
 起点课堂会员权益
起点课堂会员权益下一位数据分析师,可能不是数据分析师——体验Amazon SageMaker Canvas有感
编辑导语:当机器学习概念与数据分析场景相碰撞时,会产生什么样的“火花”?也许,用户可以更加便利地清洗、筛选数据,进行数据洞察,并创建预测模型。本篇文章里,作者结合Amazon SageMaker Canvas这款0代码机器学习智能工具进行了体验测评,一起来看看吧。

一、前言
我虽然不是数据分析师,但是因为工作及爱好的原因,经常需要做一些数据的分析。
以前我分析数据的时候,都是先去数据库写一段长长的SQL查数据,问题简单的就加多几段SQL简单分析完毕;复杂一点的就下载回来用Excel公式+透视图;再复杂一点的就上Python+NLP+sklearn;更复杂的只能摊摊手:“哦吼,这个实现不了,提个需求找开发吧”。
最近抱着好奇的心态,体验了一下亚马逊云科技号称“0代码”的无代码机器学习智能工具——Amazon SageMaker Canvas(后续简称Canvas),最近本来就很流行低代码、0代码平台的概念,这一下子把无比深奥的机器学习给0代码了,可怜的互联网程序猿们和数据分析师是不是又要面临新N轮的失业了。
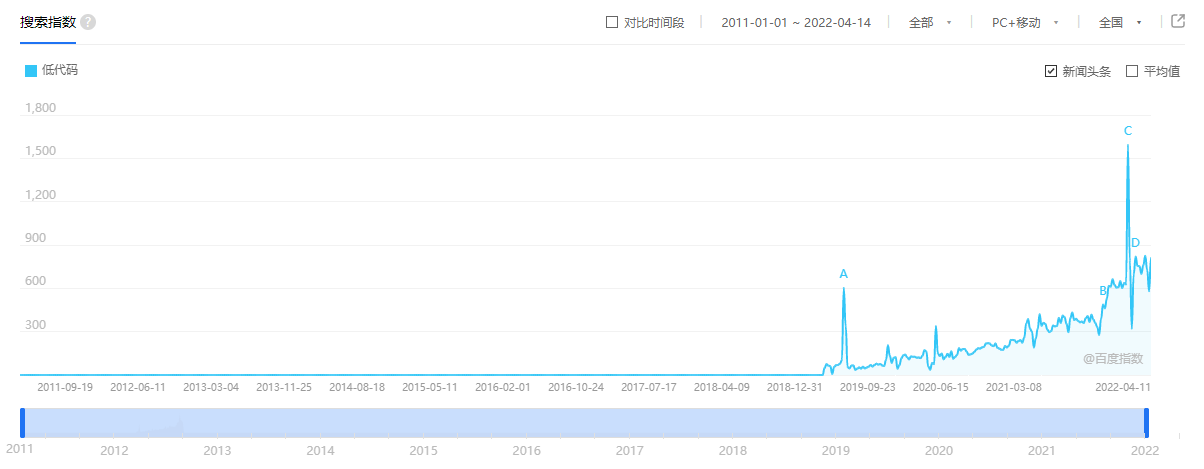
百度指数-关键词:低代码
二、机器学习与数据分析
大部分PM大佬们,没看过机器学习跑,但肯定或多或少做过数据分析的活,甚至不少公司还要求产品经理和运营、市场小伙伴们一起背着各种用户量、订单量、订单额的OKR/KPI。
用户量有多少,都是怎么来的?下单的人那么多,他们有什么共同属性?一份问卷发下去,用户反馈的结果如何?这些都是非常常见的数据分析问题。
我们通过研发协助,或者系统功能,导出对应数据后,一般在Excel、SPSS或者专业的BI软件中完成数据洞察与分析、绘制图表等工作,这就是最常见的数据分析过程。
其中最头疼的,就是如何看懂这些数据、剖析出数据背后的问题。遇到一些复杂的问题时,需要产品经理、运营或更专业的数据分析师,掌握一定的统计学方法,同时对业务背景和行业知识有深厚的理解,才可能拨开迷雾,通过数据接近真相。
一个人学习、积累经验的过程是漫长的、限制重重的,但如果让高速、大容量的电脑来代替人去学习和积累经验,通过大数据对电脑进行训练,然后让电脑对问题做出判断,是否就能培训出“电脑专家”呢?
答案是肯定的,机器学习就是一种让电脑像人一样去学习、积累经验、尝试解决问题的方案。
机器本身并不明白什么业务逻辑,于是我们要给机器“灌输”大量的数据,机器通过决策树、支持向量机、神经网络、深度学习等算法去不断“刷题”训练,形成类似人的“意识”,最后对新来的数据产生一定的预测能力。
例如一位房地产老中介,可以通过几十年的经验,在看到一个新的顾客时,快速判断该顾客的购买意向一样。机器学习完大量的交易数据后,当有一个新的样本进入时,机器就能快速判断成交的概率。
人需要数年时间、在行业里摸爬滚打加上大量前人经验教训,才可能精通一门技艺,无论是产品经理还是数据分析师、运营等,皆是如此。
对比人的学习过程,机器一样需要大量的“经验”即数据为基础,但是通过大量的CPU、GPU算力,学习过程可以缩短到数个小时内完成,只要样本量足够大,机器的分析能力一点都不比人差,就像著名的电脑围棋选手AlphaGo一样。
关键在机器的经验传承,就是“Ctrl+C、Ctrl+V”的这么简单的事情,支持不断迭代,而人的经验传承、知识升级就完成没法跟机器比了。数据分析工作更讲究基于客观事实的数据基础,相对比设计、策划等创意类工作,没那么感性,这就让本身“理性”的机器有了先天的优势。
三、机器学习能做什么
我们熟悉的特斯拉汽车自动驾驶,就是通过机器学习的方法让车载电脑学会开车。但是对于大部分产品经理,这种需求都是遥不可及的,那日常工作中,机器学习对我们有什么用?
