
 起点课堂会员权益
起点课堂会员权益AI写代码的速率是人的10倍,端到端却只快了2倍:产品经理视角下,没人讲清楚的3件事
当AI编码效率提升10倍,为何整体需求交付仅提速2-3倍?真相藏在被忽视的审阅带宽与系统瓶颈中。本文犀利指出:AI时代的真正限速点并非技术能力,而是陈旧的审阅体系、封闭的系统架构与缺失的责任归属机制——这些恰恰是产品经理最能发力的战场。

阿里技术最近有一篇文章,数据很扎心:深度使用AI的工程师,纯编码效率提升了10倍,但端到端的需求交付效率只提升了2到3倍。
很多人看到这个数字会说:AI还不够成熟。
但如果你真的把Claude Code、Cursor、Manus这些工具用进日常工作,用到上瘾,你会发现一件反直觉的事——限速的地方,根本不是AI能力。
作为产品经理,我想分享3件事:AI时代的真实瓶颈在哪里,以及一个几乎没有人在认真讨论、但迟早会爆的治理问题。

一、把产出换算成token,瓶颈就看清楚了
传统理解里,”AI提效”的图景是这样的:工程师用AI写代码,速度变快,需求交付自然变快。
但如果你把人和AI的产出都换算成token速率来衡量,会得到一个很不一样的图景:
- AI的写入速率,大约是人的10倍以上
- AI的读取速率,更是人的1000倍以上
Claude Code、OpenClaw、Manus这类工具,本质上做了一件很简单的事:把权限和”手”(鼠标键盘的控制权)交给了AI,省掉了用户把AI输出复制粘贴的中间步骤。
但是,审阅没有省掉。
当AI的输出速率是人的10倍时,人的审阅带宽就成了整个工作流里最窄的地方。你不是在等AI写代码,你是在等自己看完AI写的代码。
这就是端到端效率只提升2到3倍的真正原因:AI的生产效率提升了10倍,但人的审阅效率没有变。
问题不在AI,问题在于我们还在用旧的审阅方式,对接新的生产速率。
二、审阅压力有没有解法?有,但边界很清晰
坦白讲,人的审阅带宽是硬约束,没有根本解法。
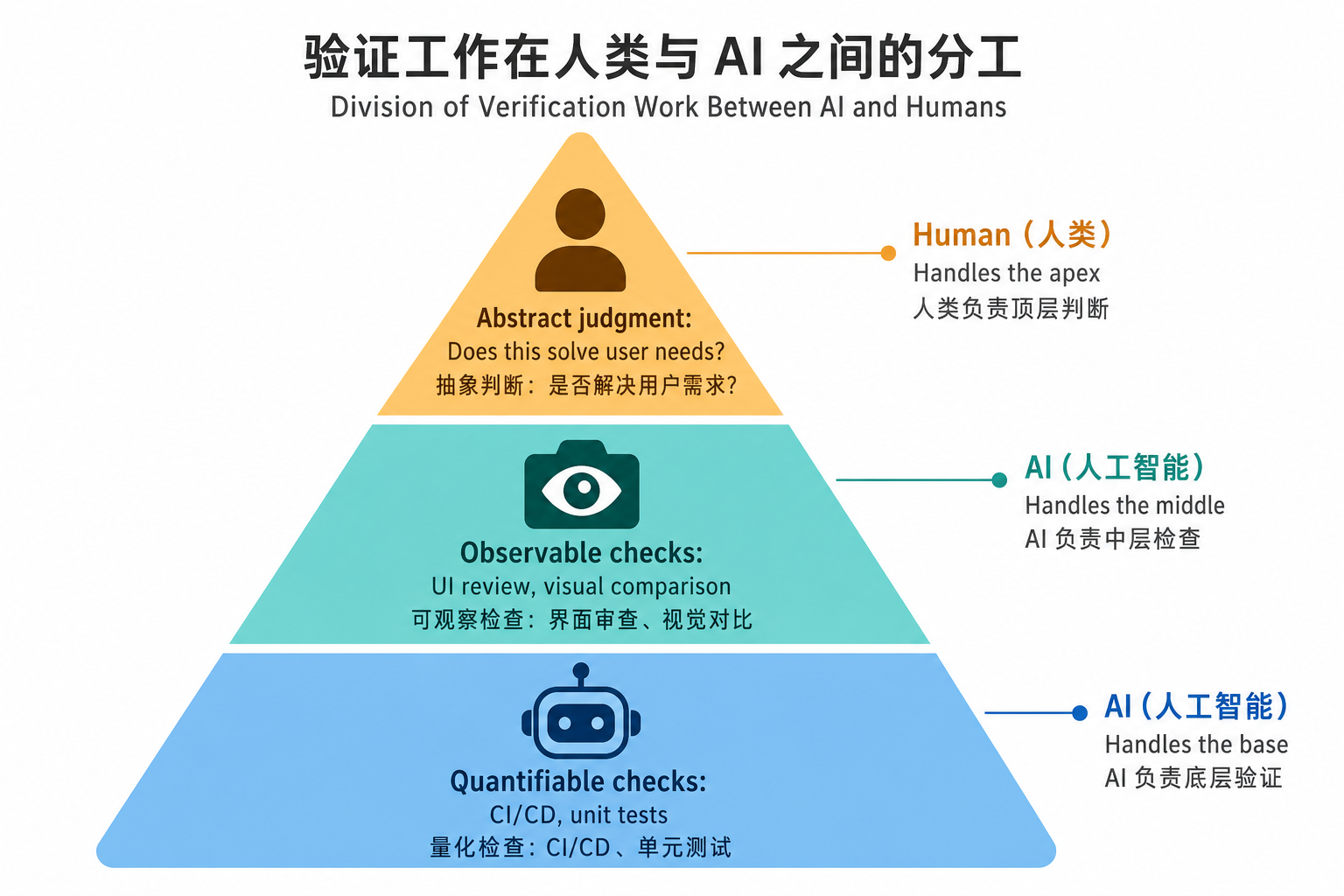
但有一个可行的分层策略:把”能量化的验证”外包给AI,把人的精力留给真正抽象的判断。
第一层,可量化的验证——代码报错、单元测试、CI/CD流水线,这些都可以交给验证Agent自动处理。不涉及主观判断的,让机器来卡。
