
 起点课堂会员权益
起点课堂会员权益一文讲透医疗 AI 的隐私合规:技术、场景、落地、避坑
医疗AI领域的数据隐私合规远比技术难题更致命。从CTO的轻率提问到法务的紧急刹车,作者用半年踩坑经验总结出医疗健康类产品的生存法则:覆盖6大隐私技术选型陷阱、四层合规架构设计,以及那些连工程师都会忽视的致命细节。文末附赠可直接落地的Checklist和架构图,为同行节省至少三个月的试错成本。

前年我接手一款 AI 健康档案管理系统。第一次评审会,CTO 问我:“用户上传的体检报告,直接发给 GPT-4 解读行不行?反正接口都加密了。”
我点头说没问题。
那天下午法务找我谈了两个小时。
谈完我才反应过来——医疗 AI 这赛道,技术不是门槛,模型也不是门槛,真正卡脖子的是数据隐私。一不留神产品上不了线,再不留神公司被监管罚到怀疑人生。
下面这些是我半年踩过的坑、对比过的方案,做医疗 AI、健康管家、互联网医院、保险科技这类产品的同行,应该能省你不止三个月时间。
正文分四块:黑话扫盲、6 种技术、场景选型、落地架构。文末有 Checklist 和架构图,建议先收藏再读。
一、几个必须懂的黑话
EMR:电子病历。医院里那套数字化的病历本,主诉、化验、影像、医嘱都在里面。国内系统主要是东软、卫宁、嘉和、创业慧康四家,国外是 Epic、Cerner。
PHR:个人健康档案。EMR 是医院持有的,PHR 是用户自己持有的——体重秤数据、苹果手表心率、自己上传的体检报告。我做的健康档案管理系统本质就是 PHR 平台。
FHIR:医疗数据互通的国际标准,可以理解成不同医院系统之间的”普通话”。
IRB:伦理审查委员会。想拿真实病历训练模型?先报 IRB。三甲一般审 1–3 个月。这就是为什么很多公司算法早期更愿意用合成数据——合成数据在多数地区不算个人信息,能绕开 IRB 等待期。
PoC:概念验证。厂商最爱说“我们和某某医院做过 PoC”,听听就行,PoC 成功离量产差十万八千里。
法规层面记住三个:HIPAA(美)、个保法(中国 2021)、卫健委 2022 年的《医疗卫生机构数据安全管理办法》。还有一条狠的,医疗数据出境必须报网信办评估,2023 年起执行。
二、6 种主流隐私技术
市面上各种隐私技术吹得花里胡哨,本质就 6 种。
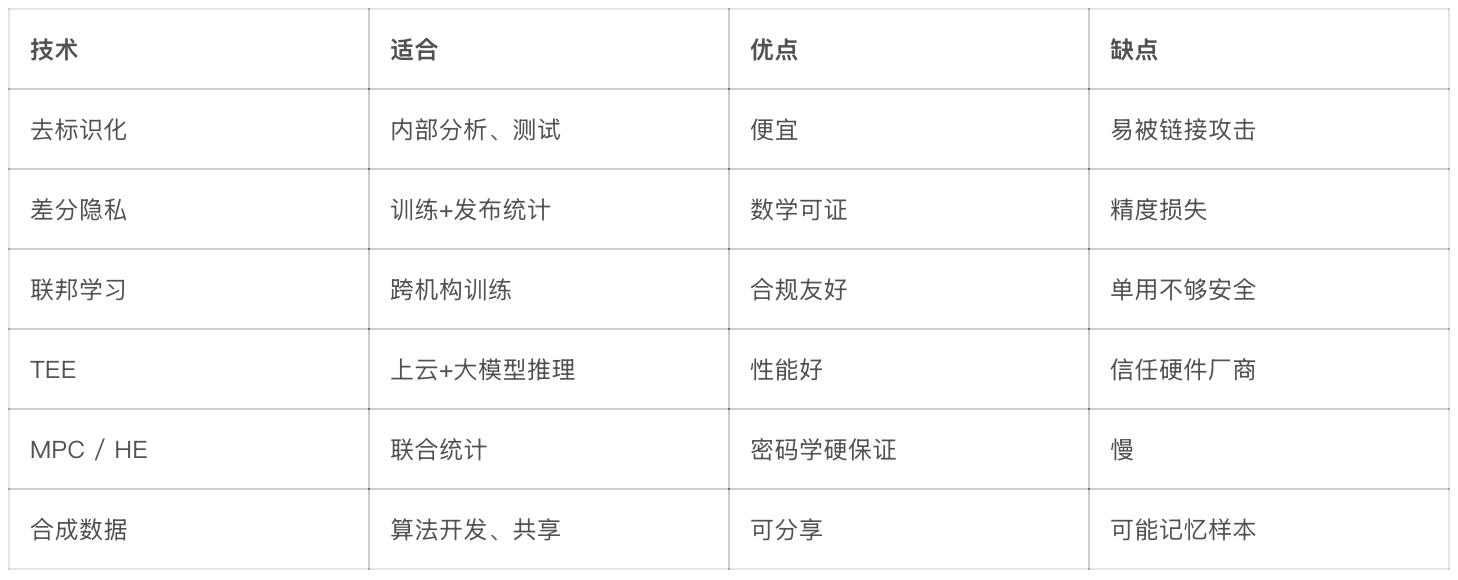
1)去标识化
最基础也最便宜。删姓名身份证、生日精度降到年、地址只到区县。HIPAA 列了 18 项必须去掉的字段。国内绝大多数医疗 App 还停在这一层。
