
 起点课堂会员权益
起点课堂会员权益从 Text-to-SQL 到 NL2MQL2SQL:企业级 Chat BI 的产品设计进化之路
在 Chat BI 的 Demo 阶段,Text-to-SQL 看起来像个魔法;但一旦进入企业真实的“深水区”,幻觉、逻辑黑盒、口径不一致就像三座大山,让 AI 变成了一个满嘴跑火车的“玩具”。本文将从产品架构视角,复盘我们如何通过引入“语义层”和 MQL,解决大模型在严谨数据场景下的落地难题。
一、 幻灭期:为什么 Text-to-SQL 在企业里跑不通?
在早期的产品探索中,为了追求“快”,我们和大多数团队一样,选择了直接让 LLM 写 SQL(Text-to-SQL)。
但在财务预算、销售分析等高容错率的场景中,这种模式很快暴露了致命缺陷。作为 PM,我收到的用户投诉主要集中在三个方面,我称之为“信任崩塌三要素”:
1. 幻觉风暴:
用户问“差旅费”,LLM 猜了一个 `cost_amount`,但数据库里实际叫 `expense_amt`。这种“一本正经胡说八道”直接劝退了专业用户。
2. 逻辑黑盒:
企业数据表往往极其复杂(Snowflake 模型、多级关联)。LLM 写的 JOIN 逻辑经常遗漏条件(比如忘了加 `is_deleted = 0`),且生成的 SQL 长达几十行,排查错误比重写还难。
3. 口径打架:
同一个“毛利”,财务算的是扣除分摊后的,销售算的是扣除前的。LLM 每次生成的逻辑随机波动,导致数据“由于 AI 的介入变得不可信”。
结论:在企业级场景下,LLM 不具备直接操作数据库的“执照”。我们需要一个更严谨的“中间人”。
二、 破局思路:从“写代码”转向“发指令” (NL2MQL2SQL)
为了解决“确定性”问题,我们将架构从 `NL -> SQL` 升级为 `NL -> MQL -> SQL`。
这里的核心变量是引入了 ——指标语义层。
核心概念重定义
- NL (Natural Language):用户的模糊意图(”我要看上个月数据”)。
- MQL (Metric Query Language):这是关键。它是一种与数据库无关的、结构化的中间态指令(通常是 JSON)。它不再是“代码”,而是对指标的“点选”。
- SQL (Structured Query Language):由语义层引擎编译生成的最终物理查询。
打个比方:
以前是让 LLM 充当“厨师”(直接做菜/写SQL),水平忽高忽低;
现在是让 LLM 充当“服务员”(生成 MQL 订单),只负责听懂客户要什么菜,具体的烹饪(计算逻辑)交给标准化的“中央厨房”(语义层)去执行。
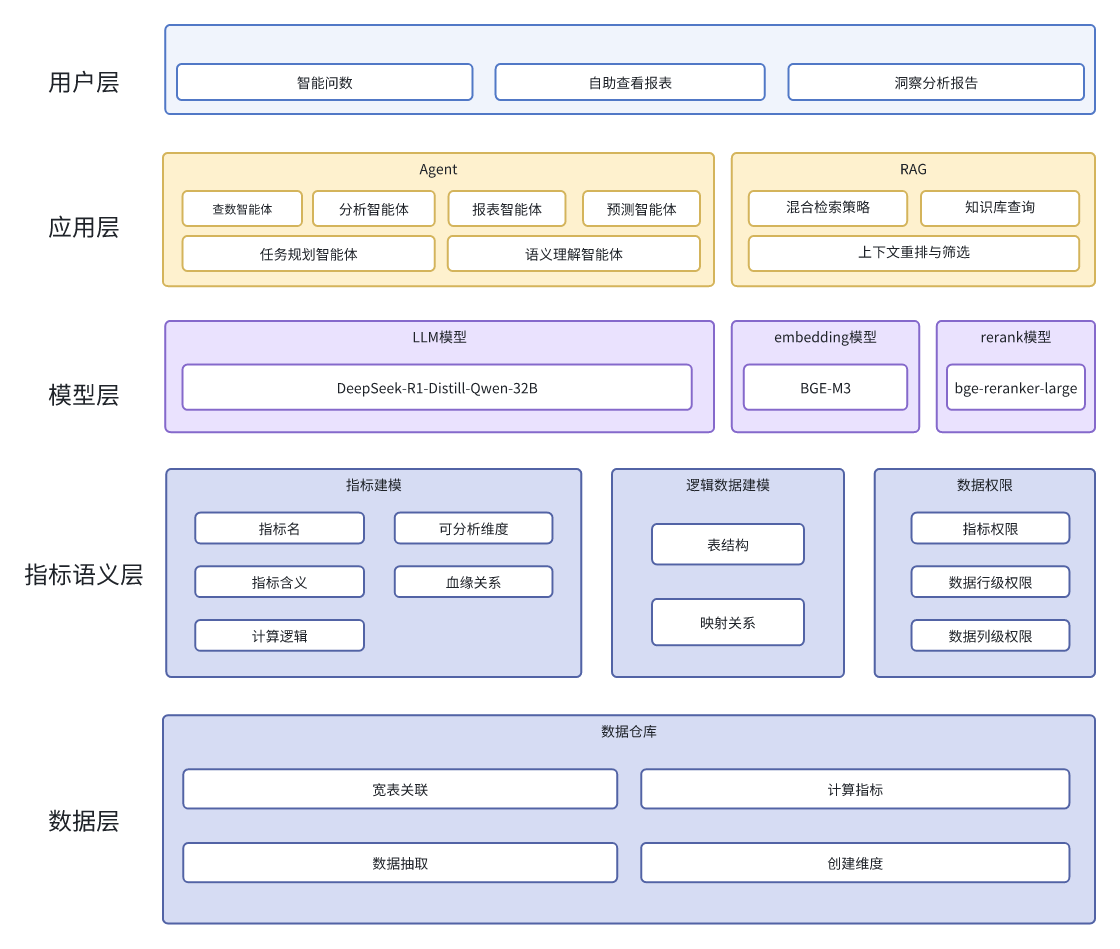
三、深度拆解:它是如何工作的?
