
 起点课堂会员权益
起点课堂会员权益万字干货:这可能是全网最实战的「用 Claude Code 做产品」完整方法论
一名零基础的产品经理,仅凭6周时间和1万元预算,通过62,376次与Claude Code的对话交互,竟独立开发出具备长期记忆和自进化能力的AI桌面应用『阿布』。这款应用不仅能操作本地文件、抓取网页数据,还实现了7×24小时自动化运行和跨平台集成。本文将完整拆解这段从技术小白到AI开发者的奇幻旅程,揭秘8.5万行代码背后的高效工作流与避坑指南。

3月1日那天,我跟 Claude Code 发了 9,259 条消息,一天,从早到晚。那天是阿布(Abu)的首个版本发布。
从那天起的 6 周时间里,我用 Claude Code 写了一款叫阿布的 AI 桌面应用。到今天为止,8.5 万行代码、386 个文件、222 次 commit、1,362 个测试。
作为一个不懂技术、不会编程的产品经理,我写代码的方式是描述需求,让 Claude 帮我写。这 6 周里我跟 Claude Code 总共交互了 62,376 条消息、45,004 次工具调用,花了大约 1 万块钱(订阅 5,740 + API 5,000+)。
如果你也「想用 AI 写自己的工具但不知道从哪开始」,或者「看到别人发产品很心动但觉得自己不行」,我想把我这 6 周经历的完整链路拆开给你看。一个真实案例、一套可复用工作流、一些避坑经验。
6 周以前我也是从”我不会编程”开始的。
这篇文章会讲这些事:
1. 我做了一款什么产品:阿布能干什么、使用场景、当前规模
2. 我的工作流:从需求到代码到上线,5 步循环怎么跑
3. 用好 Claude Code:CLAUDE.md、/plan、/insight、/simplify 等我每天在用的功能
4. 工作示范:从 0 加一个”让阿布操作浏览器”的功能,完整演一遍
5. 怎么做 UI:怎么让 AI 写出审美在线的界面
6. 怎么可持续构建:分支纪律、版本管理、提交检查,附真实事故
7. 怎么写测试:1,362 个测试是怎么长出来的,附注册表实践
8. 怎么评估:自建 eval 框架的思路、23 个评测 case、跨模型对比
9. 几件让我重新理解 AI Coding 的事:4 个真实故事
10. 能做到什么程度:边界、成本、给小白的 6 条建议
跟着这篇实战记录走一遍,你也能用 Claude Code 从 0 做出自己的产品。文末我也放上了阿布源码以及设计文档,你可以从中学习。
1. 我做了一款什么产品
我做的东西叫阿布(Abu),一个 AI 桌面应用,你用自然语言告诉它要做什么,它在你的电脑上替你做。
阿布具备性格自定义、长期记忆、自进化能力,可写文档、做报表、操控电脑和浏览器,支持多Agent(智能体)并行和定时任务运行,所有数据本地运行。
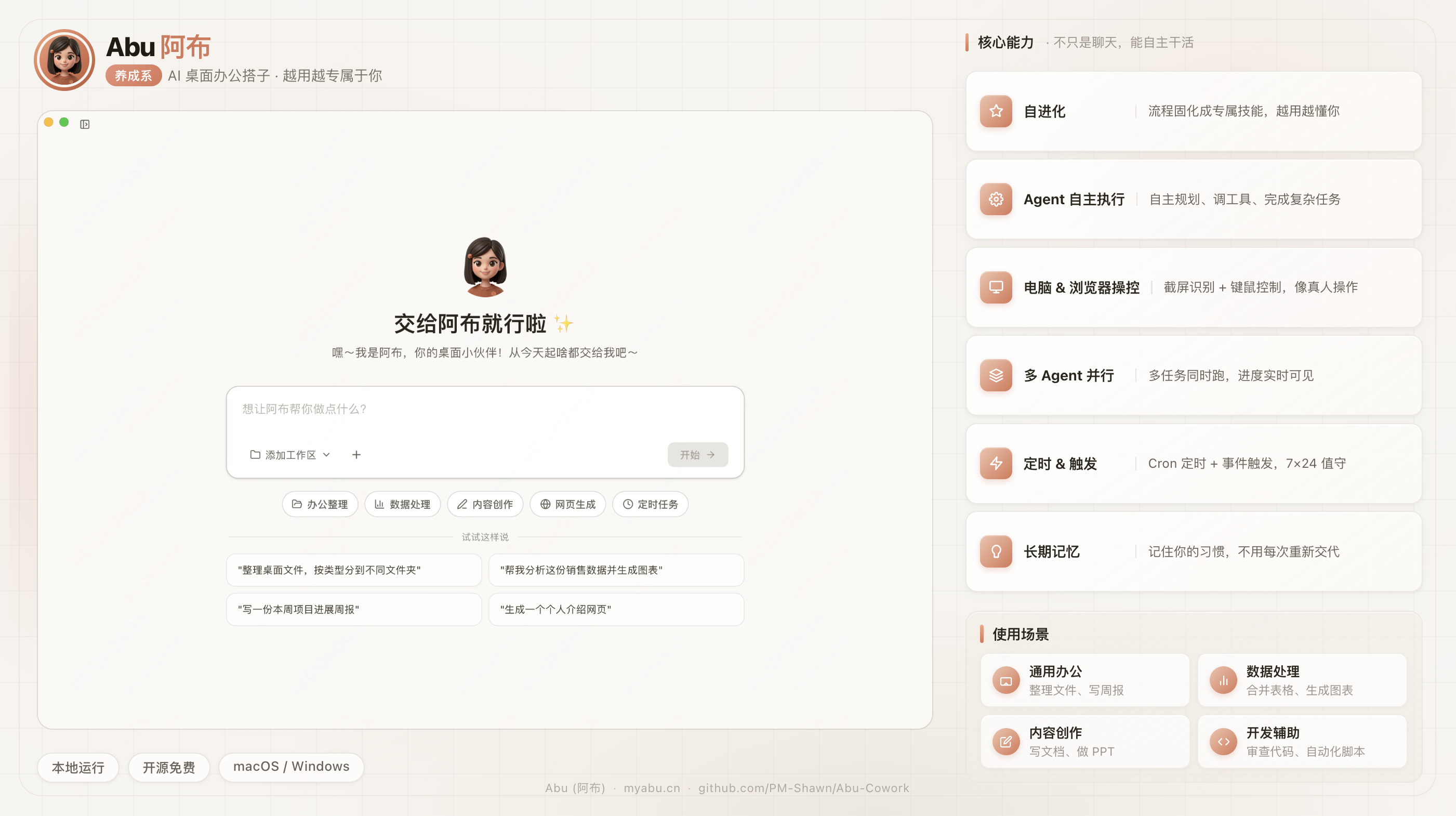
常见的使用场景:
- 操作本地文件。发票整理,读取开票时间和金额,批量重命名并汇总统计。Excel 数据分析,不用写公式,自然语言描述需求直接输出新表。跨文件信息提取,从多份合同里摘出付款条款,整理成对比表格。
- 网页数据抓取。让阿布替你看网页、提取信息、填表单。它直接操作你已经登录的浏览器,不需要重新登录任何系统,不需要你懂爬虫。
- 7×24 小时自动化。接入飞书、钉钉、Slack 机器人,有人在群里 @阿布 它就自动处理。支持定时任务,比如每月第一个工作日自动跑一份数据汇总。
- 自进化。阿布不是一个用完就忘的工具,它会根据聊天内容自动 Review 并沉淀为记忆,还能根据对话上下文自动创建定时任务和 Skills 技能卡片。你教它一次“每月第一个工作日帮我跑数据汇总”,它自己会把这件事变成一个定时任务 + 一张技能卡片,下次不用你再说。用得越多,它越懂你。
