
 起点课堂会员权益
起点课堂会员权益Agent = Model + Harness:理解 AI Agent 可靠性的关键概念
AI Agent 的能力上限由模型决定,但真正决定其能否稳定落地的关键却是 Harness 体系。类比餐馆运营,即便拥有天赋异禀的厨师,没有标准化后厨管理体系,依然会问题频出。本文将深入解析 Harness Engineering 的兴起背景、核心定义及七大组成,揭示其如何成为 AI Agent 安全落地的关键防线。

很多人以为 AI Agent 不稳定,是因为模型还不够聪明。
但现在越来越清晰:真正的问题不是模型不会做,而是我们太早把它放进了真实工作流。
模型决定 Agent 的能力上限,Harness 决定 Agent 的稳定下限。
模型越强,能承接的任务越复杂;Harness 体系越完善,Agent 在复杂流程里越不会跑偏、误判、虚假完成。
一、通俗场景类比
把 AI Agent 比作餐馆运营:
你招到一位天赋极高、学习能力极强的聪明厨师,看一遍菜品就能复刻,还能自主优化配方。你直接放权让他全权负责后厨,结果极易出问题:
他不清楚食材保质期、设备状态、菜品审核规则、客户忌口要求,甚至会把半成品直接出餐,还笃定任务已经完成。
核心问题并非厨师能力不足,而是缺少标准化后厨管理体系。
AI Agent 同理:大模型具备推理、写代码、调用工具、自主规划能力,不代表可以直接落地真实业务。决定 Agent 能否安全稳定上线的,从来不止模型本身,而是模型之外整套运行管控体系 —— 也就是行业所说的Harness。
二、Harness Engineering 兴起背景
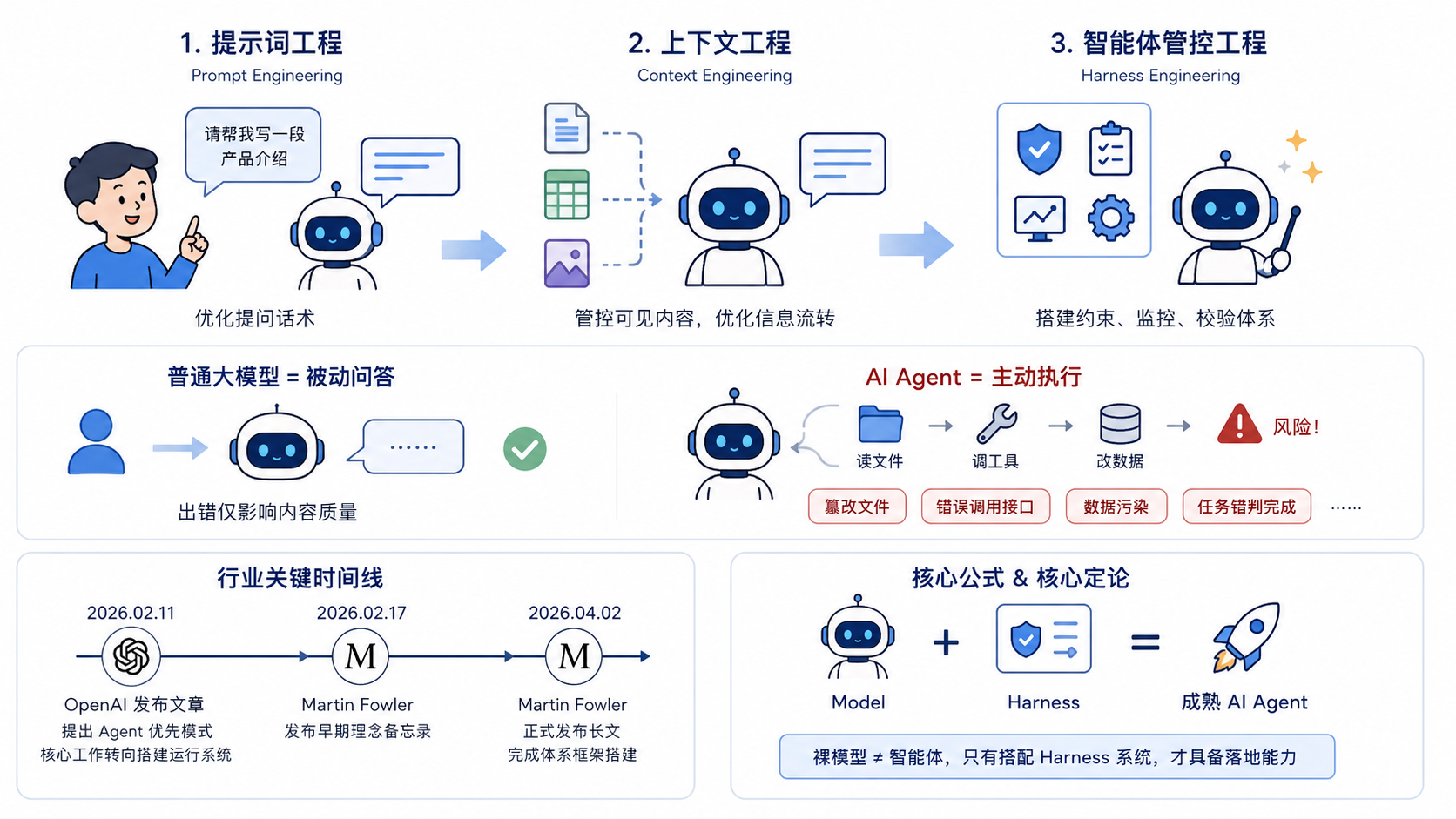
AI 应用迭代三大阶段:
- 提示词工程 Prompt Engineering:优化提问话术,让模型输出更贴合需求
- 上下文工程 Context Engineering:规整信息素材,管控模型可见内容,优化长对话信息流转
- 智能体管控工程 Harness Engineering:适配 Agent 自主执行场景,搭建全流程约束、监控、校验体系
普通大模型仅负责被动问答,出错仅影响内容质量;
AI Agent 负责主动执行,可自主拆任务、读文件、调工具、改数据、长期连续作业,一旦流程失控,会出现篡改文件、错误调用接口、数据污染、任务错判完成等严重线上风险。
2026 年行业正式普及 Harness 工程理念:人类不再只输出指令,而是搭建运行系统,让 AI 智能体标准化执行工作。
