
 起点课堂会员权益
起点课堂会员权益从 Prompt 到 World Model:一个大厂 RL 后训练工程师眼里的 AI 工程演化
AI工程正经历从Prompt Engineering到World Model Engineering的深刻变革。本文通过大厂RL后训练的视角,揭示AI训练范式如何从单一结果评判逐步演进为复杂任务环境设计,带你读懂模型如何从‘会答题’蜕变为‘会决策’的关键跃迁。

近看到一张图,把 AI Engineering 从 Prompt Engineering 一路讲到 World Model Engineering。很多人看到它,第一反应可能是:AI 工程师又要升级了。hahaha ~
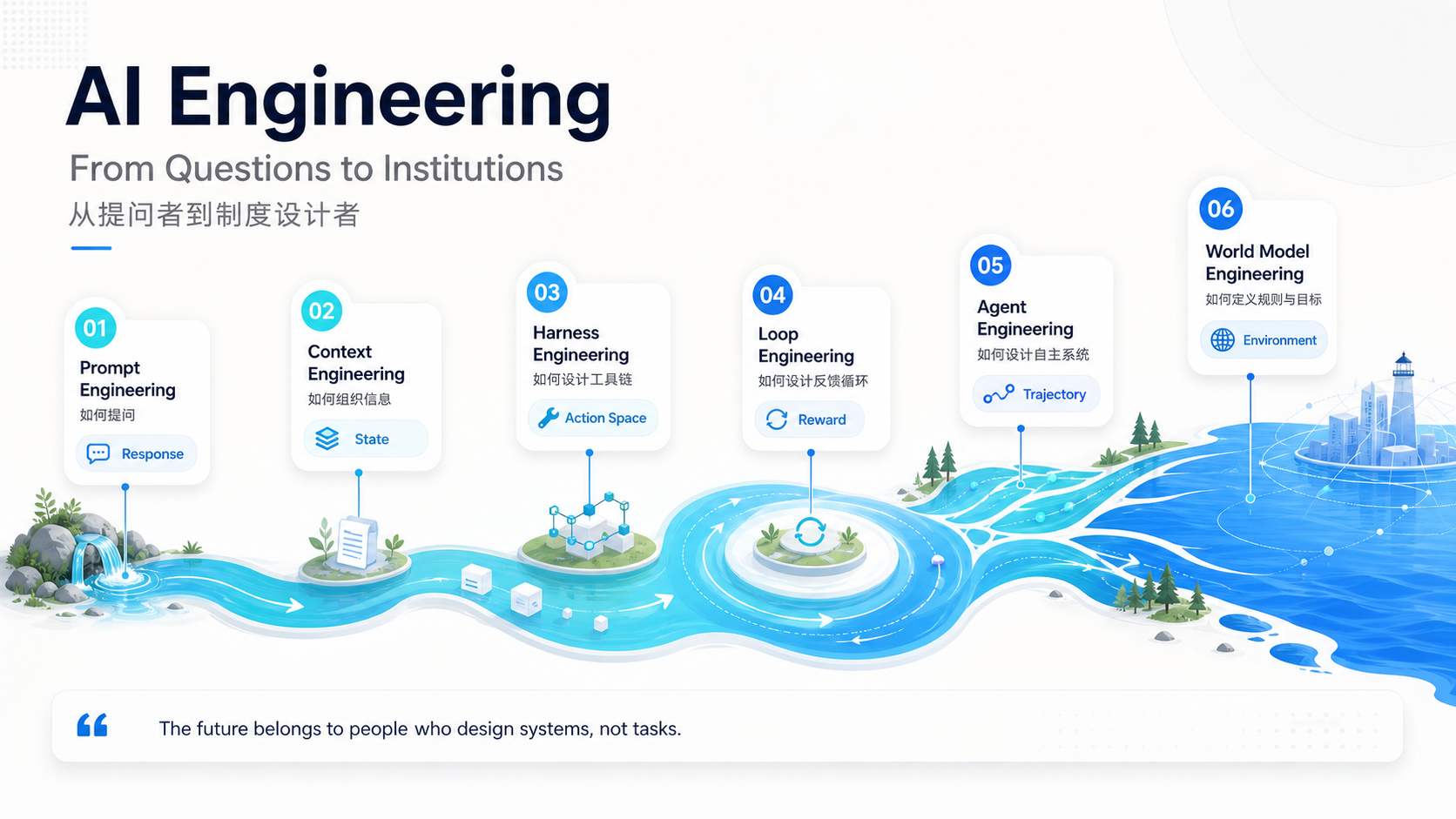
嘎达,作为一个在大厂做 RL 后训练的人,看到的是另一件事:后训练的数据来源变了。
也就是说,AI 工程这几年真正的变化,不只是 prompt 越写越复杂,而是我们开始把人类做事的经验,拆成模型能学习的东西。
01 Prompt Engineering:最早被训练的,是结果
先从最熟悉的 Prompt Engineering 说起。
