
 起点课堂会员权益
起点课堂会员权益破局“日志监控泥潭”:大型多系统智能运维中台建设全解析
在数字化转型浪潮下,企业运维面临诸多挑战。本文深入探讨了传统日志监控的困境,介绍了智能日志中台架构,涵盖其设计哲学、架构详情、基石构建及智能分析层的应用,强调AI在运维中的关键作用,助力企业提升运维效率与质量。

第一章:为什么我们需要一场“日志革命”?
1.1 大型多系统联动的运维之痛
在运营商、金融、大型电商等关键领域,业务系统呈现出鲜明的特征:
系统复杂性指数级增长:
- 某省运营商核心业务系统:15个A类平台+32个B类平台
- 单次用户请求平均穿透:4.2个系统模块
- 日均日志生成量:超过1TB(相当于100万本《红楼梦》)
故障影响的涟漪效应:
2024年某银行支付系统故障时间线: 10:03 – 数据库连接池异常(单一组件) 10:05 – 支付网关响应延迟(影响单系统) 10:08 – 订单系统堆积超时(影响关联系统) 10:12 – 客户投诉涌入(业务层面感知) 10:15 – 舆情开始发酵(品牌影响)
从技术故障到业务影响,再到品牌声誉损失,仅需12分钟。
1.2 传统日志监控的“三重门”困境
分析之浅——“知其然不知其所以然”传统监控只能回答三个问题:
- ❓有没有报错?(事后发现)
- ❓报了什么错?(现象描述)
- ❓什么时候报的?(时间记录)
但无法回答真正关键的问题:
- ✅为什么报错?(根因分析)
- ✅会影响谁?(影响范围)
- ✅接下来会怎样?(趋势预测)
- ✅怎么解决?(行动建议)
价值之困——“数据坟墓”与“知识流失”更可怕的是,企业投入巨资收集的日志数据,90%在写入存储后再未被查阅,成为“数据坟墓”。而资深运维专家的经验却随着人员流动不断流失,形成“新人重复踩坑,老师傅疲于救火”的恶性循环。
1.3 智能时代的新要求:从“事后追溯”到“事前预防”
在数字化转型的关键时期,企业对运维提出了更高要求:
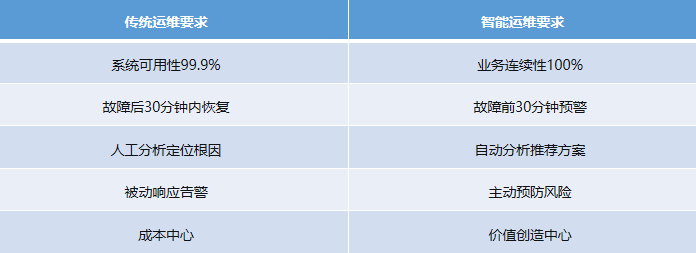
