
 起点课堂会员权益
起点课堂会员权益把 LLM 关进确定性的笼子:ToB AI 落地工程手册
当企业客户追问AI系统是否靠谱时,他们真正需要的是什么?本文深度拆解ToBAI落地的关键挑战——确定性,揭示从可复现到可追责的工程路径。你将看到如何用四道关卡构建确定性笼子,以及为何可审计性才是真正的商业模式护城河。
你把 temperature 调成 0,以为 LLM 从此会乖乖给你同一个答案。结果同样一句问询,今天的输出和明天的对不上。
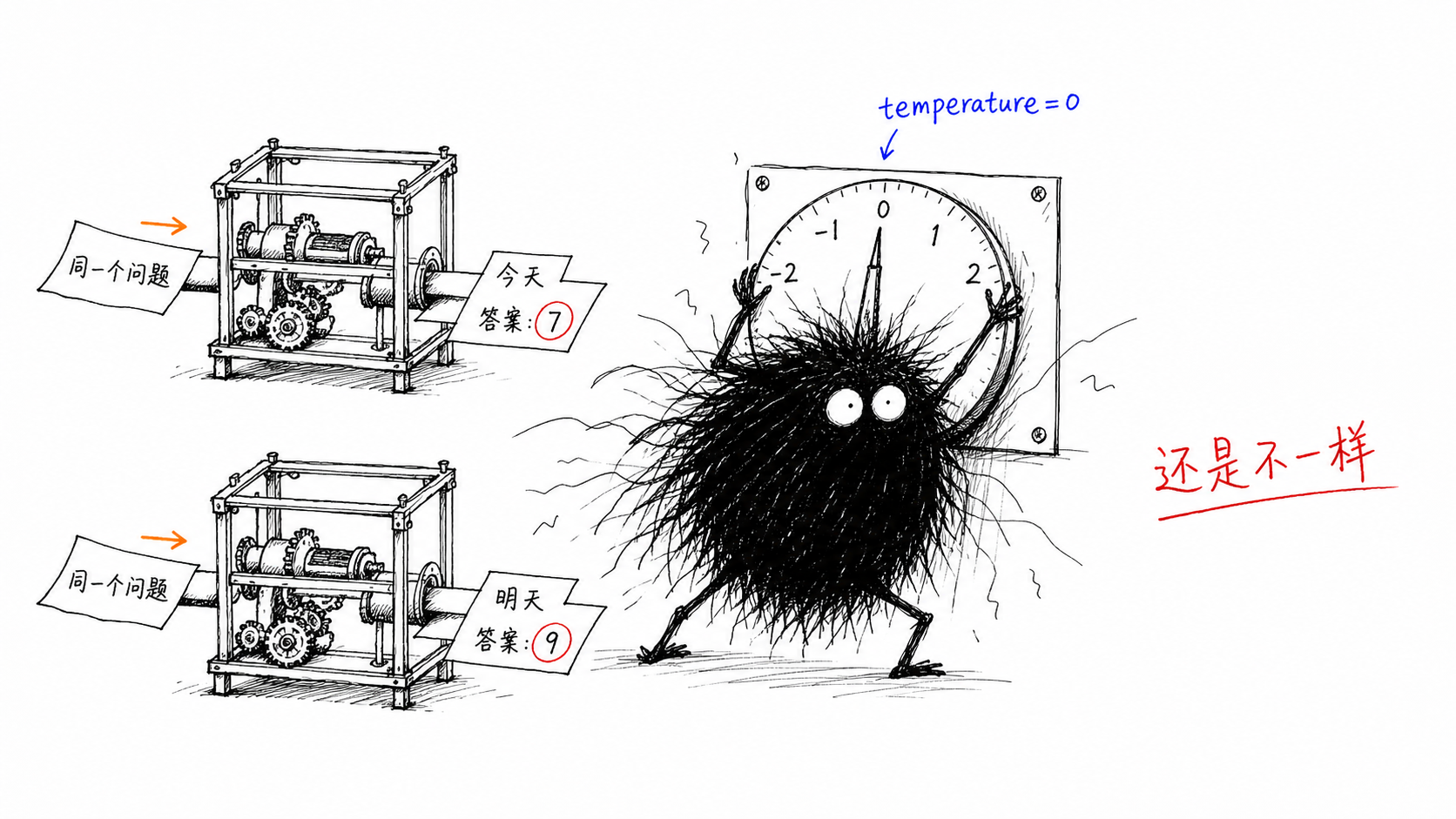
别急着怀疑自己 prompt 写错了,LLM 在系统层面,本来就不确定。
这件事放在 C 端无所谓。聊天机器人今天说话风趣、明天严肃,用户顶多觉得它有点”个性”。
放到 B 端,一张财务报表里的数字今天对、明天错,那不是个性,是事故。
一个连”同样的问题能不能给出同样正确的答案”都保证不了的产品,在企业客户那里活不过第二次演示。
这就是 ToB 商业化最硬的那道坎。
但坎的背后藏着一个更值钱的问题:当客户追问”这套 AI 到底靠不靠谱”的时候,他在买的究竟是什么?是一个更聪明的模型,还是别的东西?