2022 年前后,ChatGPT 和 Stable Diffusion 把 prompt 这个词推到大众面前。对很多人来说,AI 的使用方式突然变得很简单:你输入一句话,模型给你一个结果。
拿图像生成模型举个例子。
你写一句:
生成一张夏日饮料海报,清爽、高级,浅色背景,商品在画面中央。
模型出几张图,人再从里面挑一张更好的。
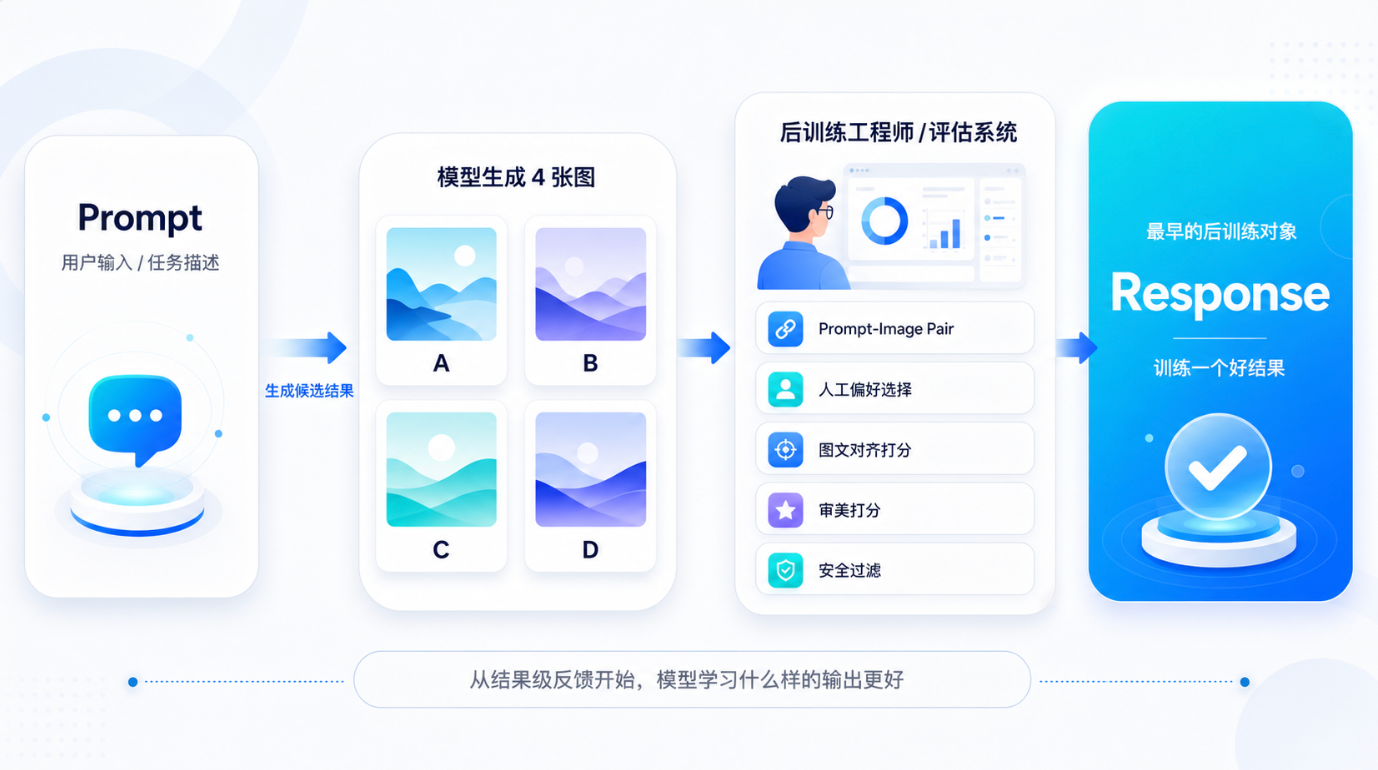
在这个阶段,后训练关心的问题比较直接:哪张图更符合 prompt?哪张图更好看?哪张图更安全?哪张图更符合用户偏好?
所以训练信号通常来自这些东西:
- prompt-image pair(图文对应);
- 人工偏好选择;
- 图文对齐打分;
- 审美打分;
- 安全过滤。
……
这就是最早的后训练对象:response
简单点说就是模型给出一个结果,人判断这个结果好不好。它有点像考试只看最终答案:你答对了就加分,答错了就扣分,但中间怎么想的,系统并不真正知道。
这一阶段当然重要。InstructGPT 和 RLHF 之所以改变行业,就是因为它证明了:模型不只是要“会生成”,还要“更符合人的意图”。
但它的问题也很明显。
如果一张图不好,我们只能说“这张不行”。至于它为什么不行,是构图错了?主体不突出?品牌感不对?还是颜色太脏?但是模型并不天然知道!!!
