
 起点课堂会员权益
起点课堂会员权益视频创作这件事, 可能今年内就会被大模型折叠掉
AI从文字助手进化到能直接修改视频的创作执行者,Google最新发布的Gemini Omni正重塑人机交互的边界。本文将深度解析多模态AI如何打破创作门槛,让普通人也能轻松实现复杂视频编辑,并探讨这一技术突破对内容创作生态带来的深远影响。
AI不只是会说话了,它开始动手了
过去几年,我们对AI的期待,基本都停留在“让它帮我说点什么”。
写文章、写脚本、写邮件、改文案、做总结。
这些能力当然有用,但它们本质上都发生在文字世界里。
你输入一段话,AI输出一段话。
最多再进一步,它能看图、能听音频、能理解一段视频,然后给你一个文字回答。
但现在,事情开始变得不一样了。
在 Google I/O 2026 上,Google 推出了 Gemini Omni。
它最值得关注的地方,不是“又来了一个视频生成模型”,而是它把AI的能力从“理解内容”往前推了一步:
AI不只是看懂视频,它开始能直接改视频了。
这件事听起来像是一个功能更新,但背后其实是一次很重要的人机交互变化。
以前,我们要完成一个视频创意,必须学会剪辑软件。
现在,越来越多任务可能只需要一句自然语言指令。
你说:“把背景换成城市夜景。”
你说:“让这段视频更有电影感。”
你说:“把情绪从压抑改成温暖一点。”
AI不再只是回答你“可以怎么做”,而是开始真的替你做。
01 Omni的关键,不是“全能”,而是“打通”
Omni这个词,本身有“全部、全方位”的意思。但如果只把它理解成“什么都能做”,反而容易把重点看偏。
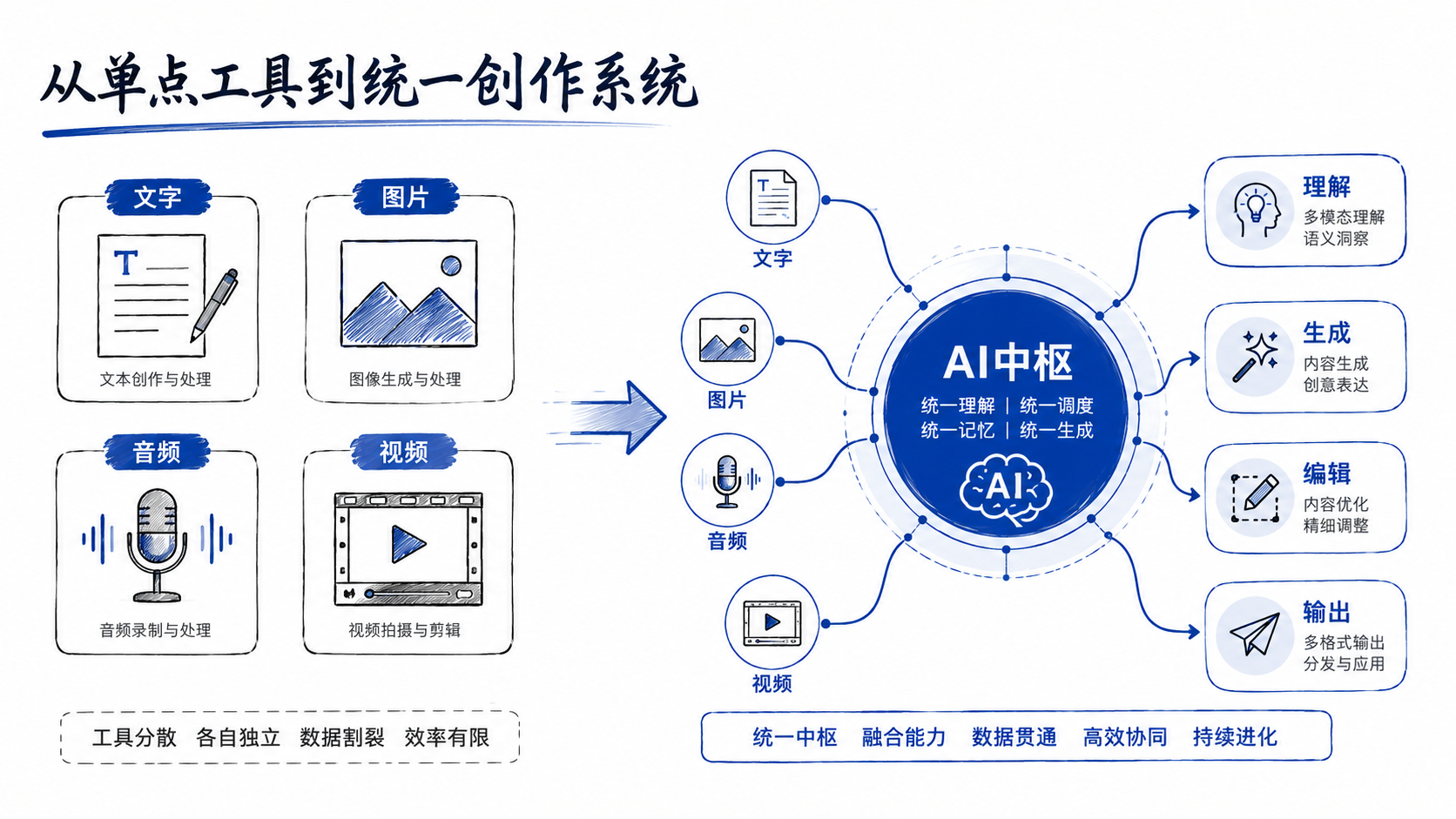
