
 起点课堂会员权益
起点课堂会员权益OpenAI新模型达到博士水平?我找几位博士测试了一下
OpenAI 最新发布的 o1 模型虽然号称达到了博士水平,但总有人不信。本文作者邀请了数位作者对 o1 模型进行实际测试,评估了其在物理学、材料化学和生物学问题上的回答质量。一起来看看表现如何。
今天凌晨,OpenAI 毫无预告地发布了业内期待已久的新模型。此前,大家从 CEO 奥特曼的推文中猜测这个模型会叫 “ 草莓 ”。

而在实际发布的时候,这个模型的名字叫 OpenAI o1 模型。
奥特曼对这个模型的评价是:他们迄今为止最强、最一致的模型。
在官方给出的一组数据图中,我们能很明显地看到 o1 模型在国际数学奥林匹克竞赛、编程竞赛还有博士级别的科学问题上有很大提高。图中最左侧为 GPT-4o,中间是目前已经开放了的预览版 o1,最右边高高的红色柱子为满血版 o1。我们可以看到,基本每一项,o1 比起自己的前辈来说,都是接近 8 倍的提升。
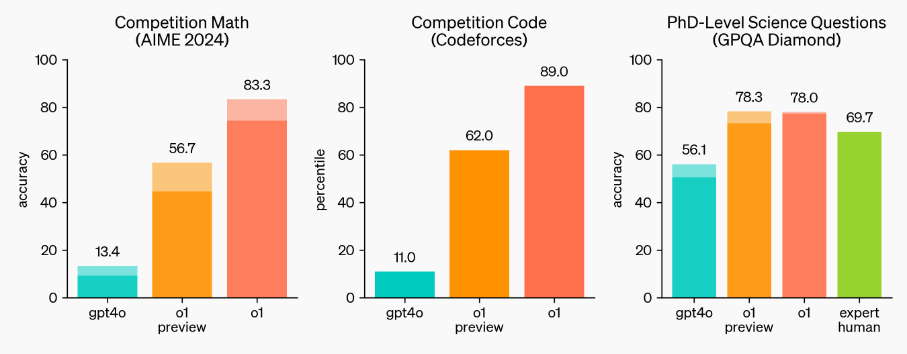
如果把这些测试结果拆开来,新 o1 也几乎是在各种学科、各种领域,都全量、全面、全方位地超越 4o 版本模型。
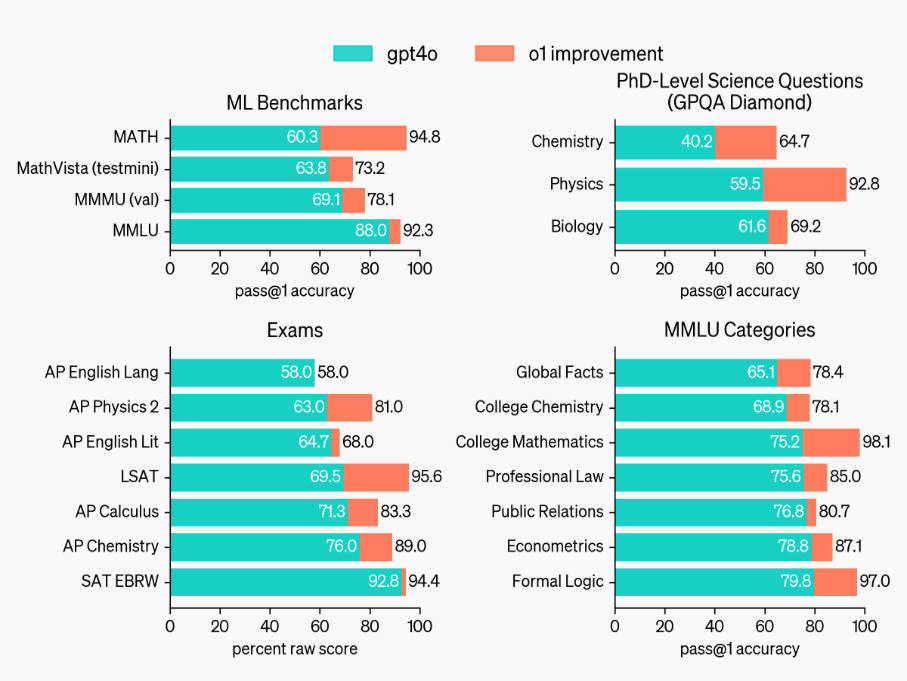
而最让人感到可怕的是:OpenAI 说自己专门请了博士专家一起答题,结果在博士级别的测试结果上,发现 o1 答题分数均超过了博士专家,o1 得分 78,人类得分 69.7。
所以,人类一败涂地了?
为了能大概了解 o1 模型( 预览版 )的真实能力到底几何,知危编辑部邀请了三位知名院校博士来向 o1 模型提问,并请他们对 o1 的回答进行打分。( 订阅 ChatGPT Plus 会员每周有 30 次向 o1 预览版模型提问的机会 )
为了保证多样性和客观性,我们邀请的博士分别涉猎生物学、物理学、材料化学。
其中,南京大学在读物理学博士崔博士对 o1 模型的评价是最高的,他认为 o1 已经达到了 60-80 分( 满分 100 分 )的水平。
甚至在某些问题上,他认为回答可以给到 90 分。
崔博士的研究方向是量子光学,所以他给出的第一个问题是:远距离纠缠光子分发,有什么克服白噪声的办法?
思考 9 秒后,o1 就给出了 10 点可行的措施。