一、ToB 的元约束:零容错
ToB 和 ToC 的根本分野,不在功能多寡,在容错率。
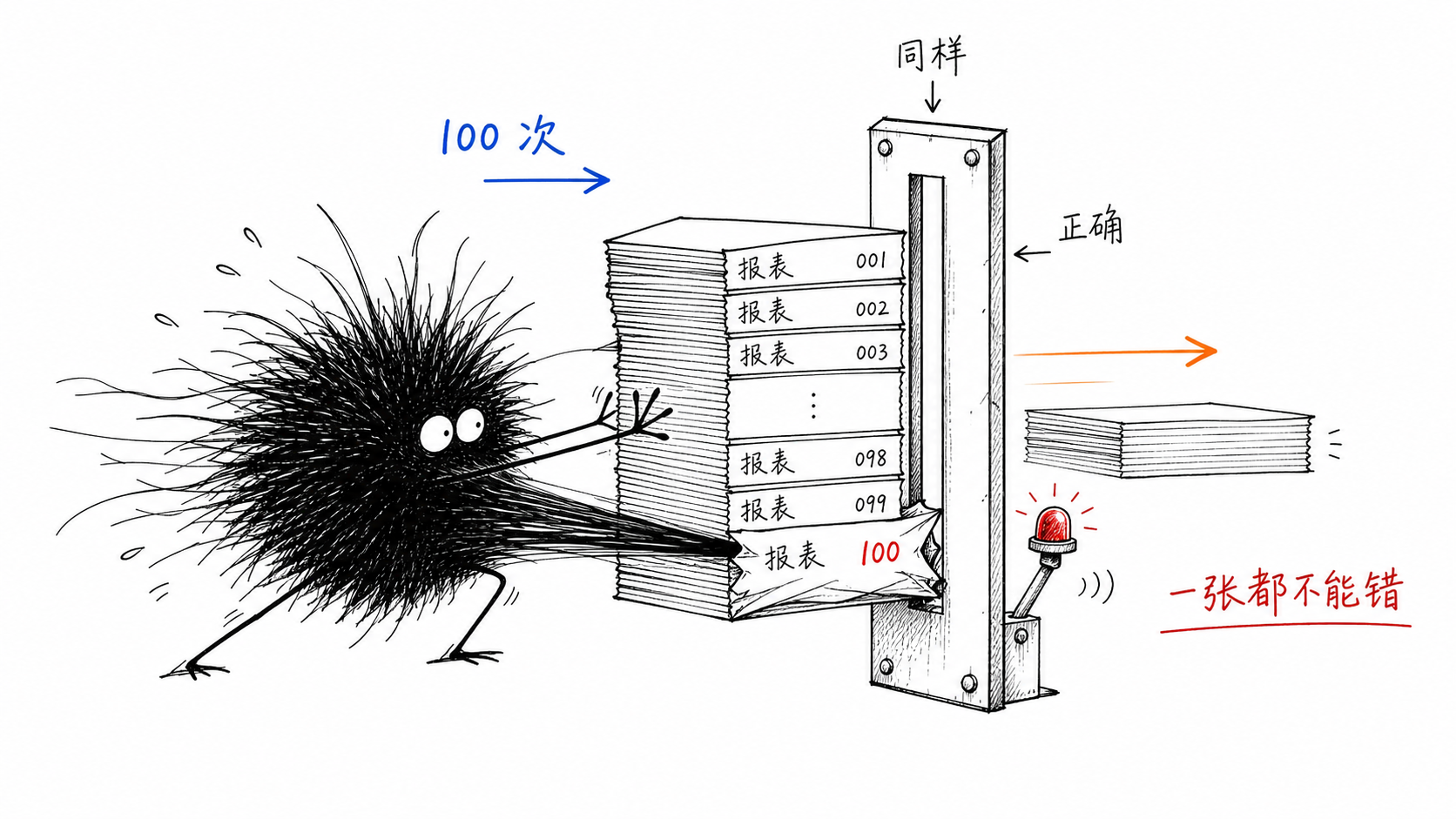
C 端用户能容忍 AI 偶尔抽风,他们要的是”大概率不错”再加一点惊喜。B 端要的是另一种东西:可复现的正确结果。同一个问题,问一百次,得一百次同样且正确的答案。
留意这句话里塞了两个要求:”可复现”和”正确”。
它们长得像,平时也总被当成一件事。后面你会看到,把它们拆开,是理解整篇文章的钥匙。
AI Agent 正在革 ToB 软件的命,这个说法不夸张。
但企业级落地的真正前提是可靠性。拿 ChatBI 这类”用自然语言查数据、自动出图表”的系统来说,它要同时扛三重约束:推理得稳,响应得快,成本得算得过来。
三样里稳排第一。一个查询系统今天给的数和昨天对不上,再快再便宜也没人敢用。
零容错不是口号,是 ToB AI 所有架构决策的出发点。
二、根因:为什么 temperature=0 也不确定
很多人以为不确定性来自采样温度,把 temperature 拉到 0 就万事大吉。
错了。真正的根源在系统层,在你看不见的硬件调度里。
问题出在 batch size。matmul、attention 这些底层 kernel 的输出,依赖当前这一批一起算的请求有多少。
生产环境里负载是波动的,这一秒十个请求一起算,下一秒一百个,batch size 一变,浮点累加的顺序就变了。浮点累加不满足结合律,顺序一变,结果在最后几位上就可能不同。