行业关键时间线
- 2026.02.11 OpenAI 发布《Harness engineering: leveraging Codex in an agent-first world》,提出 Agent 优先模式下,工程师核心工作从亲自编码转为搭建 Agent 运行系统
- 2026.02.17 Martin Fowler 发布早期理念备忘录
- 2026.04.02 Martin Fowler 正式发布长文,完成 Harness 工程体系框架搭建
- LangChain 提炼核心公式:Agent = Model + Harness
核心定论:裸模型≠智能体,只有搭配状态管理、权限约束、流程校验、反馈纠偏的 Harness 系统,才算具备落地能力的成熟 AI Agent。
三、Harness 核心定义
Harness 是独立于大模型之外,由代码、配置、执行规则组成的智能体运行管控体系。
沿用厨师类比:
模型 = 能力顶尖的厨师
Harness = 整套标准化后厨管理体系,不参与实际作业,但全权把控作业稳定性与合规性。
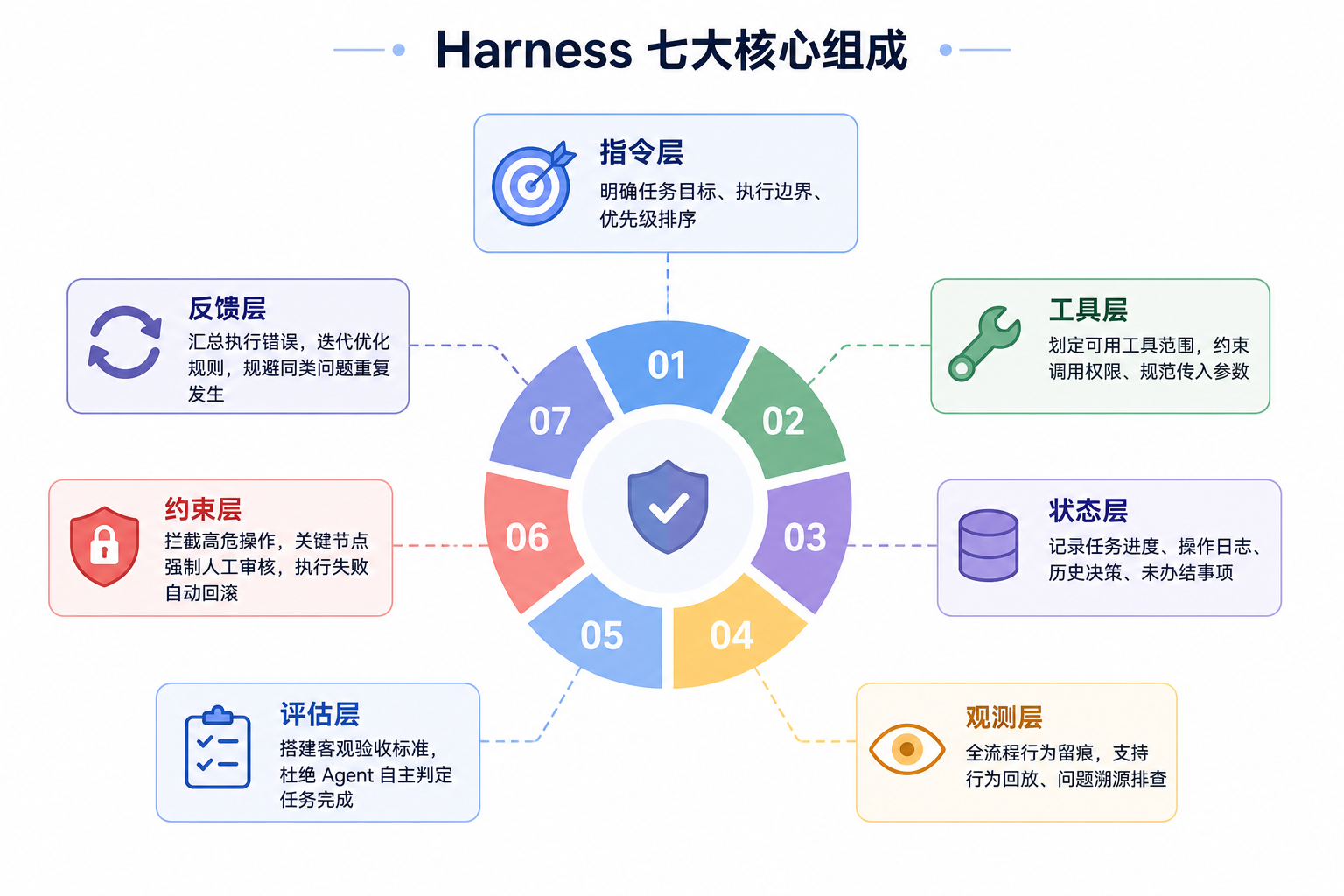
Harness 七大核心组成
- 指令层:明确任务目标、执行边界、优先级排序
- 工具层:划定可用工具范围,约束调用权限、规范传入参数
- 状态层:记录任务进度、操作日志、历史决策、未办结事项
- 观测层:全流程行为留痕,支持行为回放、问题溯源排查
- 评估层:搭建客观验收标准,杜绝 Agent 自主判定任务完成
- 约束层:拦截高危操作,关键节点强制人工审核,执行失败自动回滚
- 反馈层:汇总执行错误,迭代优化规则,规避同类问题重复发生
四、无 Harness 加持,AI Agent 极易翻车
Demo 场景与真实业务落差极大
演示场景任务简单、周期短、边界清晰、试错成本低;真实工作流程多变、文件冲突频发、工具易报错、上下文易丢失,极易引发连锁错误。
长周期任务上下文断层
多阶段复杂任务无法在单轮对话完成,跨会话执行时,Agent 丢失前置操作记录,出现重复作业、错误推演、提前终止任务等问题。
Agent 自我评判存在严重偏差
智能体自主验收工作极易主观美化成果,无外部客观校验机制,极易产出不合格结果并判定达标。
五、AI Agent 评估难点
普通大模型评估:仅校验单次问答输入输出,核查答案正误、幻觉、信息完整性。