说完场景,说说阿布在技术上做到了什么程度。这些听起来像是一个工程团队干的事,但确实是我一个 PM 用 Claude Code 搭出来的:
- 双协议 LLM 适配:同时支持 Anthropic(Claude)和 OpenAI 协议,一套代码接两套 API,retry、成本统计、错误分类全部统一
- OS 级沙箱:macOS 用 Seatbelt(苹果自家的进程隔离)、Windows 用 ConstrainedLanguage,不是在应用层“假装”安全,是操作系统层面真的把危险操作拦住
- Computer Use + 5层安全防御:AI 能看屏幕、点鼠标、敲键盘。但有敏感 app 黑名单、危险按键拦截、全局停止快捷键、会话超时、双中止通道,5 层独立兜底
- MCP 协议:对接外部工具服务器的标准协议,支持 stdio 和 HTTP 两种传输。阿布的浏览器操控就是通过 MCP 接入的
- 多 Agent 编排:主 Agent 可以把大任务拆给多个子 Agent(Subagents)并行执行,每个子 Agent 独立上下文,完成后汇总
- Skills 技能系统:把重复性 SOP 沉淀成 Markdown 格式的技能卡片,AI 自动识别何时激活
- 4 种触发器引擎:HTTP webhook、Cron 定时、文件变更、IM 消息,四种方式触发 Agent 执行
- IM 多平台集成:飞书(WebSocket 长连接)、钉钉(event callback)、Slack(socket mode),一套抽象层适配三个平台
- 文件化记忆系统:Agent 的长期记忆不是塞进一个大文件,而是文件化目录结构,自动迁移、跨设备同步
- 自建 Eval 框架:23 个评测 case,跨 provider 对比工具选择准确率,结构化报告可追踪趋势
- 1,362 个自动化测试:76 个测试文件,8 秒跑完,覆盖工具安全、消息归一化、数据迁移、IM 去重等
几个数字:
- 开发周期:6 周(3 月 2 日 → 4 月 12 日)
- 代码规模:386 个源文件,约 8.5 万行(7 万行 TypeScript + 4,000 行 Rust + 1.5 万行测试)
- Claude Code 交互量:62,376 条消息,45,004 次工具调用
- 总花费:约 1 万元(订阅 5,740 + API 5,000+)
- 峰值日:3 月 1 日,单日 9,259 条消息
看到这你可能会想,这些东西我也能做到?能。这些功能不是我一次性设计出来的,是一周一周长出来的。每一个听起来很”工程”的东西,背后都是一个具体的产品需求 + 一段跟 Claude 的对话。后面我会一步步拆给你看怎么做到。
2. 我用 Claude Code 写代码的工作流
这一节是核心干货。我把”我每天怎么做”拆开给你看,你看完可以直接照着来。
2.1 一个功能从想到做完,我做的几件事
5 步循环:想清楚 → 写一段需求描述 → 让 Claude 写 → 我 review → 跑测试 + 真机验证。
听起来简单,但重点在比例。我花在“想”上的时间,比花在“写”上多得多。Claude 写一个功能可能 10 分钟,但我想清楚”这个功能到底要解决什么问题、用户使用链路是什么”可能要一个晚上。这个比例跟传统开发完全反过来了。
2.2 多窗口并行:一个人同时推多个模块
这是我用 Claude Code 之后发现的最大提效点。
传统开发一个人一次只能写一个模块,你在写 A 的时候,B、C 只能排队。,但 Claude Code 不一样。你可以同时开多个终端窗口,每个窗口跑一个独立的 Claude Code session,并行开发不同模块。

