
 起点课堂会员权益
起点课堂会员权益产品经理的RAG决策地图:什么阶段该加什么,什么时候该停手
RAG调优绝非简单的策略堆砌,而是一场精准的工程减法。本文揭示90%团队忽视的数据摄入层才是成败关键,拆解混合检索与重排序的黄金组合,并警告Agentic RAG等‘超前优化’陷阱,带你用诊断思维重建RAG调优决策地图。

我们都被”调优清单”骗了
有一篇在AI圈广泛传播的文章,列出了12种RAG调优策略,从数据清洗到嵌入微调,从混合检索到Agentic RAG,密密麻麻排了满满一页。我认识不少团队,拿到这张清单之后兴冲冲地逐条实施,结果几个月后回头看,系统延迟增加了,成本翻了两三倍,效果甚至比刚开始还差。
他们没有做错任何一件事。问题在于,这张清单从来没告诉你:这些策略不是全都该上,更不是全都该同时上。它给了你12把锤子,但没告诉你哪颗钉子该用哪把锤。
我见过最惨的案例是一个做企业内部知识库的团队。他们在POC阶段就把句子窗口检索、HyDE查询转换、重排序模型、自反馈机制全部堆进去,每次查询要串行调用LLM三次,平均响应时间超过8秒。用户反馈”还不如直接搜索”。整个系统最后被推倒重来。

这不是个例。DataFun的调研显示,”RAG效果不理想”被提及频率高达48次,是AI落地的头号痛点。而2026年的生产实践反复验证了同一个结论:80%的RAG项目失败,根源不在LLM,在数据摄入层。大量团队跳过了最重要的地基,直接去搭六楼。
更反常识的是,有团队在做了一圈RAG优化之后,彻底放弃了向量数据库,回归最原始的方案:把文件列出来,关键词搜索,直接读内容。没有Embedding模型,没有向量索引,没有分块流水线。效果反而更稳。这件事说明的不是RAG没用,而是复杂度本身是一种成本,加的每一层都是新的故障点、新的调试负担、新的不可控变量。

所以这篇文章不打算再列一张策略清单。我想帮你建立一张决策地图:先搞清楚你的系统烂在哪,再决定该加什么,最重要的是,知道什么时候该停手。
先想清楚:你的RAG烂在哪一层
调优之前,最重要的不是选策略,是诊断。很多团队一遇到效果差,第一反应是换更大的LLM,或者上Rerank。这就像头疼就去做脑部手术,不是方向错了,是根本没诊断。
RAG系统的失败有非常固定的分层逻辑。从我观察的生产案例来看,问题几乎都能定位到三个层级之一:

诊断方法很简单:从检索结果入手。把用户的问题输入系统,只看检索出来的原始片段,不看最终答案。如果检索结果本身就是错的,那是摄入层或检索层的问题,跟LLM无关。如果检索结果正确,最终答案却错了,才是生成层的问题。
这个诊断动作,在我见过的团队里大概70%都没做过。他们用整个系统的最终效果来判断问题出在哪,这就像汽车坏了直接换发动机,也许问题只是轮胎没气。
确认了问题在哪一层,才能谈策略。不同层的药方完全不同,混用只会让情况更复杂。接下来我们按层来谈,从ROI最高但最被忽视的那一层开始。
摄入层:调优的地基,90%的人跳过它
如果让我只选一件事来提升RAG效果,我会毫不犹豫地选:把数据摄入层做好。不是Rerank,不是Agentic,不是换更贵的Embedding模型。就是这个听起来最无聊的部分。
原因很直接——垃圾进来,垃圾出去。检索层和生成层再强,也无法从一堆解析失败的乱码、在错误位置截断的文档片段、没有任何元数据标注的孤立段落里,召回出有意义的内容。
文档解析:被严重低估的坑
一个真实案例:某团队的法律知识库,固定长度分块,切片在法条的中间位置截断了前提条件。模型拿到的是半条法律,给出了完全错误的建议,还信心满满。用户发现之前,这个错误答案被引用了数十次。
另一个更常见的问题是PDF解析。双栏排版的文档,朴素的解析器会把左栏第一行和右栏第一行拼在一起,产生完全错乱的语义。这类问题在早期根本不会被测试发现,因为你的测试集大概率不会刚好命中那个被乱拼的位置。
文档解析没有银弹,但有几个基本动作必须做:对不同文档类型用不同的解析器;解析后做一次人工抽检,专门找那种”读起来语义完全不对”的片段;双栏PDF可以考虑先转图片再用多模态模型解析。
分块策略:512 Token是当前最有据可查的基准
分块这件事,用”切香肠”来理解最直接——香肠太长,塞不进嘴;太短,每片都失去了上下文。RAG里的块大小决定了检索的颗粒度:块太大,一个不相关的句子可能把整块”污染”掉;块太小,一个完整的逻辑单元被切碎,模型拿到的都是残片。
Vectara在2026年2月发布的基准测试覆盖了50篇学术论文和7种分块策略,结论是:递归512 token分割(带10-20%重叠)准确率达到69%,而语义分块只有54%,而且语义分块产生的片段平均只有43 token,信息密度极低。