以查询 “上个月销售部差旅费超支了吗?”为例,看看这套产品架构如何保证 100% 的逻辑正确性。
Step 1: Schema Linking (RAG 介入 —— 对齐认知)
LLM 本身不知道什么是“差旅费”。我们需要先通过 RAG(检索增强生成)去“指标市场”里找定义。
Input: “差旅费”, “销售部”
Retrieval:
`差旅费` -> 对应指标 ID: `travel_expense_amt`
`销售部` -> 对应维度值: `Sales_Dept`
Step 2: NL2MQL (LLM 生成指令 —— 确定意图)
LLM 不再生成 SQL,而是生成一个确定性极高的 JSON 指令。如果 LLM 瞎编字段,在这一步就会被 JSON Schema 校验拦下来。
“`json
{
“metrics”: [“travel_expense_amt”, “travel_budget_amt”], // 查什么指标
“time_range”: “2023-10-01/2023-10-31”, // 什么时间
“filters”: [
{“dimension”: “dept_name”, “operator”: “=”, “value”: “销售部”} // 什么范围
]
}
Step 3: MQL2SQL (语义层编译 —— 确保口径)
这是最像“传统软件工程”的一步。语义层引擎接收 JSON,根据预先配置好的数据模型(Model Relation),自动处理复杂的 Join、口径过滤和权限控制。
产品价值:无论谁来问,只要生成的 MQL 一样,最终出来的 SQL 永远是同一套逻辑。
四、为什么这才是“企业级”解法?
从 PM 的 ROI(投资回报率)角度来看,这套架构带来了显著收益:
- 准确率飞跃:将 Text-to-SQL 的“生成问题”降维成了“分类与提取问题”。在我们的实测中,准确率从 60% 提升到了 95%+。
- 权限安全兜底:LLM 无法看到底层表结构,只能看到语义层开放的指标。我们在 MQL 转 SQL 的过程中,可以强制注入 WHERE user_id = current_user 等行级权限控制。
- 可维护性:当业务口径变更(例如“毛利”计算公式变了),只需要在语义层改一次配置,所有 AI 生成的查询自动更新,无需重新微调模型。
五、进阶:当“查数”遇见“归因” (Hybrid RAG)
这套架构的想象力不止于查数。 当用户发现数据异常(如“超支了”),紧接着就会问“为什么?”。
此时,我们可以结合非结构化数据,实现真正的智能归因:
- Data Flow (MQL):查出具体是“业务招待费”科目超支。
- Knowledge Flow (RAG):系统自动检索该部门 10 月份的非结构化文档(周报、审批单、会议纪要)。
- Insight Fusion:检索到《华东客户答谢会预算特批邮件》。
- Final Answer:AI 最终回复:“超支主要是因为 10 月举办了华东客户答谢会(已特批),剔除该项后实际预算使用率为 92%。”
六、总结:工程化思维 > 算法崇拜
NL2MQL2SQL 不是简单的技术堆砌,而是一种产品哲学的转变:
- 把不确定的自然语言理解,交给擅长模糊处理的 LLM。
- 把确定的数据计算与逻辑,交给严谨的 语义层。
只有实现 AI 概率性与软件工程确定性的“完美握手”,智能数据助手才能真正走出 Demo,成为企业决策桌上可信赖的伙伴。
本文由 @Miracle 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议





- 目前还没评论,等你发挥!