要实现这一转变,必须构建新一代的智能日志监控体系。
第二章:智能日志中台架构全景图
2.1 设计哲学:分层处理,AI在关键环节赋能
面对海量日志数据,一个核心设计原则是:AI不能全程参与,而应在关键决策节点赋能。我们将系统设计为四层架构:
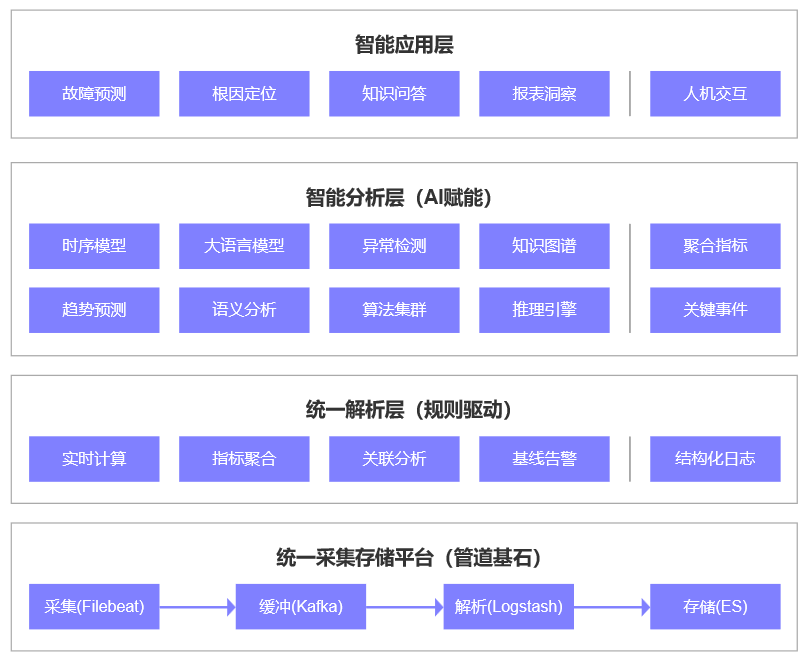
关键设计思路:
第一层:用成熟技术处理海量原始数据,保证稳定性和吞吐量
第二层:用规则和统计分析处理90%的常规场景
第三层:AI只处理聚合后指标和规则过滤后关键事件,避免“大炮打蚊子”
第四层:将分析结果转化为业务价值
2.2 架构详解:如何让AI“恰到好处”地参与?
数据处理量级对比: 原始日志:1TB/天 → 10万条/秒(全量数据,不可直接AI处理) ↓ 经过规则过滤和聚合 关键指标:1GB/天 → 100个指标/秒(AI可高效处理) ↓ 经过异常检测 需要分析的事件:10MB/天 → 50个事件/小时(AI深度分析) AI参与策略: 1. 全量日志 → 规则处理 → 异常事件/聚合指标 → AI分析(高效) 2. 全量日志 → 抽样(1%) → AI辅助解析(解决疑难杂症) 3. 历史数据 → 周期性训练 → 优化规则和模型(离线学习)
第三章:基石构建:统一采集存储平台实战详解
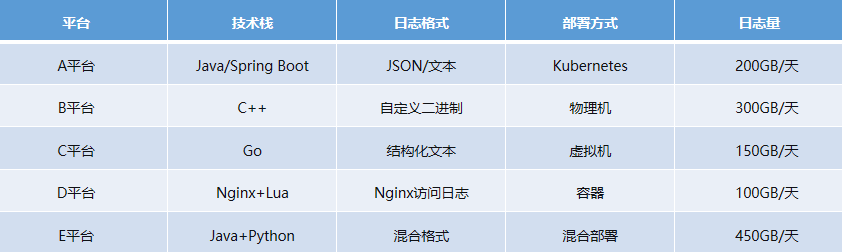
第一步:多源日志统一采集
场景挑战:不同系统平台,运行在不同的技术栈和环境:
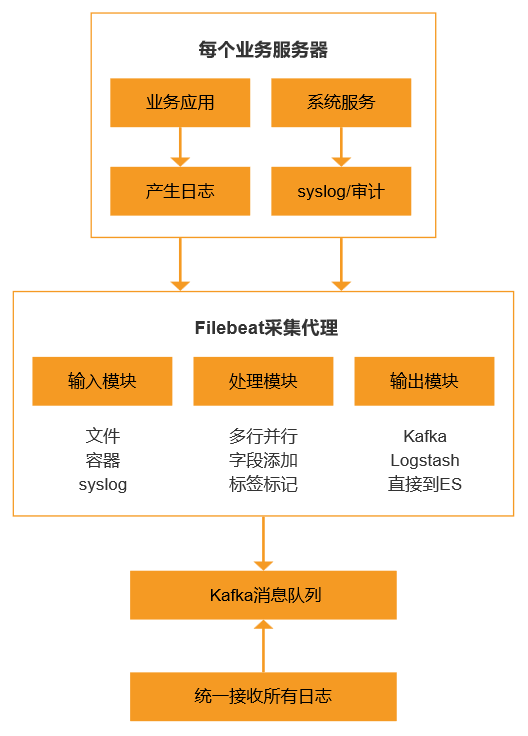
解决方案:Filebeat轻量级采集代理
Filebeat的本质是日志的“搬运工”,它的核心优势是:
- 轻量:占用资源少,不影响业务系统性能
- 可靠:支持断点续传,确保数据不丢失
- 灵活:支持多种输入输出,适配复杂环境
部署架构图:
第二步:高可靠缓冲与传输
为什么需要Kafka?想象一下,如果没有缓冲层:
- 日志产生高峰期:解析服务可能被压垮
- 解析服务升级:期间日志会丢失