所以 Prompt Engineering 的本质,是人类给模型最早的显式示范。
它让模型学会回答,但还没有真正学会在任务里决策。
02 Context Engineering:不是塞更多信息,而是构造状态
很快大家发现,prompt 不够用了。
还是那张夏日饮料海报。只说“清爽、高级”,模型可能会生成一张看起来还不错的图,但它未必知道:
这个品牌过去的视觉调性是什么?目标人群是学生、白领,还是年轻妈妈?这张图是投小红书、电商详情页,还是线下海报?哪些颜色不能用?哪些字体不符合品牌规范?用户上一次为什么拒绝了上一版?
这些信息不在 prompt 里,但它们会决定模型到底该怎么生成,这就是 Context Engineering 出现的原因。
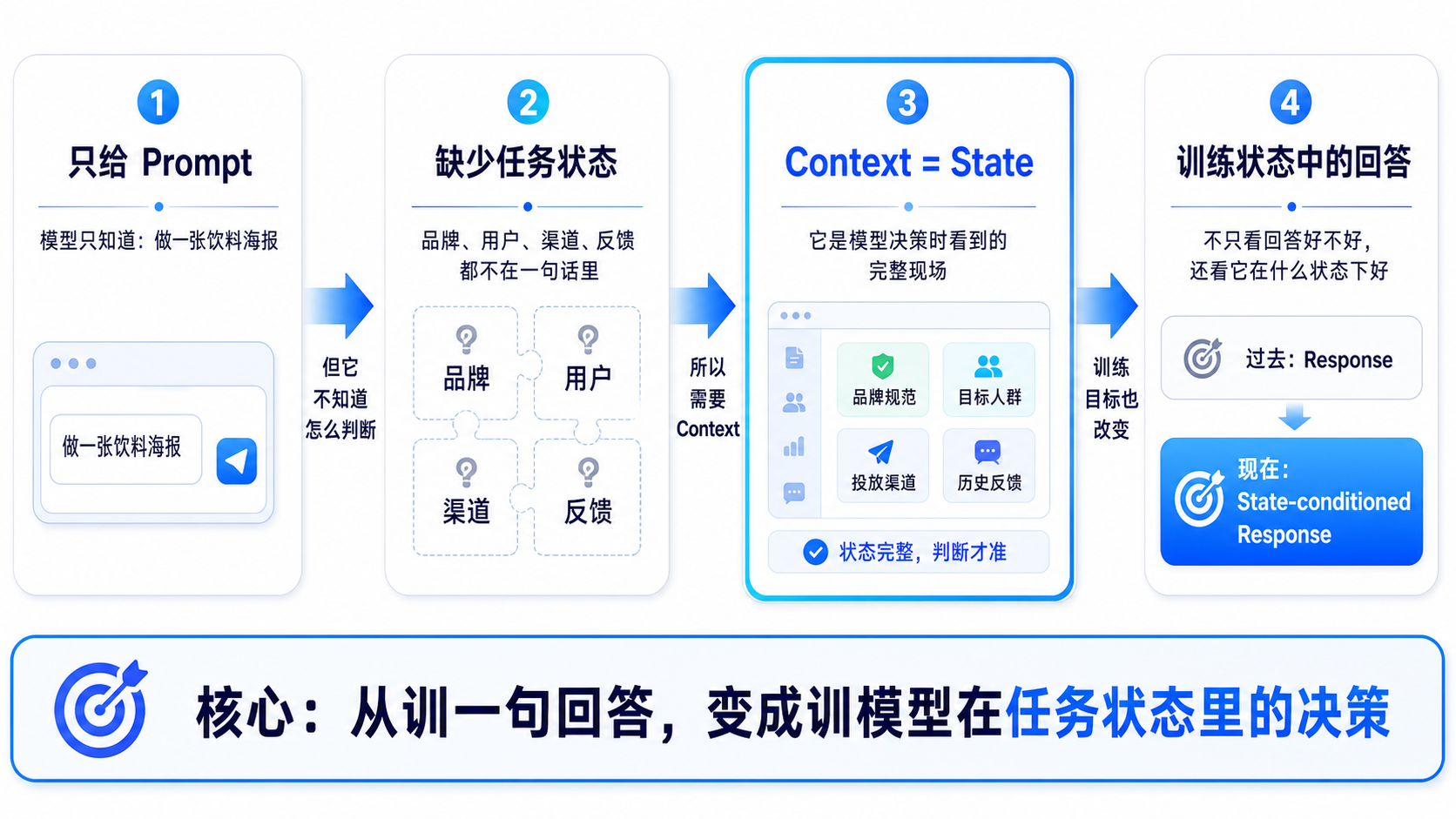
很多人把 Context Engineering 理解成“给模型塞更多资料”。但从 RL 的角度看,context 的本质不是资料,而是 state。
也就是说,它是模型做决策时看到的任务状态。
状态不完整,模型就会误判。
状态太脏,模型就会被噪声带偏。
状态不稳定,模型学到的策略也会不稳定。
这也是为什么 2023 年之后,长上下文、RAG、品牌知识库、多模态参考图、历史对话记忆变得越来越重要。
图像生成里尤其明显。