崔博士对回答的评价为:“ 答案列举的全面,符合现有的最新研究进展,对知识储备不足的人可能提供调研方向,但是可能对高级别专业人员没有提供真正有用的信息,属于科普级别的答案。”
评分方面,崔博士认为 o1 的这次回答可以打 80 分,他指出,o1 回答中提到的自适应光学的方向是今年最新的 Science 成果,回答是具有先进性的。
随后,崔博士追问了 “ 是否可以扩展到量子自适应光学?” 这一问题,o1 思考 19 秒后给出了作答。

崔博士对这个回答的评价是:“ 可以给到 90 分,这个回答对我也很有提示性,虽然不具体,但对我们只需要指个可能的方向,剩下的我们自己来调研思考。”
崔博士指出,“ 他的回答有很多是我的知识薄弱区了,有的概念我也只是简单理解,但他说的我认为都是有道理的,所以我认为还是可以的。”
相比之下,对于老版本模型相同问题的作答,崔博士的评价是不及格或是 60 分。
不过,在关于涉及实验细节的 “ 基于非线性相互作用产生的高纯度解关联单光子的自关联函数,分别在连续泵浦和脉冲泵浦的情况下,如何测量?” 这一问题上,崔博士认为 o1 的回答中规中矩,只能给 75 分。
总的来讲,崔博士认为在物理方面,o1 的表现算是不错的,和老版比下来提升基本在 20 分左右。
下面,我们来看看北京大学在读材料化学的 K 博士对 o1 模型的评价。
K 博士围绕 Fe-N4 材料问了一系列的问题,o1 给了很长的一串回答,为了精简篇幅我们这里只展示了部分问题和结果。

整体测试之后,K 博士给出的评价也差不多:可能有研究生水平,但是深入的认知和给方案的能力比较弱,主要还是针对已知内容作答。
比如问到如何调节 Fe-N4,o1 可以说出基于电子态调节,但你要是问它那该如何调节,它就有点卡壳了。虽然相比 4o 模型没那么胡说八道,但具体的问题上他俩都给不了太多建议,老版本 4o 是丧失细节乱说,新版本 o1 则是能力有限就会词穷。
下面,我们再看看清华大学在读生物学的信博士的评价,他的提问是:“ 如何从质谱数据集中区分赖氨酸残基的乳酰化和羧乙基修饰?”
o1 也给了一段非常长的回答,有些像综述,后面还贴了参考文献。