换个角度想一下:
- 当你纠结公司产品最近大量投入广告,但是订单量却一直不理想时;
- 每举办完一个活动,运营就得花几天在那里绞尽脑汁想区分出作弊的用户时;
- 运维每到活动发布后,就提示疑似有大量黑产刷单时。
产品经理会想,如果有一个工具,可以帮助我们实现精准推荐、分析用户作弊概率、预测黑产风险等,那该多少啊!这时候机器学习就离我们不远了。
我们可以通过Canvas的一些官方示例,看看机器学习在日常工作中能帮上什么忙:
1)客户成交分析
在银行办理业务的过程中,通过客户的年龄、工作、婚姻、教育、住房、贷款、违约,还有宏观经济的居民消费指数、消费者信心指数、就业指数等信息,判断客户是否会购买存款证(Certificate of Deposit,简称CD,一种定期存款)。
这是一个典型的二元分析,即通过多个条件综合判断结果是、还是不是。例如电商就可以以此分析一款产品用户会买,还是不买;快递预测是否能准时送达。
2)街区房价分析
通过街区地址坐标、该街区的房屋平均年龄、房屋数量、人口、家庭数量、家庭收入中位数等信息,分析该区域房屋价格。
这是一个常见的回归分析案例,通过一系列参数,最终得出一个数据作为结果。常见应用场景可以是成交价格预测、活动带来的用户增长效果预测等。
3)基于日期的销量预测
通过日期、销售额、是否有活动、是否是学校放假,然后判断一个具体日期或时间段的销量。这是一种基于时间的序列预测,常见的应用场景是用户量走势预测、成交量走势预测、风险数量预测等。
4)贷款违约风险预测
通过贷款人的贷款金额、贷款周期、贷款利息、贷款目的,贷款人的就业年限、房屋抵押情况、收入水平等数据,分析该用户是正常还款中、完成还款、还是会违约产生坏账(charged off)。
与案例1中的客户成交分析不同的是,此时结果是3个,甚至可能是多个,这种属于“多类分类问题”,相对于非黑即白的二元分析,借助此模式,可以用于更丰富的场景预测。例如我们有多套房子,可以用来判断用户最可能对其中哪一套感兴趣;又或者用于把用户按消费欲望自动分级、按某种用户画像自动归类等。
