
 起点课堂会员权益
起点课堂会员权益AI训练师会不会消失?我在一线看到的三个真相
今年AI训练师快被焦虑淹没了,大家都觉得合成数据一上,我们这行就得给AI陪葬。但在离模型最近的一线交了两年学费后,我看到了三个不一样的行业真相:纯堆量、挑错字的外包确实被砍光了,但岗位没消失,而是门槛暴涨到了“拼审美”的阶段;海外大厂抢着招中文导师,是因为中文里那点“人情世故”机器根本算不透;而我们团队被一批“完美数据”坑惨的经历证明,全是合成数据的“近亲繁殖”只会把模型训傻。行业正在大洗牌,工具人退场,手艺人留下。

最近半年上网,发现网络上很多人问这样的问题:“AI训练师是不是过渡职业?”
问的人有正在找工作的应届生,有刚被外包裁掉的标注组长,也有在互联网大厂做数据运营想转行的朋友。他们的焦虑不是凭空来的——今年春招数据摆在那里,要求三年以上经验的AI相关岗位占比超过七成,面向一年以内经验者的岗位缩减了将近两成。再加上合成数据的概念越来越热,热到一些媒体直接喊出“AI训练师即将被AI取代”。
我听到最夸张的一个说法是:“等模型自己能生产数据了,你们这群人还有什么用?”
说实话,这种话听多了,我偶尔也会想:是不是真的快到头了?
但回到工位上,手头的活还是那几样:审一批有争议的医疗评测数据、跟标注同学掰扯一条边界定义、盯一个上线模型的badcase回流。这些活一件都没有变少,反而越来越细、越来越杂。
这篇文章不打算给什么结论。我只想把我这半年在一线看到的三个真实变化写下来。它们是三个信号,指向同一个方向:这个岗位没有消失,但它正在快速变形。而大变形的窗口期,恰恰是留给那些愿意看清楚的人的机会。
一、岗位没消失,但门槛跳了个台阶
先说我看到的最直观的变化。
去年年初,我所在的团队还养着几组纯标注外包,每天的工作流程很简单:我们出模板,外包按模板写问答对,一天几百条,压一压量,一周能出几千条SFT数据。那时候的核心能力就两样:能把需求说清楚,能把模板写规整。至于数据质量,靠的是两条腿:量大,然后抽样检查,不好的打回去重做。
这个模式在2024年之前是行得通的;模型能力还没那么强,对数据的需求是“有就行”,质量是加分项,不是硬门槛。
但到了2025年下半年,风向变了。
首先是外包结算单上的数字在缩。不是我们不想用,是需求方开始要求“每条数据必须经过训练师审查签名”。一条签名意味着什么?意味着你不能只看格式,你得读内容、判断质量、审核逻辑一致性。外包按条计费,但我们内部审查一条数据的时间和外包写一条的时间几乎一样长。成本账算下来,养纯体力的性价比越来越低。
然后是今年开春,最后几组纯工具人外包全部撤掉了。不是企业不想做数据,是“堆量”这个模式本身被模型能力迭代淘汰了。现在开源模型拿过来跑一遍通用问答,生成质量已经不输中等标注员。那批人写的SFT数据投进去,模型收益微乎其微;甚至在重复语料上还出现了退化。
剩下的都是什么样的数据?医疗诊断场景下,一条问诊对话,模型回答“建议进一步检查”,这个回答是对是错?字面上看没错,但放在真实问诊流程里,病人问的是“我这个症状要不要去急诊”,模型给的答案是万能模板。这种数据,靠堆量判断不了。你得拆:模型有没有理解症状的紧急程度?有没有在应该明确表态的时候选择了模糊?有没有给患者传递了错误的安全感?
