
 起点课堂会员权益
起点课堂会员权益Claude Fable 5 上线第一天:贵一倍,但有件事比跑分更值得看
Claude Fable 5的发布不仅是跑分的提升,更标志着Anthropic首次将神话级模型向公众开放。这款模型在编程任务中表现惊人,将原本需要两个月工时的任务压缩到一天完成。其独特的安全分类器机制和长程任务处理能力,正在重新定义AI应用的边界。

6月9日凌晨,Anthropic 把 Claude Fable 5 推上了台面,我其实没什么期待——这是 12 天里第二次模型升级,上一次还是 5 月 28 日的 Claude Opus 4.8。说实话,发布密度太高,我心态已经从”快试试”变成”先看跑分再说”。
但翻完发布会、跑了一晚上手头几个任务的 case,体感不是”哇又一个屠榜的”,是”咦这次玩法不太一样”。
这次值得写的,不是它跑了多少分,而是 Anthropic 把”神话级”(Mythos-class)模型第一次拎出仓库摆上柜台这件事本身。
一、跑分跳了 11 分,但跑分不是它真正想让你看到的
先把数字摆出来。
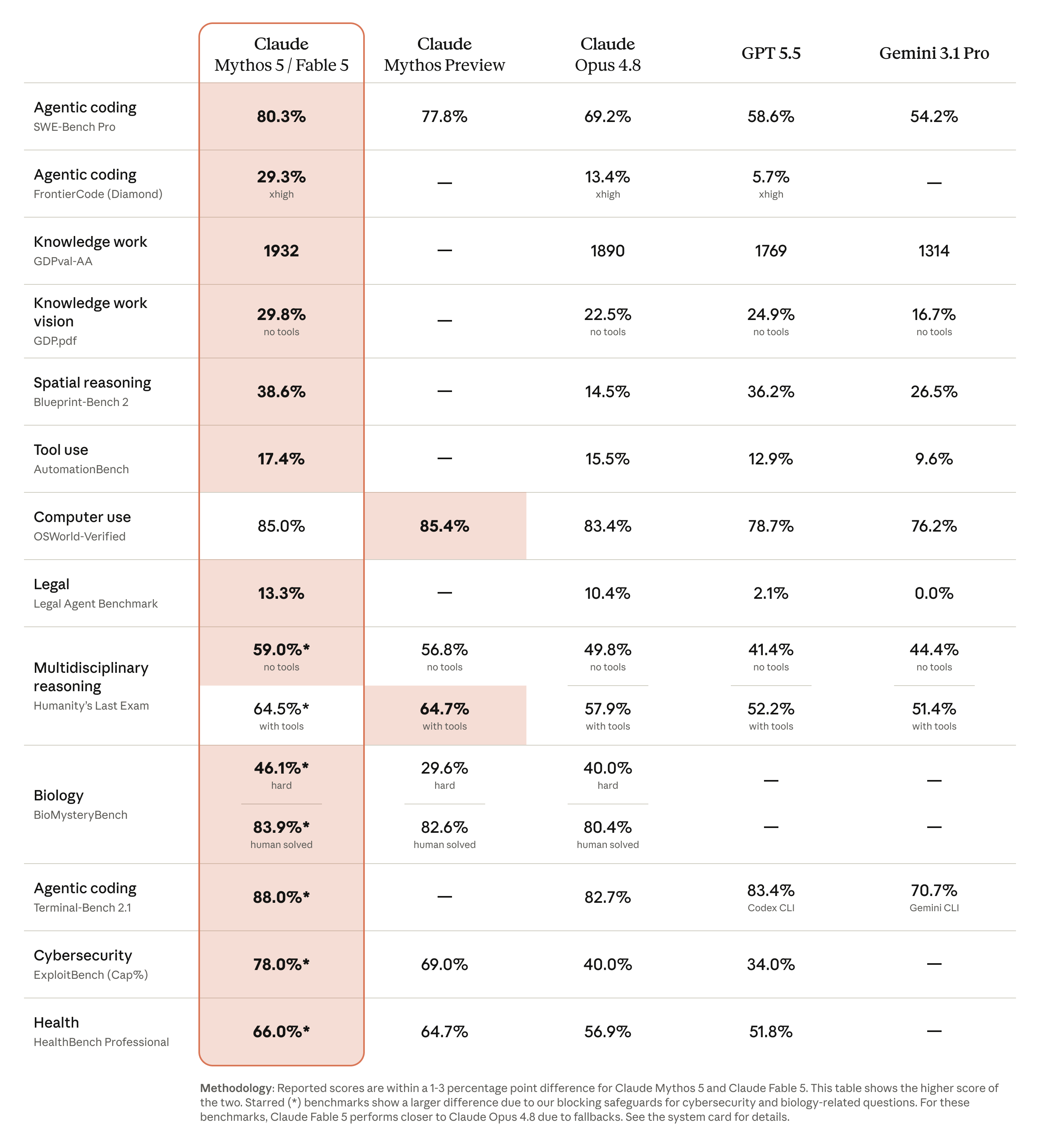
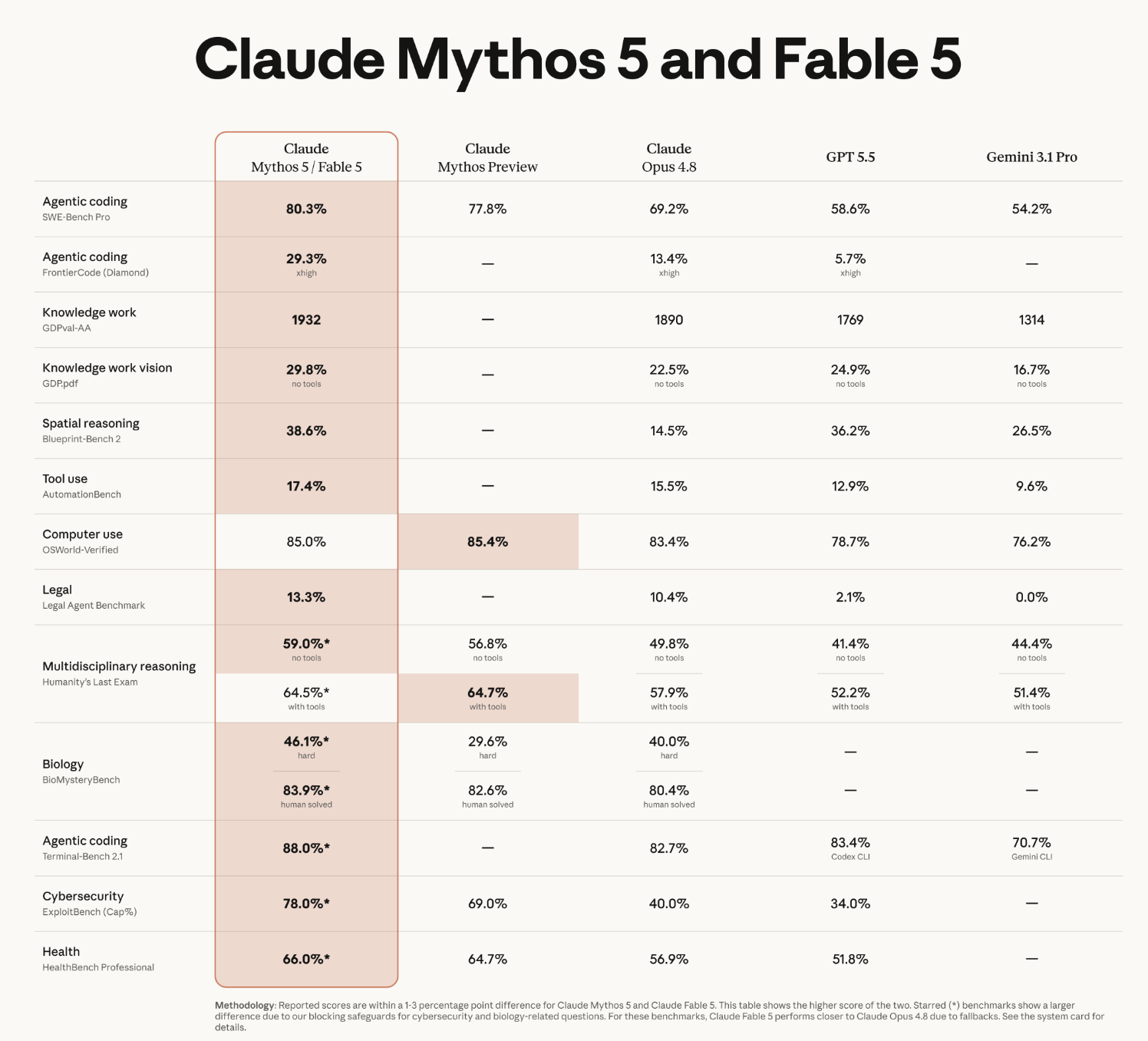
Claude Fable 5 在 SWE-Bench Pro 拿到 80.3 分,Claude Opus 4.8 是 69.2,GPT-5.5 是 58.6,Gemini 3.1 Pro 是 54.2。换句话说,它比 Anthropic 自家上一代领先 11 分,比另外两家领先 20 分以上。同一个模型在 SWE-bench Verified 上是 95.0,在 Cognition 那个叫 FrontierCode 的前沿编程评估里排第一,在 Hebbia 的金融高级推理基准里领先。
这种跑分密度,看多了反而麻木。直到我看到 Stripe 那个 case。
Stripe 在早期测试里把 Fable 5 接进了他们一个 5000 万行的 Ruby 代码库做版本迁移。原本他们排了一个团队、两个月的工期。Fable 5 用了一天。