同样一句“做一张饮料海报”,如果 context 里有品牌规范、参考图、目标渠道和历史反馈,模型生成出来的东西会完全不同。
所以这个阶段,后训练对象从 response 变成了:
state-conditioned response,即模型不再只是响应一句话,而是在一个更完整的任务状态中生成结果。
这就是第一个明显的变化:从训“回答得好不好”,变成训“在特定状态下回答得好不好”。
03 Harness Engineering:工具链不是外挂,而是动作空间
再往后,模型不能只“一口气出图”,真实的图像生产不是这样工作的。
一个可用的图像系统,往往要经过很多步骤:
先生成草图、再选择构图;局部重绘人脸或商品、放大分辨率;检查文字有没有错、去掉不合规元素;适配不同尺寸。最后输出可交付素材。
这时候,工具链就出现了。
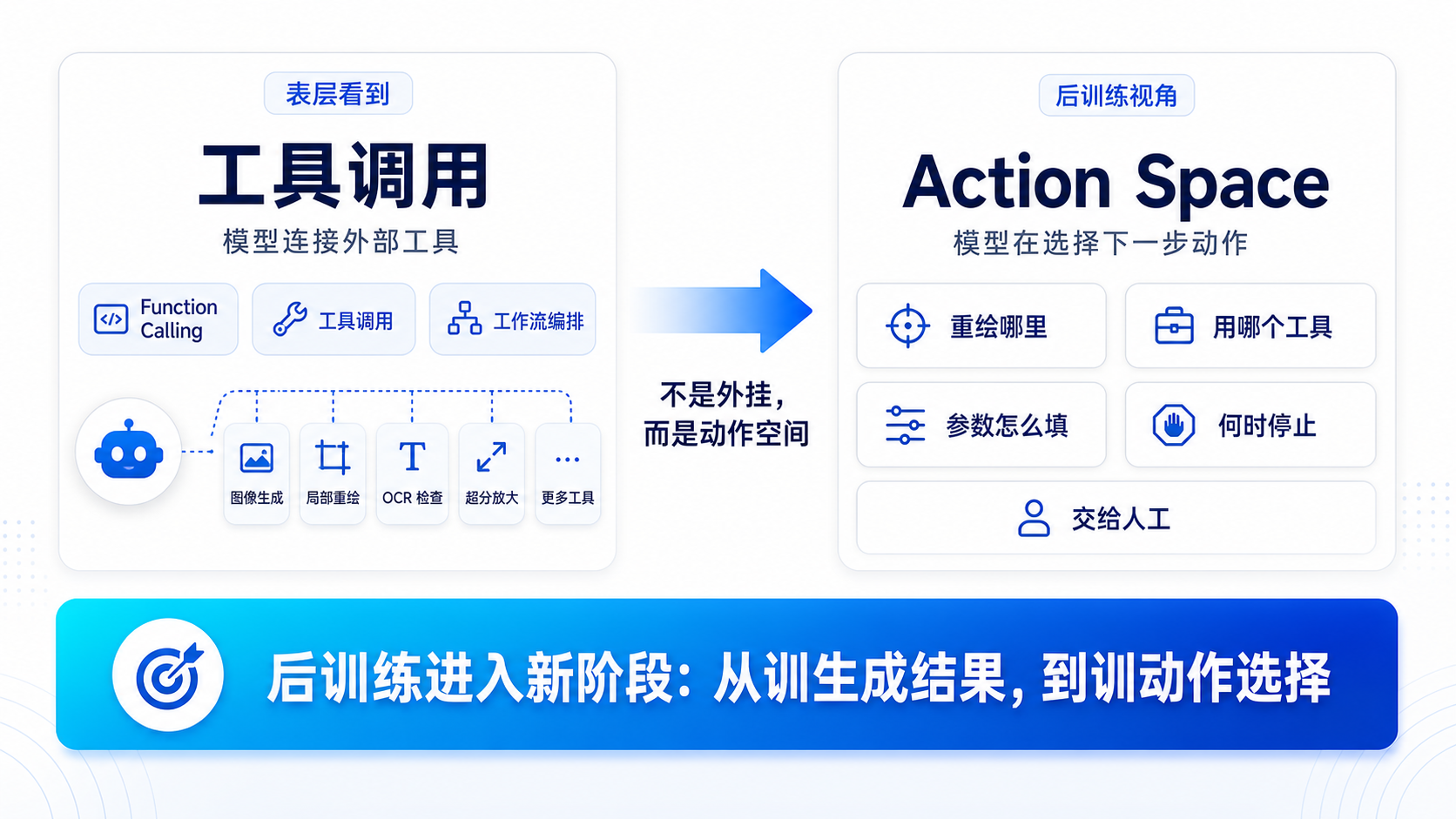
在 2023 年之后,function calling、工具调用、工作流编排、ComfyUI 这类节点式生成系统开始流行。它们让模型不只是生成内容,还能连接一组外部工具。
但从 RL 后训练视角看,工具链不是“插件”,而是 action space。
模型现在不只是回答问题,而是要选择下一步动作:
要不要重绘?重绘哪里?用哪个工具?参数怎么填?什么时候停止?什么时候交给人工?