缺点是容易被链接攻击破解。1997 年哈佛 Sweeney 教授做过一个经典实验:麻省政府公开了“匿名”的医疗数据,只删了姓名地址但留了生日、性别、邮编。她花 20 美元买了选民名册,按这三个字段一关联,直接定位到时任州长,把住院记录寄到他办公室。后续研究证明仅这三个字段就能唯一识别 87% 的美国人。
2)差分隐私 DP
数学上可证明的隐私保护,监管最认。做法是在结果里加噪声,让“加一个用户进来 vs 不加进来”对输出的影响小于参数 ε。
用大白话讲:老师统计班里平均身高,又不想让任何人具体身高被推出来。每个学生汇报时自己加一个 -5 到 +5 的随机数。班级一平均,随机数互相抵消,平均值接近真实;但任何单个学生的真实身高老师永远拿不到。
ε 越小,噪声越大,隐私越强但精度越差。适合发布统计指标、训练大规模医学模型。蚂蚁、字节内部隐私基础设施都用 DP,医疗领域真正跑通的不多。
3)联邦学习 FL
数据不动模型动。中心服务器把模型发给每家医院,各家用自己的数据本地训几轮,把参数(不是数据)传回服务器,加权平均成新版本再发下去,循环 N 轮。
适合跨医院影像模型训练、跨机构慢病研究。
关键提醒:单独用 FL 不安全。研究证明光传梯度也能被反推出原始数据(gradient leakage),必须叠加 DP 或安全聚合。
国内玩家:微众银行 FATE(最早开源)、蚂蚁摩斯、翼方健数、洞见科技、富数科技、华控清交。
4)TEE 可信执行环境
CPU 里一块加密的“小黑屋”,操作系统都进不去。数据进去解密计算,出来又加密,云厂商运维和 root 用户都看不到里面在算什么。
打个比方:你把现金交给银行 VIP 保险室,门一关连行长都进不去,但你能远程验证这房间是那种型号、没被改装过——这步叫“远程证明”。
代表产品:Intel SGX/TDX、AMD SEV、NVIDIA H100 Confidential Compute。性能损耗一般 8% 以内,可以跑完整深度学习栈。微软 Azure 中国版、阿里云、腾讯云都能直接买。
不完美的地方是信任根落在硬件厂商身上——你信 TEE 安全,本质是信 Intel/AMD 没在芯片里留后门。Spectre/Meltdown(2018)、SGAxe(2020)、ÆPIC Leak(2022)都打过 SGX 的脸。
5)MPC / HE 安全多方计算与同态加密
密码学硬保证,原始数据全程不解密。MPC 把计算任务拆给多方,HE 在密文上直接做加法乘法。
优点是无懈可击。缺点是慢——HE 跑深度网络推理慢 100 到 1000 倍。目前只适合中小算子或特定场景,比如基因组联合分析、保险核保。
国内玩家:华控清交、富数科技、矩阵元做 MPC,蚂蚁、字节内部有 HE 实践。
6)合成数据