我盯着这个数字看了很久。一个团队两个月的活,约等于 2 个人 × 22 天 × 8 小时 ≈ 352 个工时,被压成 1 天。这不是”工程师效率提升 30%”那种叙事了,这是”工程师的角色从写代码变成审 patch”的拐点信号。
GitHub 那边 CPO Mario Rodriguez 给的话是”展现了前所未有的自主性和可靠性”。这种官方话术得打三折听,但 Cursor 的 CTO Michael Truell 说的那句更值得划重点:
“它打开了一类我们之前根本碰不到的、长程问题。”
长程(long-horizon)这个词是 Anthropic 这一年最在意的指标——一个 Agent 能不能连续跑几小时甚至几天,不丢上下文、不在中间发疯。Fable 5 的 1M token 上下文加持久文件记忆,在 Slay the Spire 这种需要反复决策的任务上,跑出了 Opus 4.8 的 3 倍表现。
这意味着什么呢?意味着你以前不敢交给 AI 的”打通账期对账 + 写月报 + 发邮件 + 在 Notion 里更新看板”这种连环任务,它现在能完整跑下来。
二、Mythos 级别第一次走出仓库
这才是这次发布真正的事件。
Mythos 是 Anthropic 内部的最高能力等级。在此之前,只有一个 Mythos Preview 版本通过 Project Glasswing 项目,定向给美国政府和少数网络防御机构试用。整个 2026 年上半年,Anthropic 反复在公开场合说”我们手上的模型已经强到不能随便放出去”,公司 5 月底还专门发过一篇”AI 正在变得太危险”的声明。
12 天后,他们就把这一级别的模型对外开放了。
Fable 5 是带安全分类器(classifier)的公开版本;同时发布的 Claude Mythos 5 是同一个底模,但在某些领域去掉了分类器,继续走 Glasswing 通道,计划在 15 个国家约 150 个组织里铺开,重点是网络防御者和后续会加入的生物医学研究员。
这是一次很拧巴的发布。一边官方话术里满是”我们已经接近上限了,要谨慎”,一边商业节奏快得只能用 Token 数说话。
但商业逻辑很简单:OpenAI 今年的市场份额从 90% 跌到 65%,Anthropic 必须把最强的牌打出来。
