
 起点课堂会员权益
起点课堂会员权益数字员工为什么会遗忘:AI记忆的底层缺陷与系统性补偿(上篇)
当你的AI助手开始频繁遗忘关键信息,该如何重构它的记忆系统?本文基于扣子平台(Coze)的实战经验,深度拆解数字员工在知识遗忘与规则遗忘中的表现差异,并提出创新的多层路由+标签索引方案。从5个自动加载MD文件的巧妙利用,到规则与知识的精准分层管理,这套系统正在重新定义AI Agent的可靠性边界。
本文基于笔者与数字员工(AI Agent)日常协作中的真实实践,非理论推演。文中方案针对扣子平台(Coze)的Agent特性设计,不同平台需因地制宜。本篇为”数字员工记忆系统优化”系列上篇,聚焦问题拆解与方案设计;下篇将聚焦落地执行与效果反馈。
(本文由飞哥与仓颉共同完成,仓颉也是数字员工,是飞哥的文章助理,负责理论支撑和结构化成文。)
一、问题起点:当你的AI员工开始遗忘
我有一个数字员工叫贾维斯,负责日常工作执行。用了几个月之后,我发现一个越来越频繁的问题:他开始遗忘。
深层原因不复杂:上下文窗口有限 + 记忆压缩机制。当对话积累到一定程度,系统会自动压缩旧记忆,压缩是有损的,细节会丢失。这是所有AI Agent的先天约束。
但我发现了一个更本质的问题:AI的遗忘和人类不同。
人类忘了某件事,会有”好像做过但记不清”的模糊印象,这个模糊印象会触发我们去翻历史记录。AI的记忆是”有”或”没有”两个状态,没有中间地带。MEMORY.md里没有记录 = 这件事不存在。
这不是”偷懒没查”,而是”真的不知道要查什么”。
AI记忆的脆弱性不在于”记不住”,而在于”不知道自己不知道”。 人类会说”我不记得了,但我可以去找”;AI说”我不记得了”之后,如果没有明确的路由指引,连”去找”这个动作都不会做。
具体到实际场景中,这种遗忘表现为两种类型:
场景一:知识遗忘——忘了之前做过什么
我向贾维斯提出”UU助手高保真原型图”的需求,他立即开始制作新版本。问题在于:UU助手的高保真原型,我们已经做过v1.0、v2.0、v3.0三个版本,其中v3.0在4月14日已测试通过。但贾维斯完全忘了这些版本的存在,用PPT图片格式重做了一遍。
场景二:规则遗忘——忘了该怎么做事
同一个任务中,贾维斯制作了11页”高保真原型图”。打开一看:每张图都是在海报背景上嵌套一个手机框,文字全是乱码。问题不在”做错了图”,而在他根本没按流程走。之前我给贾维斯制定过海报制作的流程规范——先出排版草图,确认布局后再动手,文字部分用代码排版而非AI生图。但贾维斯完全忘了这套流程,直接用AI生图的方式硬做,结果每张图都嵌了不必要的手机框,文字也因AI生图无法精确控制而全部乱码。
这不是”能力不够”,是”流程忘了”。
二、遗忘的两种类型:规则遗忘与知识遗忘
经过反复实践,我总结出数字员工遗忘的两种类型:
规则遗忘:忘了做事的规矩和流程。比如”海报一律用代码排版,不用AI生图做文字部分”这条方法论,如果被遗忘,执行时就会继续用AI生图做海报,重复出现乱码问题。
知识遗忘:忘了之前达成的结论或已有的产出。比如”UU助手原型图已经做到v3.0″这个事实,如果被遗忘,就会重复制作,造成资源浪费。
这两种遗忘的后果不同:
- 规则遗忘 → 执行出错(方法用错,流程混乱)
- 知识遗忘 → 重复劳动或决策错误(不知道之前做过什么)
确定性条件:只有规则不遗忘 + 知识不遗忘,任务执行才有确定性。
这里引出一个核心区分:规则与知识的本质区别是什么?