这里有个更精确的说法值得记住:并发的那些请求,从你这一个用户的视角看,根本不是系统的”输入”,而是系统的一个非确定属性。
负载本身,就是非确定的源头。
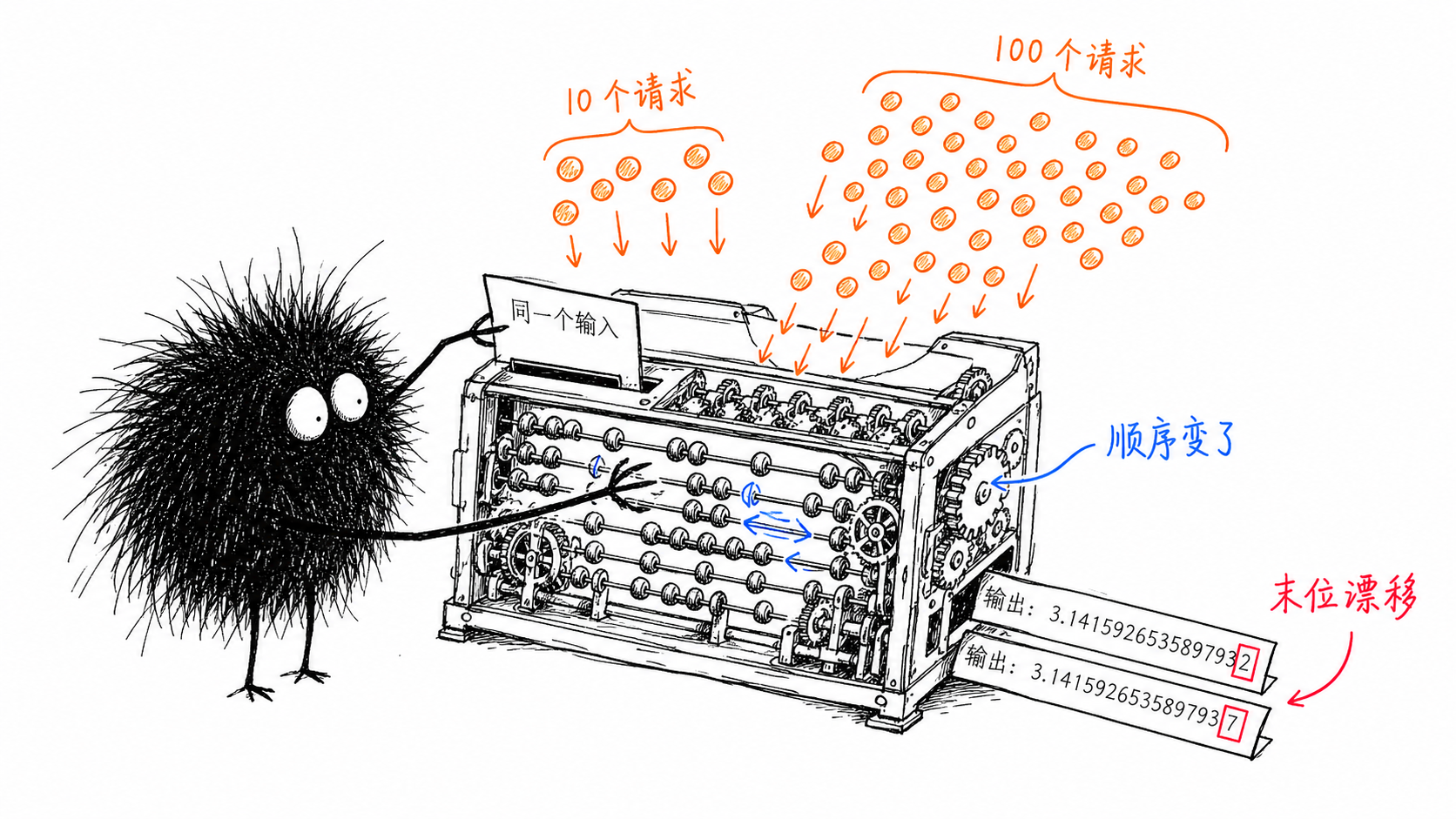
你的 prompt 没问题,temperature 也没问题,是这套服务系统在并发调度的层面,天然带着不确定性。
记住这个深度。不确定性深到了内核,连 temperature=0 都摁不住。
一般人到这儿的第一反应是:那就想办法把内核也摁住。
但 ToB 真正的解法,恰恰是不在这一层跟它打。
三、承重墙:确定性,不等于正确
ToB 要的”可复现的正确”,其实是三件能拆开的事,被我们平时糊成了一团。
第一件,可复现:同一个输入,永远给同一个输出。
第二件,正确:输出符合事实、符合口径。
第三件,可审计:每一个结论,都能回溯到它依据的是哪条规则、哪份数据。
这三件事谁交付谁,后面一件件对上。
但先得把最要命的一句说清楚:可复现,不等于正确。
一个在底层做到了完全可复现的模型,会怎么样?它会稳定地、可复现地,给你错一辈子。

同一个错误答案,你问一百次,它一字不差地错给你一百次。可复现把这个错误冻得结结实实,可它一个字都没改对。
所以当客户拍着桌子要”下周给我一模一样的数”,你得听懂这句话里有个缺口。
他嘴上要的是可复现,他真正要的,是又对、又能复现、还能让他签字向上汇报的那个结果。
用一个只解决可复现的工具,去回应一个本质是正确性的需求,逻辑上接不上。这是很多 ToB AI 方案自己都没想清楚的地方。