用模型从真实数据学到分布,再生成“看起来真但不对应任何真人”的虚拟病例。
三代演进。第一代基于规则,MITRE 开源的 Synthea 一行命令生成一万个虚拟美国人完整病历。第二代用 GAN。第三代用扩散模型和大语言模型——NVIDIA MAISI(2024)生成医学影像,国内用 Qwen、Llama 微调后生成虚拟病历。
适合算法早期开发、罕见病数据补充、规避 IRB。有风险——可能记忆并泄露真实样本,监管对“合成数据”是不是“个人信息”也没定论。
国内玩家:医准智能、零氪科技、医渡科技都在大量用合成 EMR 做算法迭代。
六种放一起对比:
三、场景 × 技术,到底选哪个
实际项目几乎没人单用一种,一般是 2–3 种组合。
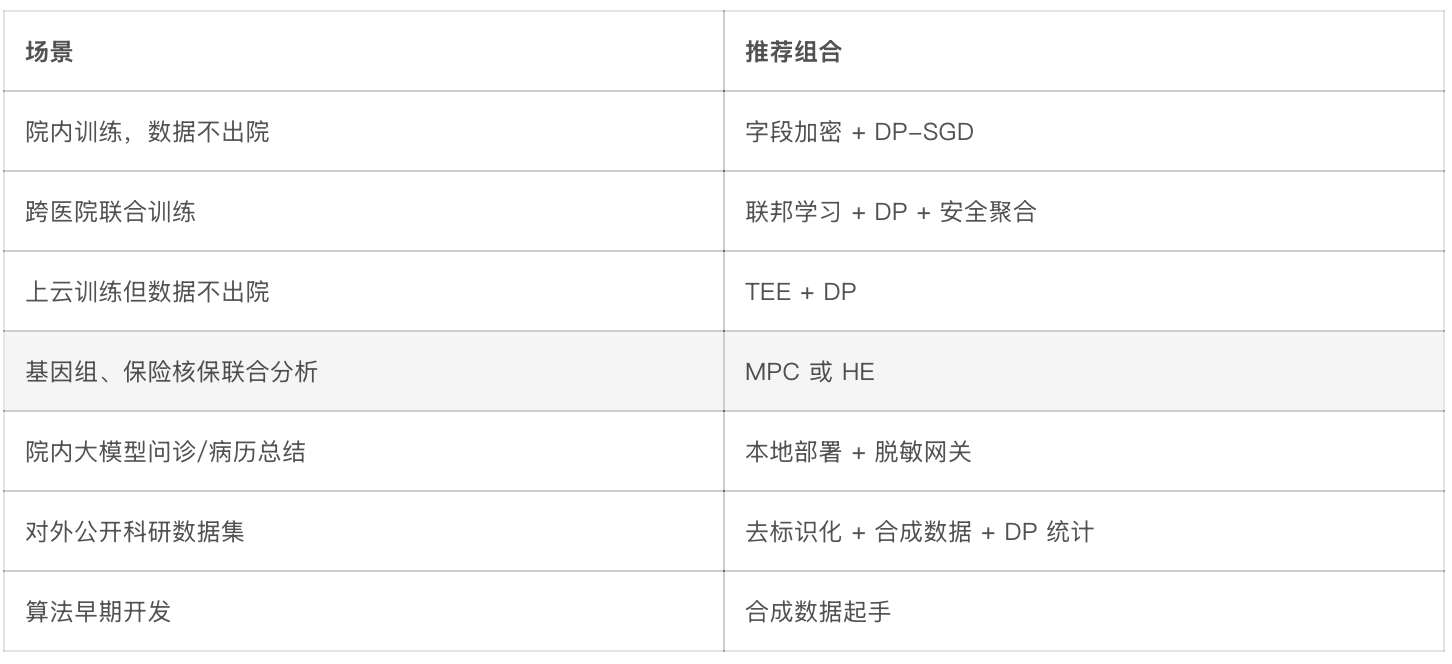
挑选时问自己三个问题就够了。
数据能不能出院、出公司?不能上 FL,可以但不能上公网就上 TEE。
要不要训自己的模型?要训就考虑 DP-SGD;只调 API 就重点做脱敏网关。
监管要不要数学证明?医保、保险、政府项目通常要,就上 DP;纯商业产品不必那么硬。
我自己产品分三期:第一期只做字段加密+脱敏网关,第二期叠 DP,第三期接 FL。
四、落地四层架构(开发同事真正要的)
第 0 层 合规底座
等保三级测评(30–50 万,3–6 个月)、个保影响评估、数据出境评估、用户授权分层勾选(基础服务必选、AI 训练单独勾、第三方共享单独勾)。
我见过太多团队跳过这层直接搞技术,上线前两周被法务卡住推迟三个月,那才叫真坑。
第 1 层 采集端
能不要的字段坚决不要。健康管家不需要身份证号,手机号哈希(Hash)做 ID 就够。
体检报告上传时,手机本地用轻量 OCR 提取数据,姓名、医院、医生名字在本地就抹掉,只把“血糖 6.8 / 血压 130/85”上传到服务器。这一步看着多余,意义在于你接触不到的数据就不存在泄露风险。
第 2 层 存储端
name、phone、id_card_no 等 AES-256 加密,密钥放云厂商 KMS。手机号要做查询索引就再加一个 HMAC 哈希字段。
重点提醒哈希要加盐。手机号直接 SHA256 太危险,攻击者用彩虹表(提前算好十几亿条常见手机号的哈希值)一查就还原。每条记录配独立随机盐,或者用 bcrypt/Argon2 这种慢哈希,每次故意慢 0.1 秒,彩虹表立刻失效。
时序数据(血压、血糖、心率)建议存 InfluxDB,里面只存 customer_id,不存身份信息——时序库即使被拖也不会泄露个人识别。
第 3 层 AI 调用层
这是我踩坑最多的地方。最容易出事的不是用户攻击,是工程师贪方便。“客户主诉直接发 GPT 就行,反正接口加密”——这话我听过不下十次,每次都得拦下来。