Gemini Omni真正值得关注的地方,在于它试图把文字、图片、音频、视频这些原本分散的能力,放进同一个理解和生成框架里。
过去的AI系统,更像是一组分开的工具箱:
- 文字模型负责写文案;
- 图像模型负责生成图片;
- 语音模型负责听声音;
- 视频模型负责生成短片。
每个工具都能用,但它们之间并不总是能顺畅协作。
比如你给AI一段视频,再告诉它:
“保留人物动作,但把背景换成下雨天的街道,音乐也变得安静一点。”
这不是一个简单的文本任务。
它同时涉及画面理解、人物识别、背景替换、声音风格、情绪判断,还要保证修改后的结果看起来是连贯的。
传统工具通常要拆成好几步:
先抠像,再换背景,再调色,再配乐,再重新导出。
而 Gemini Omni 想解决的,就是把这些步骤尽量压缩成一次对话。
换句话说,它不是单纯在“新增功能”,而是在尝试打通创作流程。
这才是Omni最重要的信号:
AI正在从单点能力,走向跨模态协作能力。
02 多模态AI的难点,不是“识别”,而是“理解后还能操作”
很多人听到多模态,会觉得这只是AI能看图、能听音频、能识别视频。
但这只是第一层。
真正难的是:
AI能不能把不同信息放在一起理解,并且根据理解去修改它。
举个简单例子。
一段咖啡馆视频里,有两个人在聊天,背景音乐很轻,画面偏暖,整体氛围很放松。
如果你问AI:“这是什么场景?”
它回答:“这是咖啡馆里两个人交谈的画面。”
这叫识别。
但如果你说:“把这段视频的情绪改得更紧张一点。”
这就不是识别问题了。
因为“紧张”不是一个具体按钮。
它可能意味着镜头节奏更快、音乐更低沉、光线更暗、人物表情更严肃,甚至画面构图也要发生变化。
这时候,AI必须先理解“紧张”这个抽象词,和画面、声音、节奏之间有什么关系。