四、第一种解法:把 LLM 关进确定性的笼子
既然问题是正确性,解法就不在改模型,而在用一套确定性的工程架构,把那个概率性的内核包起来。
我把这套架构叫确定性笼子。
ChatBI 的工程实践里有一条原则我很认同:与大模型解耦。
意思是,哪怕 LLM 这一环抽风了、服务挂了,图表生成、数据校验这些下游环节照样可靠运转。
LLM 负责把自然语言翻译成查询意图,真正执行查询、做计算、出结果的,是确定性的传统工程链路。模型在笼子里负责”理解”,笼子外那套确定的管道负责”交付”。
拆开笼子看,里头是几道串起来的关卡:
第一道,意图层和执行层分家:LLM 只把”帮我看下上季度华东区毛利”翻译成一个结构化的查询意图,它碰不到真实的数据计算。
第二道,执行前拦一道校验:生成的 SQL 先过规则校验——字段对不对、口径合不合规、有没有越权,不合格直接打回,不让它跑到生产库上。
第三道,结果出来再核一道:用确定性的算法把关键数字交叉验算,对不上就报警,而不是直接端给客户。
第四道,可回退:任何一环 LLM 抽风,系统能优雅降级到一个保守但正确的默认行为,而不是把错误答案堂而皇之端出去。
这四道关卡下来,模型那点不确定性被层层包住。它在最里层自由发挥,每往外走一层,就被一道确定性逻辑校准一次。
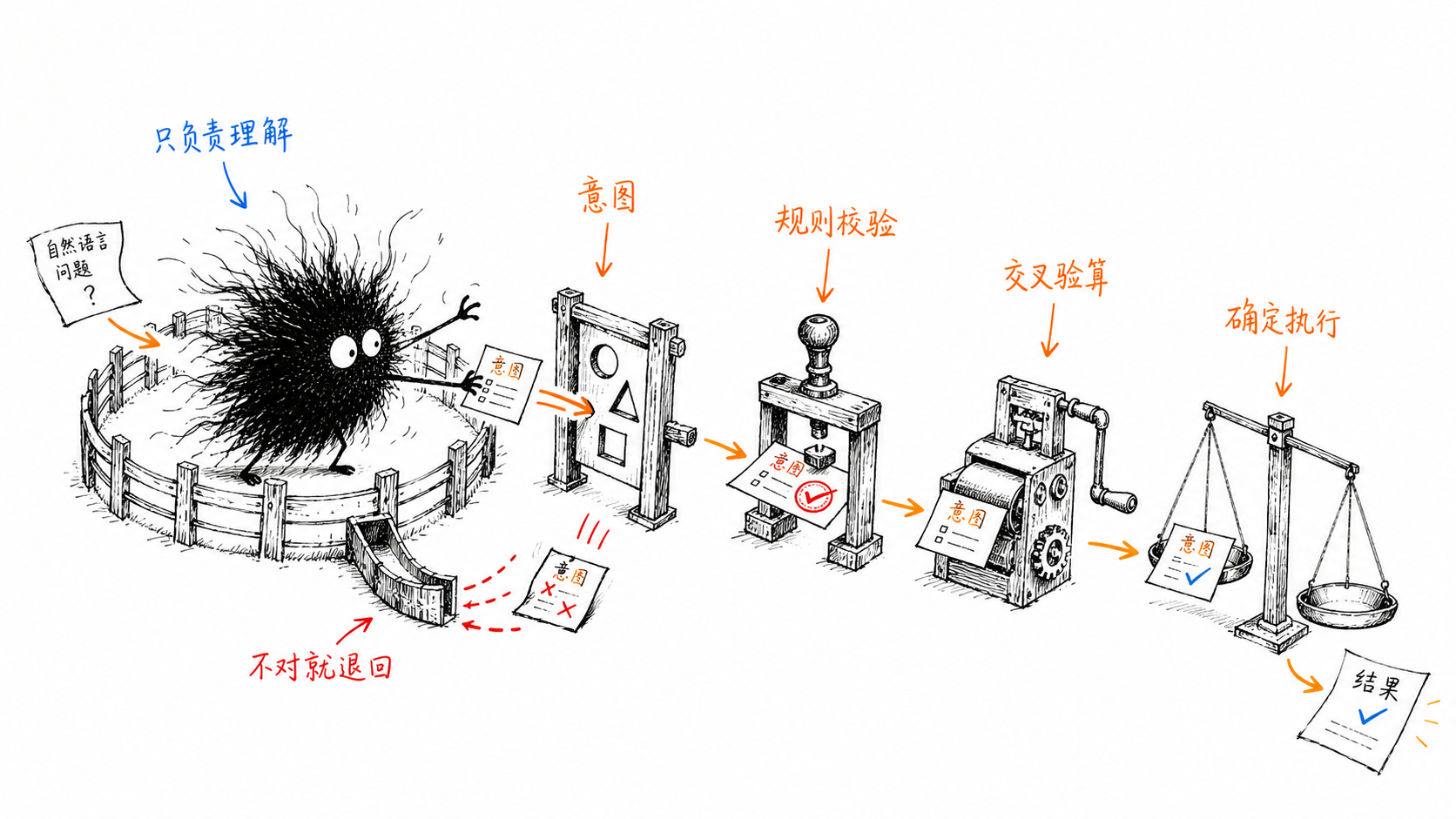
客户看到的,永远是过了所有关卡的那个确定结果。
注意这套笼子干了什么:它根本没去碰第二节那个内核难题。
