
 起点课堂会员权益
起点课堂会员权益腾讯CodeBuddy实战手记:体系化应用开发的四个坑与我的解法
腾讯CodeBuddy作为AI编程助手,在单点提效上表现惊艳,但面对企业级复杂项目时却暗藏四大深坑——从上下文污染到自动熔断机制,每个陷阱都可能让开发效率不升反降。本文以实战踩坑经验为基础,不仅揭露CodeBuddy在体系化开发中的真实短板,更给出包含强制断点、任务拆解、上下文治理等六步SOP,为技术团队提供从单兵作战到规模化落地的完整解决方案。
从传统软件实施到后来的财务系统产品设计,再到最近两年死磕AI工具提效,我们算是见证了几波技术浪潮。近两年年各企业团队开始全面尝试用AI辅助做体系化应用开发,腾讯的CodeBuddy自然成了重点研究对象。
说实话,用CodeBuddy做单个函数补全、写个单元测试,体验确实丝滑。但一旦进入体系化应用开发——多轮对话、跨文件修改、复杂业务逻辑迭代——问题就一个个冒出来了。有些坑,我反复踩了三四遍才摸清门道。
这篇文章,把我这段时间的血泪经验摊开来,既说问题,也给解法。如果你是技术负责人、信息化管理者,或者正在用CodeBuddy做复杂项目的开发者,应该能省不少弯路。
一、为什么偏偏是CodeBuddy?
先交代一下选型逻辑,不然后面的吐槽没根。
我们团队当时对比了几款工具,最终锁定CodeBuddy,核心就三点:
第一,它不只是个插件,而是三形态覆盖。 插件形态能嵌入我们现有的VSCode和JetBrains工具链;IDE形态适合从零搭建新项目;CLI形态能塞进CI/CD流水线,做批量重构和自动化任务。