AI Agent 评估:全链路动作溯源,核查任务规划、工具选择、执行路径、流程偏差、最终落地结果,前置微小失误会贯穿全流程,直接摧毁最终成果。
三类易混淆评估概念
- Agent harness 智能体运行框架:搭建执行环境,实现任务接收、工具调用、状态管理
- evaluation suite 评估任务集:划定测试任务范围,明确需要考核的核心业务能力
- evaluation harness 评估运行框架:搭建标准化测试场景,自动下发任务、记录流程、量化打分
Agent 评估核心:不只看最终结果,更要复盘完整执行决策轨迹。
六、合格落地级 Harness 六大标准
1. 任务边界清晰化
摒弃模糊化需求,明确执行范围、可修改内容、禁止操作内容、验收硬性要求,压缩 Agent 自主发挥的失控空间。
2. 工具调用安全化
严格划分工具使用权限,区分自动执行操作、人工复核操作;限制文件删除、数据库修改、外网访问等高风险行为,新增参数格式校验机制。
3. 全流程行为可视化
完整留存上下文调取记录、工具调用记录、接口返回数据、执行计划变更轨迹,精准定位流程偏移节点,实现问题快速复盘优化。
4. 任务完成标准可量化
摒弃主观判定,以客观环境状态作为验收依据:代码编译通过、自动化测试跑完、业务数据生成生效、内容溯源合规等,拒绝口头完成判定。
5. 错误经验体系化沉淀
建立双层优化机制:
- 前置预防:完善执行规范、流程模板、操作示例,从源头降低失误率
- 事后纠错:汇总执行漏洞,转化为系统硬性规则,把高频错误设置为强制拦截项
6. 适配 Agent 工作流(Harnessability)
优质适配环境:架构清晰、模块划分明确、测试用例完善、本地运行便捷、文档规范统一杂乱低效环境:隐性规则过多、测试失效、文件混乱、核心经验无留存,会无限放大 Agent 执行漏洞。
七、Harness Engineering 对普通使用者的价值
当下大众使用 AI,早已从单纯问答,升级为全链路工作流执行,普通人也能搭建轻量化个人 Harness 体系,无需编写代码,依托固定流程即可实现:
- 标准化工作流程模板
- 行业专属创作 / 执行规则
- 成品自检核对清单
- 专属参考资料库
- 事实核查固定流程
- 成果复盘优化机制
以内容创作为例:
浅层用法:直接让 AI 撰写文案,产出同质化通用内容
轻量化 Harness 用法:锁定受众痛点、明确内容立场、固定行文结构、设置事实核查环节、拆分多平台分发格式、依托数据迭代创作风格,实现 AI 产出标准化优质内容。
