
 起点课堂会员权益
起点课堂会员权益我们的RAG评测方案,第一版被批得体无完肤
RAG上线容易优化难,最怕模型明明看到了正确答案还在闭眼瞎编。本文大白话复盘了一个企业知识库项目的踩坑血泪史,拆解了系统在召回、精度和知识冲突上的三大翻车现场,并分享我们如何用专属、混淆、对抗三类题型重构评测方案,真正揪出那些“高分低能”的假把式。

很多团队上线RAG之后,都会经历一个相似的阶段。模型看起来比以前聪明了,能够引用企业知识库里的内容回答问题,业务演示效果也不错。于是大家开始讨论召回率、重排模型、Embedding选型,仿佛只要把技术栈补齐,一个可靠的企业AI助手就已经近在眼前了。但现实往往没有那么乐观。真正让人头疼的不是模型不知道答案,而是答案明明就在知识库里,模型也确实看到了,却依然能够一本正经地回答错误。更麻烦的是,当这种情况发生时,很多团队甚至不知道问题究竟出在哪里。
年初我们在做一个企业知识库项目时,就被这样的问题困扰了很长时间。为了搞清楚RAG系统究竟会怎样失败,我们从零开始设计了一套评测方案。结果第一版方案拿去评审后,被批得体无完肤。但也正是从那次失败开始,我们才真正理解了RAG评测应该关注什么。
一、我们为什么开始测RAG
那天客户发来一张截图,我们整个组人都麻了。用户询问企业版产品是否支持7天无理由退款,而模型给出的答案是“支持”。如果只是看到这句话,可能不会觉得有什么问题。但当我们打开知识库原文时,情况就变得有些荒谬了。文档里白纸黑字写着:“企业版产品属于定制化服务,一经开通,不支持退款。”这不是需要推理的问题,也不存在理解歧义,答案几乎已经摆在了明面上。
最开始,大家都以为是知识库出了问题。毕竟类似情况以前并不少见。业务规则调整后文档没有及时同步,上传过程中遗漏内容,甚至索引构建失败,都有可能导致模型拿到过期信息。于是我们先检查知识库文档,再检查更新时间和索引状态,希望尽快定位原因。结果所有环节都正常。最终让我们意外的是,当我们进一步查看检索日志时发现,那份写着“不支持退款”的文档其实已经被成功召回,而且排名非常靠前。换句话说,模型不是没找到答案,而是在看到正确答案的情况下,依然给出了错误回复。
这让我们第一次意识到,问题可能并不在知识库本身。过去我们遇到的大部分问题都比较容易归因:知识库里没有内容,那就是知识缺失;知识库里有内容但没检索出来,那就是召回问题。但这次不一样。文档存在,检索成功,相关内容也已经进入上下文,按理说整个链路最关键的环节都已经打通了,可最终结果依然是错的。
带着这个疑问,我们开始翻查更多线上案例。原本以为这只是一个偶发问题,结果越看越心惊。有些问题确实属于召回失败,模型根本没拿到答案;有些问题则是召回到了错误文档;但还有相当一部分案例与退款问题非常相似——正确内容已经被召回,甚至就在模型眼前,它却依然选择输出另一个答案。
以前我们习惯用一句话概括这些现象:RAG效果不好。现在回头看,这种说法几乎没有任何价值。因为它既不能解释问题发生在哪里,也无法指导后续优化。检索失败、排序错误、上下文构建异常、生成阶段偏离知识库,这些问题最终都会表现为“答案错误”,但对应的解决方案却完全不同。也正是在那个阶段,我们决定把这件事单独立项,建立一套完整的评测体系,试图回答一个问题:当一个RAG系统答错时,它究竟是在哪里开始出错的?