这种灵活性,对已经有成熟研发体系的团队来说,比单一形态的工具更友好。
第二,模型可切换。 混元、DeepSeek、Claude、GPT都能切。遇到复杂架构设计,切Claude-4.5-Opus;日常搬砖,用DeepSeek-V3-Terminus,速度和成本都能平衡。
第三,腾讯内部已经”吃过狗粮”。 据说内部90%以上的工程师都在用,AI生成代码占比过半,原本两周的需求两天就能交付。
大厂验证过的工具,至少不会是个花瓶。
但问题来了——单点提效和体系化开发,完全是两回事。 当你让CodeBuddy Craft智能体去处理一个涉及多文件、多模块、带业务规则的企业级应用时,那四个坑,该来的都会来。
二、坑一:修Bug修到怀疑人生,反复失败怎么破?
这是最搞心态的。
你让CodeBuddy改一个缺陷,它分析得头头是道,改完一跑,报错。你说”继续修”,它又改,报错信息换了,但根因还在。来回十几轮,代码从”有点小毛病”变成了”面目全非”,最后你看着满屏红字,只想git reset –hard。
我后来琢磨明白了,这不是CodeBuddy故意搞你,而是多轮失败后,上下文已经”污染”了。前面的错误思路被它当成了”已知事实”,越推导越偏,越偏越错。业内管这叫”兔子洞”(Rabbit Hole)。
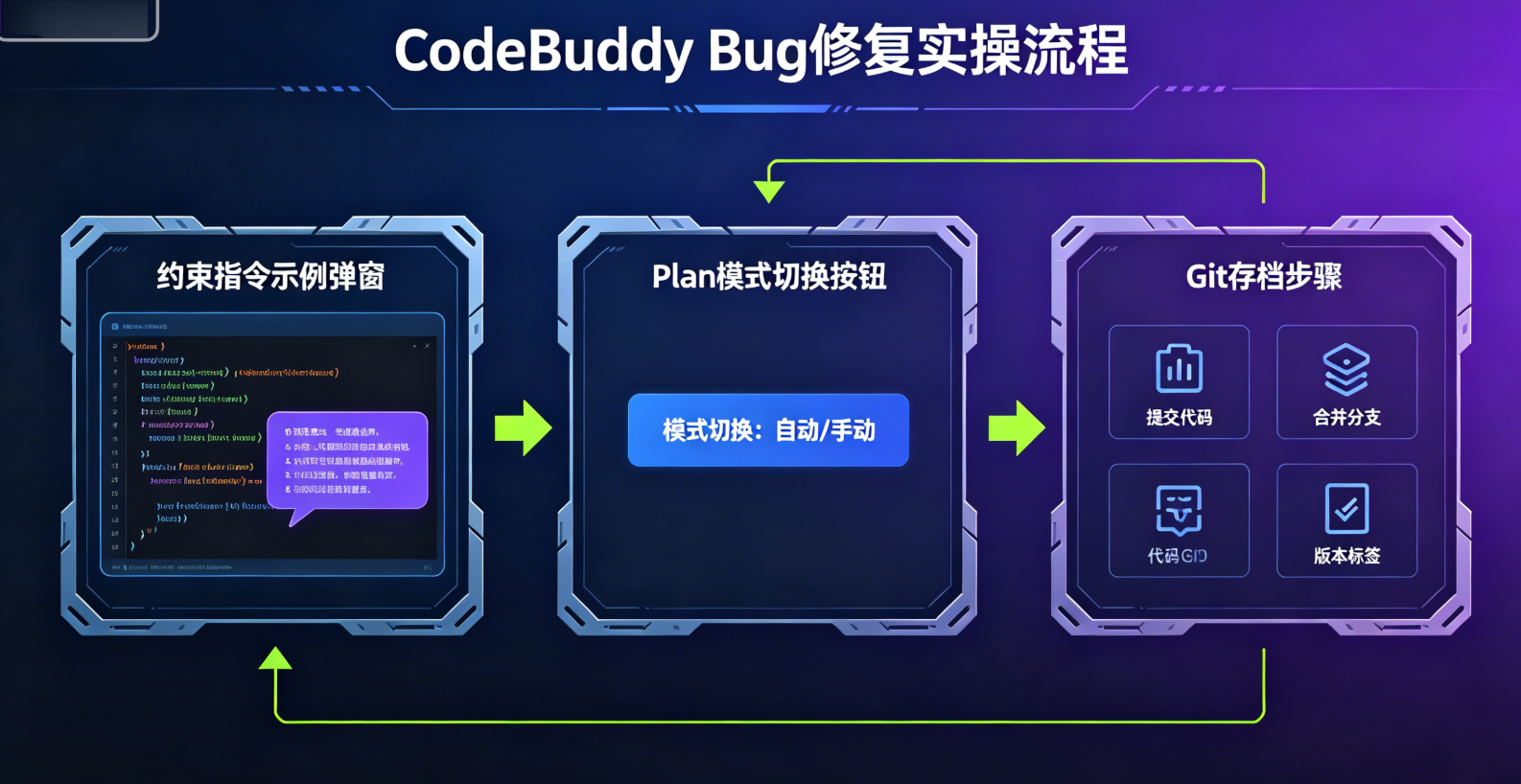
我的解法:事不过三,强制断点。
具体怎么操作?