除了Canvas官方案例外,我还整理了一些在电商运营中,售前、中、后不同阶段,机器学习可以助力的地方:
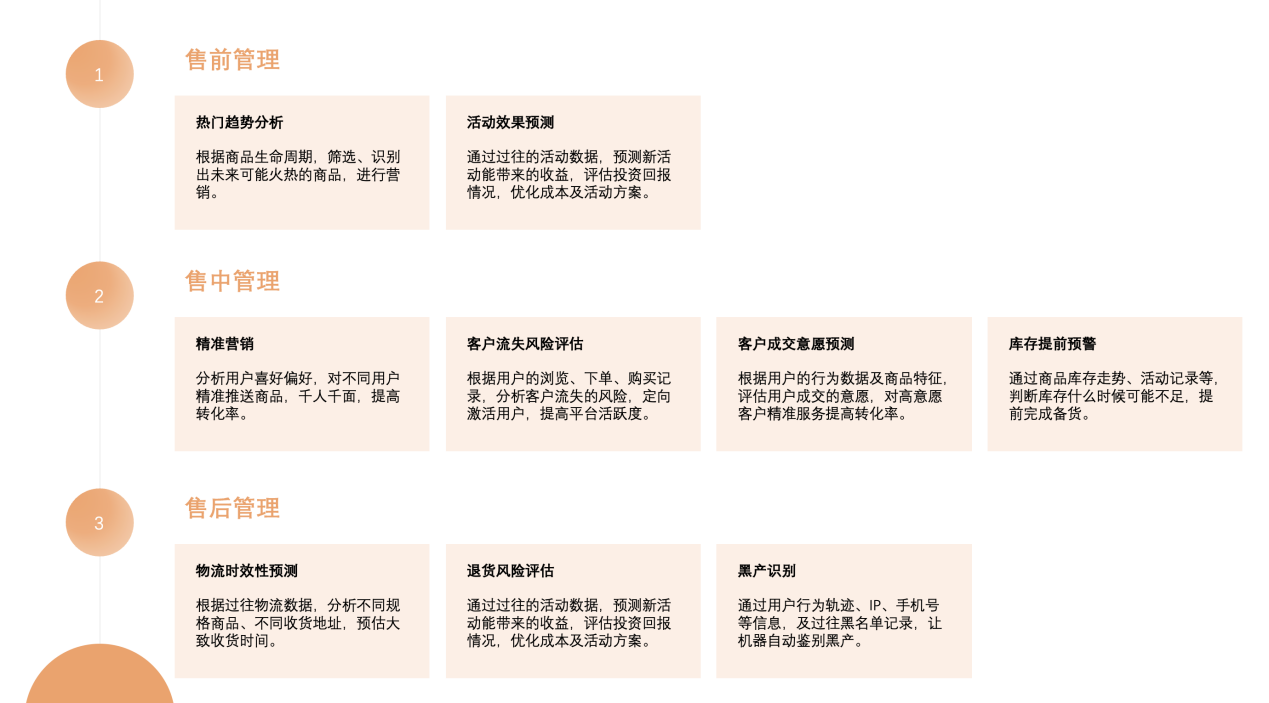
可以看出机器学习可以介入的机会很多,就算现阶段还不能完全取代人工运营,也可以有效为运营、客服、数据分析等岗位,发现问题和提供建议,从而整体提高营销能力。
四、实际体验
接下来我们将通过一份用户购买数据,通过Canvas,实际体验一番,看看0代码的机器学习平台究竟是怎么样的。
测试项目:某内购商城,将要举办一个活动,希望把几款热销的商品推广给更多的员工购买。
测试目的:预测每位员工最可能购买的商品,然后进行精准推送,提高转化率。
样本介绍:从系统中导出了5款活动商品的历史购买记录,包括了购买者所使用的手机品牌、客户端类型、性别、司龄、年龄、婚姻、户口、学历、职位、职级、工作城市、所属部门等信息,让机器学习不同类型的员工更可能选购哪款商品,根据预测结果,向公司其余员工定向推广具体的商品,提高转化率。
数据量:数据清洗后共9113条有效数据。
1. 创建账号
注册一个亚马逊云科技的个人账号,完成存储空间S3和Canvas的初始化。
2. 正式体验Amazon SageMaker Canvas
Amazon SageMaker Canvas作为一款0代码机器学习平台,可以看到整个平台界面十分的简洁、时尚,完全不会让人有对代码或者机器学习深奥知识的恐惧感,视觉效果满分。
1)创建模型
创建一个Model,即创建了一个项目。
2)导入数据
为项目导入需要让机器学习的数据。
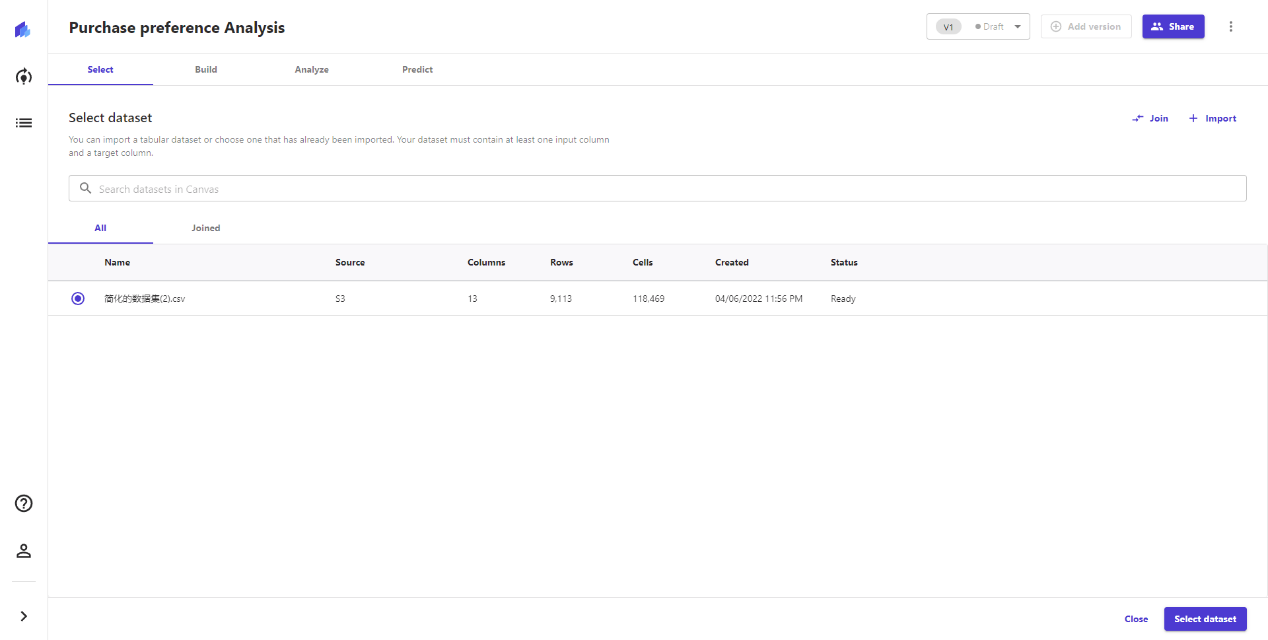
Canvas的数据需要utf-8格式的CSV,且先上传到S3储存中,才能在此导入。
除了导入单个CSV数据集,Canvas还支持对多个CSV进行可视化的联表操作、导入来自Amazon Redshift和Snowflake的数据,并进行SQL操作,提供更丰富的ETL数据处理能力。