然后,它还要把这种理解转化成具体的视频修改动作。
这就是多模态AI真正困难、也真正有价值的地方。
过去,AI更多停留在“看到了什么”。
现在,新的方向是:
看懂之后,能不能直接动手改。
这一步跨过去,AI就不再只是一个内容分析工具,而是开始接近创作执行工具。
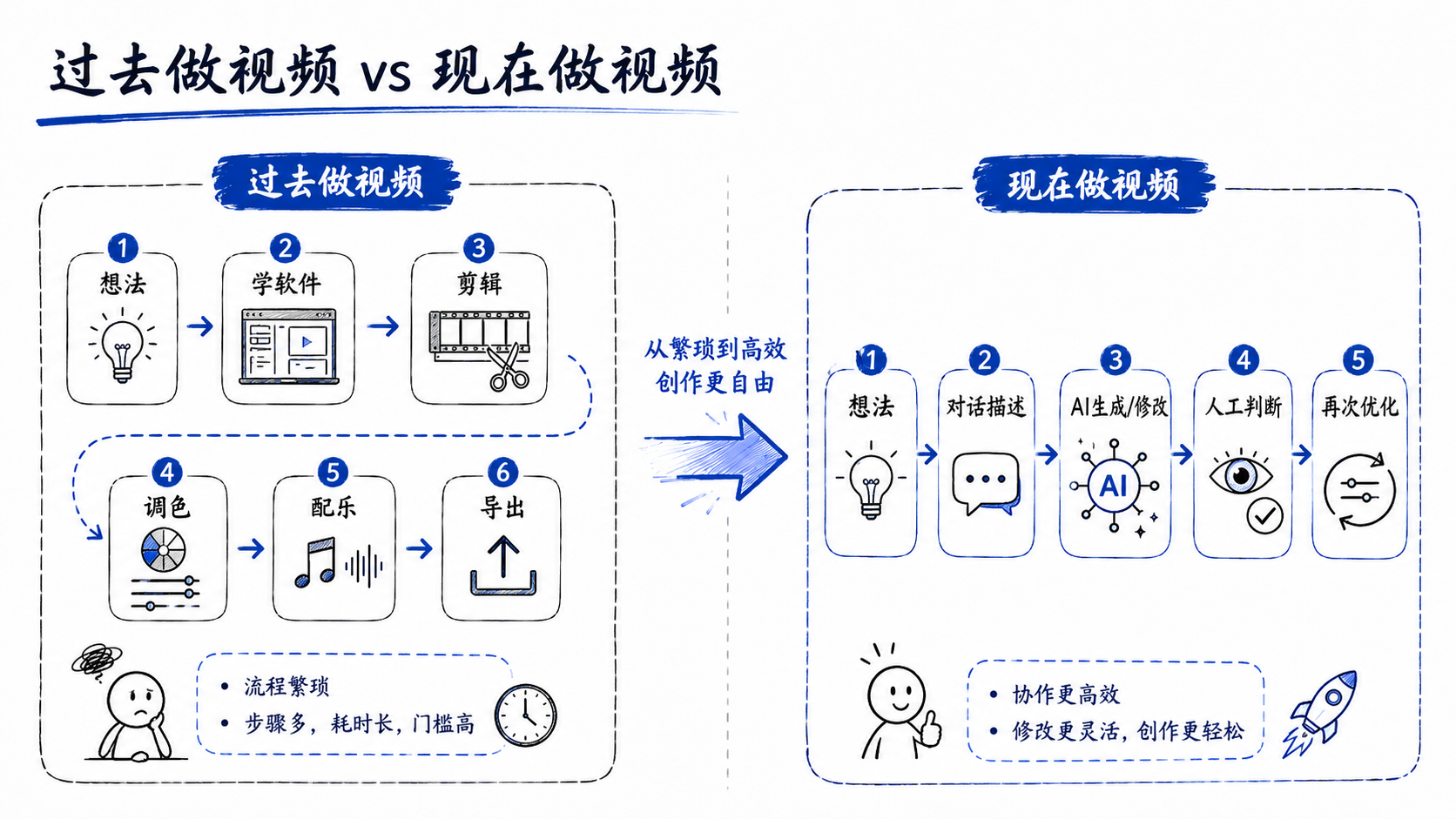
03 视频创作的门槛,正在被重新定义
视频是最能体现多模态能力的场景。
因为一条视频里,不只有画面。
它还有声音、人物、动作、环境、字幕、节奏、镜头、情绪。
这也是为什么传统视频剪辑的学习门槛一直很高。
- 你想改一个背景,可能要懂抠像。
- 你想让画面更有电影感,可能要懂调色。
- 你想让节奏更紧凑,可能要懂时间轴和剪辑点。
- 你想让音乐配合情绪,还要懂音频和节奏。
一个普通人有创意,并不代表他能把创意做出来。
这就是过去内容创作里很现实的一道门槛:
想法属于人,但执行能力属于工具熟练者。
Gemini Omni这类模型的意义,就在于它开始把一部分执行能力交还给普通人。
你不需要先学习一整套软件操作逻辑,才能表达你的想法。
你只需要说清楚你要什么,AI就尝试把它转化成可见的结果。
这件事的本质,不是“AI替代剪辑师”。
更准确地说,是创作链路被重新分层了。
专业创作者依然会有优势,因为他们知道什么是好镜头、好节奏、好叙事。
但普通人也第一次有机会绕过复杂工具,直接进入创意表达本身。
这会带来一个很明显的变化:
未来内容创作的竞争,可能不再只是谁更会操作软件,而是谁更会表达意图、设计创意、判断结果。
04 这不是工具界面升级,而是交互方式变化
有人可能会说:
“这不就是把剪辑软件的按钮,换成聊天框了吗?”
