
 起点课堂会员权益
起点课堂会员权益当我们在做数据异常分析时,我们在分析什么

数据异常分析,是数据分析工作中最常见且重要的分析主题,本文总结了数据分析的一般过程和方法,希望后续的分析在此基础上不断优化。
一、背景
数据异常分析,是数据分析工作中最常见且重要的分析主题,通过一次次的异常分析来明确造成数据波动的原因,建立日常的的运营工作和数据波动之间的相关性以及贡献程度的概念,从而找到促进数据增长的途径,改变数据结果。
本文总结了数据分析的一般过程和方法,希望后续的分析在此基础上不断优化。
二、问题界定
收集到的数据分析需求可能是类似于转化率最近在下降,询盘量有点上升。这种描述,其实并没有把问题界定与描述清楚。首要便是对数据波动进行界定,如果问题没有界定清楚,后续的数据分析也就失去了价值。
问题界定需要解决以下疑问,判断数据波动是否为异常?异常的范围、波动的程度,是否需要深入分析?
数据异常判定的理论基础如下:假设指标服从均值为μ和标准差δ的正态分布,处于(负无穷大, μ-3σ] 和[μ+3σ, 正无穷)范围时,样本的概率为0.26%,这是一个小概率事件,我们称其为3倍标准差下的异常点。
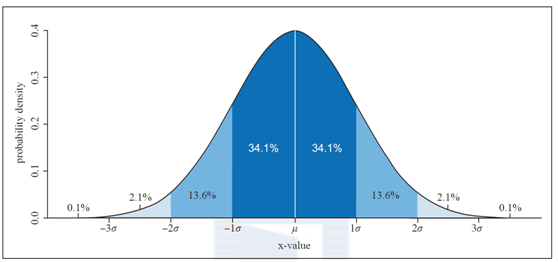
正态分布图
如果指标的样本数据为k 个,并记录为x1,x2,x3,…,xk,则阈值的计算步骤如下:
- 计算指标平均值,公式如下:x =Σxi/k;
- 计算样本的移动极差,公式如下:MR=|Xi-Xi-1|;
- 计算移动极差均值(k 个样本数据产生k-1 个移动极差),公式如下:MR =ΣMRi/k-1;
- 计算CL,公式如下:CL = x;
- 计算UCL 和LCL(在3 倍标准差情况下)。公式如下:UCL= x +3×MR/d2;LCL= x -3×MR/d2,其中d2 等于1.128。
超过UCL和LCL的则为异常,如果数据有明显的周期性和季节性,需去除相关因素之后再利用以上办法计算阈值。
三、问题分析
分析方法为基准对比分析,选取数据变化前后可对比的时间段进行对比。
3.1 明确引起指标异常的相关指标
分析思路为先对异常指标进行拆解,确保指标拆到最细粒度的原子指标,然后评估相关的指标的影响程度。
1)指标拆解方法
拆解的方法为杜邦分析,示例如下:
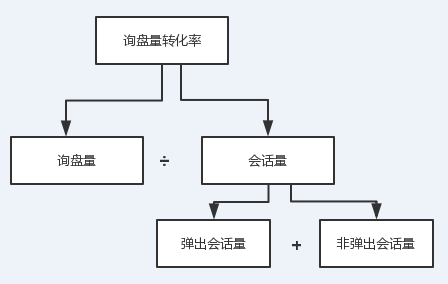
相关指标拆解示意图
2)贡献度的衡量
将变化的量分解到相关的最细粒度指标,对比前后2个时间段上最细粒度指标的变化,明确是哪一个指标的波动对这个指标的波动贡献度最大。比如:询盘量转化率上升,而询盘量转化率=询盘量/会话量,细分转化率的上升是询盘量的上升导致还是会话量的下降导致,各自贡献的比例为多少?