我们最后定的方案叫脱敏网关:
用户消息:我叫张三,38 岁糖尿病 5 年,吃二甲双胍后拉肚子 ↓ 网关替换 PII:张三 → [NAME_001] 二甲双胍保留(医学价值字段) ↓ 发给大模型:”我叫[NAME_001],38 岁糖尿病 5 年…” ↓ 模型返回:”[NAME_001]您好,二甲双胍常见副作用…” ↓ 还原 [NAME_001] → 张三,展示给用户
工具:开源用 Microsoft Presidio(中文要自己加规则),商用可考虑 Private AI、同盾、瑞数。
大模型选型必须重新算账。OpenAI、Claude 直连——医疗场景别想,数据出境违规。Azure 中国版仍要出境评估。主用通义千问 / DeepSeek / 文心;医疗专用走卫宁 WiNGPT、医联 MedGPT、京医千询;B 端项目自部署 Qwen 或 Llama-3。
我现在产品用通义 + DeepSeek 双通道,严肃健康问题走 DeepSeek(思考链路强),日常对话走通义(便宜)。
第 4 层 训练层
要训自己的模型记住三条。冷启动用合成数据(Synthea 改中国版或大模型批量生成);真实数据微调时叠 DP-SGD;跨机构合作走联邦学习——我们曾经想接体检机构数据,对方第一反应是“数据不可能给你”,FL 是唯一谈得下去的方案。
五、Checklist 与架构图
直接拿去 PRD 用。
合规底座
□ 字段分级目录文档化 □ 用户授权分层勾选 □ 隐私政策更新 □ 等保三级测评启动 □ DPO 数据保护官就位
技术落地
□ KMS 接入,敏感字段全部加密 □ 哈希加盐 / bcrypt 改造 □ 审计日志冷热分层 □ 时序库去身份化 □ 端侧 OCR
AI 调用
□ 脱敏网关上线 □ 大模型选型走境内合规通道 □ 第三方 SDK 审计(友盟、神策不能埋健康字段) □ AI 输出引用追溯链
进阶
□ DP-SGD 训练管道 □ 联邦学习接入第三方数据 □ TEE 部署评估 □ 机器遗忘流程
架构图:

写在最后
医疗 AI 的隐私合规,技术只占 40%,剩下 60% 是制度、流程、人。
我见过太多技术做得很猛的团队,因为客服可以随意查所有客户就诊记录、因为测试环境用了生产数据没脱敏、因为离职员工账号没及时回收,监管一查一个准。
技术能买,工具能买,方案能抄。但”医疗数据是别人的命”这句话,必须刻进每一行代码、每一次评审、每一份 PRD。
如果你也踩过类似的坑,评论区聊聊。
本文由 @Niney 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