三、那个”分类器降级”机制,是我这次看 Fable 5 最有意思的设计
发布稿里有个细节很容易被划过去:当用户在 Fable 5 上问到生化、网络攻击、模型蒸馏这三类高风险问题时,Fable 5 本身不是拒答,而是把这次回答悄悄交给 Claude Opus 4.8。
我读到这条的时候,第一反应是想起便利店收银台后面挂的那条红绳——年轻店员看到酒水单或敏感商品,会把单子推给后面那个戴老花镜的店长。Fable 5 在做一样的事,遇到自己评级”得拿稳一点”的问题,就把笔交给隔壁那个稳重点的同事。
这个机制的设计角度,比我看到过的任何模型卡都更接近”产品”——它没用”拒绝回答”这种硬墙,而是用”模型分流”这种软处理。从用户体验上看,你大概率察觉不到自己被降级了,回答还在,只是这次回答你的不是 Fable 5。
我必须诚实地承认,我这一晚没复现出 fallback 的具体边界。我跑了几个我能想到的偏侧 prompt,模型回答顺得很,看不出明显切换的痕迹。Anthropic 没公开分类器的阈值,外部红队报告 1000 小时没找到通用绕过,我也只能信他们这个数字。
至于蒸馏分类器,那条是专门防”被授权外的训练方”从 Fable 5 拷能力的,平时用不上,但它的存在本身就是一个声明:
Anthropic 这次不打算把 Fable 5 的能力随便放出去给别人复刻。
四、$10 / $50 这价钱,谁该现在切,谁该再等等
钱的事儿放最后说。
Fable 5 的官方定价是输入 $10 / 百万 token,输出 $50 / 百万 token,正好是 Opus 4.8 的两倍。但开了 prompt caching 之后,缓存命中的部分有 90% 折扣,这一点不能不提——做长 RAG 流程的团队,真实成本不一定翻倍。
订阅侧的安排比较有意思:6 月 9 日到 6 月 22 日,Pro / Max / Team / Enterprise 这四档订阅用户免费用 Fable 5;6 月 23 日起改成消耗 credit。这是 Anthropic 一贯的打法——给两周时间让你的真实工作流跑出依赖,等你回不去再开始扣钱。
那到底该不该现在切?我说个分类:
- 你的活儿是长程任务(多步 Agent、大代码库重构、跨文档审阅)——立刻切,这 12 天里把账算清楚