以前我们判断数据质量,只看“回答对不对”。现在我们在做的事情,是把模型的输出掰开来细看:这一段是事实性幻觉(说了不存在的事实);那一段是编造引文(把A论文的作者说成B);还有一类最难定性,那就是过度推理,模型在不确定的时候硬给了一个看起来合理的答案。这三种幻觉,处理方式完全不同;前两种靠数据清洗能解决,最后一种靠的是训练师给模型定规矩:什么时候必须说“不知道”,什么时候可以给倾向性建议,什么时候必须明确引导用户就医。
这些东西没有现成的标准答案。每条数据的边界是靠训练师和评测同学来回“磨”出来的。
我称之为“数据审美”。不是美学意义上的审美,而是一种对数据质量的本能判断力,你能在几十条看起来都合格的回答里,一眼看出哪一条会让模型学歪。知道哪些数据该留,哪些该砍,哪些虽然格式完美但就是太“模板化”了,会让模型说话像机器人。
这种能力的培养没有捷径。它依赖于你亲手处理过多少条争议数据,跟标注同学吵过多少回架,看过多少badcase回流之后才搞清楚“哦,原来是那批数据的问题”。而现在的行业现实是,已经没有新手村给新人练级了。要求三年以上经验的岗位占了七成以上,背后的逻辑很直接:企业不想花钱培养一个人从“能写数据”到“能判断数据”,他们想直接招一个已经具备判断力的人。
AI训练师这个岗位没有消失,但它的准入门槛跳了一个台阶。过去你只要会写、会标、能熬夜干量就行了;现在你需要能判断、能定标准、能为模型的行为负责。

二、中文数据是一块硬骨头,母语者才有资格啃
六月第一天,我看到一条新闻:xAI开始在全球招募“中文AI导师”,核心任务是教Grok听懂标准普通话、方言,以及中英混杂的日常生活用语。
这条消息在我们圈子里转了一圈,大家的第一反应不是“机会来了”,而是“他们终于知道中文有多难搞了”。
这不是xAI一家的事。过去两年里,海外大厂在中文数据上踩的坑,我或多或少都接触过一些。很多团队的第一反应是找翻译公司把英文数据翻成中文。结果出来的是什么?是“为了你好,请确保你的安全”这种翻译腔极重的语料。模型上线后,你跟它聊两句就觉得这人“不太像在中国生活的”。不是模型参数不够,是从根上数据就歪了。
中文的难,不在字面,在语境。
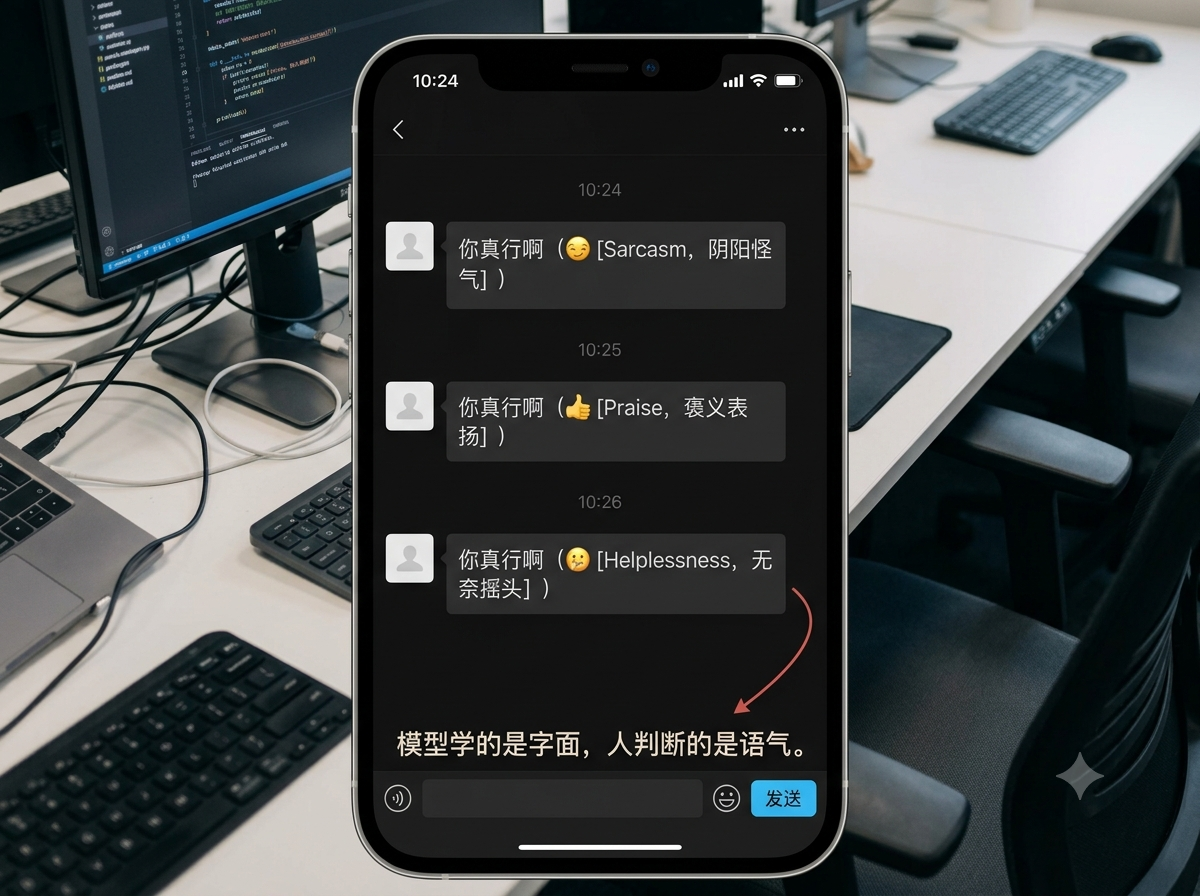
我团队里有个同学专门负责清洗情绪语料。她给我看过一条标注记录,句子是“你真行啊”,标注员标注了“褒义——表扬”。但这句话在任何中文母语者看来,配上不同的上下文,可以是讽刺,可以是阴阳怪气,也可以是无奈摇头。标注员按字面意思标成表扬,模型学到的就是“你真行啊=正面评价”,上线之后碰到用户阴阳怪气说这句话,模型回一句“谢谢夸奖”,场面直接失控。
这种“话外音”问题在中文里到处都是:“你看着办吧”,是信任还是甩锅?“再说吧”,是真的还有机会还是委婉拒绝?“挺好的”,是真的好还是懒得说不好?母语者靠直觉判断,但模型学的是统计规律。如果训练数据里80%的“挺好的”都是中性偏正面标注,模型遇到负面语境下的“挺好的”就会崩。