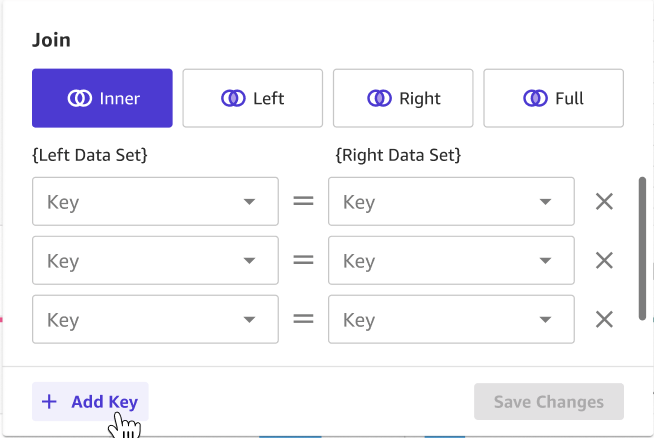
数据安全:如果需要学习训练的数据中,包含了公司的敏感信息,请提前完成脱敏,避免不必要的数据泄露。
3)预览字段和选择目标
查看导入的数据、选择需要作为预测结果的字段。
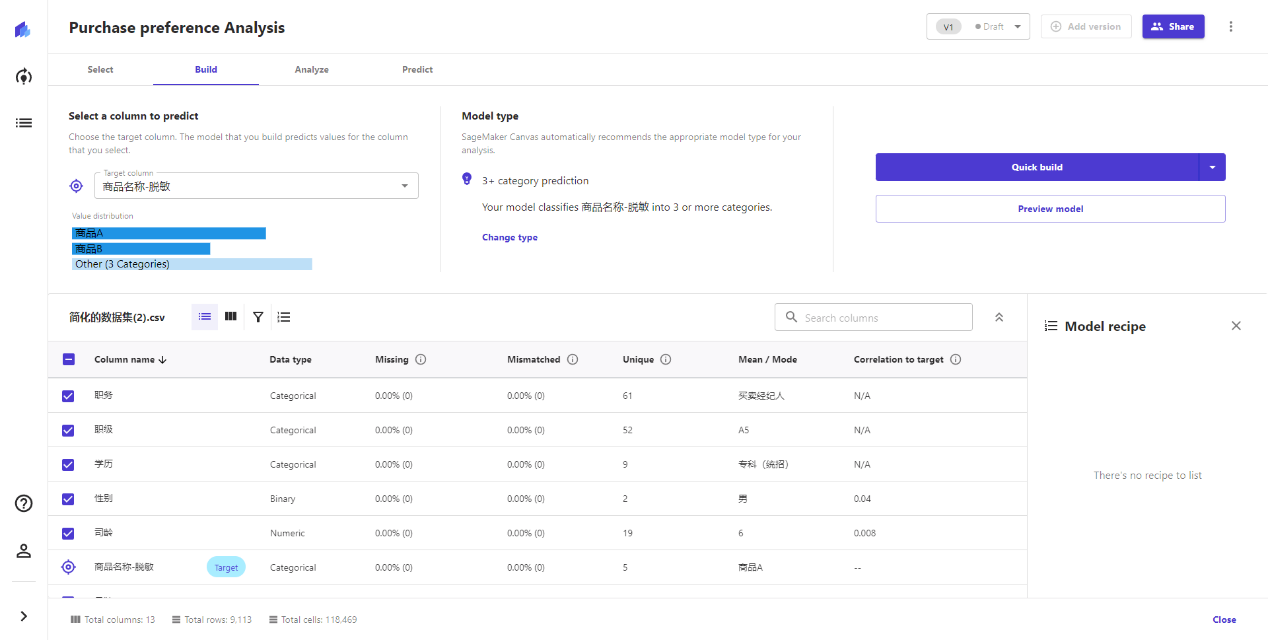
Select a column to predict:选择一列字段作为预测对象,选择好后,Canvas会自动识别该列数据的类型,是数值、二元对象、还是多元对象等,如果识别不正确,可以点击Change type手动修改。
其他作为被分析对象的列,Canvas会自动检测它的数据类型,但是有一定概率识别不准确,且不支持修改,所以需要检查清楚,并在数据源头解决问题,例如某零件的型号格式是个数字组合,但是Canvas就会将其当作数值处理了,从而影响了机器学习准确性。
此时我选择商品名称作为最终的预测对象,后续系统就会自动分析其他字段与商品名称之间的关系,即分析不同的用户属性,对最后购买商品的影响。
4)预览模型
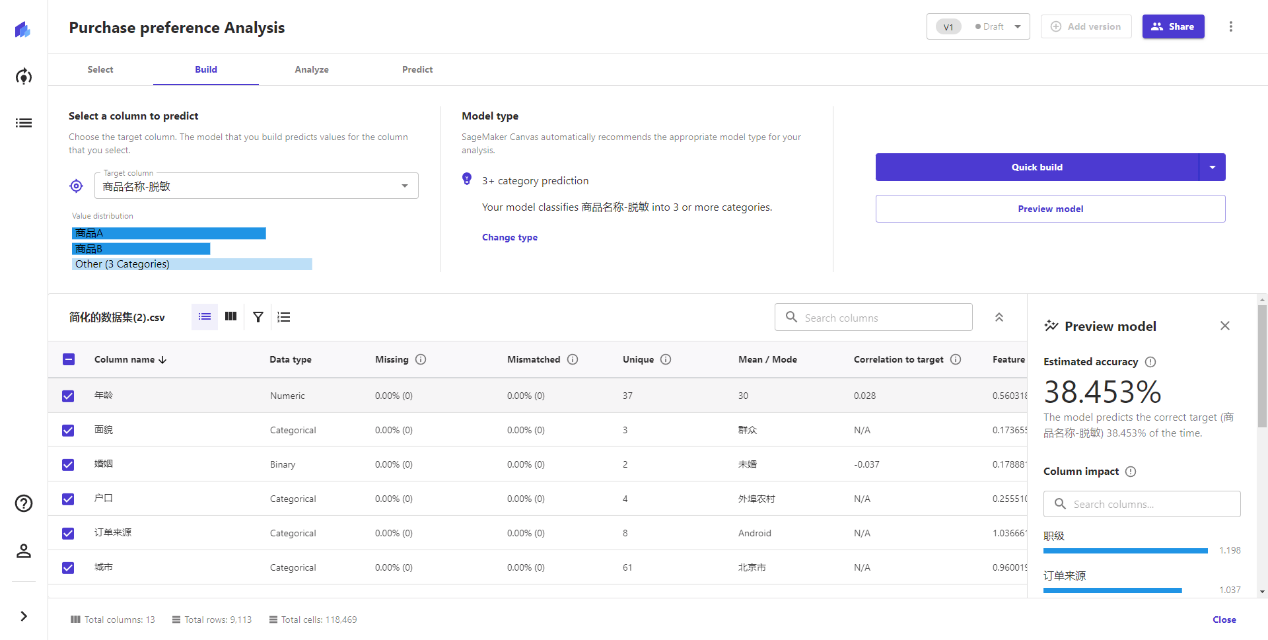
通过点击Preview model,只需要稍等几十秒到几分钟(取决于字段的数据和数据总量),就可以看到系统的预估准确率、以及每个字段的影响权重。Canvas会自动完成传统机器学习过程中,从样本库切分训练集、测试集的过程,自动使用测试集的完成准确率评估,降低了机器学习的操作门槛。
在过往数据模型建设的过程中,需要大量用户调研、经验总结、甚至专家评审的数据建模过程,Canvas就用了几分钟就完成了!极大地降低了数据分析的门槛(甚至完全没门槛了,会认字看结论即可)。
如果我们发现一些字段的影响权重非常低,对结果几乎毫无影响,可以直接在字段列表中去掉这些值,这样可以提高后续分析的速度,甚至提高预测的准确性。有些字段系统可能会认为对结果影响不大,但是我们从经验或常识认为并非如此,则可以选择性保留。
