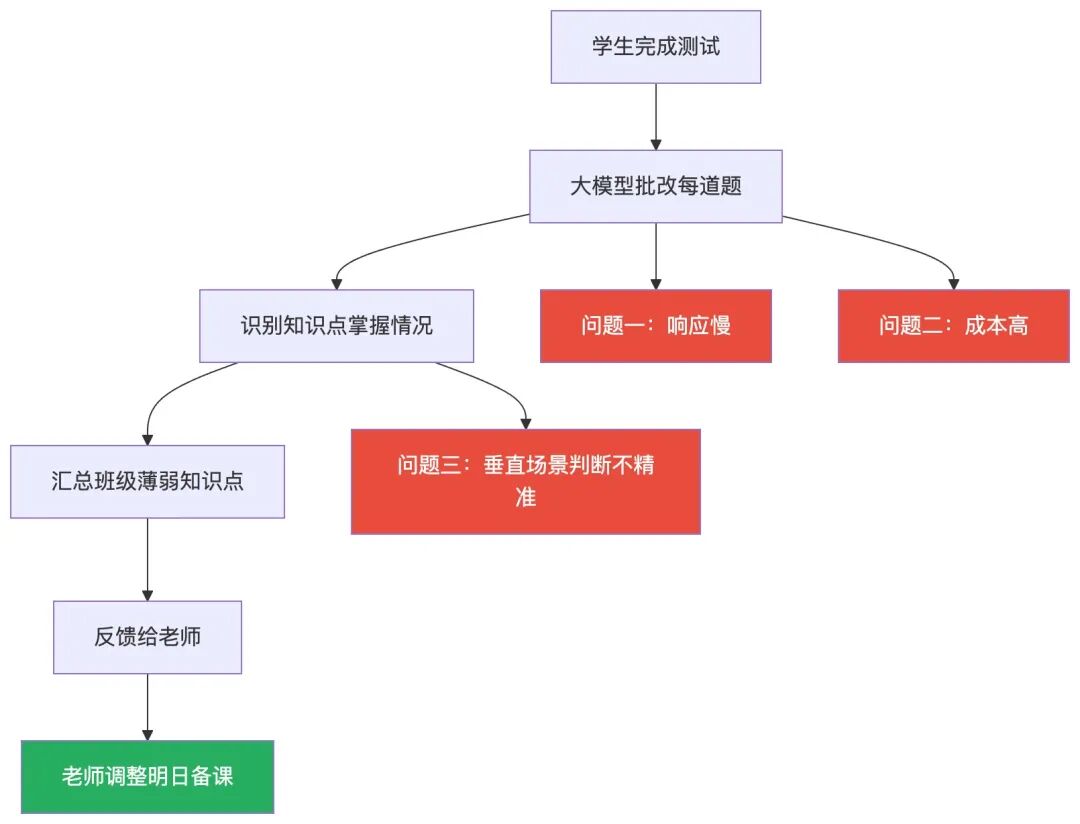
蒸馏方案:让大模型”带出”一个专科小模型
面对这三个问题,蒸馏给出了一个系统性的解法。
思路是这样的:大模型的能力是真实的,它对题目的理解、对知识点的判断是有价值的。我们要做的,不是放弃大模型,而是让大模型把它的能力传授给一个专门为这个场景训练的小模型。
具体分三步走:
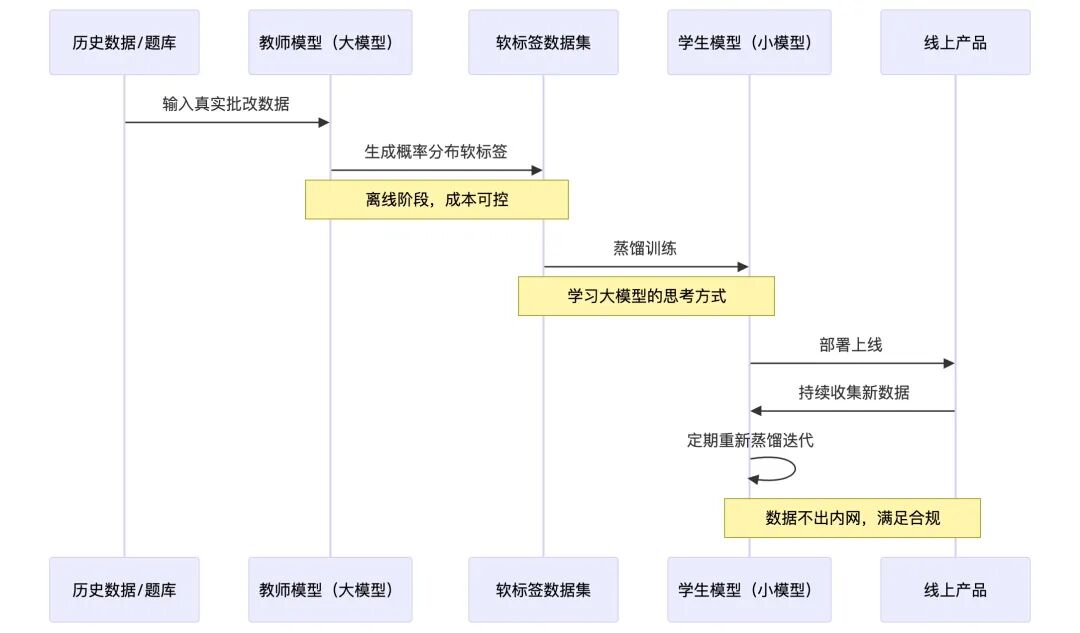
第一步,用大模型生成高质量软标签。把平台上积累的历史批改数据,以及按照课标整理的 K12 题目库,喂给大模型,让它对每道题输出详细的知识点判断和掌握度评估,生成带概率分布的软标签。这个过程是离线的,不影响线上响应速度,成本可控。
第二步,蒸馏出专属小模型。选一个参数量更小的开源基座模型,用上一步生成的软标签数据进行蒸馏训练。这个小模型的训练目标很专一——它不需要会写诗,不需要懂历史,只需要在”K12 学科知识点掌握度判断”这一件事上做到足够好。
第三步,线上部署 + 持续迭代。蒸馏后的小模型部署在本地服务器上,学生数据全程不出内网,满足合规要求。同时建立监控机制,随着平台数据积累,定期重新蒸馏,让模型持续进化。