LLM 这次多吐一个 token 还是少吐一个,意图要么过校验、要么被打回,语义层早把那点逐字的抖动中和掉了。
内核还在抖,但你绕开了它,没去修它。第二节留的那句话,到这里兑现:ToB 不在内核那一层跟不确定性打。
五、别把确定性推到底
你可能会问:既然抖动的根子在内核,有没有更狠的办法,从推理层把它根除?有。
SGLang 基于 Thinking Machines 的工作做了 batch-invariant kernel,让计算结果不再依赖这一批有多少请求,同一个输入永远走同样的累加顺序,进去出来字字一致。
听着很美。但搬到 ToB 查询上,这是一把用错地方的锤子。
先说代价。SGLang 官方给的数:开了 batch-invariant,推理减速 25% 到 45%,主流后端平均三成出头,而且官方白纸黑字写着”主要用于调试和复现”。
还有更新的批评直指它不适合真实的 LLM 服务系统,它把确定性变成每个请求都得交的固定税,还顺手干掉了 split-K、shape-aware tiling 这些让动态批处理有效的优化。
再说场景。batch-invariant 真正的主场是 RL 训练:on-policy 的时候,采样和训练必须用同一套数值,否则梯度对不上、reward 崩掉。那是个逐字可复现救命的场景。
可你的业务不是。笼子一立,逐字抖动在语义层已经被中和,你为了那点用不上的逐字一致,去付三成的速度税、去杀掉批处理优化,不值。
对绝大多数 ToB 查询场景,财务、报表、合规这些只要结果对、并不要求逐字一致。第一种解法就是答案,这第二条路是个诱人的歧路。