- 规则:对内,约束数字员工的行为——通过流程、方法论、操作红线来规范AI员工”应该怎么做”
- 知识:对外,展示给使用者的内容——项目进展、客户信息、历史结论等,是人需要看到和确认的
举例:做海报时,”先确定文案,再确定背景,最后排版”——这是流程,是规则,约束数字员工的行为顺序。而”对外宣传的slogan是’农夫山泉有点甜'”——这是确定的结论,是知识,是给人看的内容。
同一个内容,如果因为表述不同而同时属于规则和知识,就分成两个版本,分别放在规则目录和知识目录下。这样数字员工在使用时,不用纠结哪些是给用户看的、哪些是约束自己行为的——规则目录里只有”我该怎么做”,知识目录里只有”确定的结论是什么”。
三、早期思路:影子规则官与记忆保管箱
面对遗忘问题,最直觉的思路是:把记忆从主Agent身上剥离,外部化存储。
我设想过两个方案:
影子规则官:创建一个独立Agent专职记忆规则,主Agent执行前先问规则官。这相当于给数字员工配一个”私人秘书”,专门负责提醒。
记忆保管箱:用知识库 + 向量检索,把知识外部化存储,按需调用。这相当于给数字员工配一个”外部硬盘”。
这两个方案的底层逻辑一致:记忆不应该依赖Agent的上下文,而应该有一套确定性的、可追溯、可查找的机制来确保记忆的可靠性。
但我没有直接采用这套方案。原因是:不同平台能力不同,不能一刀切。扣子平台有自身的文件系统限制,需要先摸清平台特性,再制定针对性方案。
四、平台特征发现:从概念方案到可执行方案的关键转折
在制定方案之前,我让贾维斯做了一次自检反馈,目的是摸清扣子平台的能力边界。
关键发现一:扣子平台5个MD文件自动加载
扣子平台的Agent配置中,有5个MD文件会在每次对话开始时自动加载:SOUL、TOOLS、USER、SECRET、MEMORY。这意味着这5个文件是天然的路由入口——所有需要”每次都记得”的内容,都应该写入这些文件。
关键发现二:扣子自带文件系统,已具备知识库基本功能
平台提供了文件存储能力,可以按目录结构组织内容。不需要额外搭建外部知识库,直接利用平台能力即可。
关键发现三:Agent本身有查询和总结能力,可参与方案设计
贾维斯能理解任务指令,能总结执行结果,说明Agent不只是执行者,也可以成为方案设计的参与者。
基于这三个发现,我的决策是:
- 影子规则官 → 用路由文件替代(把规则官的功能分散到目录结构中)
- 记忆保管箱 → 用平台文件系统 + 标签索引替代(把外部知识库的功能内化为标签检索)
从概念方案到可执行方案,关键是:先理解平台能做什么,再设计方案适配平台,而不是让平台适配你的方案。
五、最终方案:多层路由 + 标签索引
基于扣子平台特性,我设计的指导方针是:多层路由 + 标签索引。
架构设计
一级路由:5个自动加载MD文件