询盘转化率的波动=询盘转化率2-询盘转化率1=询盘量2/会话量2 -询盘量1/会话量1
假设在询盘量不变的情况下:
会话量对转化率的波动贡献=询盘量1/会话量2 -询盘量1/会话量1
假设在会话量不变的情况下:
询盘量对转化率的波动贡献=询盘量2/会话量2 -询盘量1/会话量2
3.2 单指标多维度的分析
能在一个指标能拆分成的多层树状结构中,具体是哪一层的哪一个节点的波动对这个指标的波动贡献度最大?比如:以询盘量的上升为例,可以如下进行拆分。
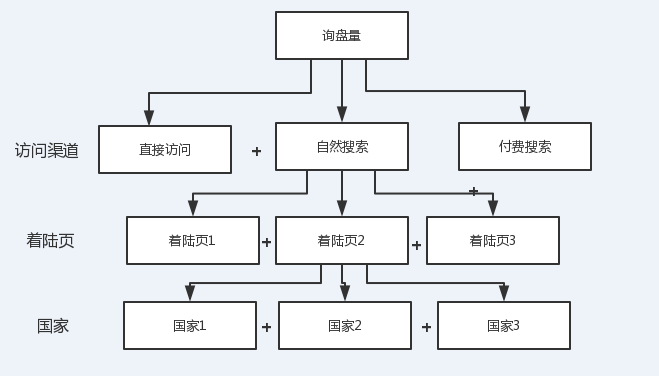
细分维度拆解示意图
3.3 明确波动的原因
在数据现象明确之后,需要对数据进行一定的推理,得出明确的结论。在逻辑推理过程中,需做到推断合理,避免常见的错误。
错误1 :相关性的误解
案例:发现人智力水平和胳膊长度 的统计数据中,发现人智力水平和胳膊长度是正相关的,胳膊长人,智力也一般比较高!
启示:相关性并不能表明因果系。上述数据的统计范围是从不足1岁的孩子,到完全长成岁的孩子到完全长成 年人。在成长过程中,体型会逐渐变大智年人。在成长过程中,体型会逐渐变大智年人。在成长过程中,体型会逐渐变大智力也会逐步发展。
错误2: 缺失对比对象
案例:某药厂推出了一款新感冒,配有说明药广告厉害的语:“临床显示, 本药品可以在 10 分钟内杀死 5万个感冒病 毒!”
启示:乍一看好像很有道理,感冒药好像很厉害,但是如果我们拿到了更多的比较数据,如“人一次感冒会产生5亿个病毒”或“其它药厂的感冒药至少可以在10分钟内杀死100万个病毒”,那这个新感冒药的效果不是低劣的可笑吗?
错误3:基于个案来推总体
案例:一个朋友有吸烟的习惯,以往每次劝他戒烟的时候,他都振振有词的说:“你看名人A吸烟活到80多岁,名人B不吸烟不喝酒却很早就去世了。所以寿命这种东西,和吸烟不吸烟么啥关系。”
启示:无论一个人是否吸烟,均可能过早去世,也可能活到高寿。但从大样本的数据来看,吸烟人群的寿龄普遍比不抽烟的整体减少5岁。下论断要从统计整体上来看,揪住一些个案没有太多意义的。
在避免常见的逻辑错误的同时,也要敢于下结论,虽然结论有可能是错的。
三、解决方案
数据分析的终极目的是对业务改进产生价值,基于此,分析结论之后一定要提出切实可执行的方案,即落地到业务和产品上的具体建议,确保方案可执行,效果可评估。
分析报告完成之后,一定要多与业务部门进行沟通,收集反馈,听取他们需要的是什么?一起商讨解决方案。作为分析师也要不断反馈自己,如何改进才能更有效的与业务结合?
四、总结
本文总结了分析的过程,包括如下内容:
- 问题的界定,界定数据异常的方法。
- 问题的分析,关键在于从指标和维度2个角度进行拆解,以及从数据到结论的推理。
- 结论的推动执行,与业务沟通反馈分析结论,探讨后续方案的执行。
本文由 @时之沙 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CCO协议









你好,请问为什么剔除异常点时要算极差均值而不是用平均值±3倍标准差呢
请教下多维度分析里,维度的顺序是怎么定的?
比如:询盘量转化率上升,而询盘量转化率=询盘量/会话量,细分转化率的上升是询盘量的上升导致还是会话量的下降导致,各自贡献的比例为多少?
询盘转化率的波动=询盘转化率2-询盘转化率1=询盘量2/会话量2 -询盘量1/会话量1
假设在询盘量不变的情况下:
会话量对转化率的波动贡献=询盘量1/会话量2 -询盘量1/会话量1
假设在会话量不变的情况下:
询盘量对转化率的波动贡献=询盘量2/会话量2 -询盘量1/会话量2
————————————————————-
▋请教下:
1. 为何第1个询盘量不变不变的时候, 是询盘量1不变? 而第2个会话量不变的情况下, 确实会话量2不变?
怎样才能看得懂这篇文章呢?
成为一个稍微厉害点的数据分析师的时候
sorry,那还是我写的不够清楚,没有让你明白。
不是不是,是我不够厉害~