- 每次动手前,先存档。git commit或者git stash,给自己留条后路。CodeBuddy改坏了,你能秒回退。
- 给指令加”约束围栏”。 别说”把这个Bug修了”,要说:”只修改UserService.java里的validateOrder方法,不要动其他模块,不要引入新依赖,修复后确保单元测试通过”。范围越死,它越不容易跑偏。
- 三次不过,立刻重置。 这是我给自己定的铁律。第一次失败,优化Prompt;第二次失败,继续精简需求;第三次还搞不定,直接清掉对话上下文,重新开一轮。别赌第四次,沉没成本会拖死你。
另外,CodeBuddy有个Plan模式(按Shift+Tab切换),能让它先出方案、你确认后再动手。触及多个文件的改动,千万别直接开干,先Plan,能大幅降低反复返修的概率。
三、坑二:代码生成”神仙”与”魔鬼”并存
有时候CodeBuddy主动生成的功能,确实让你眼前一亮:”这思路我怎么没想到?”但下一段代码,它可能又给你埋雷——硬编码了个路径、漏了边界判断、用了个废弃API,甚至变量名起得让你怀疑人生。
根子出在上下文膨胀和自动压缩上。
CodeBuddy的上下文窗口虽然不小,但长对话后,早期关键信息会被慢慢挤出窗口。更隐蔽的是,当上下文快满时,系统会自动压缩历史对话,生成摘要。这个过程中,一些关键约束(比如”必须用微服务架构”、”数据库不许用外键”)可能被”遗忘”。
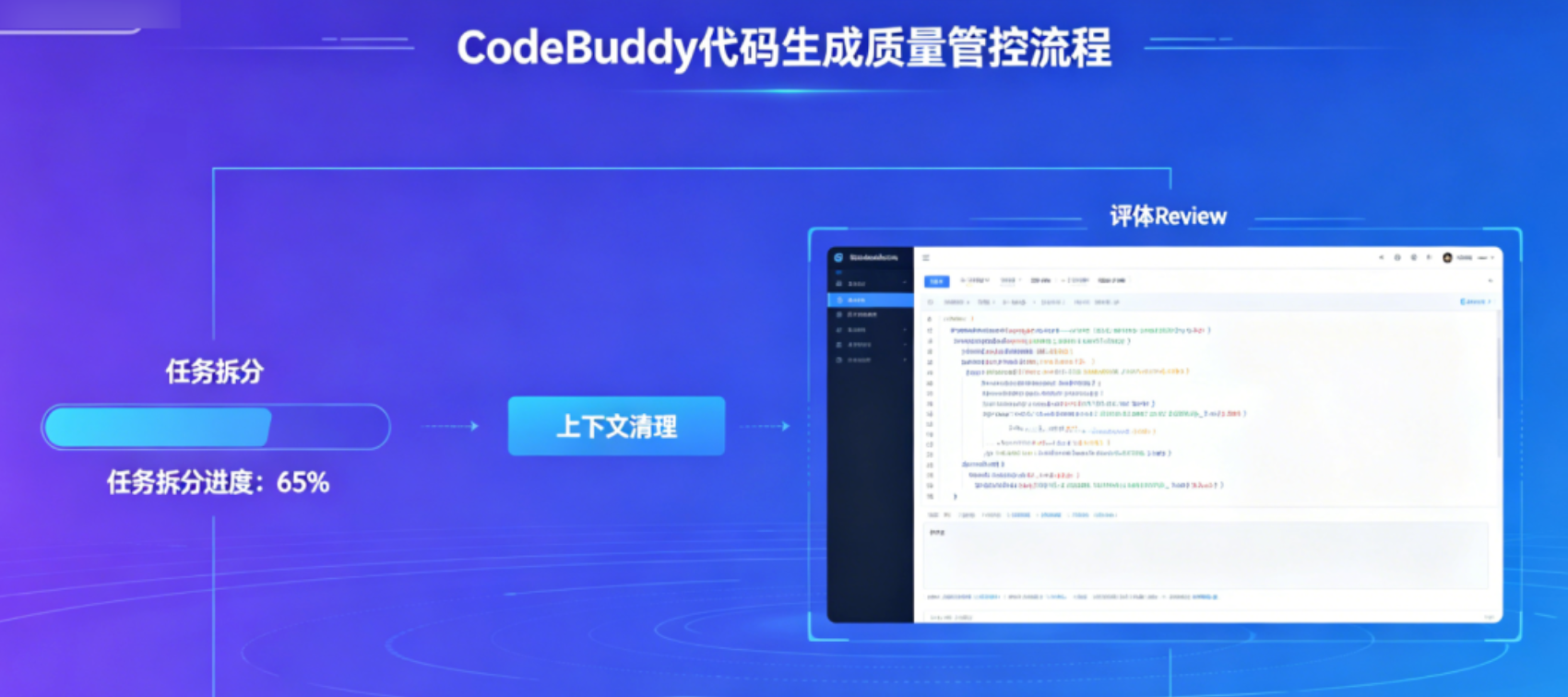
于是,后半程生成的代码就开始”放飞自我”。
怎么稳住质量?三条经验:
第一,动手前先让它”读代码”。 别上来就说”给我加个功能”。先问:”分析一下这个模块的表结构、接口契约和错误处理机制”。让CodeBuddy对项目有整体认知,生成质量会稳很多。
第二,大任务拆小步。 别一次性扔一个”重构整个订单系统”的需求。拆成”先改接口层→再改业务逻辑→最后补测试”。每完成一步,人工Review一下,确认方向对了再继续。
第三,主动清上下文,别等它自动压缩。 CodeBuddy完成一个模块(比如用户中心),提交代码后,手动清空对话历史,再开新会话做订单模块。这样能大幅降低”自动压缩”在任务中途突然发作的概率。如果对话已经很长,也可以利用它的对话历史保存功能,把关键结论记下来,然后重启会话。
四、坑三:任务干一半,程序突然”猝死”
这是最吓人的。你看着CodeBuddy正在输出修复方案,突然”啪”一声,进程退出了。或者它弹个提示说任务已终止,你一脸问号:我啥也没干啊?
我排查了很长时间,发现”猝死”通常有三个凶手:
凶手A:终端进程异常。 尤其是在Windows环境下,如果CodeBuddy调用了PowerShell执行命令,而环境配置、权限或.NET SDK有问题,就会出现异常终止,退出代码像-2147450749这种。
说白了,不是CodeBuddy本身崩了,是它调用的”手脚”(终端进程)出了问题。