这就把后训练带到了一个新阶段。
以前我们训练的是结果,现在开始训练动作选择,对图像生成模型来说,这个变化非常关键。因为一张图最终好不好,往往不是第一次生成决定的,而是中间一系列操作共同决定的。
如果模型不会调用局部重绘工具,商品永远不突出;
如果模型不会做 OCR 检查,海报文字可能一直错;
如果模型不知道什么时候停止,它可能把一张本来不错的图越修越坏。
所以 Harness Engineering 的价值,在于把模型的行为变得可执行、可记录、可回放、可验证。
只有动作被记录下来,后训练才知道模型到底做了什么。
这一阶段的 0-1 变化是:后训练从训生成结果,进入训动作选择。
04 Loop Engineering:用户反馈不是 reward,只是 reward 的原材料
接下来是 Loop Engineering,这也是我认为最容易被误解的一层。
很多产品视角会把 Loop 理解成增长飞轮:用户使用,系统收集反馈,然后产品不断优化。
但在 RL 后训练里,Loop 的核心不是“有反馈”,而是能不能把反馈加工成可训练的 reward。
图像生成里,用户反馈通常非常口语:
这张太 AI 味了、商品不够突出、人脸有点假、颜色太脏、第二版方向对,但还不够高级、这张最终被投放了、这张 CTR 更高……
这些反馈很有价值,但它们不能直接拿来训练。
因为真实业务反馈往往是脏的、延迟的、主观的、稀疏的。
用户说“高级一点”,到底是色彩更克制,材质更真实,构图更留白,还是字体更稳?用户最终选择了 A 图,是因为 A 图真的更好,还是因为 B 图文字错了?某张图 CTR 高,是因为图好,还是因为投放人群更精准?
这就是 Loop Engineering 真正困难的地方。
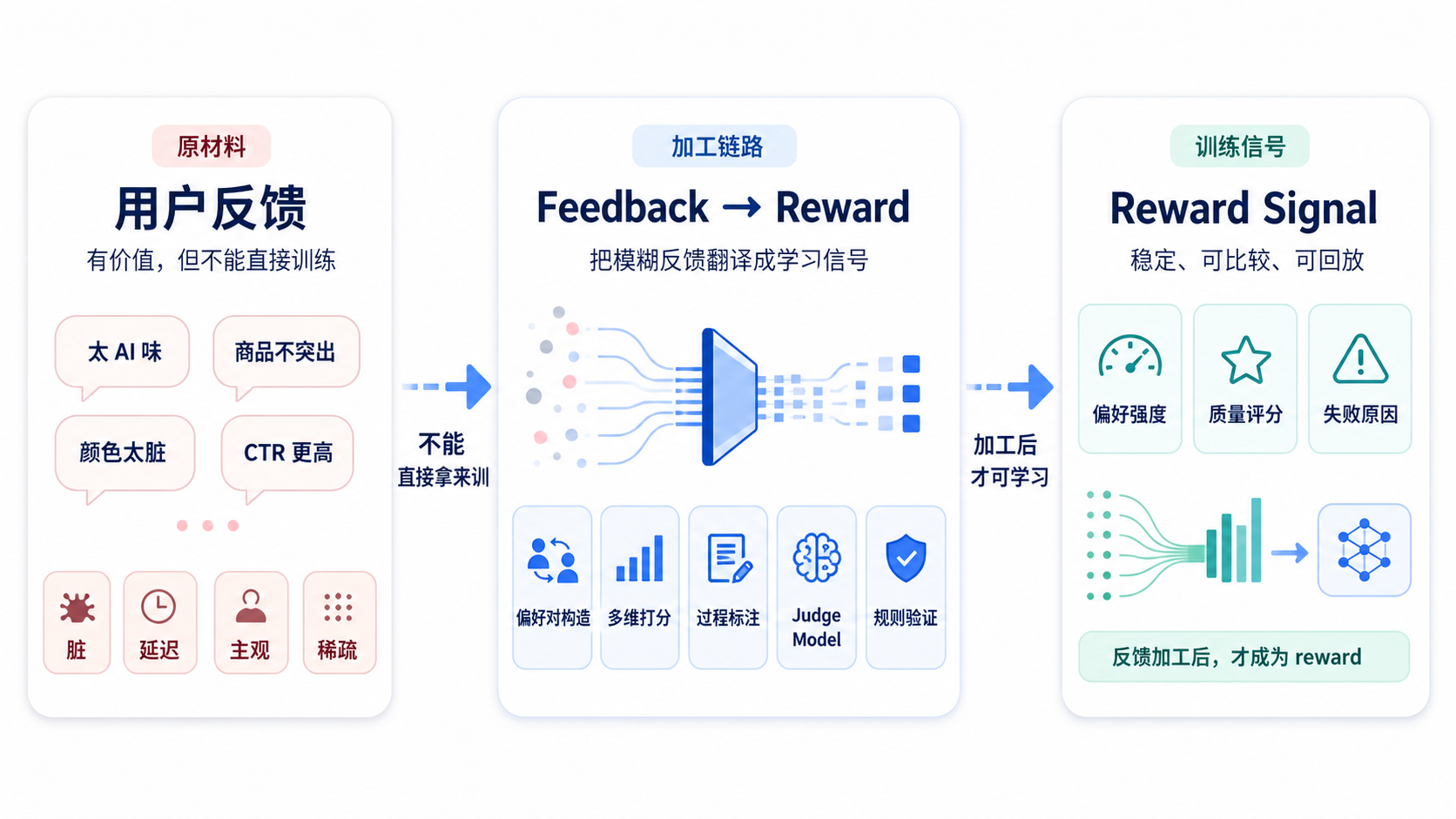
它不是简单收集反馈,而是搭一条 feedback-to-reward 的加工链路。
这条链路可能包括:偏好对构造;多维度打分;过程标注;自动 judge model;规则 verifier;线上指标回流;失败样本挖掘…..