还有中英混杂语料的问题。互联网行业干活的人都懂,“这个需求很Urgent,先Catch一下”、“我们Align一下再Go”,这种句子在真实聊天记录里出现的频率高得吓人。如果训练数据按教科书中文去滤波,模型就听不懂互联网人在说什么;但如果全盘接受,模型输出里全是中英夹杂的黑话,又显得很不专业。怎么在真实感和规范化之间拉出一条及格线?这个度全靠一线的人拿肉身去和标准博弈。
我之前在金融AI项目里处理过一批数据,客户要求输出语言必须“规范”,但又希望模型能理解用户的自然表达。这句话听起来简单,做起来极其分裂。用户说“帮我看看这个能不能搞”,模型翻译成“请帮我评估该操作的可行性”,意思对了,但人机对话的体验感全没了。后来我们只能做分层清洗:模型理解层保留口语化表达,模型输出层走规范化路径。但这么做,数据量翻倍,标注复杂度翻倍。
海外大厂不是做不了中文,是他们缺少真正理解中文的人在一线定标准。他们可以花高价请翻译、请语言学博士、请标注团队,但这些人中间,如果缺少一个真正在中文互联网语境里泡了二十年、能判断“这句话写出来像不像真人说的”的人,那数据质量的天花板就卡在那里。
中文训练数据不是技术问题,是文化问题。海外大厂对中文母语训练师的需求,不是短期缺人,而是他们发现这条路绕不过去。能做这件事的人,门槛并不高:你不需要是语言学教授,你只需要是一个能真正理解中文语境、能把自己对语言的直觉变成标注规则的人。
三、合成数据最怕的不是质量,是“太标准”
现在圈内聊合成数据的主题,已经从“合成数据靠不靠谱”变成了“合成数据用多少、怎么用”。我们团队用合成数据已经相当普遍了:批量面试题、基础代码练习题、通用问答对,这些场景用LLM生成,效率确实高,一条指令能顶一个标注员一天的产出。
但我最近越来越强烈的感受是:合成数据正在制造一批“太标准”的数据。
为什么说“太标准”是问题?因为AI模型学到最后,学的是数据分布。如果训练数据里每一条都格式工整、逻辑完整、用词规范,模型就会认为“世界就是这个样子的”。一旦遇到真实的、杂乱的人类表达,它就不知道该怎么处理了。
我们去年被这个问题狠狠坑过一次。
当时团队接了一个垂直领域的对话优化项目,为了确保数据质量,我们制定了一套极其严格的清洗SOP:格式必须统一;标点必须全角;每段回答必须包含“首先其次最后”的逻辑结构。外包按我们的要求执行得完美无缺,几万条SFT数据交回来,毫无语法瑕疵,排版整齐得像印刷品。当时大家都觉得稳了。
结果模型一上线评测,效果直接崩了。
AI变得极度刻板。用户问一个非常简单的问题,比如“今天外卖怎么还没到”,模型回答的开头是“首先,请您不要着急……”正常人类在2026年的对话里已经没人这么说话了。再多测几条,发现模型在所有对话中都套用同一个模板,字里行间全是机器感。你问A,它给你首先其次最后;你问B,它还是首先其次最后。几万条“完美”数据投进去,反而把模型训成了一个复读机。