凶手B:工具调用上限。 CodeBuddy在Craft模式下会连续调用工具(读文件、改代码、跑测试),但单次对话轮次里,工具调用次数是有上限的。一旦触及,会话会被强制暂停。
凶手C:自动熔断。 如果开了自动执行模式,系统检测到连续异常操作(比如反复失败的命令),会主动中止任务,防止它”疯跑”烧光资源。
我的逃生指南:
- 养成随手存档的肌肉记忆。 每完成一个子任务,git commit一次。CodeBuddy退出后,至少代码还在,你能根据提交记录快速重建。
- 建立任务清单(todo.md)。 让CodeBuddy把当前任务拆解写入todo.md,每次执行前对照文档。这样即使会话崩溃,你也能根据清单快速重建上下文,而不是从头再解释一遍需求。
- 检查终端环境。 如果是Windows,确保PowerShell和.NET SDK安装正确,环境变量配好。必要时,在CodeBuddy设置里把默认终端改成cmd.exe试试稳定性。
- 把”长任务”切成”短冲刺”。 单个会话别超过20-30轮交互。超过这个范围,不仅容易触发上限,上下文质量也会断崖式下跌。
五、坑四:那个”执行任务超过100次,请确认是否继续”
这个弹窗,第一次出现时我挺烦的——我都快修完了,你问我确不确认?但用久了,我理解了它的设计逻辑。
这不是Bug,是”防呆保险丝”。
CodeBuddy作为编码智能体,在自主模式下会进入一个”观察-思考-行动”的循环。想象一下,如果它陷入死循环(比如”改代码→跑测试→失败→再改”无限重复),没有上限的话,一小时能把你的API额度、计算资源烧穿。所以,100次的硬性天花板,本质上是防止无限循环和资源失控的安全机制。
另外,CodeBuddy的更新记录里也明确提到支持”对话安全停止”,说明团队在交互安全上是有系统设计的。
那能不能取消? 严格来说,不能完全取消,但你可以优雅地绕过和适配:
方案1:给任务加明确的”停止条件”。别只说”把这个功能做好”。要说:”跑通所有测试并输出任务完成后停止”。明确的完成标记能让CodeBuddy在达标后主动退出,而不是磨洋工。
方案2:大任务拆小,人工设置检查点。100次其实够做很多事。把大型重构切成几段,每段之间人工介入一次:Review代码、提交Git、确认方向。这样既不会撞墙,又能及时纠偏。
方案3:利用多模型切换”续命”。如果真撞到了100次,别急着重开。CodeBuddy支持一键切换模型,换个模型继续任务,能一定程度上延续上下文,减少重复解释的成本。
方案4:CLI模式跑无人值守任务。如果是夜间批量重构或CI/CD集成,用CodeBuddy CLI更合适。CLI形态天生就是为自动化和批处理设计的,能更好地嵌入流水线,避免IDE交互层的限制。
六、我的实战SOP:怎么和CodeBuddy高效协作
把上面这些坑和解法串起来,我现在在团队里推行的标准workflow是这样的:
Step 1:需求冻结,先出Plan开新会话,切到Plan模式,让CodeBuddy把需求整理成todo.md,明确每个子任务的验收标准。你Review完方案,再让它动手。
Step 2:小步快跑,频繁存档每个子任务完成后,git add . && git commit -m “feat: xxx”。把大任务切成15-20分钟能完成的小块。
Step 3:感知到卡顿,主动清上下文对话超过20轮,或者CodeBuddy开始”遗忘”之前的约定时,保存关键结论,然后清空历史重启会话。
Step 4:三次失败,强制重置任何一个修复或生成功能,三次尝试不过,立刻重置对话或回退代码。不要赌第四次。
Step 5:复杂修复,先分析再动手让它先读代码、出方案,确认理解无误后,再执行修改。别直接说”修Bug”。
Step 6:100次预警前,主动收尾在接近100次时,人工介入,提交当前进度,确认下一步方向,然后开启新会话接力。
这个SOP在团队里跑了一个多月,原本容易”翻车”的体系化开发任务,稳定度提升了不少。CodeBuddy的平均提效能到30%-40%,但前提是你得会驾驭它,而不是放任它自己跑。
七、给技术管理者和信息化负责人的三条建议
如果你是CTO、技术总监或者信息化负责人,正在考虑在团队层面推广CodeBuddy,我有三个从实战中磨出来的建议:
1. 别只看”代码生成率”,要看”上下文治理能力”。选AI编程工具,单次补全准确率已经拉不开差距了。真正决定能不能上企业级生产的,是工具对工程上下文的理解深度、多文件协同的稳定性、以及长对话中的信息保持能力。CodeBuddy的”全仓记忆”机制在这里是个加分项,但团队必须配套使用规范(如主动清上下文、任务清单化),才能把能力释放出来。
2. 建立”人机协作”的评审流程,而不是完全放手。AI生成的代码,审查逻辑要变。从”逐行检查语法错误”,转向”检查架构一致性、业务规则合规性、安全边界”。建议把CodeBuddy的Code Review模块用起来,但最终的合并权必须留在人手里。
3. 分形态推广,别一刀切。日常编码开发者,给IDE插件;做大型重构和跨仓库迁移的,上IDE独立版;DevOps和运维团队,推CLI形态。不同场景给不同形态,才能让每个角色都拿到最优效率,而不是强行统一。
写在最后
CodeBuddy不是神仙,它是一个能力极强但需要约束的实习生。100次限制、自动退出、上下文压缩——这些看似烦人的机制,本质上都是保护你不被无限循环和资源失控背刺的安全网。
真正的高效,不是让AI无限制地跑,而是你清楚它的边界,并在边界内把杠杆用到最大。
体系化应用开发这件事,AI能帮你提速,但架构设计、业务理解、质量兜底,目前还得靠人。把这篇文章转给你们团队的技术负责人,下次用CodeBuddy做复杂项目时,对照着来,应该能少踩几个坑。
本文由 @数智产研笔记 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议






- 目前还没评论,等你发挥!