元数据:最低成本的精度提升
元数据是摄入层里ROI最高的单项策略,没有之一。给每个文档片段打上时间戳、来源文档、所属章节、内容类型这几个字段,查询时可以直接过滤。
微软Azure架构中心在2025年的实测数据:给文档块做元数据增强,QA准确率从50-60%区间提升到72-75%,在不改动任何检索架构的前提下。这是纯粹靠数据工程拿到的收益。
没有元数据过滤的RAG系统,一旦文档库里有新旧版本共存,就是一个定时炸弹——用户问”最新的退款政策是什么”,系统会把三年前的旧版本和今年的新版本一起召回,然后把两个矛盾的内容喂给LLM,生成一个听起来有道理但实际错误的综合回答。
Embedding模型:不一定要用最贵的
通用Embedding模型在企业专有名词、产品编号、行业术语上表现不好,有时候”精确查询的表现甚至不如20年前的模糊搜索”——这是真实反馈,不是段子。
2026年MTEB榜单的英文检索前几名分别是Cohere embed-v4(MTEB分65.2)、OpenAI text-embedding-3-large(64.6)、开源的BGE-M3(63.0)。但分数高不代表适合你的场景。LlamaIndex的实测数据显示,在自己的领域数据上微调Embedding模型,检索效果可以提升5-10%——这个提升是稳定的,但微调需要标注数据,有一定门槛。
建议的决策顺序:先用开源的BGE-M3试水,如果发现专有术语召回率明显差,再考虑微调或换商业模型,不要一上来就冲最贵的选项。

检索层:三个值得上的策略,和两个大坑
摄入层做好之后,很多系统其实已经够用了。但如果你的诊断结果是”检索层有问题”——召回的东西相关但不精准,或者复杂问题根本搜不到——那就轮到检索层的优化了。
检索层的策略里,我认为值得在大多数场景投入的只有三个。
混合检索:几乎必选的基础配置
纯向量检索有一个致命弱点:对精确匹配不敏感。你问”SKU编号A00123的退货政策”,向量检索会给你一堆语义相关的退货政策文档,但那个精确编号对应的片段可能反而排在后面。
混合检索把向量搜索(语义理解强)和关键词搜索BM25(精确匹配强)结合起来,通过一个alpha参数控制权重。alpha=1是纯向量,alpha=0是纯关键词,中间值是混合。生产实践里,混合检索能将召回率提升20%以上,而且实现成本不高,是摄入层之后最值得投入的单项策略。
Rerank重排序:性价比最高的精度提升
两阶段检索是目前生产环境最稳定的检索架构:第一阶段用向量检索快速召回20个候选结果,第二阶段用Cross-Encoder重排序模型精选出最终的3-5个。
为什么这样拆?因为向量检索快但不够精准,Cross-Encoder精准但对大量文档来说太慢。分两阶段,用速度换规模,用精度控最终输出。而且重排序只作用于召回的少数结果,计算代价很低,但用户能感受到的答案质量提升是明显的。
重排序模型能识别出Query和候选片段之间的微小语义偏差——比如问题问的是”退款流程”,召回了一篇讲”退货流程”的文档,两者高度相关但重排序模型能区分,向量检索不行。
查询转换:有效但有代价
HyDE(假设性文档嵌入)的逻辑是:与其直接用用户的问题去检索,不如先让LLM生成一个假设的理想答案,然后用这个假设答案去检索文档。原理是”用答案找答案”,语义空间更接近目标文档。
这个策略在标注数据少、领域偏专业的场景里确实有效,LlamaIndex的实验数据支持这一点。但代价是每次查询多调用一次LLM,延迟增加,成本上升。我的建议是:如果你的系统已经在延迟和成本上有余量,再考虑HyDE;如果响应时间已经有点紧,先不要动它。
两个大坑:Agentic RAG 和 GraphRAG
这两个是2025-2026年被讨论最多的进阶策略,但我要认真说:99%的团队在需要它们之前就已经用上它们了,这是当前最普遍的过度工程化。
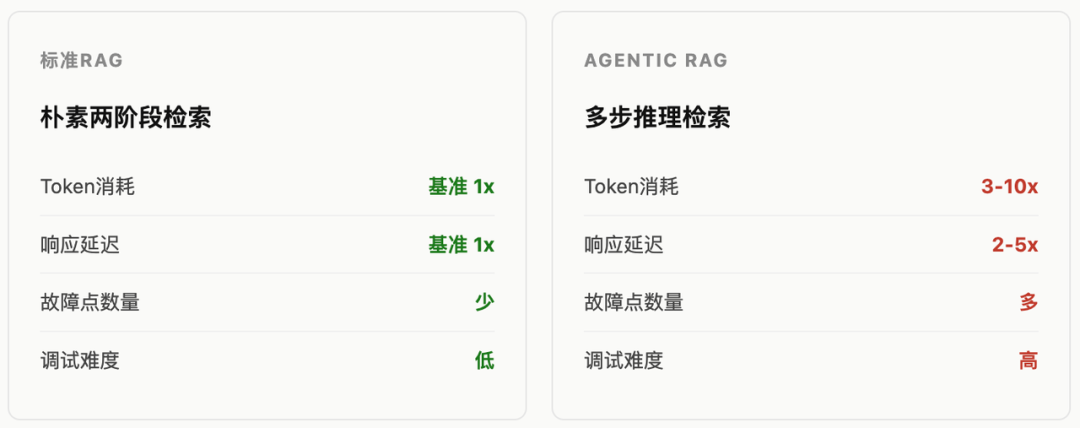
Agentic RAG的问题不是它不好,是它贵。每一步推理都要调用LLM,多步推理意味着3-10倍的Token消耗,2-5倍的延迟。而且Agentic RAG有一个隐蔽的失败模式:Agent靠自我评估来判断检索是否成功,但当它基于错误的内部逻辑一步步强化了一个错误答案时,你根本察觉不到——系统表现得信心满满。
GraphRAG的理论很漂亮——把文档库建成知识图谱,关联实体之间的复杂关系,回答”跨文档推理”类的问题。但生产证据目前比简单方案薄得多。构建和维护知识图谱的成本极高,图谱一旦更新不及时,整个答案质量就会崩塌。
一条判断标准:如果你现在遇到的问题,用混合检索+Rerank能解决80%,那就先解决80%。剩下20%的复杂多跳问题,等你有足够的数据和资源时再专门处理,不要为了20%的场景让整个系统付出3-10倍的成本。
决策地图:三个阶段,三套打法
现在把上面讲的所有策略,放进一个实际的项目推进框架里。
2026年的企业RAG市场有一个明显的分水岭:2024-2025年,大量POC项目证明了RAG”能用”;进入2026年,采购方的核心问题已经变成”能稳定可靠地用在生产环境吗”。这个转变直接决定了不同阶段应该把精力放在哪里。