二、第一版方案,交出去就被怼了…
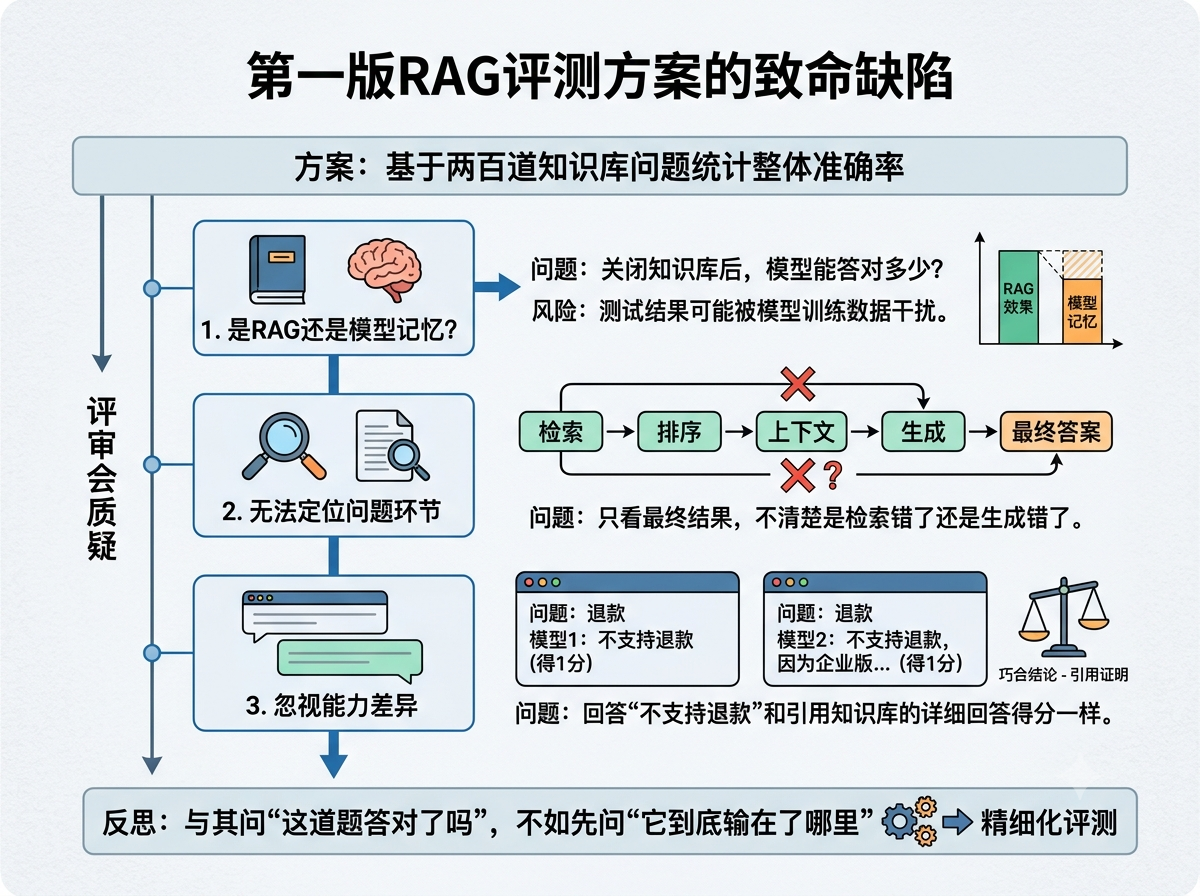
第一版方案完成得很快。现在回头看,快得有些危险。当时我们的思路非常直接:既然要测RAG能力,那就从知识库里抽题。我们整理了两百多道问题,覆盖产品功能、业务规则、操作流程和常见FAQ几个模块。评分标准也很简单,回答正确得1分,回答错误得0分,最后统计整体准确率。在方案写完的时候,我们甚至觉得这套设计已经足够完整。
真正的问题出现在评审会上。一位做搜索评测出身的同事看完方案后问了一句:“如果把知识库关掉,这些题模型还能答对多少?”我当时愣了一下,因为这个问题从来没有出现在我的思考范围里。顺着他的逻辑往下想,我很快发现了问题所在。像公司成立时间、行业通用概念、产品基础定义这类问题,本身就可能存在于模型训练数据里。如果关闭知识库模型依然能答对,那么最终测出来的高分,到底来自RAG还是来自模型自己的记忆?