每次调整好要分析的字段后,可以点击一次Preview model,看看准确率是否有所变化,从而实现优化模型的过程。
5)模型构建
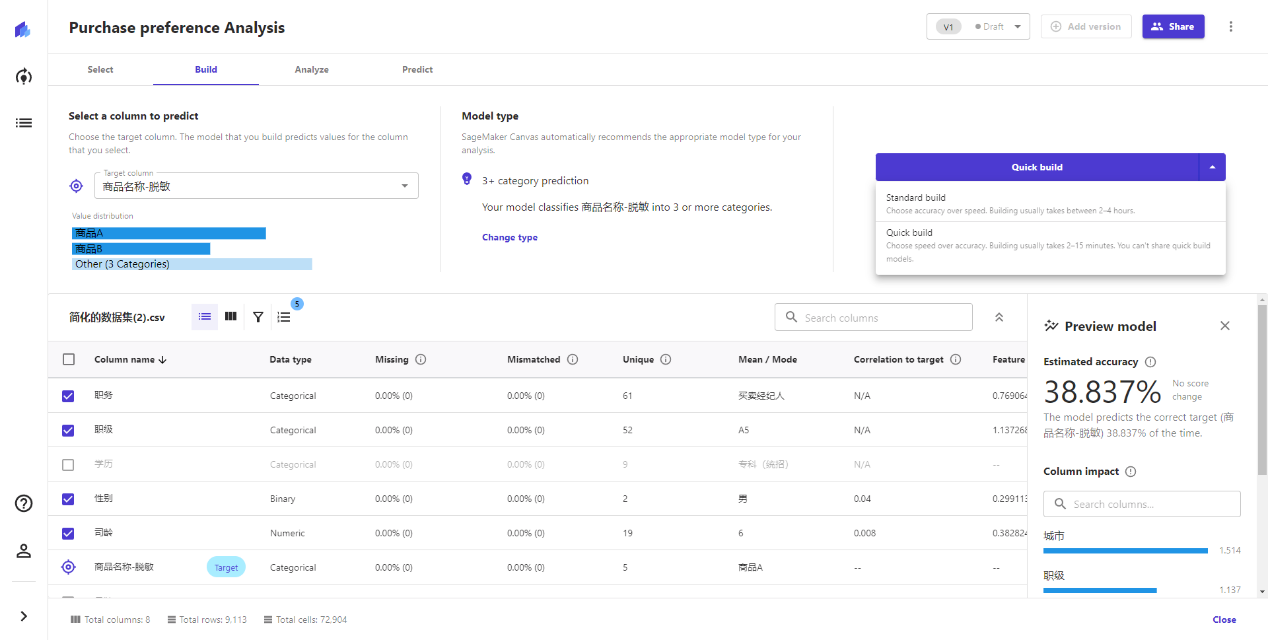
Canvas提供了Quick快速和Standard标准两种模式,快速一般需要2-15分钟,标准需要2-4个小时。
标准和快速的区别是,标准的预测准确率会高些,而且支持分享给Amazon SageMaker Studio——一款面向数据科学家、研发工程师的,代码化机器学习平台,让专业用户可以对这个模型调优、用于生产环境等。如果只是想试用,使用Quick模式将高效得多。
我尝试了两次标准的建模过程,发现数据量超过十万行以上,界面预估的时间就不太准。如果只是想体验,使用Quick build即可。
Canvas可以让用户不再需要关注机器学习的策略和算法的问题,极大地降低了机器学习的入门门槛。
- 策略:用什么准则去学习、确定损失函数;
- 算法:此处的算法指狭义的算法,如最小二乘法、梯度下降、上升法等,是从数学上如何解决问题的算法。
广义的算法,就是我们在学习机器学习过程中经常会听到的名词,如线性回归、决策树、贝叶斯、支持向量机、神经网络等算法,其实囊括了上述策略和算法这两者的内容。
6)训练结果
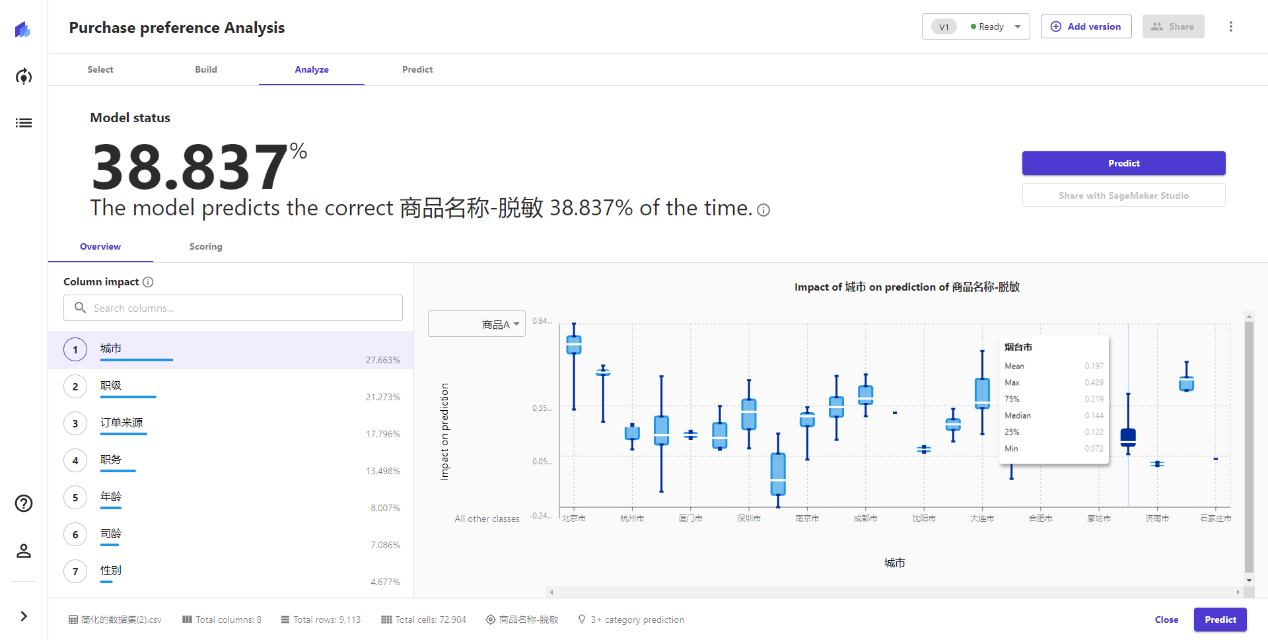
等待机器学习完毕,就可以看到系统分析出来的预测准确率。
在概览Overview Tab里,可以看到每一个指标的影响系数,点击具体指标,可以查看该指标的枚举值,对预测结果的影响系数平均/最高/75%/中位/25%/最小值,通过概览数据,可以快速了解不同的字段对于最终结果的值的具体影响。
机器自学完成了对数据的理解和影响权重的判断,并生成了精美的权重影响表格,以往需要数据分析师或者运营同事花上个半天甚至几天时间的工作,全自动化了。