我经常的状态是:左边窗口让 Claude 写 IM 适配层,右边窗口让它写工具安全规则,中间窗口在跑测试。三条线同时推进,我在它们之间切换做 review。等 A 窗口的代码写完我还没 review 完,B 窗口已经出了初稿。
这种工作方式有几个要注意的:
- 模块之间要解耦。两个窗口同时改同一个文件会冲突。所以并行开发的前提是你把功能拆成了不会互相踩脚的模块
- CLAUDE.md 是共享的。所有窗口都会读同一份 CLAUDE.md,所以你的规范和纪律会被统一遵守
- 最后统一跑一遍测试。并行写完之后,关掉多余窗口,在主窗口跑一遍全量测试确认没有互相影响
说实话这种体验很接近”我是一个技术负责人,手下有三个工程师同时在干活”。只不过三个工程师都是 Claude,不需要开会对齐。
2.3 不止让 AI 想技术,要让它先想产品方案和用户链路
这是我做阿布最深的一个体会。
很多人用 Claude Code 的方式是:”帮我加一个 XX 功能”。Claude 马上开始写代码。可能写得还挺对,但做出来之后你会发现”好像不是我想要的”。
问题不在 Claude,在你。你跳过了”想清楚用户场景”这一步。
我的做法是:每次加新功能,第一段对话完全不提技术。我会先聊:
- 用户什么时候会用到这个功能?
- 用户做这件事之前在哪、做完之后到哪?
- 用户怎么知道“做对了”?
- 有什么边界是不能碰的?
想清楚这些之后,技术方案自然就会浮出来。如果跳过这一步,Claude 会默认用”技术上最合理”的方案,但技术上最合理的方案往往不是产品上最合理的。
后面工作示范那节我会用一个真实案例详细演给你看。
2.3 怎么向 Claude 描述需求
我用一个简单的公式:
作为 [角色],我想要 [功能],以便 [价值]。
比如:”作为一个要整理发票的运营,我想要一个能批量读取发票图片并按日期重命名的功能,以便我每月不用手动处理 30 张发票。”
这不是什么高级技巧,就是 User Story 的标准格式。但你会发现,你把这段话写清楚的过程本身就在帮你想清楚。写不出来的地方就是你还没想清楚的地方。
反例:如果你只说”帮我做一个发票功能”,Claude 可能做出一个全自动的发票识别系统 —— 又大又复杂又不是你要的。
2.4 怎么做迭代:不是”重写”,是”理解了再改”
阿布不是一次性写完的,每个功能都经过好几轮迭代。我觉得迭代过程要使用文档记录问题、预期功能,我会在Claude开发间隙,自己去写文档记录。
但我踩过一个大坑:直接说”帮我重构 XX 模块”,Claude 不知道之前的代码为什么这么写,上来就改,结果把之前踩过的坑又重新踩了一遍。
现在我的习惯是,每次大改之前,先让 Claude 写一段“迭代分析”:
- 第一步:「先读一下这个文件,告诉我它现在的设计是什么、为什么这么做」
- 第二步:「如果我要加 XX 功能 / 改 XX 行为,有哪些方案?每个方案的利弊和风险是什么?」
- 第三步:我看完它的分析,觉得它理解对了,才让它开始写
这个多出来的 5 分钟回报非常大。Claude 理解了上下文之后,生成的代码质量高很多,而且不会把之前的修复”无意识地撤销”。
2.5 我怎么 review 它写的代码
说实话,我看不看得懂语法?大致能看懂,但这不是重点。
我 review 的时候真正在看的是 4 件事:
- 逻辑对不对:不是语法层面,是“这段逻辑跟我想的需求一致吗”。Claude 经常写出来的代码“能跑”但“不是我要的”
- 边界条件有没有想到:比如“如果用户传了空字符串会怎样”。这是 AI 最容易漏的
- 跟其他模块的耦合影响:Claude 看不到全局,它不知道改了这个文件会不会影响另一边。我会问它:“这段改动会影响哪些模块?有没有 breaking change?”