复盘的时候,我们把SOP摊在桌上一行一行过。发现问题出在一个非常隐蔽的地方:我们制定的清洗规则,把人类说话时所有的“真实瑕疵”全部当成噪音洗掉了。语气词(如“嗯……”、“那个……”)、口语化的省略(如“你看能不能……”)、语序的颠倒(如“不是,我是说那个……”),这些在传统数据工程中被视为脏数据的东西,恰恰是模型学到“人味儿”的关键素材。把它们全部去掉之后,模型学到的是一种现实中不存在的人类语言。
那次之后,我们调整了清洗策略。不再是“越干净越好”,而是给每条数据的清洗留了一个“毛边”的余量。什么样的毛边可以保留?不会影响语义理解的口语化表达保留,可能引入歧义的模糊表达标记但不直接删除。这个调整让下一轮模型评测的对话自然度提升了将近十五个点。
这个教训放在合成数据的话题下来看更有意思。
合成数据最大的问题不是质量,而是“缺少意外”。LLM生成数据本质上是在已有概率分布上做重采样,它产出的每一条数据都在“模型已经知道的东西”的范围内打转。喂多了合成数据,模型的输出就会越来越平滑、越来越安全、越来越没有惊喜,用我们团队的话说,叫“近亲繁殖退化”。
我做过一个视觉理解的实验,让模型识别一张复古胶片的街拍照片。画面里的内容并不复杂:一条老巷子、一个骑自行车的人、旁边有几家小店。但那张照片的特点是角度奇怪、画面失焦、光影关系微妙,人在看的时候,会本能地把注意力放在骑车的人身上,因为那是画面主体。但模型的分析结果是“一条街道,两侧有建筑物,有一个人在骑自行车”。
看懂了没有?模型说对了所有元素,但它没有抓住重点。它不理解什么叫“主体”,不知道怎么区分“主要信息”和“背景信息”。这个能力不是靠加参数能补的,它需要大量经过人工判断、标注了“主次关系”的训练数据。而那些数据,恰恰是LLM自己生成不了的,因为LLM生成图片描述的时候,不会主动去区分“这是一个特写”和“这是一个全景”在语义层面的差别。
我后来把自己在数据清洗中摸索的那套“空间-面积-主次”标准搬到了视觉数据的处理上。过去我们用这套SOP做文本数据的去噪和清洗,砍掉了一万多条垃圾数据之后,模型在内部自建测试集上的准确率从六成多提到了八成以上。现在把它用在图像理解数据的标注规则上,逻辑是相通的:先识别画面中的空间结构,再判断各元素的面积占比,最后确定主次关系。这套标准看起来笨,但它解决了当时模型“认出了所有东西但看不懂画面”的问题。
合成数据是效率工具,但不是答案本身。它擅长解决通用场景的规模问题,但真正能让模型从“及格”走向“优秀”的,是那些合成数据生成不了的坏数据、极端个案、以及人对“主次”、“氛围”、“重点”的判断力。人工训练没有消失,它只是从体力活变成了手艺活。
结语:三条路,对应三种选择
回到开头那个问题:AI训练师会不会消失?
