
 起点课堂会员权益
起点课堂会员权益如何七周成为数据分析师12:解锁数据分析的正确姿势(上)

本文是《如何七周成为数据分析师》的第十二篇教程,如果想要了解写作初衷,可以先行阅读七周指南。温馨提示:如果您已经熟悉统计学,大可不必再看这篇文章,或只挑选部分。
当获得一份数据集时,你会怎么做?
立马撩起袖管进行分析么?这不是一个好建议。无数的经验告诉我们,如果分析师不先行了解数据集的质量,后续的推断分析是事倍功半的。
正确的处理方法是先使用描述统计。
什么是描述统计学
它是一种综合概括数据集的方式,包括数据的加工和显示,数据集的分布特征等。它与推断统计相呼应。
在进入统计学习前,先明确基础概念。
数据可以分为分类型数据和数值型数据。分类型数据是识别变量的类型,比如男女、地区、各种类别;数值型数据是表示数值的大小和多少,比如年龄中的18、19、20岁。
最明显的区分是,分类型数据不能使用加减法,而数值型数据可以。两者在一定程度可以互相转换。比如年龄,18岁是数值型数据,但它也可以转换成分类数据「青少年」。我们也能用数值表示分类数据,比如0代表女,1代表男,它依旧没有计算意义,更多是方便计算机存储而已。
分类数据和数值数据的具体应用,会在往后的学习中继续深入,本文先将主要精力放在数值型数据。
数据的度量
平均数是一种数据位置的度量,用以了解整体数据,这是小学就学到的内容。可是平均数并不是一个权威的衡量指标,当我们提到全国平均工资的时候,我们都是被马云爸爸王健林爸爸平均的普通人。
平均数容易受到极值的影响,因为数据集并不能保证「干净」,各类运营数据经常受到扰动,比如薅羊毛党就会拉高营销活动的平均值。一般而言,可以用调整平均数(trimmed mean)消除异常波动,在数据集中删除一定比例的极大值和极小值,比如5%,然后重新计算平均数。
它既然不靠谱,我们便请出中位数。将所有数据按升序排列后,位于中间的数值即中位数。当数据集是奇数,中位数是中间的数值,当数据集是偶数,中位数是中间两个数的平均值。这也是小学的内容。
另外一种度量是众数,它是数据集出现频次最多的数据,当有多个众数时,称为多众数。众数使用的频率低于前两者,更多用于分类数据。
平均数、中位数、众数构成了标准的衡量方法。但是还不够。
数据分析师常将数据划分为四个部分,每一部分包含25%的数据集,划分的分割点叫做四分位数。
依次将数据升序排列,位于第25%位置的叫做第一四分位数Q1,位于第50%位置的叫做第二四分位数Q2,即中位数,位于第75%的叫做第三分位数Q3。这三个点,能辅助衡量数据的分布状态。