所以这一阶段,后训练对象从 action 进一步走向 reward,更准确地说,是从单次人工偏好,走向持续生产奖励信号的系统。
这也是为什么 2023-2024 年,RLHF、DPO、RLAIF、自动评估器和各种偏好优化方法会快速成为后训练主线。
因为模型要持续变好,不能只靠一次性标注。它需要一个稳定的奖励管道。
这层的核心判断是:用户反馈不是 reward,它只是 reward 的原材料。真正有价值的是,把模糊的人类反馈翻译成模型能学习的信号。
05 Agent Engineering:最有价值的不是完成任务,而是留下轨迹
到了 Agent Engineering,问题又变了。
模型不再只是生成一张图,或者调用一次工具。它开始执行一个完整任务。
比如一个图像 Agent 接到 brief:
给某个新品饮料做一组小红书投放素材,要求清爽、年轻、有夏日感,同时突出低糖卖点。
它可能会经历这些步骤:理解 brief、拆解卖点、找参考风格、生成三版方向、自评每一版问题、局部修正商品和文字、根据用户反馈再迭代、输出最终素材包。
这不再是单步生成,而是一条完整的 trajectory(决策链路)。
从 RL 角度看,Agent 就是 policy rollout。模型在一个任务里连续做决策,每一步都会影响最终结果。
于是一个老问题出现了:credit assignment(信用分配,即奖励分配的一个动作)。