但出乎意料的是,当我们把这个回答交给信博士时,他看完就发现有些不对劲儿。
倒不是这 AI 回答的全错,而是 AI 在参考文献里乱编,这论文压根不存在!
不过,总体来,信博士还是觉得比之前的 AI 强了不少,起码理解能力是肉眼可见的增长了,编的时候也编的很像。。。
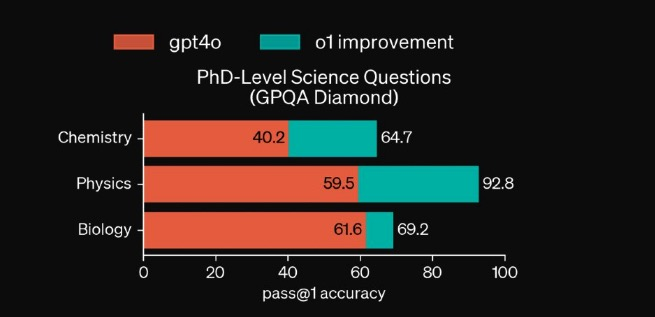
实际上,这个测试的结果并不出乎知危编辑部的预料——因为根据官方给出的数据来看,o1 在物理上的分数达到了 92.8,已经远超其他两门学科,这或许就是崔博士对它比较看好的原因。
综合来讲,真要说到超越专业博士水平,三位博士们认为还得缓缓。
崔博士直言,在现实科研工作中,多数情况学者们都还得自己动手,AI 只能提供大致方向,因此花钱要这样的细致 AI 意义不大。
他表示,他更推荐本科生选择这个 AI,要是硕博阶段,那这个 AI 的回答其实并不符合导师标准,组会上肯定要挨批。
清华的信博士也同样持这种看法,且不说 AI 的幻觉编造文献问题,就专业程度而言,AI 的回答也只能糊弄大同行,也就是同一大学科里面方向不同的人群;而在小同行,专业研究这个方向的人眼里,AI 的毛病还是非常明显的。
北大 K 博士则谈的更深入,他认为这个 AI 只能说在认知上有了硕士生的水平,但也只是作为一个缝补匠,谈不上说出什么创造性的成果。就创造性这一点来说,AI 是远远比不上硕博的水平的,这也是 AI 需要解决的重要问题。
在博士们的评价里,我们似乎能抓到一个重点:o1 模型之所以相对更强,是因为他有了更高维的认知和思考模式。
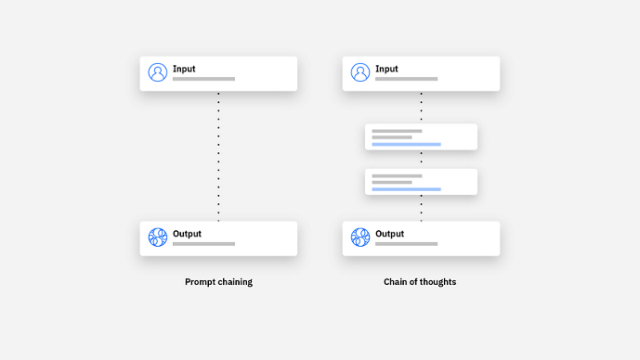
这,也是 o1 本次更新的要点。在 OpenAI 关于 o1 模型原理解释的文章中,他们表示 o1 变强主要是他们用上了长思维链 ( CoT,Chain of thought ) ,而不是传统的提示链( Prompt chain )。
第一眼看上去有点懵,说人话就是,这个大模型改变了以往那种你问我答的思考方式。
在以前的模式下,大模型的问答就跟下意识出答案一样,比如你问我天是啥颜色,这问题我想都不想,秒答蓝色。这实际上需要我本来就知道这个知识点,然后给你直接反应就完了。
但这个长思维链就相当于,我不仅要知道蓝色是个啥,还能自己推一遍为啥是蓝色,什么大气散射,光谱波长都要考虑进去。
这,就需要 AI 得有实打实的构建逻辑,推理论证的能力,换句话说,他不仅要长脑子,还要动脑子。
尽管思维链这个概念是 2022 年谷歌提出来的,但 OpenAI 这次是第一个实现的。
实操过程中,现在你与 o1 模型对话,除了收获答案,还可以看选择展开看他解答问题时的思维逻辑,他的思考是具象化的而不是黑盒。
我们拿崔博士提问的 “ 远距离纠缠光子分发,有什么克服白噪声的办法? ” 这一问题为例,o1 模型的思考过程如下:

当我们询问崔博士这个思考过程是否合理时,崔博士表示:“ 合理,达到了博士级别,还是高年级博士级别。”
所以,o1 模型之所以会在物理学问答上面表现更出色,就是因为他的思维链达到了博士的水准,他会像博士一样思考物理问题。
同理,o1 模型在生物学、化学方面年表现相对不佳,很有可能是是思维链还没训练到最佳状态,但是从物理学问题的表现来看,等到训练愈发成熟,o1 会变得更强,我们可以期待一下 o1 模型正式版的发布。
哦,对了,最后放一个有趣的小彩蛋。
思维链虽然使得 o1 模型能像博士一样思考,但似乎在基础问题上训练的还是不够全面,我们发现他在简单问题上依然会犯低级错误。

他思考了 12 秒之后,自信地告诉我们 8.11 比 8.9 大。。。
怎么说呢,博士也会犯错,没毛病~
撰文:纳西、四大、大饼 编辑:大饼
本文由人人都是产品经理作者【知危】,微信公众号:【知危】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