表面看,确实有点像。
但真正的变化不在界面,而在谁去适应谁。
传统软件的逻辑是:
工具已经设计好了,你要学习它的菜单、按钮、参数、快捷键,然后把自己的想法翻译成机器能执行的操作。
所以很多人不是没有创意,而是卡在了工具门口。
自然语言交互的逻辑刚好反过来:
你先用人的语言表达想法,工具再把你的想法拆成可以执行的动作。
这就是从“人适应机器”,转向“机器理解人”。
当然,这并不意味着一句话就能生成完美作品。
AI仍然会误解,也会生成不稳定的结果。
你仍然需要判断、筛选、修改、迭代。
但门槛确实变了。
以前你必须先学工具,才能开始创作。
现在你可以先开始创作,再在过程中逐步学习如何把需求说清楚。
这个变化很重要。
因为一旦创作门槛下降,就会有更多原本不参与创作的人进入内容生产。
老师可以更容易做课程视频。
小商家可以更快做产品展示。
自媒体作者可以把文字内容变成短视频。
普通人也可以把脑子里的画面表达出来。
AI的价值,不只是替专业人士提效。
它也可能让更多非专业人士拥有表达能力。
05 Google的布局:不是发一个模型,而是把它放进使用场景
一个AI模型能不能真正改变工作流,关键不只看模型本身,还要看它被放在哪里。
这次Google比较值得注意的一点是,Gemini Omni并不是只作为一个实验室Demo出现。
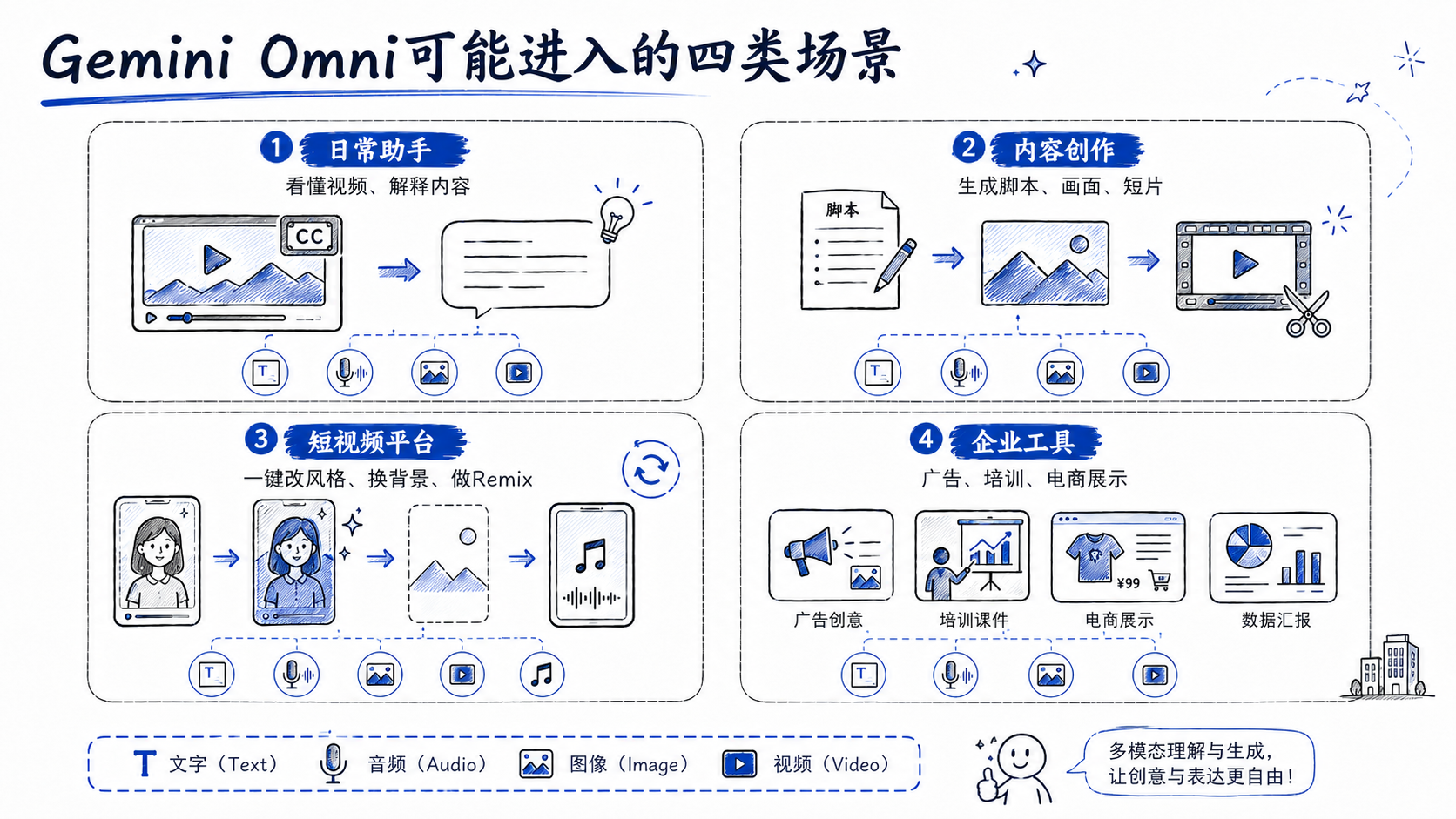
从官方信息看,Gemini Omni Flash已经进入 Gemini App、Google Flow、YouTube Shorts Remix 和 YouTube Create 等场景。
这几个入口对应的用户并不一样。
- Gemini App更偏日常助手。
- Google Flow更偏创作者工作流。
- YouTube Shorts更偏大众短视频创作。
- YouTube Create则更接近移动端轻量创作工具。
这说明Google不是只想展示技术,而是想把多模态生成和编辑能力,直接塞进用户已经在使用的产品里。
这一步很关键。
因为大多数普通用户不会专门去研究一个模型。
他们只会在某个具体任务里感受到:
- 这个功能能不能帮我省时间?