如果最后这套素材失败了,到底是哪一步错了?是 brief 理解错了?是参考找偏了?是第一次构图方向错了?是局部重绘把商品修坏了?是自评没发现文字问题?还是最后过度优化导致失真?
这就是 Agent 后训练真正难的地方。
不是让模型“动起来”最难,而是让训练系统知道:它哪一步做对了,哪一步做错了,哪一步应该被奖励,哪一步应该被惩罚。
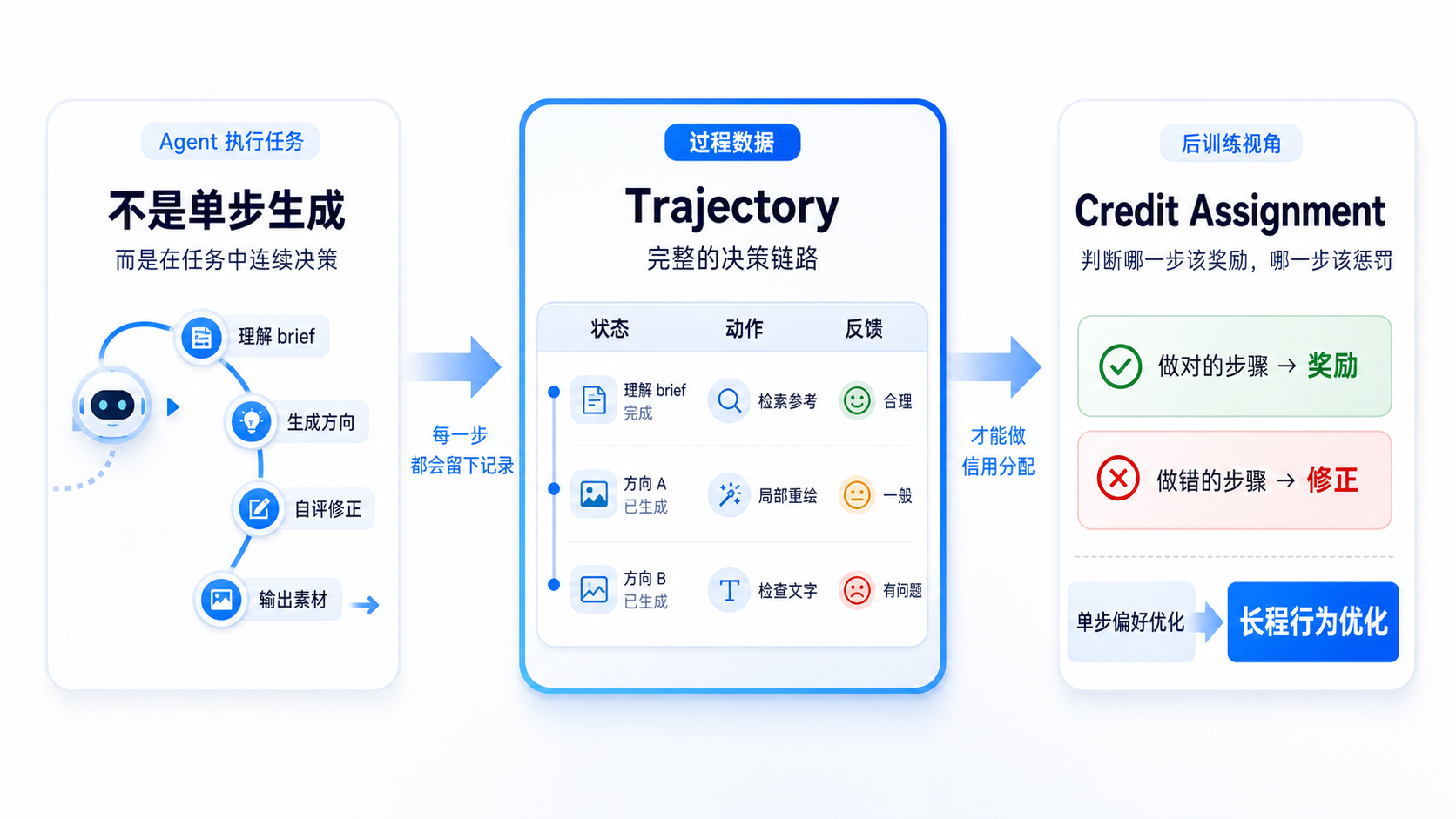
所以 Agent Engineering 对后训练的意义,不只是多了一个产品形态,而是多了一类非常重要的数据:过程轨迹。
这一阶段的 0-1 变化是:后训练从单步偏好优化,变成长程行为优化。
也就是说,我们不只是训练模型生成一个好结果,而是训练它在一个复杂任务中走出一条更好的路径。
06 World Model Engineering:没那么玄,其实它是训练场建设
最后是 World Model Engineering。
这个词很容易被讲得很玄,好像一说 World Model 就必须谈 AGI、具身智能、模拟世界。
但如果落到业务后训练,它可以非常朴素:
World Model Engineering 首先是训练场建设。
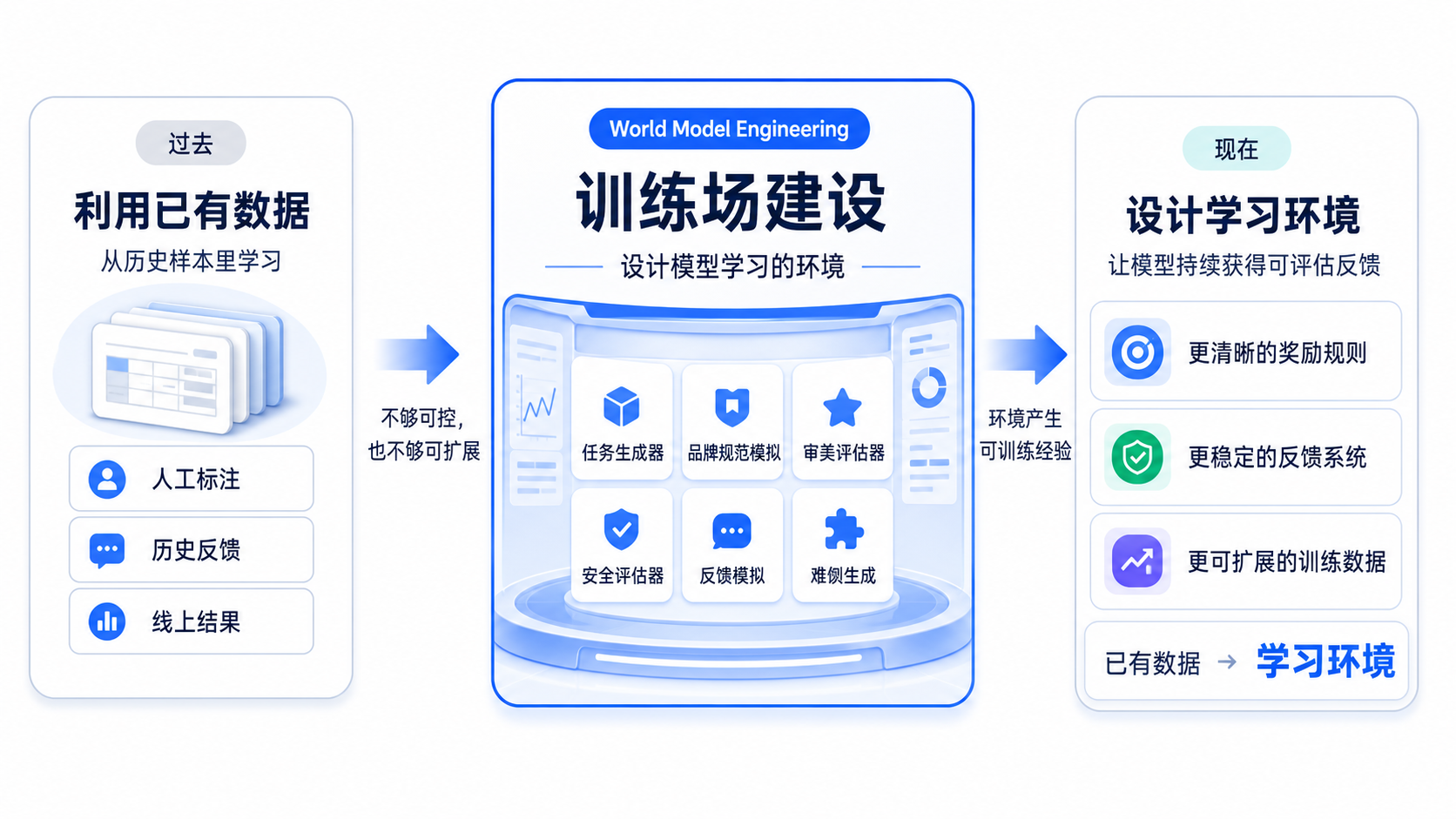
对于图像生成模型来说,一个训练场要回答这些问题:
什么样的任务会出现?什么叫好图?什么叫品牌一致?什么叫商品突出?什么叫构图稳定?什么叫违规?什么叫用户真的会采纳?什么样的错误最值得模型学习?