- 你的活儿是单次 chat、短 prompt、客服问答——别切,Opus 4.8 完全够用,Haiku 4.5 还更便宜
- 你的活儿涉及生化、网安、蒸馏相关研究——切了你也只能拿到 Opus 4.8 的回答,省点钱
- 你是被老板要求”评估一下新模型”——免费的两周窗口正好给你写评估报告,过了 6 月 22 日就得报预算
价格策略上还有一件不太被提的事:Mythos Preview 版本之前的价格比 Fable 5 现在贵 50% 以上。也就是说,Anthropic 这次是把更强的能力以更便宜的价格放出来。这不是降价,这是 Anthropic 在告诉 OpenAI 和 Google:我们已经摸到了一个我们觉得舒服的成本曲线,你们要打就来。
写在最后
回到最开始那个问题。12 天里两次发模型,这次的关键不是”跑分跳了 11 分”,是 Anthropic 第一次把 Mythos 级别的能力放进 API,让你用 $10 就能调到。
能不能赚回那 $10,不在跑分里,在你手上那个具体的活儿里。你的代码库多大,你的 Agent 长链谁来扛,你愿不愿意在 6 月 22 日之前免费跑几个真实任务做对照——这些我不知道
本文由 @阿铭Ziven 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









Mythos级别对外开放确实是关键里程碑,意味着Anthropic在安全性和能力之间找到了平衡。分类器降级而不是硬拒,既符合安全要求又保持了用户体验,这种产品思维值得其他模型厂学习。
Fable 5贵一倍,但长程任务确实强。不过分类器降级机制虽然设计巧妙,但用户察觉不到自己被降级了,对开发者来说,如果任务涉及安全边界,实际拿到的是Opus 4.8的能力,那是不是有点挂羊头卖狗肉?
这次Fable 5发布,跑分涨了11分不是重点,真正关键的是Anthropic把Mythos级别的模型开放给了公众。以前只给政府用,现在直接上API,价格还比神话预览版便宜一半。分类器降级的设计很聪明,遇到敏感问题自动切到Opus 4.8,既安全又不影响体验。最后建议根据任务类型选择,长链任务值得切,简单对话就别折腾了。