这一步我们看到,机器认为员工所属城市是影响商品购买决策的主要原因,其次是职级、订单来源(设备)、职务等信息。婚姻、户口、学历等因素对购买决策影响非常小。
本次预测,系统提示的成功率是38.8%,看似不太理想,但换个思路:向三个人推送不同的商品,有一个人会喜欢这款商品,这个结果还是很不错的,毕竟我们有五款商品,如果是随机盲推的话,准确率就只有20%了。如果数据量更大,并采用标准的数据建模方式,应该能获得更好的预测准确率。
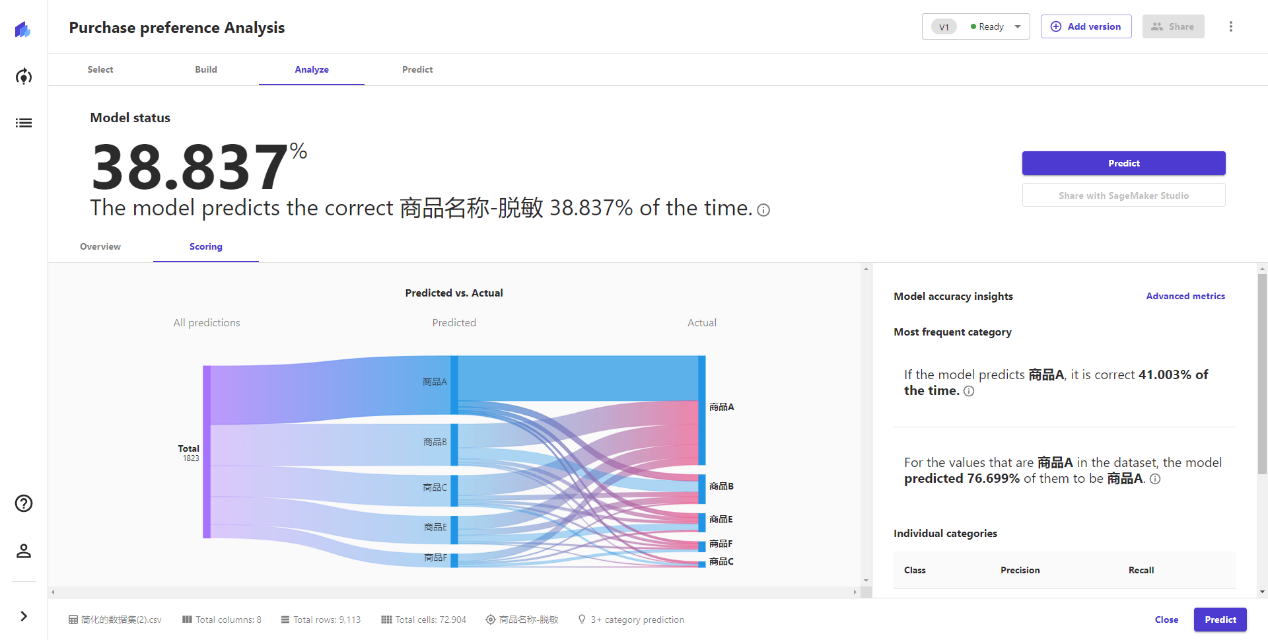
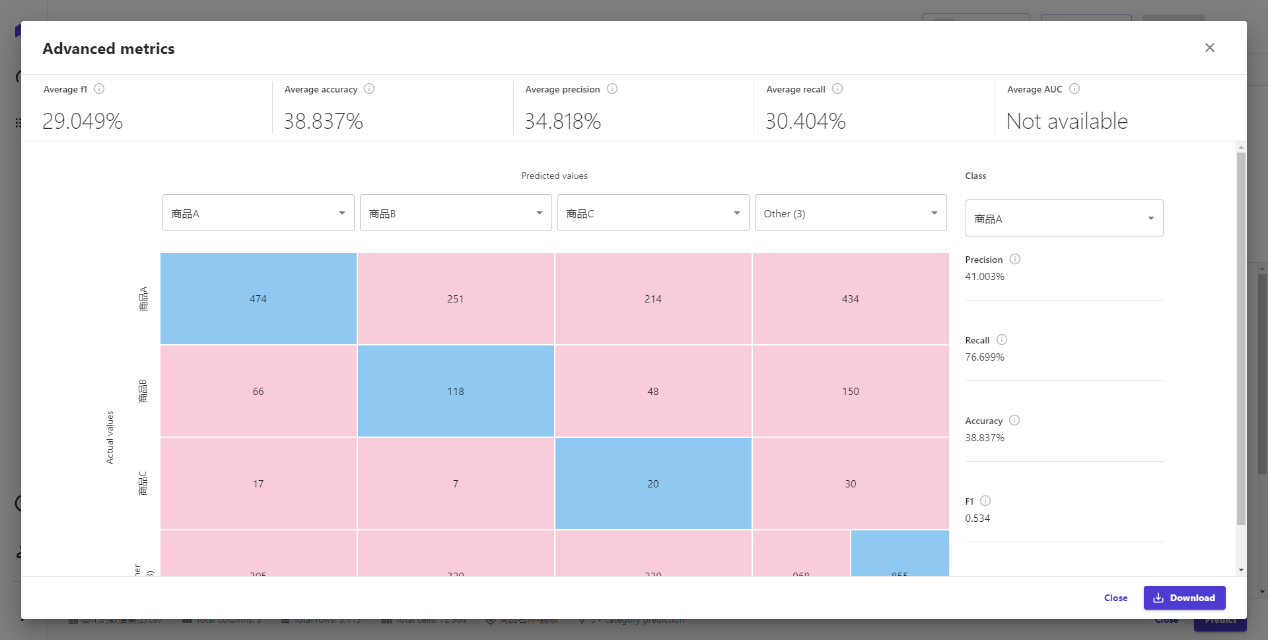
点击得分Scroing Tab,可以查看预测结果和实际结果的区别,以及对于每个预测结果的准确率,点击高级指标Advanced metrics,可以查看到更多高级指标。
由于预测对象类型的不一样,高级指标也不一样,可用于给数据分析师进行更高阶的预测效果判断使用。
7)模型预测
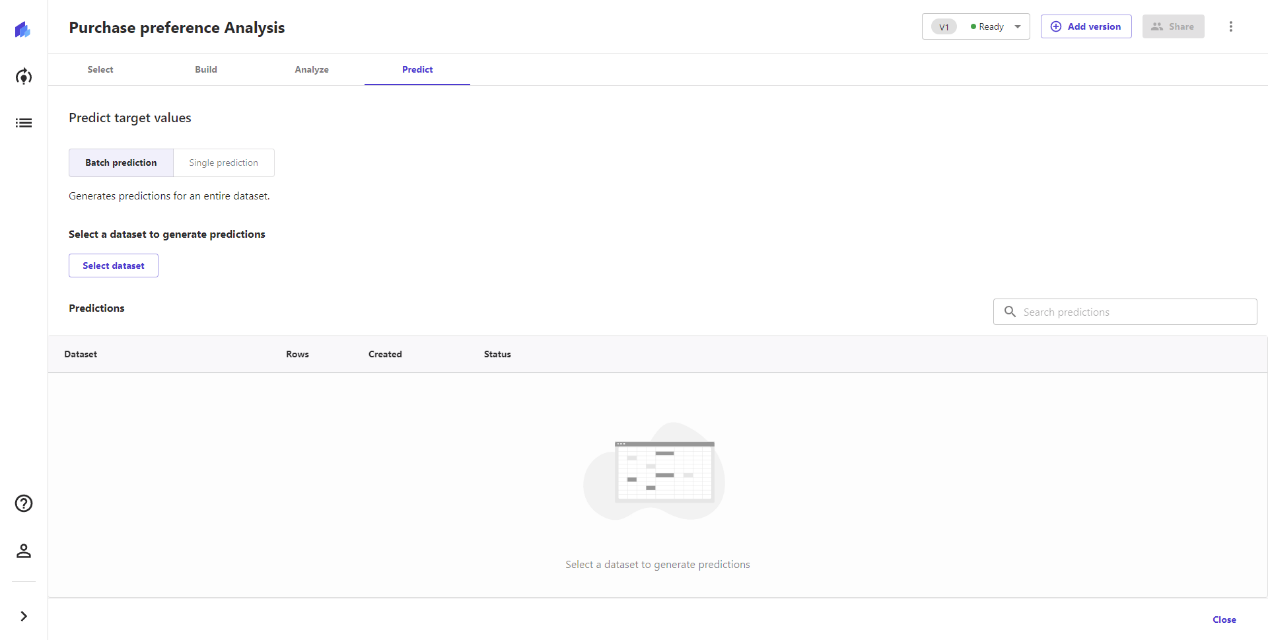
Canvas支持批量预测和单个预测的功能,如果我们只是想测试预测效果,或者被预测对象较少或较低频出现时,可以直接使用单个预测,输入已知的属性,即可完成预测过程。
此处我输入用户信息后,系统预测该用户购买商品A的意愿最大,以及其他各商品的购买可能性。
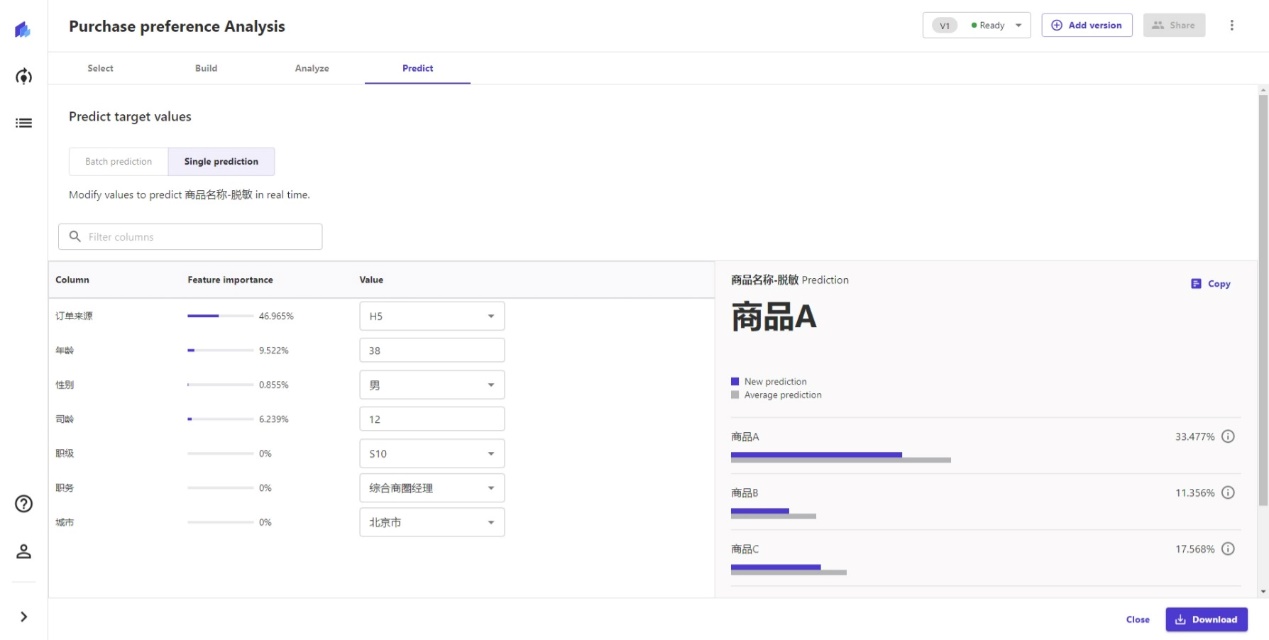
批量预测,需要先将需要预测的数据集上传到S3储存中,再在此处选取,然后完成批量预测和结果下载。批量预测更适合商业化场景使用,可以对多个数据同时完成预测,预测结果可以用于精准推荐、定向营销。
营销的过程中,我们还可以把新的产生的订单数据和旧的整合在一起,再建一个机器学习项目,不断哺育机器学习样本、提高预测精准性。
8)版本管理