还没等我们消化完这个问题,第二个质疑又来了。有人指着评分标准问:“如果答案没被召回,你怎么知道是检索错了还是生成错了?”由于我们的方案里只有最终得分,没有过程分析。对于一个包含检索、排序、上下文构建和生成多个环节的系统来说,只看最终答案是否正确,其实根本无法定位问题。
第三个问题才最致命。有人举了个例子:同样是退款问题,一个模型回答“不支持退款”,另一个模型回答“不支持退款,因为企业版属于定制化服务,不适用七天无理由政策”。在我们的评分体系里,两者得分完全一样。但事实上,它们代表的能力并不相同。前者只是碰巧给出了正确结论,后者则能够证明自己真正引用了知识库内容。而对于RAG系统来说,后者显然更有价值。
那次评审结束后,我们重新看了一遍方案。越看越觉得问题严重。表面上我们是在设计RAG评测,实际上却根本没有搞清楚RAG会怎样失败。我们把所有错误混在一起,再试图用一个准确率解释全部问题。这种做法最大的风险在于,即使最终发现模型得分下降,也无法知道究竟应该优化哪一个环节。从那以后,我们开始换一个角度思考:与其问“这道题答对了吗”,倒不如先问“它到底输在了哪里”。
三、RAG到底会在哪里出错
把手里几百个Bad Case彻底摊开、一个个对齐之后,我们发现大伙平时嘴里念叨的“RAG效果不好”,其实里面藏着三种完全不同的翻车姿势。如果连问题出在哪都分不清,后续优化根本无从下手。
第一种是最直观的,就是压根没捞到答案。很多时候知识库里明明躺着那条规则,但召回结果里连个影子都没有,模型最后只能一通瞎猜。这种情况通常得去排查Embedding质量、文档切块颗粒度或者索引参数,这属于检索大底座没打好,模型连看一眼正确答案的机会都没有。
第二种更搞心态,叫“捞是捞到了,但捞错了”。比如用户明明问的是高级版怎么接API,系统却把企业版的文档给召回上来了。这两份文档里全是相似的关键词,算分的时候很容易混在一起。如果最开始倒在重排(Rerank)和相关性判断这一步,后面生成出来的回答就算再通顺,方向也全偏了。
最让我们意外的是第三种情况:东西找得奇准无比,就差怼到模型嘴边了,它还是能给你闭着眼睛瞎编。最开始那个退款的案子就是典型的例子。我们后来复盘才发现,模型并不是无条件相信知识库的。就拿我们测过的一个真实场景来说,知识库里写着新会员取消了无限下载,但模型最后非说还能无限下。原因很简单,网上海量的公开语料和历史评测都在刷“无限下载”这个卖点,这些记忆已经在模型脑子里生根发芽了。当企业的新规和模型原有的记忆发生冲突时,模型往往会固执地选择相信自己,把知识库当成耳边风。