落地效果:小模型反而更”中”
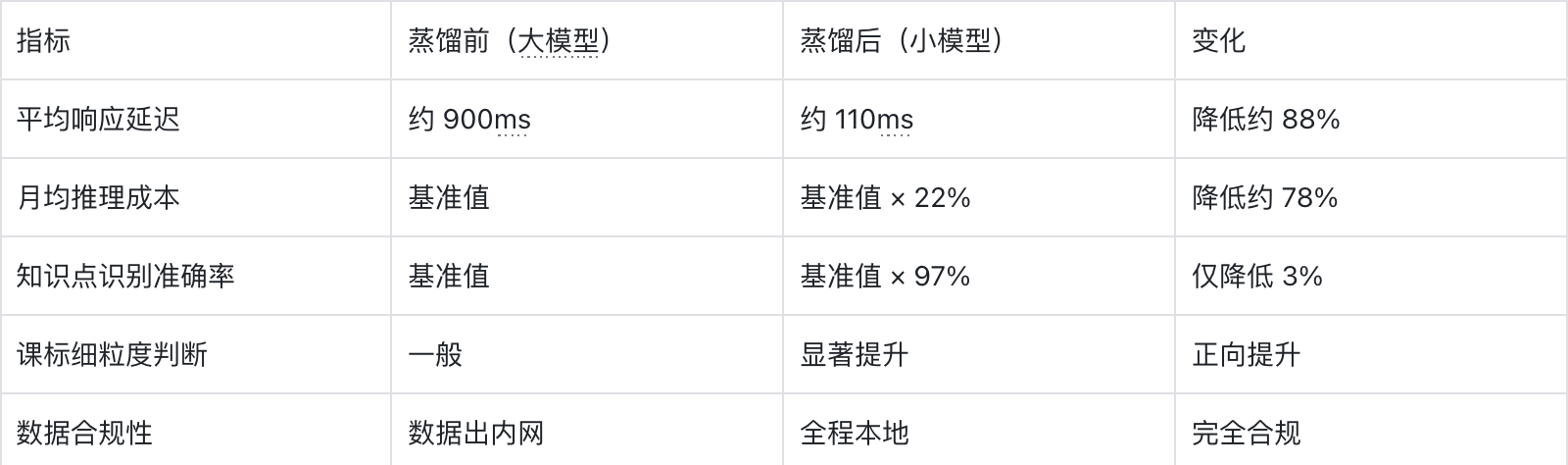
结果有点出乎意料——蒸馏后的小模型,在知识点判断的准确率上,不仅没有明显下降,在部分学科的细粒度判断上,反而比通用大模型更准。
这其实是有道理的。训练数据来自真实课堂,包含了大量学生的非标准表达、地方教材的特殊表述方式,以及课标体系下的知识点层级关系。这些东西,通用大模型不一定见过,但我们的专属小模型,全学到了。
用河南话说,这个小模型真的是”中”——不是将就,是真的合适。
三个决策值得复盘
回过头看,这个项目里有几个关键决策是对的,值得单独说一下。
一是坚持用真实数据,不用合成数据。团队讨论过用大模型批量生成模拟题目来降低数据成本,但最终还是坚持用线上真实数据。事实证明,真实数据里那些”非标准表达”和”地方教材特殊术语”,是合成数据根本覆盖不了的,也是小模型最终能超越通用大模型的核心原因。
二是把”课标细粒度准确率”单独列为评估指标。如果只看整体准确率,很容易掩盖领域适配的问题。正是因为专门建立了这个评估维度,才发现并解决了通用大模型在 K12 知识点体系理解上的盲点。
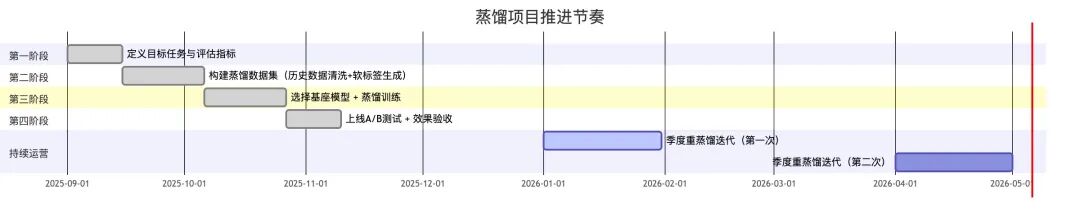
三是建立季度重蒸馏机制。随着平台上新学科、新题型的不断扩展,模型需要持续吸收新的领域知识。把重蒸馏纳入常规迭代节奏,而不是等到效果明显下降后再补救,是这个项目里最值得借鉴的运营经验。
五、写在最后:蒸馏思维,是一种资源分配的智慧
模型蒸馏的本质,是一种资源分配的智慧。
不是所有场景都需要最强的模型。真正的产品力,不是接了多大的模型,而是能不能把模型的能力,高效地转化为用户真实感知到的价值。
对产品经理来说,理解蒸馏不是为了自己去写训练代码。而是为了在产品设计、技术选型、商业决策里,有更清晰的判断框架——当技术同学说”我们需要做蒸馏”,你能听懂他们在解决什么问题;当老板问”为什么 API 成本这么高”,你知道蒸馏是解题思路之一;当企业客户说”数据不能出去”,你清楚这条路走得通。
大模型时代,AI 产品的竞争不只是模型能力的竞争,更是把模型能力高效转化为产品价值的能力的竞争。蒸馏,正是这种转化能力的核心工具之一。
下次当你面对”要不要接大模型”的决策时,不妨多问自己一句——
这个场景,值得蒸馏吗?
本文由 @兜得Grace 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