新建版本后,可以切换不同的字段,但是不允许修改导入用于机器学习的数据集。如果我们认为预测结果、准确率不太理想,可以尝试创建新的版本,对上传的数据集,选择不一样的字段,然后再重新机器学习训练,构建获得一个新的模型,在多个模型间对比,找到效果最好的方案。
9)模型分享
如果每次数据预测都需要先导出要数据,然后再上传到S3、再导入Amazon SageMaker Canvas,然后预测、导出结果,需求频率一高,必然导致效率低下。
通过标准模式构建出来的模型,支持分享到Amazon SageMaker Studio,让研发和分析师进行更高阶的开发,最终将机器学习的结果应用于业务生产过程中,使预测能力功能化、产品化。
3. 计费方式
根据Amazon SageMaker Canvas的介绍,收费是使用会话费用+模型训练费用综合计费。即按使用系统的时长+模型的数据量两个维度双重计费。
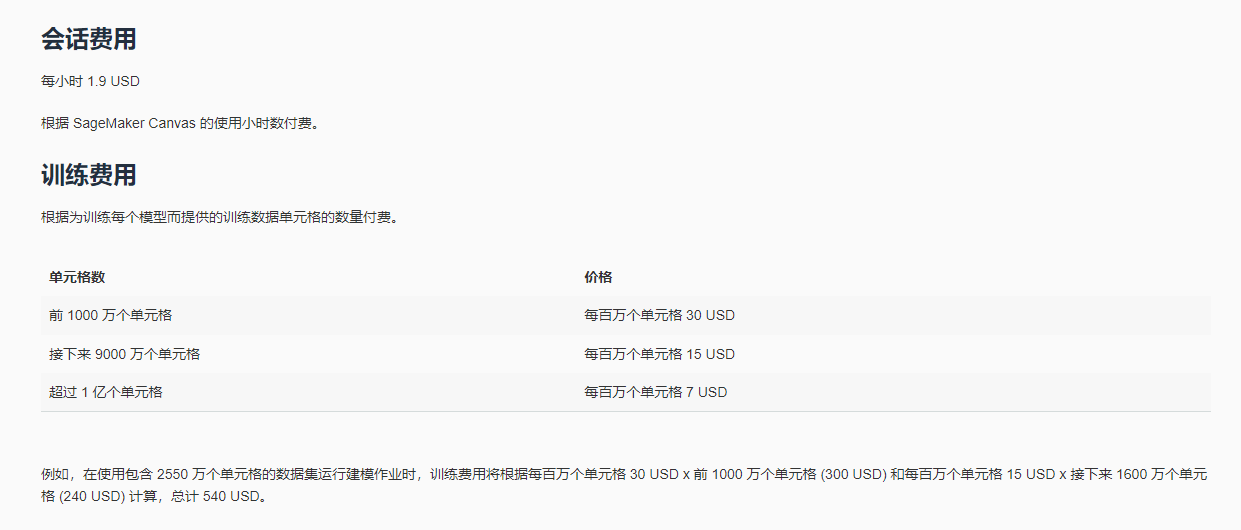
Amazon SageMaker Canvas为新人提供了免费试用套餐:免费套餐为期两个月。该免费套餐包括每月最多 750 小时的交互式会话时间,以及每月最多 10 个模型创建请求,每个模型创建请求最多 100 万个单元格。如果只是用于试用,应该绰绰有余。
五、体验总结
在评价Amazon SageMaker Canvas好坏前,我们要看它到底解决了什么问题:Canvas相对比传统的机器学习平台,好处是无需编写任何代码,无需学习那些高深的数据分析方法和机器学习算法,就能实现对数据的机器学习和预测。
Canvas将机器学习的门槛大幅度降低,整个操作流程(注册和初始化除外)甚至比很多Excel中的公式都更简单,让人可以轻松上手。Canvas还提供了工作流对接,做好的模型可以给工程师进一步使用,这就让该平台不仅仅是“玩玩而已”,做出来的东西是可以真正应用到生产作业中的。
随着机器学习相关技术的不断发展,机器学习在很多行业已展露出逐步取代人工的态势,未来的科技发展势必离不开机器学习。如何降低门槛,让更多人投入机器学习工作的怀抱中、扩大机器学习的影响面,将是一个全新的问题。