- 能不能让我做出以前做不出来的东西?
如果答案是肯定的,技术才算真正进入生活。
另外,Google也提到,相关能力会继续通过API开放给开发者和企业客户。
这意味着,Omni未来不一定只存在于Google自己的产品里,也可能被集成进教育、电商、营销、企业培训等更多行业工具中。
当然,这些场景真正跑通,还需要时间。
但方向已经很清楚:
多模态AI正在从“看起来很厉害的展示”,进入“可以嵌入工作流的能力”。
06 从工具到智能体,AI正在补上“动手能力”
过去我们说AI像助手,其实更多是在说“文字助手”。
它能帮你想标题,帮你写大纲,帮你总结资料,帮你润色表达。
但它很少直接进入真实生产环节。
- 你要做图,还是要打开设计工具。
- 你要剪视频,还是要打开剪辑软件。
- 你要做广告,还是要找素材、写脚本、剪片子、调细节。
AI主要负责“出主意”,真正执行还得靠人。
现在的变化是,AI开始向执行层靠近。
- 它不只是告诉你该怎么改,而是直接参与修改。
- 它不只是帮你描述画面,而是尝试生成画面。
- 它不只是分析视频结构,而是开始编辑视频结构。
这就是AI从工具走向智能体的一个关键变化。
工具是被动的。
你必须知道每一步怎么操作,它才会执行。
智能体更接近合作伙伴。
你告诉它目标,它会理解任务、拆解步骤、调用能力,然后给你一个结果。
Gemini Omni代表的,不只是视频生成能力升级。
它代表的是AI开始补上“动手做事”的能力。
当AI既能理解你的意图,又能直接操作内容,很多工作流就会被重写。
07 但越是强大的创作工具,越需要人的判断
讲到这里,很容易走向一种过度乐观的结论:
以后是不是只要一句话,就能做出所有内容?
还没到那一步。
至少现在看,AI视频生成和编辑依然有不少限制。
- 它可能理解错你的意图。
- 它可能在细节上不稳定。
- 它可能生成看似高级、但缺少真实表达的画面。
- 它也可能让大量相似风格的内容涌入平台。
所以,越是强大的工具,越需要人的判断。
未来真正有竞争力的创作者,不一定是最会操作软件的人,但一定是更会判断结果的人。
- 你要知道什么样的画面是好的。
- 你要知道什么样的节奏适合你的内容。
- 你要知道什么样的表达能打动你的观众。
- 你还要知道什么时候该相信AI,什么时候该推翻重来。
AI会降低执行门槛,但不会自动带来好内容。
它能帮你更快抵达一个结果。
但这个结果有没有价值,仍然取决于人。
这也是为什么我更愿意把 Gemini Omni 看成一种“创作放大器”,而不是“创作者替代品”。
它放大的不是空白,而是人的想法、审美、判断和表达能力。
写在最后
技术真正改变世界的时候,往往不是因为它看起来多么炫酷,而是因为它让更多普通人,第一次拥有了原本不属于自己的能力。
过去,创作常常是一件有门槛的事。
- 你有一个想法,不代表你能把它剪成视频;
- 你有一个画面,不代表你能把它做成广告;
- 你有一个故事,不代表你能把它表达给更多人看见。
很多时候,我们缺的不是想法,而是把想法变成作品的能力。
而多模态AI正在改变这一点。
当AI能听懂音频、理解视频、看懂画面,并根据一句自然语言直接完成修改时,它降低的不只是工具门槛,也是在释放更多人的表达欲。
这或许才是Gemini Omni这类模型最值得关注的地方。
本文由 @流窜AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