数据的离散和变异
我们考虑一个新的问题,现在一家电商公司要卖两个同类型的商品,它们的一周销量(单位:个)如下:
- 商品A:10,10,10,11,12,12,12
- 商品B:3,5,6,11,16,17,19
它们的平均数一样,中位数也一样,可它们的真实情况呢?当然不。作为商品,我们更喜欢销量稳定的。
方差是一种可以衡量数据「稳定性」的度量,更通俗的解释是衡量数据的变异性,从图形上说,也叫离散程度。
方差的计算公式是各个数据分别与其平均数之差的平方和的平均数。
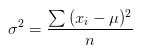
上述公式是总体数据集的方差计算,当数据近为部分抽样样本时,n应该改为n-1。数据集足够大时,两者的误差也可以忽略不计。
现在计算上文商品的方差。Excel中的方差公式为VARP( ),如果是样本数据,则为VAR( )。不同Excel版本,函数会有微小差异。
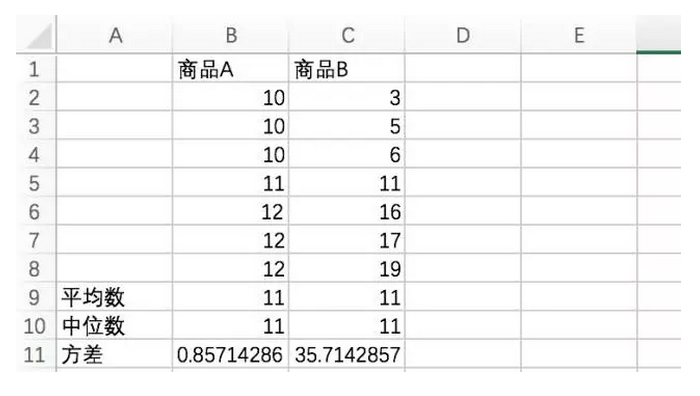
方差越大,说明数据集的离散程度越大,商品A的销量波动明显比商品B稳定。方差的计算中,因为涉及到了平方和,所以单位的量纲是平方(商品A和B的方差,单位为个^2),它很难有直观的诠释。于是我们又引入标准差。
标准差是方差的开平方:
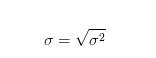
Excel中,标准差的计算函数为stdevp( ),如果是样本数据,则为stdev( )。
方差和标准差的意义是相同的,但是标准差与原始数据的单位量纲相同,它更容易与平均数等度量比较。比如商品A的平均销量为11个,标准差为0.85个,于是我们知道这个商品卖的比较稳。
切比雪夫定理指出,至少有75%的数据值与平均数的距离在2个标准差以内,至少有89%的数据与平均数在3个标准差之内,至少有94%的数据与平均数在4个标准差以内。这是一个非常方便的定理,能快速掌握数据包含的范围。
假设上海地区的平均薪资是20k,标准差是5K,那么大约有90%的薪资,都在5k~35k的区间内。
如果数据本身符合正态(钟形)分布,那么切比雪夫定理的估算将进一步准确:68%的数据落在距离平均数一个标准差内,95%的数据值落在距离平均数2个标准差之内,几乎所有的数据落在三个标准差内。
在Excel中,有一个重要的工具叫数据分析库(部分Excel版本需要安装,自行搜索),里面封装了大量的统计工具。
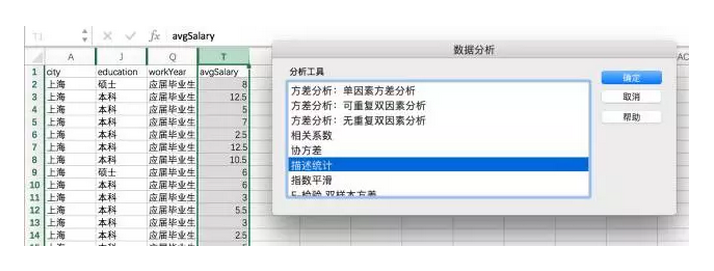