目前很多耳熟能详的科技巨头,如微软、谷歌、苹果等,都相继推出了自己的0代码/低代码机器学习平台,受限于数据安全、语言门槛、网络访问以及其他一些局限问题,其中很多平台还处于一个不温不火的阶段。
但是,通过对Canvas的体验,可以断定在可期的未来,机器学习大概率会成为一种可以速成的技能,只不过是有人专门研究数据收集,有人研究如何构建模型,有人挑选算法、有人选择策略……就像现在的互联网IT分工精细化一样的过程。
有了这样快捷的工具后,用户将无法感知如何预防过拟合、如何进行算法调优提效等传统机器学习过程中常见的问题。不需要太多的统计学和行业知识,就能完成数据建模和预测,还可能导致用户对于机器学习的过度依赖,从而忽视了行业知识的沉淀和人在此过程中的重要意义。但是这些问题,随着0代码机器学习平台的不断升级迭代,肯定会逐步得以解决。
最后,回归本篇的题目,下一个数据分析师,何必是数据分析师,借助更高级的0代码机器学习平台,机器学习平台可能就像Axure、墨刀、XD等软件一样流行,简单上手,人人都是数据分析师。
#专栏作家#
iCheer,公众号:云主子,人人都是产品经理专栏作家。房地产/物业行业产品经理,Python编程爱好者,养猫发烧友。
本文原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议








这个人是个上门女婿,臭不要脸,靠女人养的
你真弱
死废物,装你妈逼
丈母娘:许可你就是个废物,蛀虫,骗我首付钱,能力不行娶村姑不好吗
看了博主的文章,感觉未来数据分析师的发展方向应该是数据产品或行业专家,一是因为数据技术已成熟,关于数据的一切复杂操作都可以沉淀为自动化系统,这个系统需要有既懂产品又懂数据的数据产品来牵头设计;二是因为自动化系统一旦大规模应用,数据分析师就不用埋头于数据本身(比如取数、清洗等),有更多的时间来解读数据,给出观点,即成为有数据sense的行业专家。