我的判断是:这个岗位不会消失,但会快速分化。分化之后,留下的是三类人,淘汰的可能是处于中间地带的。
首先是能把数据和业务场景深度绑定的人。你懂医疗,能判断一条问诊对话里的回答到底安全不安全;你懂金融,能分辨哪些合规表述是底线、哪些可以灵活处理;你懂某个垂直领域的用户习惯,能告诉模型“这句话用户听了会觉得你在糊弄他”。这种人不会消失,因为模型可以学你的知识,但它没法批量生成你对一个领域的敏感度。
其次是能把“数据审美”变成可执行标准的人。你不仅能判断数据好坏,还能把你的判断规则写下来、教会别人、重复验证。这种人更稀缺,因为能把直觉产品化的人,在任何行业都是核心资产。我在空间-面积-主次SOP上花了将近半年才把“我觉得这张图拍得不好”翻译成可量化的规则,但这个投入在模型准确率提升上带来了明确的回报。具体做起来就是三步:第一步用空间结构拆解把画面分层(前景、主体、背景);第二步用面积占比量化各元素的重要性;第三步用主次关系标注做最终裁决,看谁在画面里承担叙事核心。这套规则看起来笨,但它最大的价值是可复现。换一个人来用这套规则标注,结果不会差太多。把经验翻译成SOP,把SOP做成可复现的标准,这种翻译能力,是未来最硬的通货。
最后是训练工具和训练方法的设计者。当合成数据成为基础设施,当标注工具越来越自动化,真正有价值的不是“用工具的人”,而是“能设计工具怎么用、数据怎么来、流程怎么跑”的人。这个角色不需要你会写多复杂的代码,但需要你理解全链路:从数据采集到清洗到评测到回流,每一个环节的坑在哪里。我见过最厉害的一个同行,他不写一个Python脚本,但他能告诉工程团队“这条数据流的反馈回路设计有问题,badcase回去之后没有跟训练数据做对齐”,一句话省了团队两周的排查时间。这种端到端的理解力,是长期待在数据一线的人才攒得出来的。
至于被淘汰的是谁,数据已经给出了答案。今年春招面向一年以内经验者的岗位缩减了两成,这不是行业在收缩,是行业在说,我们已经过了靠堆人头解决问题的阶段了。那些只会执行、不会判断,只会写模板、不会定标准的人,会最先被挤出这个市场。
但反过来看,这对愿意长期做这件事的人未必是坏事。门槛提高的同时,留下来的人会拥有更高的议价权和更清晰的职业路径。AI训练师这个title不会消失,但它的内涵已经变了:它不再是“谁都能干的体力劳动”,而是一个需要判断力、领域知识和数据直觉的专业岗位。
我在文章开头说,这篇文章不打算给什么结论。但写到这,还是有了一个:这个行业正在把“谁都能做”的工作交给机器,把“只有人能做”的工作留给人类。而判断什么是“只有人能做”的,本身就是我们这个岗位现在最大的价值。
本文由 @L.NaN 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供









中文语境的复杂性被说透了。处理“你真行啊”这种反讽,靠的不只是语言学知识,更是对真实对话场景的浸泡感。大厂挖中文导师,本质是在买这种浸泡感。
说门槛跳台阶没问题,但“三年以上经验”的要求其实也挡了很多有天赋的新人。企业不想培养人,可判断力本身就得靠实战磨出来,这矛盾短期内无解。