
 起点课堂会员权益
起点课堂会员权益数据分析能力的核心是思维

对于业务人,比如产品或运营,数据分析能力的核心不在方法和工具,而在于思维。
- 大多数人错误地理解了数据分析,把数据分析能力提升的关键放在了方法和工具;
- 对于业务人而言,数据分析的核心思路是,得到两个变量之间的「量化关系」,用以解释现象;
- 数据分析的步骤,感知问题、提出假说、选择表征、收集数据、分析验证;
- 提出假说和选择表征是很多业务人数据分析做不下去的原因。
数据分析的方法崇拜
在和团队小伙伴分享的的时候,发现一个问题:
我问,你怎么看数据分析能力?如何评价自己的数据分析能力?
大家的回答主要是这样的:
运营是基于数据驱动的,但是拿着很多数据,不能分析下去,主要是对于excel的一些陌生的公式、函数都不太会,我要专门去学一下excel
我感觉导致现在转化率低低原因是xxx,最近接触到很多用户都是这么反馈的,但还没有找到好的分析方法
产品的数据分析能力还是很重要,我想去学个R,能够去构建量化模型
……
以上,我觉得太在意数据分析方法和工具,我觉得都还没有把握住一个业务人数据分析能力的核心。
业务人考虑的最重要的问题是,业务结果到底怎么样,出现了什么问题,原因是什么,可能的解决方案是什么。
数据分析只是手段,它的误区就是,太在意方法和工具。
而最缺少的,恰恰是最重要的思维。
数据分析的本质
数据分析最重要的思维就是,不断确定业务中两组变量之间的关系,用以解释业务。
收入、转化、用户规模、用户活跃等,我们称为现象。而只有通过数据量化的现象,我们才能精准感知。所以,数据是用来描述现象的,是被量化的现象。这就是数据统计在干的事情,比如建立数据漏斗,严格意义上这就是数据统计。
而数据分析,就是寻找这些被量化的现象之间的「关系」。这个关系就是y=f(x)。找到两个变量之间的关系,多找到一种这样关系,在实践中,就多一种有效手段。