四、第二版方案怎么改的
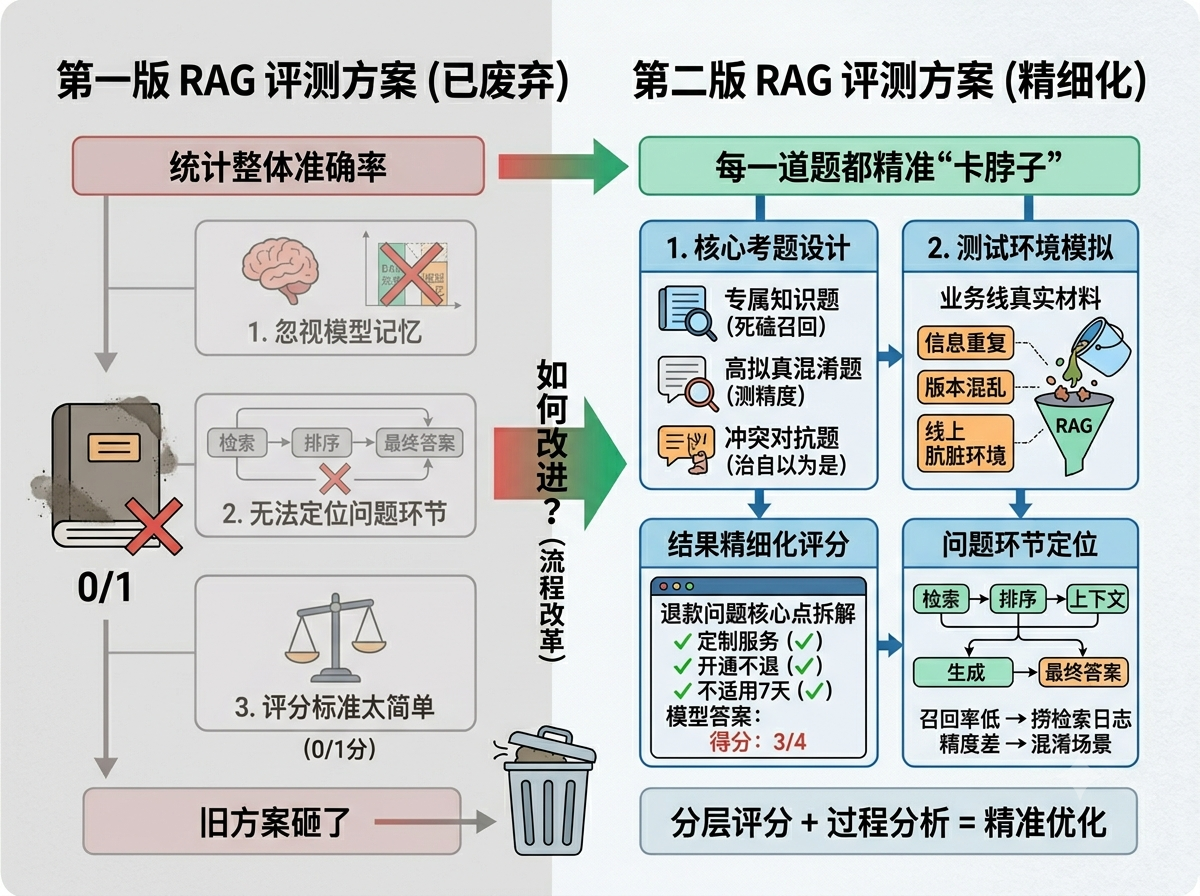
看清了这三个坑,我们直接把第一版那套应试教育一样的“200道FAQ打分表”给全砸了。新方案就一个硬性要求:出的每一道题,都必须能精准卡住某一个环节的脖子。
首先是专属知识题,用来死磕召回能力。我们挑的全是那种只存在于公司内部、模型在公开网络上绝对没见过的细节,比如某一个特定版本号的供应商审核流程。这种题模型不可能靠常识去蒙,答对了就是检索立功,答错了直接去捞检索日志,一抓一个准。
其次是高拟真混淆题,用来测检索精度。我们会故意把普通版、高级版、企业版的权益说明这些极度容易混淆的文档同时塞进库里,看系统在面对满屏大同小异的关键词时,能不能把唯一正确的那张牌给翻出来。
最后是分值最高的冲突对抗题,专门治模型的“自以为是”。我们会故意找一些跟行业常识、历史规则反着来的新规进库,如果模型这时候还凭着自己的记忆去答题、不听知识库的指挥,哪怕它回答得再专业,也直接判零分。
另外,测试用的知识库也重新洗了一遍。以前我们总喜欢用那种清洗得干干净净、分好段落的结构化文档,后来发现太脱离群众了。这次我们直接去业务线捞了脱敏后的真实材料,格式混乱的、信息重复的、老版本没删干净的,一股脑全倒进去。只有把评测环境弄得跟线上一样脏,测出来的分数才算数。分数的扣法也变了,不再是简单粗暴的对错二元论。我们把一个答案拆成四五个核心得分点,比如退款问题里必须提到“属于定制服务”、“开通不退”、“不适用7天无理由”等。模型答出几条给几条的分,这样一眼就能看出它到底是漏掉了关键信息,还是逻辑彻底走偏了。
五、测出来三个没想到
这套方案真正跑起来之后,结果直接把我们之前的一些经验主义给推翻了。第一个没想到,是高分不等于RAG能力强。有些模型测下来正确率高得惊人,结果我们把知识库一关,发现它拿到的分数居然没怎么掉。这说明它完全是在吃自己训练集的老本,靠着记忆在答题。这种模型在企业知识库这种需要随时更新规则的场景下用,简直就是个定时炸弹。
第二个没想到,是上下文给得越多,效果反而越烂。以前大家都觉得,反正Token窗口够大,多塞几份参考文档总归能当个保险。结果测试发现,无关信息一多,模型的注意力直接被稀释了,经常把真正有用的那两句话给漏掉。