这时候,我们不再只是利用已有数据,而是开始设计数据产生的环境。
环境里可能有:任务生成器;品牌规范模拟;审美评估器;安全评估器;多轮反馈模拟;难例自动生成;线上指标回流。
这也是 2024-2025 年之后行业特别值得关注的变化。OpenAI o1 把“用 RL 训练推理能力”推到台前,DeepSeek-R1 又进一步证明,大规模 RL 可以让模型在特定任务上涌现出更强的推理行为。
虽然图像生成和语言推理不是同一个任务,但背后的趋势是相通的:模型能力的提升,不只来自更大的预训练数据,也来自更好的训练环境、更清晰的奖励规则、更可扩展的反馈系统。
所以 World Model Engineering 的意义不是“造一个虚拟世界”这么简单。
它更像是在问:我们能不能为模型设计一个足够真实、足够可控、足够可评估的学习环境?
这一阶段的 0-1 变化是:后训练不再只是利用已有数据,而是开始设计模型学习的环境。
07 把六层串起来:AI 工程真正迁移的是什么
如果把这六层放在一起,会发现它们其实不是彼此独立的 buzzword(黑话)。
更通俗地串起来就是:
- Prompt Engineering : 怎么问,模型才能答得更好。
- Context Engineering :给模型看什么信息,它才能答得更准。
- Harness Engineering :给模型什么工具,它才能真的做事。
- Loop Engineering :模型做完以后,怎么判断好坏、怎么反馈。
- Agent Engineering :模型怎么连续执行一个任务,而不是只回答一句话。
- World Model Engineering :我们要给模型设计什么样的学习环境,让它在里面变强。
从 RL 后训练角度看,这条线其实是:
从训练一个回答 → 到训练带状态的回答 → 到训练动作 → 到训练奖励 → 到训练任务轨迹 → 最后到设计训练环境。
这也是 AI 工程近几年真正的变化。
早期我们关心的是:模型能不能给一个好答案。
后来我们关心的是:模型能不能在更完整的状态里给出好答案。
再后来我们关心的是:模型能不能选择正确工具、接收反馈、持续迭代、在长任务里做出一连串正确决策。
最终我们会关心:模型到底在什么环境里学习,它接触什么任务,得到什么奖励,如何从失败中更新。
未来稀缺的,是能把现实转译成 reward 的系统
这张图的最后一句话是:
The future belongs to people who design systems, not tasks.
我同意,但我会再补一句:
未来也属于那些能设计训练信号的人。
因为模型不会自动从世界里学到正确的东西。
它学到什么,取决于我们给它什么状态,允许它做什么动作,如何评价它的结果,如何归因它的失败,以及把什么样的轨迹重新喂回训练系统。
从 Prompt 到 World Model,AI 工程真正完成的不仅是一次岗位升级,也是一次训练范式的迁移:
我们不再只是教模型回答问题。我们是在设计一个让模型持续学习的世界。~
参考节点
2022:InstructGPT/RLHF 论文发布,RLHF 成为对齐和后训练的重要方法。
2022-08:Stable Diffusion 发布,文生图进入大众创作工具链。
2022-11:ChatGPT 发布,prompt 和对话式 AI 进入大众视野。
2023:DALL-E 3 强化复杂 prompt 理解,并与 ChatGPT 结合。
2023:function calling、工具调用和工作流编排成为 AI 应用的重要方向。
2024:OpenAI o1 发布,强化学习与推理模型成为行业焦点。
2025:DeepSeek-R1 发布,大规模 RL 后训练进一步进入公共讨论。
本文由 @AI搭子木木 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