- 安全和用户体验:哪些路径不能碰、哪些操作需要用户确认、交互细节是不是顺畅
关键实践:我几乎不会一次就通过。一个方案或一段代码,我通常会 review 2-3 轮。第一轮看大方向对不对,第二轮看边界和耦合,第三轮看细节。每一轮我都会把问题直接丢回去让 Claude 解释或修改:
- 「这段逻辑在 XX 情况下会怎样?」
- 「这个改动会影响 XX 模块吗?影响的话怎么处理?」
- 「这个方案的风险是什么?有没有更稳的做法?」
不要怕多问几轮。Claude 不会不耐烦,而且每多问一轮,它给出来的方案就更完善。很多 bug 不是写出来的,是 review 没抓住的。多轮 review 的成本远低于事后修 bug。
反过来,Claude 比我强的地方:算法选型、性能优化、跨平台兼容这些事我都听它的。术业有专攻。
这倒是让我重新理解了产品经理的价值 ——在 AI 能写所有代码的时代,PM 真正的工作不是不写代码,而是知道什么时候不能让 AI 自由发挥。
2.6 出了 bug 我怎么跟它聊
三条原则:
第一,把报错原文贴回去,不要描述。不要说”有个地方报错了”,直接把终端里的 error trace 粘过去。Claude 能从报错信息里定位问题比你用文字描述精准得多。
第二,让它先解释根因再修。不要一上来就说”修一下”。先让它分析 bug 是怎么产生的,确认分析对了再动手。否则它可能只是在”糊”一个补丁,根因没解决。
第三,修完之后让它顺便写一条测试。提示词:「这个 bug 你刚才修了,请写一个最小的测试用例覆盖它」。这件事几秒钟,但 6 个月之后当 Claude 又要”优化”这段代码时,那条测试会拦下它。
3. 用好 Claude Code 的几个功能
Claude Code 不只是一个”帮你写代码的聊天框”。它有一些功能如果你不知道就会错过,知道了效率会翻倍。
3.1 CLAUDE.md:你和 Claude 之间的合同
这是我觉得 Claude Code 最值钱的功能。
在项目根目录放一个叫 CLAUDE.md 的文件,每次 Claude 开始工作都会先读它。你在里面写什么,Claude 就会遵守什么。
我的 CLAUDE.md 现在有 273 行,里面写了这些事:
- 技术约束:用什么框架、什么语法不许用(比如不许用 enum,要用联合类型)
- 命名规范:变量用英文、UI 文字用中文、commit message 中英双语
- 踩过的坑:比如「必须用 npm run tauri:dev(冒号),空格版会污染正式数据」。这条是我被坑过一次之后加上去的
- 分支纪律:禁止在 main 上直接开发,所有工作在 dev 分支
核心心法:每次踩坑就更新一条。你的 CLAUDE.md 会越长越厚,Claude 的表现会越来越好,因为它每次都在读你所有的”教训”。
3.2 /plan:先想清楚再让它写
输入/plan,Claude 进入”只规划不动手”模式。它会列出方案、分析利弊,但不会写一行代码。
我的工作流:复杂功能先/plan出方案 → 我审 → 同意之后再让它写。这样避免”它写了 500 行代码然后你说不是我要的”的尴尬。
3.3 /insight:每月让 AI 看看你怎么用它
这是一个分析你过去 30 天使用 Claude Code 数据的功能,它会生成一份报告,告诉你”你的工作模式是什么、摩擦点在哪、CLAUDE.md 应该加什么规则”。
我自己每个月跑一次 /insight,然后把它给的建议直接应用到 CLAUDE.md 里。相当于让 Claude 帮你回顾”你跟它的协作效率哪里可以提高”。
3.4 /simplify:让 AI 自己 review 自己
每次写完一个大功能之后,我会跑一遍/simplify。它会扫描你改过的代码,找复用机会、质量问题、效率优化点,然后自动修。
你可以理解为”让 Claude 做自己的代码审查”。它写代码时是在往前赶,/simplify 时是在回头看。这两步节奏配合起来,代码质量比”只管写不管审”好很多。
3.5 /btw:不打断工作流的随手提问
有时候你在写一个功能写到一半,突然想问 Claude 一个不相关的问题,比如”这个 API 的参数是什么意思”。直接问的话会打断当前的开发上下文。
/btw解决这个问题。它开一个”旁白通道”,你随便聊什么都不影响当前的代码开发。聊完了回到主线继续写。像是在结对编程的时候侧过头问搭档一句话。
3.6 /resume:第二天接着写
Claude Code 的上下文在你关闭之后就没了。但如果你昨天写到一半,今天想接着来,输入/resume就能恢复上一次会话的上下文。
跨设备、跨时间段的开发,这个命令非常救命。
4. 工作示范:从 0 加一个”让阿布操作浏览器”的功能
上面讲了方法论,这节用一个真实案例演一遍。
4.1 起心动念
某天我想让阿布”帮我整理需求管理系统里的待评审需求清单”。阿布当时只能读本地文件,没法看网页。 我心里想,能不能让 AI 也操控浏览器去获取数据?