第二层,可观测的验证——UI走查、页面对比、功能是否如期渲染,这类视觉验证可以用视觉MCP或Agent来完成。不需要人眼逐一确认。
卸载这两层之后,人负责的剩下什么?
“这个产品有没有真的解决用户需求。”
这件事,到今天为止,没有任何自动化方案。你没法给AI一个标准让它判断”用户会不会喜欢这个”——这个判断背后需要对用户的共情、对场景的理解、对市场的直觉,这些都是AI替代不了的。
所以AI替代的是执行,不是产品判断。这是PM在AI时代真实的价值所在——但前提是你把前两层验证真的外包出去,而不是还在用人眼逐行审查AI生成的代码。
三、信息瓶颈已经向前移了,但大多数团队还不知道
许晓斌在《AI Native时代——研发组织何去何从》里提出过一个判断:AI进来之后最大的新瓶颈,不是AI能力不足,而是”系统的信息形态”——大量需求、文档、约定是非结构化的,AI无法消化,人反而变成了在各个系统之间手动搬运数据的”人肉中间件”。
这个判断在两年前是对的。
但现在有一个变化值得注意:随着主流AI的上下文窗口扩展到1M token,这个瓶颈已经开始向前移了。
只要给AI足够的信息和权限,它完全可以自己检索、自己理解、自己整合——根本不需要用户把问题翻译成AI能理解的形式。
但在很多团队里,AI还是用不上这个能力。原因不是AI不够聪明,是系统没有对AI开放接口:数据库没有权限、运维系统没有API、遗留系统无法对接。
于是出现了一个荒诞的场景:员工从业务系统手动导出数据,复制粘贴给AI处理,再把AI的输出搬回系统——人在扮演系统和AI之间的中间件。
今天真正的瓶颈,不是”怎么写更好的prompt”,而是“怎么让AI直接访问你的系统”。这是一个系统接口化的问题,是架构问题,也是数据安全政策的问题。
这件事,是PM能推动的,也应该推动的。花时间优化prompt,不如花时间推动IT和安全团队给AI开一个正式的数据访问通道。后者的复利,远远大于前者。
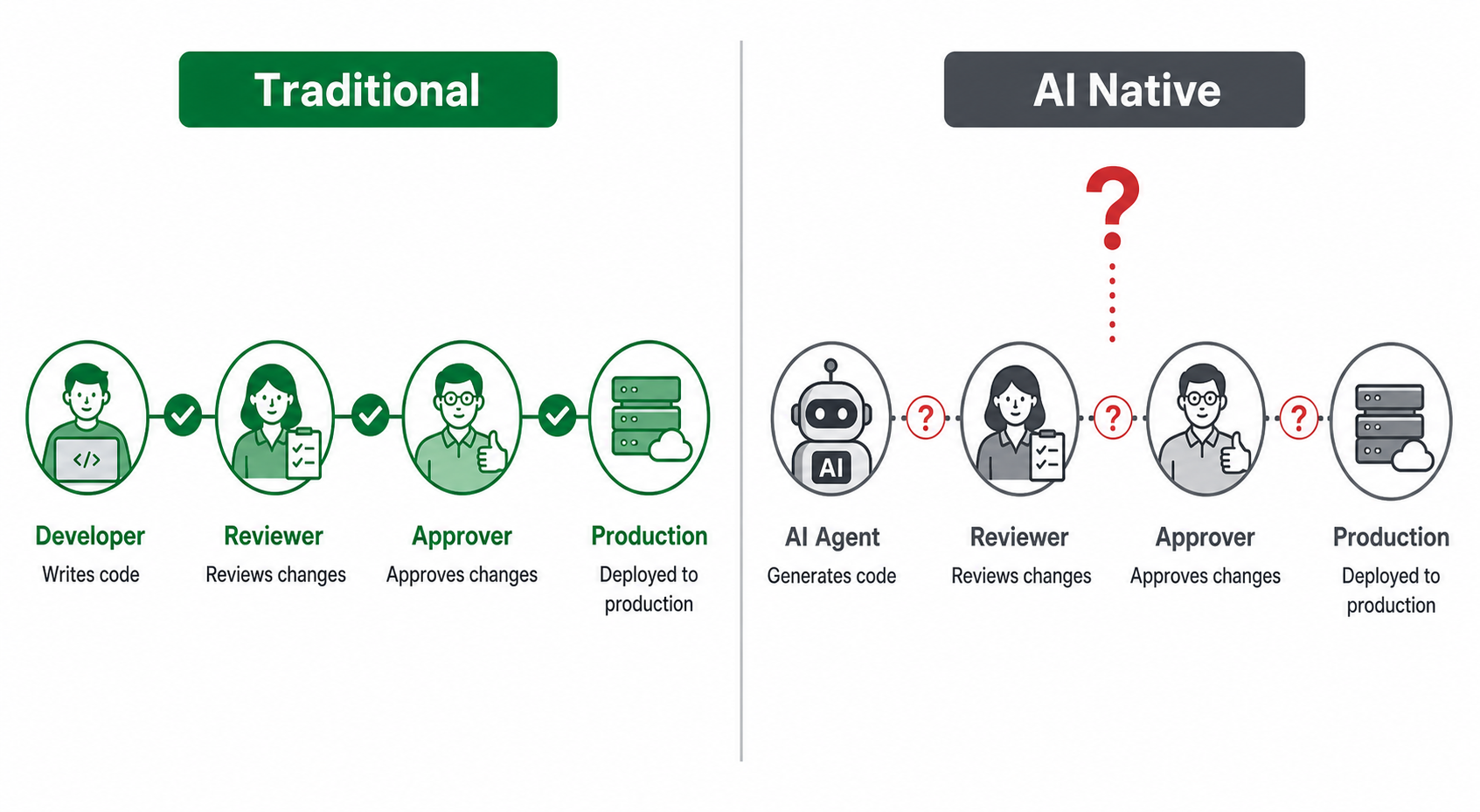
四、最大的盲区:AI写的代码,出了问题谁来负责?
这是产品经理圈讨论AI提效时,被说得最少、但可能最值得认真对待的一个问题。
现实已经走到了这里:Claude Code的大量更新,相当比例是由AI写出来的,人只做review,甚至是AI review AI。AI写代码的能力,今天已经超过了市场上大多数的初级和中级开发者。