所以,在数据处理层面,有这样两个方式:
- 数据统计——利用数据体现现象,比如建立数据漏斗
- 数据分析——利用数据寻找现象关系,比如城市特征和活跃之间的关系
本文核心是围绕数据分析进行展开。
比如,做社群运营的同学,常常会想,到底什么因素在影响用户的活跃度。在实践的过程中,我们感觉到,不同的进入社群的时间点可能是活跃度比较关键的影响因素。于是,尝试通过数据定义,确定x=进群时间点与开群的时间差,y=第一月活跃率。我们将x变量按天为单位氛围不同类别,得到了以下的关系:
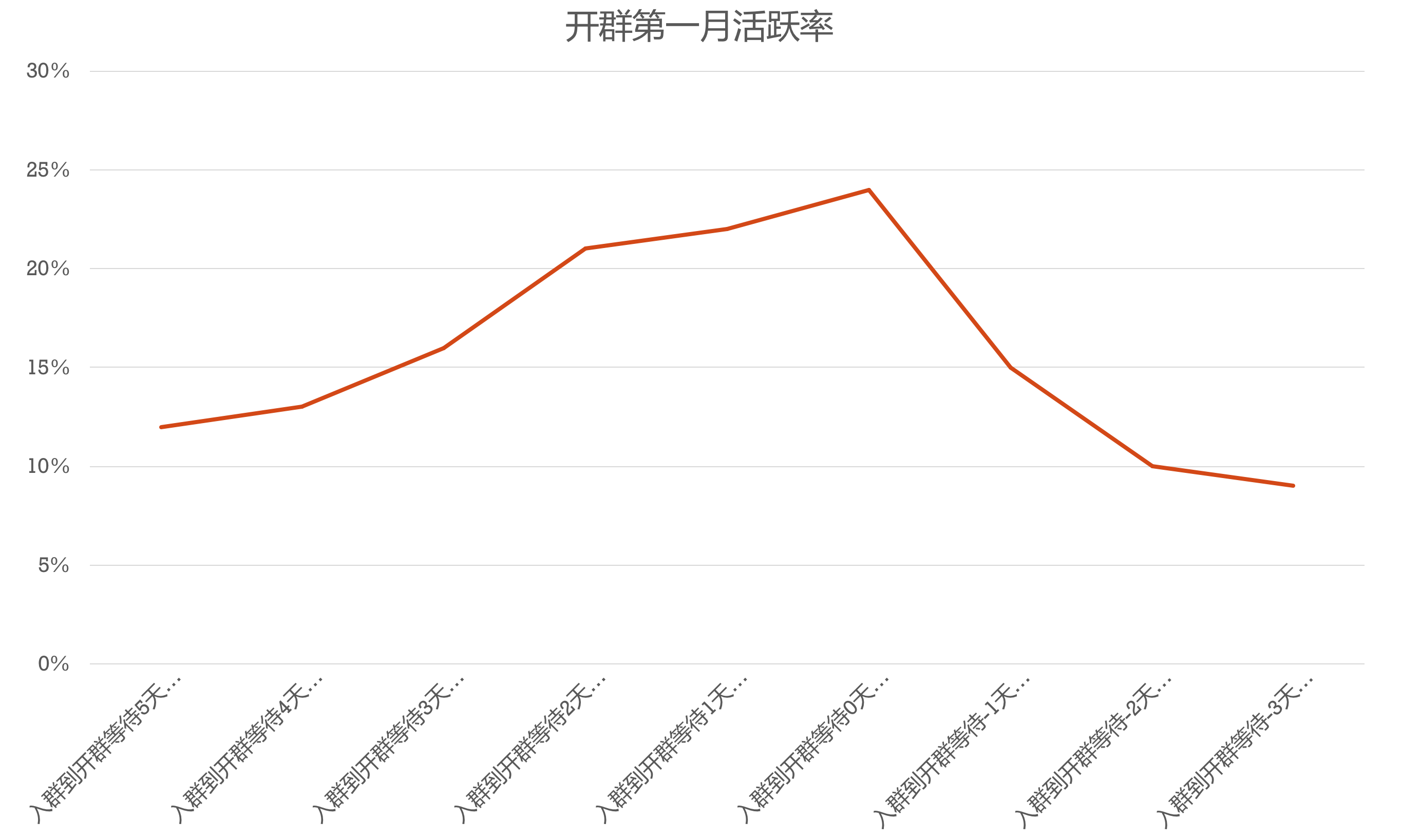
*x变量每类样本N>50,且基本是同一时间的社群,排除了其他因素影响
当我们得到以上图示的关系其实足以指导我们的工作了——做社群运营,尽量做到及时开群,不要让用户等待,消耗热情。
所以,数据分析最重要的思维就是,不断去寻找可能与业务结果有关的变量,确定这两个变量之间的关系。多确定了一种关系,就多了一种手段,少了一些瞎干。
要做到这些,excel的基础功能,妥妥解决。通过统计学方法回归分析出一个量化模型或论证其信效度。
因为,对于大部分业务而言,动作的精度有限,所以不需要分析的精度太高,同时,统计方法的量化模型无法用业务逻辑进行解释,只能预测,对于实操类业务意义不大。
业务中数据分析的一般方法
前面简单说了数据分析的方法工具误区和数据分析核心是要去寻找两组变量之间的关系。
那在业务中,如何进行有效的数据分析。我将数据分析归纳为以下五个步骤:
- 第一步,感知问题
- 第二步,提出假说
- 第三步,选择表征
- 第四步,收集数据
- 第五步,分析验证
第一步,感知问题
如果没有问题,是不需要数据分析的。
但是,那是不可能的。KPI总是差点才达到,即使达到了,领导还会问你,就不能做到更好吗?