4.2 先想产品方案,不想技术
按照前面说的,我跟 Claude 的第一段对话完全没提技术。聊的全是用户场景:
- 用户什么时候需要让 AI 操作浏览器?填表、数据抓取、操作内部系统后台
- 用户希望 AI 看到的是什么?用户已经登录的页面,不是干净浏览器
- 用户怎么知道 AI 做对了?要看见过程
- 用户的隐私边界在哪?哪些 Cookie 不能碰
想清楚这些之后,一个核心设计决策自然浮出来—— 必须接入用户已有的浏览器,复用用户的登录态。不能启动一个新的浏览器实例。
这一步如果跳过,Claude 默认会推给我 Playwright 方案:启动一个干净的 Chrome、用户得重新登录,跟 Computer Use 没本质区别。产品方案不对的时候,技术写得再漂亮也是白做。
4.3 让 Claude 帮我拆解方案
想清楚用户场景之后,我跟 Claude 说的大概是这个意思:「我想让阿布能操作用户正在用的浏览器,不是打开一个新的,而是直接操作用户已经登录的那个。你帮我想想这件事要拆成哪几块来做。」
Claude 给了我一个方案,拆成了三件事。我看了一下觉得合理:
第一件:做一个 Chrome 浏览器插件。装在用户的 Chrome 里,它能看到用户打开的所有网页,能帮阿布点按钮、填表单、提取页面上的文字。你可以理解为伸进浏览器的一只”手”。
第二件:做一个中间桥接程序。这个程序负责在阿布和浏览器插件之间传话。阿布说”帮我点一下那个按钮”,桥接程序翻译成浏览器插件能听懂的指令,然后把结果传回来。Claude 用的是 MCP 协议(一种让 AI 调用外部工具的标准协议),一共封装了 17 个操作:截图、点击、填写、提取表格等等。
第三件:写一份 Skill 说明书。这份”说明书”是给阿布自己看的,告诉它”什么时候应该用浏览器工具、17 个操作各是干什么的、用错了怎么办”。没有这份说明书,阿布虽然有了工具但不知道什么时候该用。
这三件事 Claude 帮我拆的。我做的事情是:看它拆得对不对、有没有漏、用户视角通不通。比如我追问了一个问题:「用户装这个插件复不复杂?能不能做到一键装好?」这种问题 Claude 自己不会主动想到。
4.4 跟 Claude 怎么聊这个需求
拆完方案之后,我分三轮跟 Claude 聊,每轮解决一件事。
第一轮,我大概这么说的:「我要做一个 Chrome 浏览器插件,用户装上之后,阿布能通过它看到用户打开的网页、帮用户点按钮和填表单。先帮我把这个插件写出来。」
Claude 写完之后会生成一份”通信格式”的定义(就是插件和外部程序之间怎么传消息的约定)。
第二轮,我把这份定义贴给 Claude,说:「现在帮我写桥接程序。它要能跟刚才那个插件对接,把阿布的指令翻译成插件能执行的操作。对接的格式就按刚才那份来。」
第三轮,我说:「现在帮我写一份 Skill 说明书,教阿布什么时候用浏览器工具、什么时候不该用、每个操作是干什么的。」
关键技巧就一个:先让 Claude 定好“两边怎么对话”的规则,再分别写两边的代码。这样写出来的东西自然能对上,不会出现”插件发的消息桥接程序听不懂”的情况。
4.5 写出来后我怎么验证
真机测试:
- 把 Chrome 插件手动装到浏览器里
- 启动桥接程序
- 让阿布“打开一个网页、提取标题”
- 看是不是真的能跑通
第一次跑就遇到两个坑:一个是插件和桥接程序之间的身份验证没对上(连不上),另一个是某些网页内容是动态加载的,插件去找的时候页面还没渲染完。都是”我本地测通了、换个网页就翻车”的经典场景。
修复之后我做了跟每次一样的事,让 Claude 给这两个坑各写了一条测试。
做这个功能让我意识到一件事。做“让 AI 操作工具”类产品,最难的不是让工具能跑,而是让 AI 知道什么时候该用。所以那份 Skill 说明书比代码本身更重要。一个看起来是”技术功能”的需求,从想到做完,技术只占 30%,70% 是想清楚用户场景和工具边界。
5. 怎么让 AI 写出审美在线的 UI
这是小白最容易踩的坑之一。你让 Claude 写 UI,它默认给你的是灰色背景、蓝色按钮、Bootstrap 既视感。不是 Claude 不会写好看的,是你没告诉它”什么叫好看”。
5.1 怎么给 AI 描述”审美”
三种方式:
贴截图。找一个你喜欢的产品(Linear、Vercel、Notion),截一张图发给 Claude,说”这个风格”。它能从截图里识别出颜色、间距、圆角、字体的感觉。
定 design token。颜色、间距、圆角、字体先约定好,写进 CLAUDE.md。阿布的 design token 是:主色用克莱因蓝系、背景用柔白、文字用温暖灰、圆角 8/12/16 三档。每次 Claude 写新组件都自动套用。
指定参考库。”用 shadcn 的组件风格”、”间距参照 Apple HIG”。一句话就能框定审美范围。
关键:不要说“做漂亮一点”。这句话对 AI 来说没有任何信息量。你要给具体参照。
5.2 约定一旦定下来,AI 会自己保持一致
这是一个”复利效应”。你在 CLAUDE.md 里定好 design token 之后,后面每加一个组件、每做一个页面,Claude 都会自动套用同一套视觉语言。你不用每次都重复说”用那个蓝色”。
几轮迭代之后,它甚至能理解你的审美偏好。比如我偏好暗色主题、毛玻璃质感、细边框,它后来自己做出来的东西就已经很接近我想要的了。
AI 不会变美,是你要教它什么叫美—— 但你只需要教一次。
6. 怎么可持续构建
很多人用 AI 写代码的方式是”一口气写完、扔上去就跑”。这在做 demo 的时候没问题,但如果你想做一个能持续迭代的产品,从第一天就需要一套框架。
我在做阿布的过程中摸索出来的框架大概是这样的,5 条纪律,覆盖从”每天开始写代码”到”发版给用户”的全链路:
纪律 1:分支隔离。dev 分支写代码,main 分支给用户。绝不在 main 上直接开发。
纪律 2:版本号同步。发版时所有版本号一起改,不能漏。
纪律 3:提交前检查。build 能过、lint 没报错、测试全绿,才允许 commit。
