
 起点课堂会员权益
起点课堂会员权益LTV预估与留存曲线拟合:指数函数还是幂函数?
编辑导语:LTV,即用户生命周期总价值,是运营人员在业务过程中常接触的指标,通过对LTV的预估,运营人员可以为后续决策做好准备。本篇文章里,作者便针对LTV预估、留存函数拟合等问题进行了解读,一起来看一下。

一、从LTV预估开始说起
LTV的预估,是许多业务UE模型和增长模型的起点:
![]()
其中,用户生命周期又可以用累加的留存率来计算:
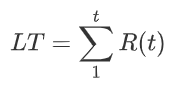
不过,这里面使用的留存率却未必是实际发生的历史数据。
因为我们做决策时往往等不了那么长的时间,所以我们一般使用的是根据前面一小段时间的数据拟合出来的留存函数R(t)。
那留存函数应该怎样拟合呢?
二、留存函数拟合
许多文章或资料会推荐这么一个方法:
- 把过去的次日、3日、7日、14日、30日等留存率记录在Excel中,画出来一个散点图;
- 然后点击图上的数据点,右键选择“添加趋势线”,这时右方就会出现可以拟合的曲线类型(指数、线性、对数、多项式、乘幂、移动平均);
- 打开显示公式和R平方项,在这些曲线类型和公式中,选择R方最接近1的那个(一般是指数或乘幂),即为最终拟合得到的留存函数R(t)。

番茄小说2021.05新用户留存率,QuestMobile
选择R方最接近1,意味着找到了拟合程度最高的函数作为留存函数R(t),接下来就可以回到LTV预估的主线去了。
不过这里有个小问题,却似乎鲜有人讨论过:为什么是指数或乘幂这两个函数?如果拟合的结果是这两个函数中的一个,意味着什么?它俩最核心的差异和联系在哪?
三、两个函数的差异
这两个函数有什么差异呢?如果光从函数本身看,指数函数和幂函数的核心差异在于衰减的速度。指数函数的表达式为:
![]()
幂函数的表达式为:
![]()
根据表达式我们可以推导出,如果以3天为一个周期,对于指数函数来说,留存率每三天会以同样的速度衰减:
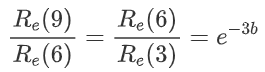
而对于幂函数来说,留存率衰减的速度会逐渐放缓,下一个同比例衰减周期会拉长到6天,即上一个周期的两倍:
![]()
我们总是希望留存率的衰减能够慢一些,所以相比之下,拟合成幂函数是更希望看到的结果。
四、艾宾浩斯遗忘曲线
那这两个函数有什么联系呢?1885年,德国心理学家艾宾浩斯(H.Ebbinghaus)首次对人类的记忆进行了定量研究,他用无意义的音节作为记忆的材料,通过记录一段时间后被试人员对这些音节材料的记忆留存率,绘制出了这样一个曲线:

这个曲线也被称为艾宾浩斯遗忘曲线(或记忆曲线),可以看到通过对这个曲线进行拟合,得到的拟合度最高的是一个幂函数。
不过后续人们的研究表明,单一的遗忘曲线实际上应该是更接近指数函数的,结合前面提到的指数函数的性质,说明人类会以一个固定的周期等概率地遗忘大脑中的信息,是一个很符合大自然规律的现象。
而艾宾浩斯之所以拟合得到了幂函数,是由于最初的记忆实验,混杂了不同难度的记忆材料,这种混杂改变了遗忘曲线的指数性质。
下面的这个例子,可以解释这一现象:

图中黄色和紫色曲线,分别代表两种难度记忆材料的遗忘曲线,它们都是指数函数y=e^(-kt),其中k的大小不同,代表难度不同;
而黑色的散点,则为两个函数的平均值(或可泛化为线性组合),通过对这些散点进行拟合,会发现一个有趣的事实:
某些情况下,对两个指数函数线性组合后的曲线,拟合度更高的(即R方更大的),却不再是指数函数了,而是幂函数!
这个有意思的现象,各位有兴趣的话,可以自行验证一下。
五、遗忘曲线与留存曲线
关于遗忘曲线的结论,对我们理解留存曲线有什么帮助吗?
事实上我们早就发现,这两个曲线惊人地一致。
如果把拉新激活的动作视为最初始的记忆训练,那么在后续的时间里,如果没有再次激活,用户就会以一定的概率,自然而然地遗忘我们的App,表现就和遗忘曲线是一样的。
为了让用户回到我们的App,提升用户留存率,我们通过各种push召回它们,这也和关于记忆的研究中,定期复习的方法如出一辙。
同时,和混杂材料带来的遗忘曲线类似,绝大多数功能丰富的成熟应用,留存曲线都应该是衰减程度更慢的幂函数。
事实上也确实如此,包括前面提到的番茄小说例子在内,我从QuestMobile验证了其他一些常见App,以及手头有的一些内部数据,它们的留存曲线的确都是拟合成了幂函数:

番茄小说、知乎与陌陌2021.05新用户留存数据,QuestMobile
六、对数函数与其他LTV预估方法
最后再补充两个点。
在前面的趋势线拟合中,有一个对数函数可能会是迷惑选项。
对数函数的表达式是:
![]()
随着t的增长,对数函数计算得到的结果很可能会小于0,而不是像指数函数和幂函数一样始终保持大于0的结果。
小于0的留存率是没有意义的,因此如果最优拟合的结果是对数函数,更可能的情况是巧合或者样本量太小,对数函数在这个场景下本身没有合理的物理意义。
不妨在指数函数或者幂函数中选择一个,他们的拟合度离最优拟合应该差不了多少。
而对于最开始提到的LTV预估公式:
![]()
需要说明的是,这里面隐藏了一个假设:ARPU值恒定不变,是个常数。
但在现实情况下,这样的假设往往会带来一些误差,因为随着留存时间增加,这部分用户的ARPU总是会随之有所变化。
一种调整的方法是对ARPU同样进行预估,将公式改造为:
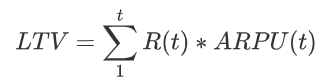
不过ARPU的变化规律可能很难找,或者压根就没有像留存曲线这样简单清晰的规律。
因此另一种调整方法是不做拆分,用更多样本数据和特征数据,整体地对用户贡献价值进行函数拟合预估:
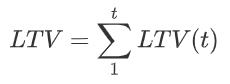
这样的方法需要足够多的样本,本身也更适合需要精细化的运营场景,这里就不再展开了。
参考资料:
[1] https://supermemo.guru/wiki/Exponential_nature_of_forgetting
[2] https://supermemo.guru/wiki/Forgetting_curve
作者:青十五;公众号:青十五,新书《策略产品经理:模型与方法论》作者
本文由 @青十五 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。









mk
很有意思~