点击描述统计,选择需要计算的区域,设置为逐列,输出区域选择旁边U2区块。输出计算结果。
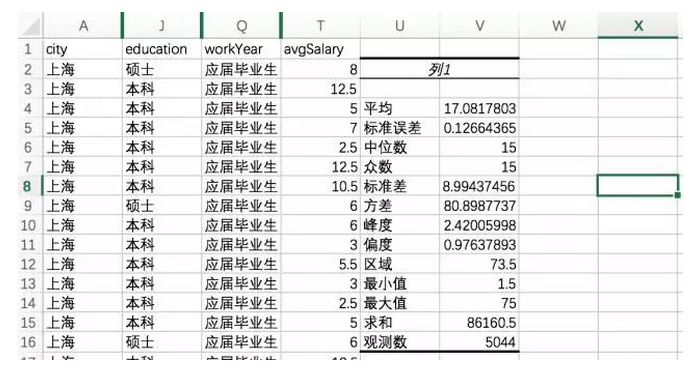
列1的所有内容,均属于描述统计中的各类度量。我们不用一个个函数去计算了。
方差和标准差是重要的概念,在后续的统计学中将继续出现。
数据的箱线图
回到度量,上文提到的内容,都属于数值类的方法,可它们还是不够直观。
先汇总五类数据:最小值、第一四分位数Q1、中位数、第三四分位数Q3、最大值。
拿数据分析师的薪资数据作案例。

以上是清洗后的数据。我们用Excel函数计算这五个度量。分别是median( )、max( )、min( )、quartile( )。按城市区分。
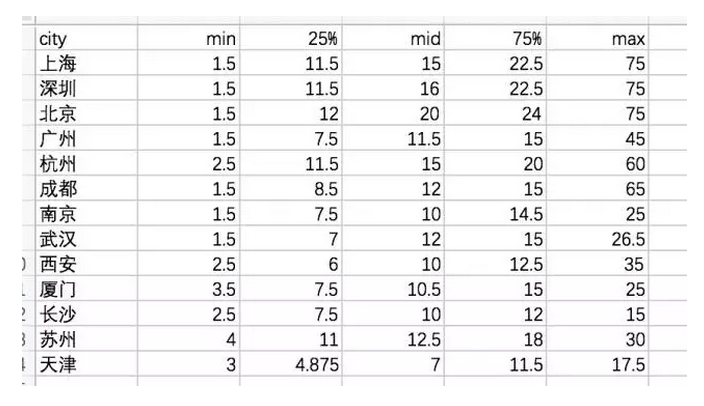
通过数据,现在可以了解各城市的数据分析师薪资分布了,接下来把它们加工成箱线图,它是最常用的描述统计图表。
箱线图通过我们求出的五个数据确定位置。
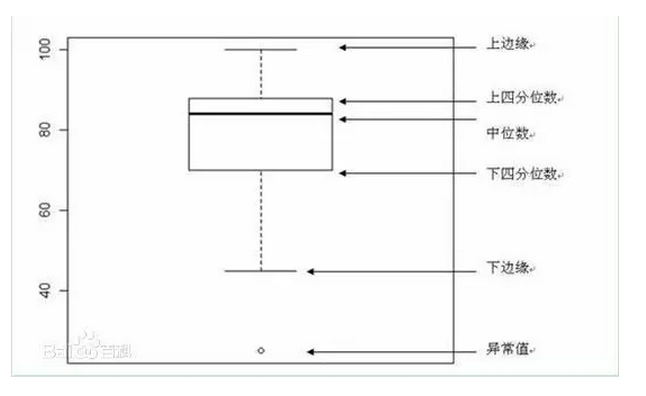
箱线图的上下边缘分别是最大值和最小值(实际不是,这里为了方便,先这样理解),箱体的上下边界则是25%分位数和75分位数。箱内横线是中位数。异常值是箱线边缘外的数值,需要直接排除。
Excel2016可以直接绘制箱线图,如果是早期版本,有两种作图思路。
第一种,是利用股价图。将图表按25%分位数、最大值、最小值、75%分位数的顺序排列。

然后直接生成图表:
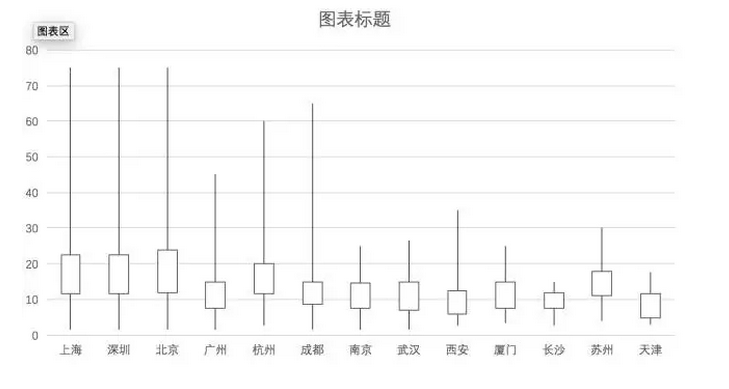
这个图表是没有中位数的,中位数需要添加上去。数据源新建一个系列,该系列应该调整到位于数据源的中间位置。
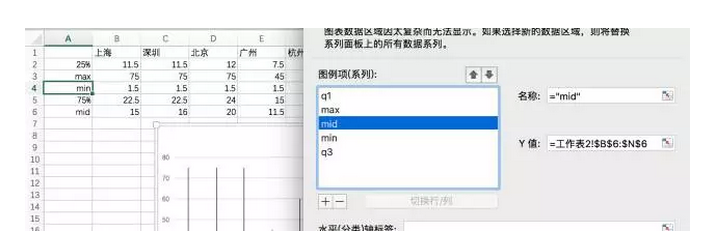
选择中位数的数据系列格式,更改标记为「-」,大小为12榜,颜色为黑色。此时就有箱线图的雏形了。
另外一种思路是利用散点图的误差线绘制,和甘特图的原理一样,大家自己练习吧。
其实从图表中看到,虽然我们描绘出了箱线图,但是不同城市的数据区别并不直观,因为最大值撑高了箱线图的边缘。我们经常会遇到这些影响分析质量的异常值(过于异常的数值虽然存在合理性,但是很多分析必须移除掉它们)。我们需要清洗掉这批异常值。
定义四分位差IQR=Q3(75%分位数)—Q1(25%分位数),箱线图的界限在(Q1-1.5IQR,Q3+1.5个IQR)处。界限外部所有值均为异常值。