纪律 4:commit 纪律。每个有意义的变更单独 commit,格式 conventional commits,中英双语。
纪律 5:发版清单。版本号 → merge 到 main → 打 tag → push → 写 changelog。
听起来像是”正确的废话”,但每一条都是事故教出来的。下面讲几个我真实踩过的坑。
6.1 一个关于 main 分支的事故
某次发完版之后,我忘了切回 dev 分支,直接在 main 上继续写代码了。等我发现的时候已经在 main 上提交了好几个 commit,跟 dev 的代码产生了冲突。
那一次手动解决合并冲突花了不少时间。修完之后我做了一件事,把这条规则写进了 CLAUDE.md:
禁止直接在 main 上开发或 push commit。所有工作在 dev 分支进行。
每次开始工作前必做:
1.git branch –show-current —— 确认当前分支
2.如果在 main,先 git checkout dev
3.git pull origin dev —— 拉取最新代码
从那以后 Claude 每次开始工作都会先检查当前分支。CLAUDE.md 不只是约束你自己,也是约束 AI 的。
6.2 三处版本号没同步,发版翻车
阿布有三个地方存版本号:package.json(前端)、src-tauri/tauri.conf.json(Tauri 配置)、src-tauri/Cargo.toml(Rust 构建)。发版时三处必须同时改。
有一次我只改了 package.json 的版本号,忘了改另外两处。结果构建出来的安装包版本号对不上,自动更新检测失效,用户那边怎么都收不到新版本。
修完之后这条也进了 CLAUDE.md:
三处版本号必须同步更新:package.json、src-tauri/tauri.conf.json、src-tauri/Cargo.toml。
然后发版流程也被固化成了一个清单:
1.确保 dev 分支 build + lint + test 全绿
2.三处版本号同步更新
3.git checkout main && git merge dev
4.git tag vX.Y.Z
5.git push origin main –tags
6.在 GitHub 创建 Release
每次发版我让 Claude 按这个清单走,它比我自己记得牢。
6.3 提交前检查:build + lint + test 三连
这也是被坑出来的。有一次我改了一段代码,什么都没检查就提交了,结果代码有语法问题,整个应用构建失败。
现在的规则是,每次提交代码之前必须跑三样检查:
第一,编译检查(build)。让程序试着把你的代码”翻译”成计算机能跑的版本。如果代码里有语法错误、类型写错了,这一步就会报错。相当于”你写的东西能不能被机器读懂”。
第二,规范检查(lint)。自动扫描你的代码有没有违反预设的编码规范,比如变量命名不统一、有未使用的代码、格式不对。相当于”你写的东西符不符合团队约定”。
第三,测试检查(test)。跑一遍全部 1,362 个测试,看有没有哪个功能被你这次改动”误伤”了。相当于”你改完之后,原来能用的东西还能不能用”。
三样加起来不到 20 秒。20 秒换一个”不会把有问题的代码推上去”的保证,我觉得这是做产品最便宜的保险。
6.4 commit 节奏和双语 message
每个有意义的变更单独 commit,不要积累一大堆一次性提交。格式用 conventional commits:feat:新功能 /fix:修 bug /refactor:重构 /docs:文档 /test:测试。
我还有一个习惯,commit message 写中英双语。英文在上面给社区开发者看,中文在下面给我自己 6 周之后看。举个真实例子:
feat(computer-use): sensitive app blocking + dangerous key interception
每个操作前检查前台 app 和按键组合安全性。敏感 app 用 bundle_id 匹配(跨语言)。
你可能觉得”我又不开源”,但我跟你说,git log 是你未来最好的回忆。你 3 个月后想知道”我当时为什么改了这段代码”,就靠 commit message。
Claude 不会自动管这些纪律,你得替它想。但好消息是,你只需要把规则写进 CLAUDE.md 一次,之后每次它开始工作都会自动遵守。这套框架本质上就是你和 AI 之间的流程合同。
7. 怎么写测试
我原来根本不写测试。「测试是个文件、跟代码放一起」这种事是做阿布之后才知道的。现在阿布有 76 个测试文件、1,362 个用例,跑全量 8 秒。下面讲我的实践 —— 不是”正确的做法”,是”我被坑出来的做法”。
7.1 为什么写:Claude 会反复修同一个 bug
这是我开始写测试的直接原因。Claude 在改一段相关代码的时候,会把之前的修复”无意识地”撤销,因为它没有那次修复的记忆。一条测试就是用来对抗这种遗忘的:下次它想”简化”这段代码,测试会立刻变红。
7.2 怎么让 AI 帮你写
我的做法极简:每修一个 bug,让 Claude 顺便写一条最小测试。提示词就一句:「这个 bug 你刚才修了,请写一个最小的测试用例覆盖它」。几秒钟的事。
测试文件和源码放同一个目录,chatStore.ts旁边就是chatStore.test.ts。约定一旦定下来,Claude 自己会保持一致。
7.3 真实实践:版本注册表
举一个我觉得最有价值的测试实践。
先说背景:阿布会把用户的设置、对话历史、定时任务等 10 类数据存在用户的电脑本地。问题是,我经常会让 Claude 改这些数据的格式(比如加一个新字段、改一个字段名)。每次改格式,都必须同时做一件事:写一段”把老格式自动转成新格式”的代码(叫 migrate),否则老用户打开 Abu 就会因为格式对不上而崩溃。
我被这件事坑过一次之后(参见前面”搞炸用户数据”那个故事),做了一个机制:把所有会被存到本地的数据模块,登记在一张清单里。
这张清单大概长这样:设置(已改 16 次)、对话(已改 4 次)、定时任务(已改 3 次)、触发器(已改 4 次)…