然后呢?
然后没有人知道出了问题该找谁。
在传统研发体系里,代码归属是清晰的:谁写的、谁review的、谁approve的,出了线上问题,责任链条清清楚楚。这条链条不只是为了追责,更是为了让整个团队有动力去认真对待自己的输出质量。
当AI成为主要的代码生产者,这条链条断了。
没有人真正”拥有”这段代码——AI没有责任感,review它的工程师也没有和亲手写代码等价的ownership感。Commit记录里写的是谁的名字,但判断和产出是AI的。
这不是技术问题,是组织治理问题。而目前几乎没有公司有完整的应对方案。
这个问题会在哪里爆发?可能是一次线上故障,可能是一次安全漏洞,可能是一个悄悄上线的功能没人发现有问题。到那个时候,才会有人认真开始思考:谁来对AI的输出负责。
产品经理可以提前想这件事,而且是最有资格推动这件事的角色:
- 谁来定义”AI参与度超过多少比例时,验收标准需要调整”?
- 谁来推动建立AI代码的参与度记录和可溯源性机制?
- 当AI写的代码出了用户投诉,PM应该怎么复盘?
这些问题没有现成答案,但提前想清楚的团队,会比被动等待爆发的团队,多出一个完整迭代周期的应对空间。
想清楚限速的地方,比换更好的工具更重要
回到那个数字:纯编码效率10倍,端到端效率2到3倍。
差距不来自AI不够强。差距来自:我们还没想清楚限速的地方在哪里。
用token速率的视角重新看自己的工作,你会发现:
- AI不需要你帮它翻译需求,它需要的是系统接口
- AI不需要你教它写代码,它需要的是量化的验证体系
- AI写出的代码不需要你逐行审查,它需要的是清晰的责任归属机制
这三件事,恰好都是产品经理能推动、也应该推动的。
AI时代PM的护城河,不在”会用多少工具”,在于能看清楚系统性的瓶颈在哪里,然后推动解决它。
执行效率的10倍,是AI的礼物。端到端效率的剩余差距,是留给看清楚瓶颈的人去填的空间。
本文观点来自对AI工具的日常使用实践,以及许晓斌《AI Native时代——研发组织何去何从》的深度启发。
本文由 @被抢了名字的Kimi 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