POC期:先让它跑起来,别让它好看
POC的目标只有一个:验证这条路能走通。这个阶段最忌讳的是”因为要演示,所以加了很多优化”。每加一个策略,都是一个新的变量,出了问题你不知道该归咎于哪里。
朴素的向量检索加上基础的提示词模板,能跑通业务逻辑,就是成功的POC。数据层面,尽量手动清洗几十个核心文档,先把最重要的内容质量保住。元数据、微调这些可以完全不碰。
内测期:这才是调优的主战场
内测期是整个项目里调优投入产出比最高的阶段,也是最该认真打的阶段。这时候你有了真实用户反馈,有了失败案例的积累,知道问题到底出在哪一层。
这个阶段必须做的三件事:把元数据体系建完整;上混合检索+Rerank;用真实失败案例反推摄入层的修复。大量的精力应该花在分析”为什么这个问题答错了”,而不是盲目地往上加策略。
规模化期:稳定性优先于效果
规模化之后,产品经理的关注点要从”效果好不好”切换到”稳不稳定、成不成本、合不合规”。2026年企业采购RAG产品的核心诉求已经是这三点,而不再是”哪家效果最好”。
这个阶段才值得认真考虑查询路由(按用户意图决定用哪条检索路径)、权限控制(在检索发起的瞬间做硬过滤,不是在最终结果里做)、完整的监控和审计追踪。Agentic RAG如果你确实遇到了大量多跳推理问题,可以专门针对这个场景引入,而不是全局替换。
什么时候该停手
我想以一个反问结束这篇文章:你上一次评估RAG系统,是从用户体验倒推的,还是从技术清单正推的?
这两种路径会得出完全不同的结论。从技术清单正推,你永远能找到”还没做”的策略,永远有理由再加一层。从用户体验倒推,你的问题变成:用户现在最大的不满是什么?那个不满对应的是哪一层的问题?那一层最简单的修复是什么?
生产实践反复证明的那个结论,值得再说一遍:80%的场景,朴素RAG加上干净的数据加上细致的产品设计,打得过任何花哨的技术组合。不是因为高级策略没用,是因为高级策略的前提是你把基础做扎实了。
调优是减法,不是加法。每加一个策略之前,先问自己三个问题:我能说清楚这个策略解决了哪一层的哪个具体问题吗?我有数据证明这层确实是瓶颈吗?加了它之后如果出了问题,我能定位是它导致的吗?
三个问题都能答上来,加。答不上来,停手。

本文由 @芒果爸爸AI产品笔记 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议





- 目前还没评论,等你发挥!