- SOUL.md:身份定位 + 全局硬性规则 + 工作规则(自动加载,红线永远在)
- TOOLS.md:工具经验 + 规则路由表 + 知识路由表(指向具体规则文件和知识文件的路径)
- USER.md:用户个人信息 + 偏好 + 团队成员 + 执行授权规则
- SECRET.md:保密信息
- MEMORY.md:任务进程追踪 + 项目进展 + 待跟进事项
核心设计:底层规则放在SOUL.md,自动加载不用路由找;规则路由和知识路由放在TOOLS.md,数字员工执行任务时先读TOOLS.md就知道该去哪查规则、去哪查知识。SOUL.md解决”红线永远在”,TOOLS.md解决”去哪找东西”。
二级路由:项目
一级路由文件指向具体的项目目录。每个项目对应一个独立的目录,路由告诉数字员工”这个任务属于哪个项目”。
三级路由:事类
项目目录下按事类细分。比如”UU助手”项目下分为”视觉设计””客户跟进”等事类,路由进一步缩小查找范围。
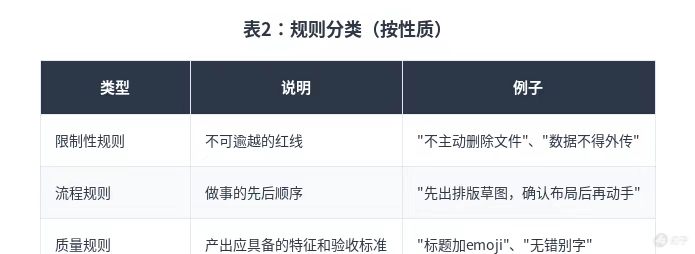
类型:仅规则有
事类目录下,规则文件再按类型细分——限制性规则、流程规则、质量规则。知识文件到事类这一级就结束了,不再按类型分,因为知识只需按相关性查找,不需要每个类型都过一遍。
一级(自动加载MD)→ 二级(项目)→ 三级(事类)→ 类型(仅规则)
标签索引:文件目录
路由能指路,但到了具体目录下,不可能把所有文件通读一遍——那是浪费。标签的作用就是解决”找哪个文件”的问题。
每个规则文件和知识文件都有一个标签,标签格式:名称 + 极简描述
标签 | 极简描述
UU助手原型规范 | UU助手视觉产出标准
UU助手客户跟进规则 | 先到先得、跟进频率
标签只放20字以内的描述,一眼知内容。数字员工先读标签,快速判断需要加载哪些文件,再按路由路径去读。
路由和标签配合:路由指路,标签定文件。两者共同构成一个完整的目录体系——路由告诉你去哪个目录找,标签告诉你该读目录里的哪个文件。
执行流程
数字员工收到任务后,按以下5步执行:
① 自动加载5个MD文件
每次对话开始时,SOUL、TOOLS、USER、SECRET、MEMORY自动加载到上下文。红线规则和工作规则已在SOUL中,路由指引已在TOOLS中。
② 识别任务 → 查TOOLS路由表 → 加载规则
根据任务类型,在TOOLS.md的路由表中找到对应的规则目录,按”限制性 → 流程 → 质量”的顺序加载规则文件。限制性规则是底线,流程规则是步骤,质量规则是验收标准。
③ 按需加载知识
规则加载完毕后,根据任务需要从知识目录中选择性加载相关知识文件。知识不需要全读,只加载与当前任务相关的。
④ 执行
按规则执行任务:限制性底线不可逾越,流程按步骤走,质量标准做验收。
⑤ 更新记忆
执行完毕后,将任务结果、新达成的结论、待跟进事项更新到MEMORY.md。