往底层推过头是一种错,往另一个方向推过头是另一种。
学界有 Stochastic CHAOS 这一类观点,值得听:LLM 本质是一个条件分布 p(y|x),不是一个固定函数 f(x)。你把这个分布硬压成一个单点,等于把模型自己的不确定性藏了起来。
一个被锁死的确定模型,会自信地给你一个答案,却瞒着你”这其实是一次掷硬币的结果”。
偏偏这件被藏起来的事,是 ToB 最该知道的。
它不是创意问题,是安全问题。模型对同一个问题的多次回答有多分散,本身就是信号:分散得厉害,说明这道题它没把握。
读法不玄:同一个问询,让模型背对背跑上几遍,几遍的答案对不齐,这条查询就别直接出,报警,或挂起来转人工。
方差是信号,不是噪音。
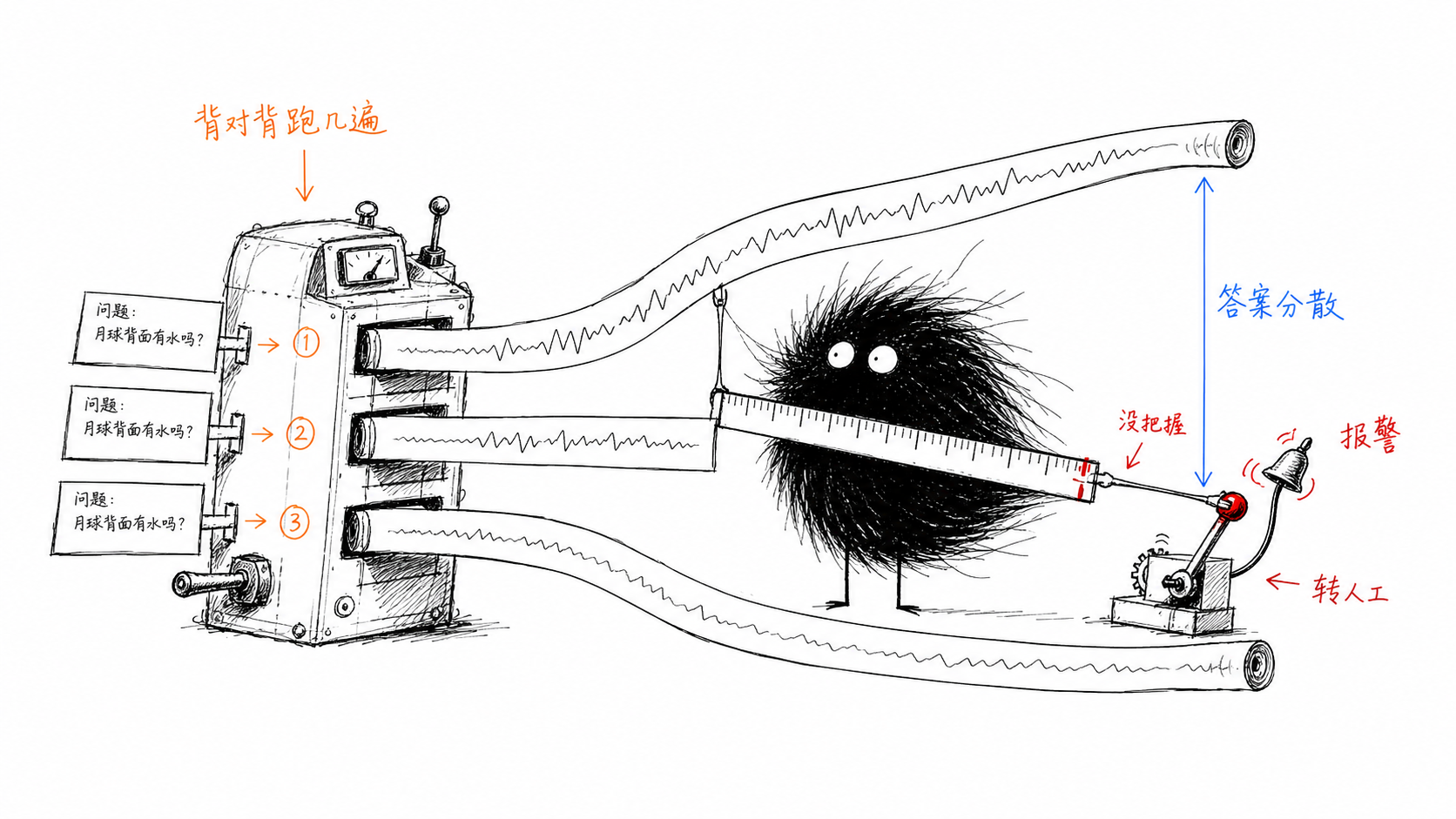
一个好的笼子,不该只把不确定性关掉,更该把它读出来,当成风险阈值喂给校验层。
确定性的正确姿势,是把它当成要关进笼子的猛兽,不是要抽干的血。
六、可追责性,才是商业模式
到这儿会有人泼一盆冷水,这盆冷水值得接住:你说的这套笼子,解耦、校验、回退不就是普通工程吗?人人都能搭,算什么护城河?确定性顶多是入场券,不是壁垒。
这话对一半。确定性确实是入场券,它是 ToB AI 活过第二次演示的门票。
真正的护城河,得往上挪一层,挪到那三件事里的最后一个:可审计。
我自己参与过一个部委级的 AI 招投标平台,从立项做到落地。