最让人头疼的是第三点:只要知识一冲突,模型极度迷恋自己。看报告的时候,我们看到知识库白纸黑字写着A,模型却言之凿凿、语气无比自信地回答B,当时团队都傻眼了。这其实暴露了大模型和企业私有知识之间天然的矛盾:一个是靠海量数据训出来的长期记忆,一个是企业最新、最局部的阶段性规则。怎么让模型在面对冲突时乖乖听外部知识的话,估计是接下来很长一段时间大家都得攻克的硬骨头。
六、这套方法能复用吗
如果让我给出一个结论,我会说可以复用,但不要把它当成万能框架。这套方法最适合企业知识库问答、客服机器人、内部助手以及文档检索类场景,因为这些系统的核心目标都是让模型正确使用外部知识。如果你的场景主要是开放式聊天或者内容创作,那么评测重点可能完全不同。
整个项目做完之后,我们最终沉淀出三个原则:

写完这篇文章后,我其实还有一个问题没有想清楚。今天我们讨论的是RAG评测,但越来越多企业已经开始部署Agent系统。未来一个复杂任务可能同时涉及检索、规划、工具调用、执行和反馈。如果评测对象从单一RAG系统变成完整Agent链路,那么今天这些方法还能覆盖多少问题?或许几年后,我们会重新定义“评测”这件事。
下一篇文章,我会把这次测试中不同模型的具体表现拆开分析,包括哪些模型最容易出现“找到却编造”的问题,哪些模型在冲突信息场景下表现更稳定,以及一些让我们印象深刻的真实Bad Case。相比最终得分,我更关心的是这些分数背后的原因。因为在AI系统里,真正有价值的从来不是结果本身,而是结果为什么会出现。
本文由 @L.NaN 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供









拿真实业务线脱敏材料代替干净文档做测试库,这个细节特别实在。很多团队评测做得漂亮,上线就翻车,就是因为测试环境和生产环境差太远,脏数据才能暴露真问题。
确实,不让模型在脏数据里滚几圈,测不出检索和重排的真实抗噪能力
用专属题测召回、混淆题测精度、冲突题测对抗这个思路确实比直接打分靠谱,但冲突题的标准怎么定?如果新规和常识冲突太剧烈,模型坚持常识可能反而是安全的,这个分寸其实很难拿捏。
目前的做法是把常识做个分类,通用物理常识和安全底线,让大模型用常识死守。像业务规则常识,一旦和企业最新公告冲突,必须强行让外部知识覆盖,边界得根据具体业务场景不断对齐