在业务中的问题有这样两种,一种是直接找最终结果的问题,比如收入比不上竞品,DAU下降了10%等;一种是环节上的问题,拆解漏斗和业务环节,比如通过分析app数据漏斗,发现每日使用一次人数相对于每日打开人数相对于流失了30%等。
记住这样一句话,但凡有差异,必有问题,但凡有问题,必要寻找原因。
这一步困难的不是有没有问题,差距、不足总是在那里。困难的是,能不能找到最重要,也就是最和业务结果相关的问题,优先级排序是关键。
而排序的关键就是,基于最重要的结果或KPI的标准进行排序。不断思考一件事,解决了这个问题能够对结果有多大的改善?
第二步,提出假说
找到问题,下一步就是找方法解决。
在管理咨询界有个说法,叫作不要煮沸海洋。说的是,把所有的,可能导致问题的因素全部找出来分析一遍,那是低效也是不可能的。
所以,这里就需要使用到「假说」的方法。
哪些因素可能影响到收入?哪些因素会导致打开app的人不使用任何功能直接离开?
找到以上问题可能的答案的过程,就是提出假说的过程。
这里有两个路径用来提出假说,一个是归纳的方式,一个是演绎的方式:
什么是归纳式的,就是根据个案进行总结。比如在收入可能的影响因素的时候,我会找所有相关工作人员进行头脑风暴,提出可能的因素;也会对分层的用户进行抽样深读访谈,了解他们购买或不购买的原因及其他看法。
什么是演绎式的,就是根据模型进行推演。比如在app打开不使用直接离开,我们可以根据对用户行为模型的理解进行拆解,而拆解的有效与否,其实就是关于你模型多少、深度。
结合归纳式和演绎式的方法,我们会得到非常多的可能与结果相关因素。进行整理,并进行重要性排序。
到这里,我们就找出很多可能、未经确定、未经量化的y=f(x),也就是一对对可能有关系的变量。
第三步,选择表征
不可被数据量化,就不能被改变。如前文所说,数据分析,需要将现象量化,得到可以分析的数据。
所以,需要将提出的假说中所选择的变量,用数据来进行表征。
在入群时间点对用户活跃度影响的例子中,我们将入群时间点(x)定义为:入群时间与开群时间差;将活跃度(y)定义为用户从进入起一周的活跃率,即一月内活跃天数的占比。
在选择数据表征元素的时候,需要把握的原则就是:
- 选择的数据能够充分代表假说中变量的内涵;
- 选择的数据尽量是用户客观行为数据而非主观态度数据;
- 选择的数据是有被记录或容易获取。
第四步,收集数据
互联网的很大优势就是数据驱动的,数据往往是被有效收集的。
但是,也存在数据没有被记录情况。支持产品功能的数据,会被记录,但是很多行为数据只能通过调取接口数据或埋点的方式进行记录。这就需要业务人能够提前规划所需数据,让工程师将数据记录在库。
在收集数据的过程中,需要注意到就是有效数据量不能太小。
第五步,分析验证
反倒是,分析验证这个步骤变得不是那么核心的步骤。
确定好了x与y的含义和数据,剩下的分析就很简单了。通过数据可视化的方式,表现出x与y的关系,就能发现其中是否存在有价值的规律。
发现x与y存在某种关系的时候,最好通过数据进行再次验证。选择另外一组数据,再次进行分析,看确定的关系是否再次被复现。
当然,最重要的验证是在业务实现中体现。
数据分析,一种必备能力
数据分析,是认识事物的重要方式之一,它的特点是定量的非定性的、过去的非未来的、相关的非因果的,有其适用范围,但一定是所有业务人必须掌握的能力。
对于业务人,不用太崇拜于方法和工具,首先需要锤炼分析思维,寻找两个变量的关系,真正指导业务才是关键。
而在分析的过程中,「提出假说」和「选择表征」是关键所在,也是很多业务人没有能够作出有效分析的关键所在。
本文由 @个家 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Pixabay,基于 CC0 协议








你好,文章是很不错的,但是看完结合我自己自身的数据分析,产生了一个疑问,想请教下作者。
提出假说部分,给出的(y)和(x)都是非常明确的单一变量,但是在业务分析中,很可能会遇到自变量的情况。
比如想探究用户付费率(y)和产品试用领取情况(x)之间的关系,此时的(x)就是自变量,(y)就是因变量,需要通过两者之间的关系来验证。比如领取试用的用户付费率是10%,没有领取试用的用户付费率是5%,以此说明(x)对(y)有促进作用。但是这种分析方式无法剔除领取试用这一用户客观行为是否存在主观性(即领取试用可能本身存在较强的付费倾向)
想问的内容是:
1.上述情况是否和本篇文章宗旨相悖?