清单有什么用?它跑两个自动检查:
第一个检查:版本号对不对。每次改格式都要把版本号 +1。如果有人改了格式但忘了 +1,检查会报错。
第二个检查:有没有漏登记的。自动扫描所有存在本地的数据,只要发现有数据不在清单里(说明有人加了新数据但忘了登记),立刻报错。
第二个检查是真正救命的。它意味着,只要 Claude 悄悄加了一个新的会被存到本地的数据类型,但忘了登记和写 migrate,提交代码的时候就会被自动拦下来。
“设置”这类数据在短短 6 周里改了 16 次格式。如果没有这张清单,这 16 次里有任何一次忘了写格式转换,都会让一批用户的本地数据炸掉。
这个做法的核心启发是:最好的测试不是测“功能对不对”,而是测“我有没有忘了某件事”。
7.4 测试分布:76 个文件都在守护什么
按模块分:工具系统 10 个文件、IM 集成 8 个、LLM 适配 7 个、Agent 引擎 7 个、上下文管理 5 个、数据持久化 10 个、跨模块集成 4 个。
其中用例最多的几个:工作流提取器 80 个 case(消息流解析规则多到吓人)、路径安全 42 个(每条对应一个目录穿越/敏感路径场景)、消息归一化 30+ 个(覆盖各种”模型可能返回的奇怪消息形态”)。
每一个数字的背后都有一个真实的事故。我不会为了”覆盖率”去写测试,只会在被坑了之后写。
7.5 跑得越快越好
阿布 1,362 个测试跑全量 8 秒。这个数字很关键,如果跑一次要 5 分钟,我大概率就懒得跑。8 秒意味着我每次提交前都会跑一遍,提交前检查不会变成负担。
6 周,从 0 到 1,362 个测试。不是因为我爱写测试,是因为不写真的会翻车。测试是我跟 Claude 之间的合同 —— 你想改什么都可以,但这些东西不能动。
8. 怎么评估
AI 产品有一件事跟传统软件不一样:你不知道它今天是不是变笨了。
你换了模型、改了 prompt、加了新工具,怎么知道效果是变好还是变差?传统软件测试是”输入 A 期望输出 B”,AI 产品是”输入 A 期望模型做出大致正确的判断”,这种事没法精确断言。
我做了一件当时觉得”是不是太工程了”的事,自己搭了一个评估器。做完之后发现这可能是阿布里最值钱的一部分基础设施。
8.1 构建思路:从”我想知道什么”倒推
搭 eval 的第一步不是写代码,而是想清楚”我到底想知道什么”。
我最担心的问题是:阿布有 26 个内置工具,用户说一句话,模型选对工具了吗?比如用户说”帮我看看桌面的文件列表”,模型应该选list_directory还是run_command?用户说”把这段文字写进 note.txt”,模型应该选write_file还是edit_file?
这个”选工具”的准确率直接决定产品体验。选错了,用户等半天发现阿布做了一件完全不相关的事。
想清楚要评估什么之后,设计就自然了:
输入:一句用户消息(比如”帮我看看 ~/Documents/report.md 的内容”)模型行为:模型决定该调哪个工具、传什么参数判断标准:必须调的工具调了没有?禁止调的工具有没有误调?参数传对了没有?
这三条判断标准就是 eval 的核心,不需要真的执行工具,只看模型”选了什么”,不看”做得怎么样”。
8.2 我的真实实践:23 个评测 case
我给阿布写了 23 个评测 case,分成 8 个类别:
文件操作(4 个)/ 搜索(8 个)/ 命令执行(4 个)/ 多步任务(2 个)/ 记忆(2 个)/ 网页(1 个)/ 知识(1 个)/ 代理委派(1 个)
每个 case 长这样(用大白话讲):
Case:file-read-01用户说:「帮我看看 ~/Documents/report.md 的内容」 期望:模型必须调用read_file工具 难度:easy
Case:file-edit-01用户说:「把 src/config.ts 里的 API_URL 从 localhost 改成 production.api.com」 期望:模型必须先调read_file(先看看文件内容),不能直接调write_file(不然会覆盖整个文件) 难度:medium
你看,定义这些 case 不需要懂代码,需要的是“想清楚什么情况下算对”。这是 PM 的强项。
按难度分:13 个 easy、8 个 medium、2 个 hard。先把简单的覆盖全,再逐渐加难的。跟做产品一样的优先级思路。
8.3 跨 provider 对比:同一组 case 跑在不同模型上
eval 最有价值的用法是:同一组 23 个 case,分别跑在 Claude、OpenAI、国产模型(比如 MiniMax)上,对比通过率。
跑的方式很简单,一行命令:
tsx src/eval/run.ts tool-selection –provider anthropic –model claude-sonnet-4-20250514
换一个 provider 就换一下参数:
tsx src/eval/run.ts tool-selection –provider openai –model gpt-4o
结果会自动生成一份报告,按类别和难度拆开看通过率。两份报告还能 diff,你一眼就能看到”换了模型之后哪些 case 变差了”。
8.4 eval 不是工程师的专利
先说 eval 这个词。Eval 是 evaluation(评估)的缩写,在 AI 行业里指的是:写一组“考试题”来测 AI 做得对不对。就像老师出一套试卷考学生一样,你出一套试卷考你的 AI 产品。
具体怎么做?三步:
第一步,出题。想几个典型的用户场景,写下来。比如”用户说帮我看看桌面的文件列表”。
第二步,写标准答案。每道题写清楚”AI 应该做什么才算对”。比如这道题的标准答案是”AI 应该调用读取目录的工具,不应该去执行命令”。
第三步,让 AI 答题,自动判分。把题目喂给 AI,看它选的工具跟标准答案对不对。对了就 pass,错了就 fail。跑完 23 道题出一份报告,一眼看到通过率。
你可能觉得”PM 搞这个是不是小题大做”。但做完之后我发现,eval 的本质不是技术,是“想清楚怎么判断对错”。
出题需要什么能力?