四个核心原则
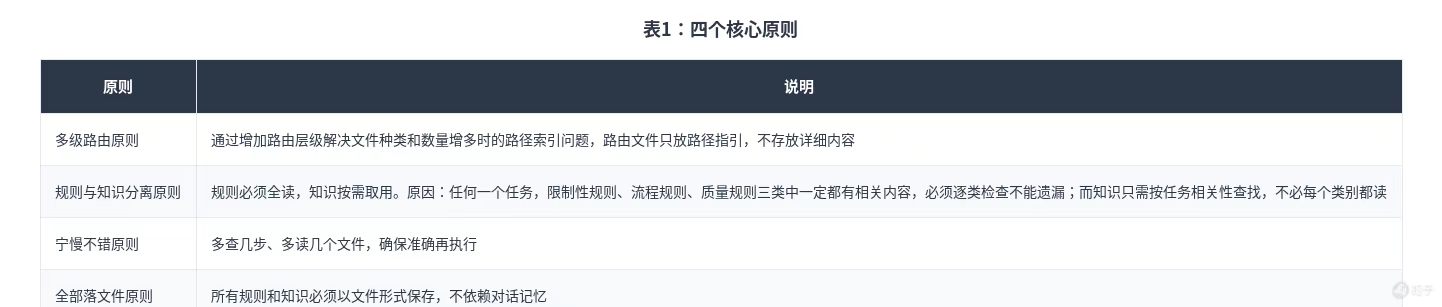
全部落文件是所有设计的前提。 如果规则不落文件,路由表再精确也没用。
六、规则体系:分类与分层
规则分类(按性质)
规则分层(按适用范围)
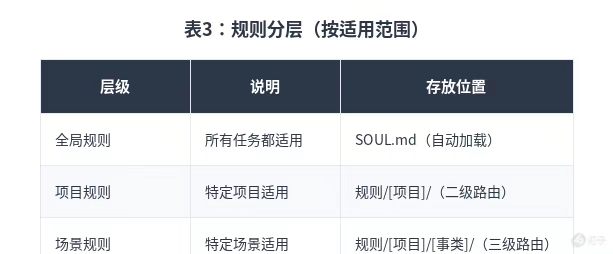
设计要点:全局硬性规则写入SOUL.md,不用单独建目录。项目规则和场景规则按路由层级组织,目录结构即为路由结构。
知识分类
知识分类只到二级:项目 + 事类。
第三级不预设,按需自然生长。
为什么知识不预设第三级?预设分类反而增加认知负担——AI会觉得”我是不是每个分类都得看一眼”,不必要的读取造成效率损耗。
规则与知识的关键区别
规则加载:必须全读(限制性 → 流程 → 质量,逐类检查,不能遗漏)
知识加载:按需取用(根据任务需要选择性加载)
这是效率与准确性的平衡:规则影响行为方式,必须全读;知识只是参考,可以按需调用。
七、自检机制:从被动纠错到主动发现
规则体系刚执行时,一定有覆盖不到位的地方。我们不能等结果出来了,通过自检去处理——如果到时候才发现问题再重复执行,本质上是资源浪费。
磨合期(前2周)每天查1次,稳定后降到每周1次。
四个检查维度
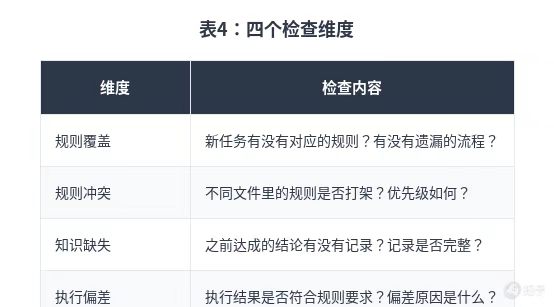
双线评估
- 数字员工自检:AI按标准化报告格式输出自查结果
- 人类体感判断:我作为使用者,感受任务执行是否符合预期
自检机制的核心价值:把”被动等出错”变成”主动找问题”。
八、写在最后:AI记忆问题不是技术问题,是设计问题
这轮实践让我意识到一件事:数字员工的”记忆问题”不只是技术问题,更是设计问题。
技术层面,我们可以用更大的上下文窗口、更智能的记忆压缩算法。但这些解决的是”能存多少”,解决不了”怎么找到”。
把”记得去查”变成默认行为,才是关键。
这需要两件事:
- 承认记忆的脆弱性。不要假设AI”应该记得”,而是假设AI”随时会忘”。所有重要信息都必须落文件,所有文件都必须有明确入口。
- 设计不依赖记忆的执行流程。多级路由解决的是”入口问题”,标签索引解决的是”精确指向问题”,自检机制解决的是”主动发现问题”。三者配合,才能让记忆系统真正运转。
落地路径两步走:先自检了解平台特性,再针对性制定方案。
不同平台的约束不同(文件数量限制、加载机制、检索能力),照搬方案往往失败。在理解平台的基础上设计方案,才能真正可执行。
下篇预告:这套方案在贾维斯身上落地后的实际效果——好的怎么迭代,差的原因在哪。以及一个关键问题:当规则数量增加时,加载成本如何控制?
敬请期待。
本文由 @孔明灯-校园市场 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