招投标这个领域,合规是刚性的,一处资格审查、一个口径判断,不能这次这样、下次那样。但更要命的不是”一不一样”,是”拿不拿得出依据”。
印象最深的一次,是评审结束后落标方提了质疑,咬定中标方一条”类似业绩”不该算数:合同金额够了,可服务期跟招标文件的口径差了两个月。
复议会上对方很凶。我们一句没跟他争口径,把系统的判定链路一条条调出来:资格条款是招标文件第几条、那条业绩填在对方投标书第几页、规则引擎判它不达标命中的是哪一行、判定发生在哪个时间戳,全程可回溯。摆完,对方没再追。
那一刻我才真切体会到这套东西的分量:模型从头到尾只干一件事,把那条业绩从一沓 PDF 里读出来、对到条款上;真正下”达标/不达标”这个结论的,是确定性的规则,而且它必须经得起被人一条条倒查。
这跟笼子一脉相承:模型只在”理解和组织”这一层发挥,下结论的环节交给确定性的规则与校验,每一步都留痕。
你看这里的落点,其实不是”可复现”,是”可审计”。
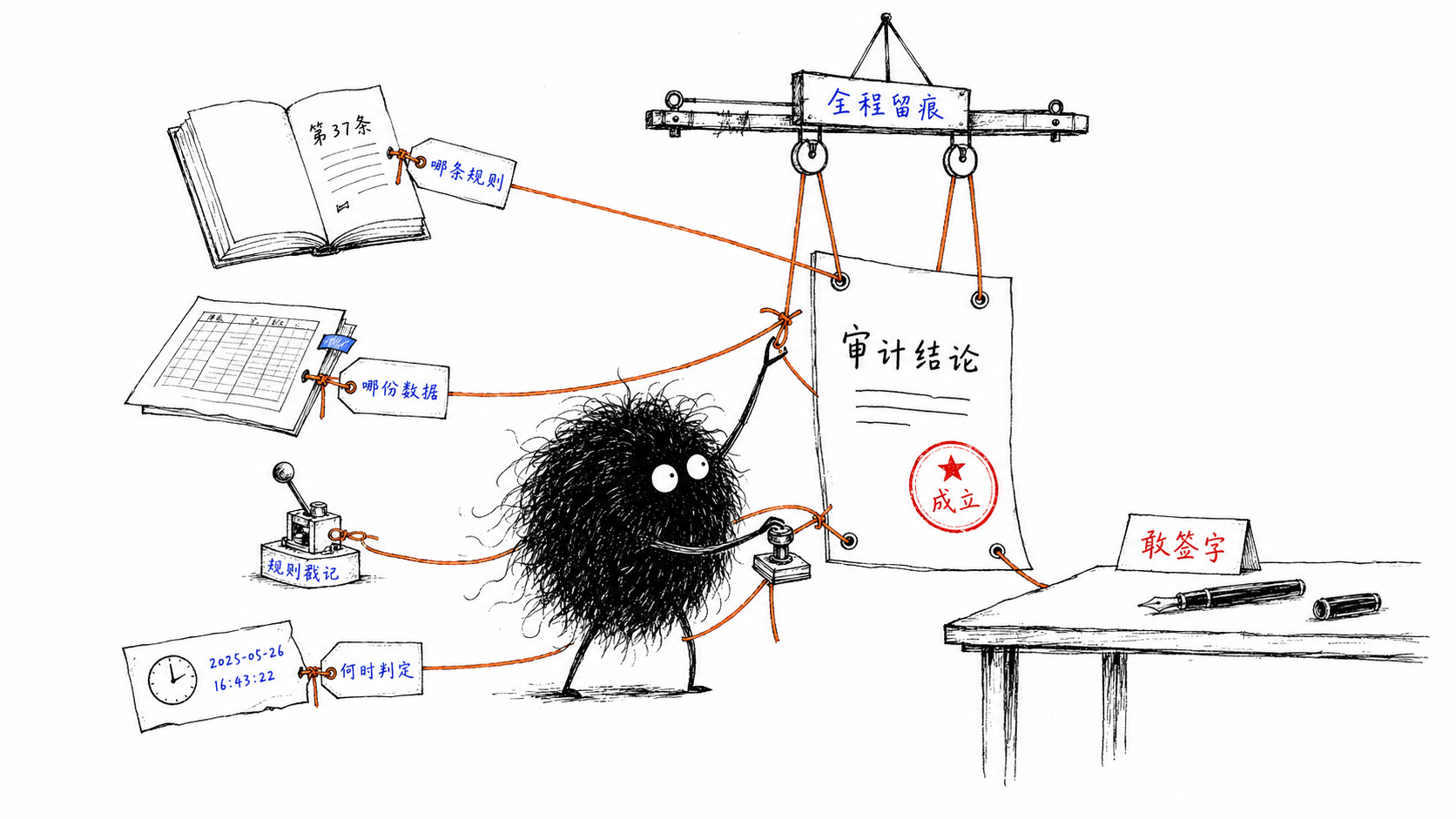
同一份结论,光是每次都一样,没用;它得能在被质疑的时候,把自己的依据一条条摆出来。能复现是手段,能追责才是目的。
这套东西交付的从来不是”一个很聪明的模型”,而是”一套敢让人签字背书的确定性流程”,模型只是这套流程最里层那个被严密看住的零件。
这才接得住前面那盆冷水。敌论者说得对,笼子本身那几样,解耦、校验、回退确实人人能搭。
但笼子里关的那套东西不是工程,是一个行业的规则、口径、判例,一条条沉进系统里的。