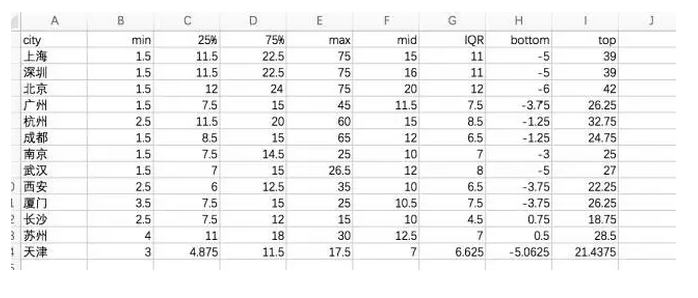
bottom和top就是新的界限,对于在界限外部的数据,均认为是异常值。界限内部的数据则是箱线图的主体,接下来找出界限内的最大值和最小值。比如上海的界限是-5~39之间,而界限内的数据实际范围为1.5~37.5,那么就以1.5~37.5绘制箱形。
现在大家求出了真正的五个度量,可以重新绘制箱线图(我们要用bottom和top求出范围内新的最大值和最小值)。为了方便演示,我直接以Python生成(以前教过的BI也行,更好看)。
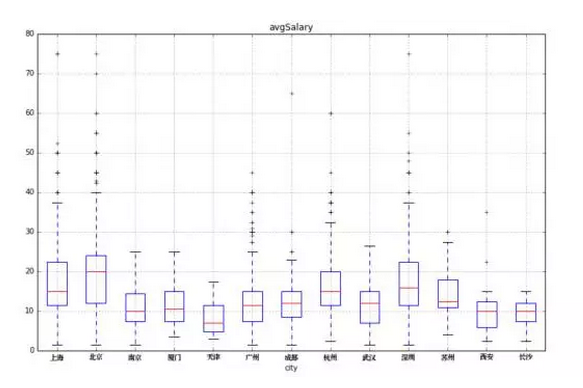
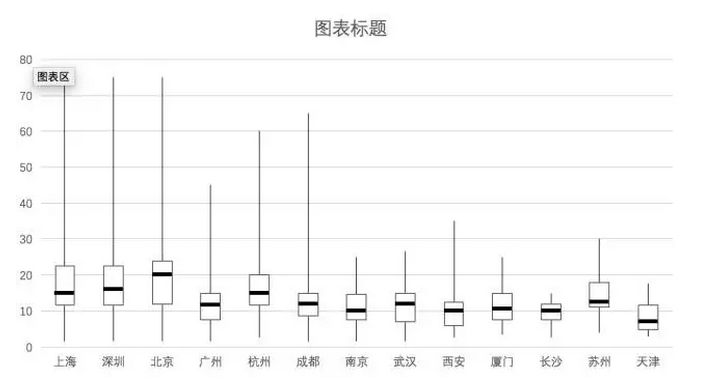
比Excel绘制的图直观多了。红线位置,是各个城市中游水平的数据分析师能够获得的薪资标准,上边的蓝线区间为中上游,下边的蓝线区间为中下游,以此类推。简而言之,人群被四等分了。
我们解读一下:上海、北京、深圳的数据分析师,薪资范围接近,但是中上游水平的人,北京地区能获得更高的薪资,因为中位数的位置更高。西安、长沙、天津则不利于数据分析师的发展。杭州的水平接近北上深,但是薪资上限受到一定限制。
这张图能一眼看出不少内容,想必大家已经明白箱线图的作用了,它能读出数据的整体分布和倾斜趋势(偏态)。
通过图表(直方图、散点图也算描述统计)快速解读数据,是数据分析师的基础能力之一。
大家想一下,如果是O2O的数据分析,能不能快速判断各城市的业务状况?如果是金融,能不能划分人群看它们业务之间不同的分布?如果是电商,不同类目的营销数据会有大的差异吗?再配合不同的维度细分,发挥的价值大着呢。
箱线图是一种非常优秀的图表。虽然在Excel中会繁琐一些(赶紧更新到2016),但是在Python和R语言,也就是十秒钟的操作时间。
相关阅读
如何七周成为数据分析师01:常见的Excel函数全部涵盖在这里了
如何七周成为数据分析师:Excel技巧之甘特图绘制(项目管理)
#专栏作家#
秦路,微信公众号ID:tracykanc,人人都是产品经理专栏作家。
本文由 @秦路 原创发布于人人都是产品经理。未经许可,禁止转载。

















超级无敌好
写的很好,但是图挂了~
我们用Excel函数计算这五个度量。分别是median( )、max( )、min( )、quartile( )。按城市区分。这步骤有快捷一点儿的么?
啦啦啦
啦啦啦
学习了!大学时候学的统计学 全还给老师了。。