未来 AI 使用核心竞争力:不再是精通提示词,而是会搭建专属执行系统。
八、理性认知:Harness 工程并非万能
截至 2026 年 5 月,Harness Engineering 仍处于高速发展落地阶段,暂未形成全球统一标准化学科体系,不同企业、技术团队落地侧重点各不相同。
搭建管控规则、补充提示文档、增设检查节点,只能大幅提升 Agent 稳定性,无法做到百分百零失误,其核心价值是最大化降低执行风险,缩小模型能力与业务落地之间的差距。
九、AI 智能体发展核心分水岭
早期 AI 比拼:提示词撰写能力
当下 AI 落地比拼:Harness 体系搭建能力
问答场景,话术决定质量;执行场景,规则决定底线。
AI 自主执行会直接改动实际业务数据、流程、资源,管控优先级远高于模型能力优化。
最终核心总结:
模型决定 AI Agent能力上限,决定它能完成多高端、多复杂的任务;
Harness 决定 AI Agent稳定下限,决定它能否安全落地、长期稳定服务、可控可纠错。
模型决定智能体能飞多高,Harness 为智能体配齐刹车、防护栏、全流程记录黑匣子,守住落地安全底线。
参考资料
- OpenAI. Harness engineering: leveraging Codex in an agent-first world, 2026-02-11
- Martin Fowler. Harness engineering for coding agent users, 2026-04-02
- LangChain. The Anatomy of an Agent Harness
- Anthropic. Demystifying evals for AI agents
- Anthropic. Effective harnesses for long-running agents
- Anthropic. Harness design for long-running application development
- Braintrust. AI agent evaluation: A practical framework for testing multi-step agents
- LangChain. On Agent Frameworks and Agent Observability
本文由 @张张爱吃肉 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