这堆东西,是拿一个个真实项目、一次次合规质疑喂出来的,对手就算照抄你的架构,也抄不走你攒了几年的场景。能复现的工程是地板,能追责的领域积累才是墙。
现在回到开头那个销售桌上的问题。
我见过 ToB AI 的演示,模型答得又快又漂亮,客户也确实眼前一亮。
可真正决定签不签的,往往是采购方一句平淡的追问:”同样这个问题,我下周再问一遍,能给我一模一样的数吗?”
他嘴上问的是可复现。他真正在买的,是”我敢把它写进工作流、敢拿它的输出去向我老板汇报”的那份底气。
底气从哪来?不是从”每次一样”来,是从”出了事我能查到是哪一步、依据是什么”来。客户说的是确定性,他买的是可追责性。这两个词之间的那道缝,就是整门 ToB AI 生意的所在。
那句”确定性即商业模式”,说到位了该是:可追责性,才是商业模式。
小结
回到最初那个问题:ToB 的 AI,卖的是更聪明的模型,还是可被追责的确定结果?
答案现在清楚了。模型的聪明是入场券,谁都拿得到。
客户真正付钱买的,是一套能在出事时摆出依据、敢让人签字的流程。
可复现、正确、可审计——这三件事里,前两件是地基,最后一件才是你和对手拉开差距的地方。
驾驭 LLM 的关键,从来不是把它变确定,而是用确定性的工程,把它的不确定性精准地关进该关的那个笼子里。
同时,把笼子没关住的那点抖动,读出来,当成它在向你报警。
确定性是入场券,可追责性才是护城河。
本文由 @巫师Sorcerer 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