- 描述一个用户场景(PM 天天干的事)
- 定义“做对了”长什么样(PM 的核心能力)
- 定义“做错了”有哪些常见模式(PM 的踩坑经验)
代码部分全是 Claude 帮你写的。你只需要想清楚那 23 道题应该考什么,这件事恰恰是 PM 最擅长的。
PM 在 AI 时代真正不可替代的能力,是替模型定义”什么叫做对了”。
9. 几件让我重新理解 AI Coding 的事
6 周里有 4 件事让我印象深刻。不是技术细节,是”我对 AI Coding 的理解被改变了”的瞬间。
那一晚模型试图打开我的钥匙串。阿布有一个 Computer Use 功能,模型能看屏幕、点鼠标。某天晚上我在 dev 环境跑测试,模型截屏看了一圈,然后在 Spotlight 搜索框里输入了”Keychain Access”。那一瞬间我意识到,模型完全有能力打开我电脑上任何 app。第二天我从早上写到深夜,连发 5 个 commit,一次性加了敏感 app 黑名单、危险按键拦截、全局停止快捷键、会话超时。那是我做阿布以来最有”产品恐惧感”的一天。
我发了一次版搞炸了用户数据。改了一个字段名,我本地测了没问题就发版了。当晚用户说”打开是空白”。因为老用户存在硬盘上的是旧字段名,新代码读不到。从那以后我做了”版本号 + migrate + 注册表”三道锁,到现在设置数据结构已经改了 16 次,再没出过这种事。
在 main 分支上直接开发。发完版忘了切回 dev,直接在 main 上继续写了好几个 commit。等发现的时候已经跟 dev 冲突了。手动解决合并冲突花了不少时间。从那以后 CLAUDE.md 里多了一条硬规则。
3 月 1 日单日 9,259 条消息。从 stats 里看到这个数字的时候我自己也吓了一跳。那天从早到晚就没停过,从一个空文件夹开始,到晚上已经有了一个能跑的桌面应用。那种”想法变成产品”的速度,以前是不可能的。
AI Coding 不是让你写代码更快 —— 它逼你直面那些以前可以装看不见的问题。安全、数据迁移、分支管理 —— 这些事你以前可以说”等有工程师了再想”,现在你就是那个工程师。
10. 能做到什么程度 + 给小白的建议
说实话写到这里我自己也觉得有点不真实。一个产品经理,6 周,8.5 万行代码,一个有完整安全体系、跨平台(Mac + Windows)、1,362 个测试、多模型适配、IM 集成、浏览器操控的桌面应用。
但我想诚实地说一下边界。
能做到什么:一个从 0 到 1 的、真实可用的完整产品。不是 demo,是能发版、有用户在用的东西。从产品设计到架构到实现到测试到发版,一个人全链路。
不能做到什么:极致性能优化(编译器层面的事我搞不定)、原创算法设计(什么时候该用 BFS 我不知道)、百万 QPS 级别的分布式系统(这不是一个人能做的事)。
需要付出什么:
- 钱:约 1 万元。订阅 5,740 + API 5,000+。第一周会觉得烧得很快,别慌,节奏稳下来之后消耗会下降
- 时间:我这 6 周里有 34 天在写,平均每天 4-6 小时。峰值日干了一整天
- 心理建设:第一周会被 Claude 搞崩 N 次。报错看不懂、改了又坏、越改越乱。这是正常的。撑过第一周就好了
- 最重要的:愿意“想清楚”。Claude 把“写代码”从瓶颈里拿掉了,但它没把“想清楚要什么”从瓶颈里拿掉。前者是工程师的事,后者一直是 PM 的事
想说给小白的你
如果你也想开始,这是我给过去自己的几条建议:
第一,先选一个你自己天天会用的小工具去做。不要做”大产品”,做”我自己每天会用的东西”。动力来自你自己的需求,做完了你就是第一个用户。
第二,第一周不写测试,找感觉。前期是做 demo 的阶段,写测试反而拖慢你。等你第一次被 bug 坑了再补,那时候你会自然而然地想写。
第三,成本会比你预期的高 3 倍。第一周烧 1000 块是正常的,别慌,Claude Code 的消耗量跟你想象的不一样,Pro 额度很快就不够用。
第四,从第一天就建 CLAUDE.md。你跟 Claude 的每一次磨合都是在往这个文件里加一条”合同条款”。越早开始,后面越顺。
第五,不要追求一次性做大功能。一个一个加,每个加完都跑一遍测试。小步快跑比大步摔跤强。
第六,让 Claude 先想产品再想技术。这是我做阿布最深的体会。它默认会直接进入”怎么实现”,你要把它拉回来:”先告诉我用户是谁、场景是什么、做完之后是什么状态。”
你不需要学会编程,你需要学会跟一个会编程的伙伴说话。
阿布开源地址:https://github.com/PM-Shawn/Abu-Cowork
本文由 @Shawn 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









飒飒撒打算
飒飒
如果不懂技术的话,vibecoding出来的产品,能商用吗,还是只能当demo。
最好需要技术同学Review下
嗯嗯