2.如果相悖,那么针对上述情况,该如何提出假说、选择表征?
以上,望作者不吝赐教,感谢🙏
感谢你的问题,不常上这个平台,回复慢了。
你说的情况与文章的思路并不相悖,但是文章中对于这种类型的变量关系并没有深入探讨——
你举的例子,本质上是付费率与试用领取情况是相关关系,并非因果关系。即愿意付费和愿意领取试用的用户可能都是对于这类产品有需求,付费和领取试用是这个因导致的两个结果,这两个结果是相关的。但也不一定是这样的,用户可能是因为试用而导致了对于产品更多了解,更大需求,从而付费。所以,这个时候需要通过A/B测试来确定其关系,如一组自然转化,一组增加领取试用的转化,看差异。若试用组有明显的优势,那么你需要判断的是,当前提升试用比例是不是一个关键动作,若是,那么你需要找试用的影响因素,比如触达、比如包装、比如试用周期等等,又进入新的一轮分析中。
但是,不管怎么说,多提取出一组y=f(x)对于理解业务都是有价值的,比如你发现了领取试用和付费之间有一定的关系,那么你就会去探究到底这个是不是因果性的或者及时其是相关性的,你可以将它当做一个观测指标来提前预测付费结果。
不知道是否能够回答你的问题,可继续探讨,一起进步。
“定量的非定性的、过去的非未来的、相关的非因果的” 笔者这段话让我着实困惑。
数据分析是一种定量分析方法,而非定性分析方法;
数据分析是针对过去的历史数据/现象进行,而非针对未来的未发生的现象进行分析;
数据分析寻找的是数据之间的相关关系,而非因果关系。相关关系和因果关系是存在很大区别的
感谢吴晗帮助回复,很赞同你的看法。另相关和因果上面一条评论中多少涉及。
起点学院专门为0基础的0-2岁互联网人开设了《15天入门互联网数据分析》班级哦~课程由数据思维+真实案例+实操相结合,提升你的数据分析能力!戳此了解>>http://996.pm/YNG4e
赞同
数据分析是为了验证,不是为了分析去分析的!
看完之后对数据分析有了学习的方向,期待看到更多数据分析的文章哦!
分析工具是可以在短时间内学习的,重要的还是分析的方法和思路~思想起飞才重要
学习分析的方法和思路,有推荐的学习教程吗
我个人经验,供参考。1、和君系单其武老师的其来有自,比较实战,学理上不一定严谨;2、学术派(其实也是和君系)的阳志平老师的开智学堂,学理严谨,需要重功夫。这是个人测试不错的课程。如果自学的话,其实多看两本方法论的书就会有帮助
看了前几段就想留言,讲到点上了!
哈哈,有机会探讨
“要做到这些,excel的基础功能,妥妥解决。通过统计学方法回归分析出一个量化模型或论证其信效度”请问一下,如何通过excel实现一个回归分析的模型?
很抱歉,你引用的那段文字我可能没有表达清楚。在业务解释的过程中,建立统计分析模型的意义并不一定特别大,而是直接通过可视化的方式观察X变量和Y变量是否有相关性,描绘成曲线即可,就可以联系上直接业务,对于普通业务型,不需要高精度预测的业务,相关性就能指明问题。当然,如果要用Excel直接做回归也是可以的,“工具-数据分析-回归”
很赞,如果可以落地使用就更好了
期待什么样的内容算落地? 🙂
应该是说的有 case的那种
写的很棒,期待您能再写1篇关于数据统计的文章
OK,这几天写一下,一起交流一下
😯