- 多个消费者:无法同时处理同一份数据
Kafka作为消息队列,提供了三大核心价值:
- 削峰填谷:应对日志产生的不均衡性
- 生产消费解耦:采集和解析可以独立演进
- 数据复用:一份日志可以被多个分析管道消费
第三步:日志解析与标准化
这是整个管道中最复杂、最关键的环节。我们需要将五花八门的原始日志,转化为统一的、结构化的数据。
Logstash解析流水线设计:
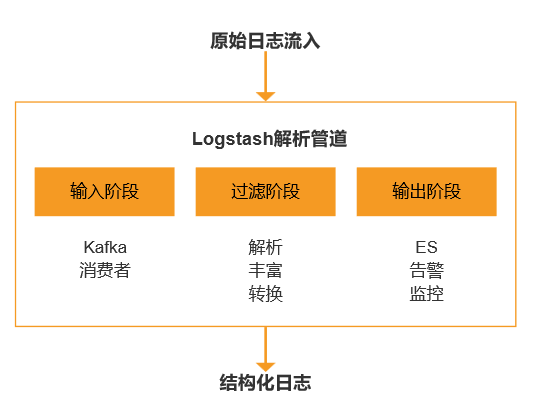
第四步:高性能存储与检索
Elasticsearch集群设计:
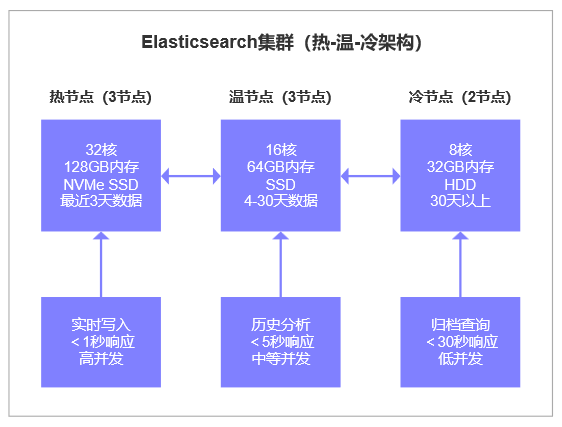
第四章:智能分析层:AI如何“恰到好处”地赋能?
设计智慧:AI不是苦力,而是军师
想象一下这个场景:你每天要处理1TB的日志——这相当于300万本《红楼梦》的文字量。如果让AI逐条分析每一条日志,就像让人工智能去数沙滩上的每一粒沙子,既不可能,也没必要。
我们的设计哲学很清晰:AI不做苦力活,只做决策层的事。
打个比方:
- 原始日志就像原始矿石——量大、杂乱
- 规则处理就像初筛流水线——用固定规则快速分类
- 聚合指标就像提炼后的金属——体积小、价值高
- AI分析就像高级工匠——只在关键决策点介入
这样设计的好处显而易见:AI只处理已经提炼过的“高价值信息”,效率提升了几百倍,成本却大幅下降。
第一步:把日志变成“可读的指标”
日志本身很难直接分析。想象一下,给你看这样一行日志:
[2024-05-27 14:30:15] [ERROR] SMS_SERVICE – 发送失败 user=13800138000 code=5003 provider=aliyun duration=245ms
单看这一条,你只知道“有一次发送失败了”。但如果有1000万条这样的日志呢?人脑是处理不过来的。
所以我们需要先把日志变成指标。指标就像是给日志做的“体检报告”。
基础指标(系统自动计算):
- 每分钟总请求数
- 每分钟错误数
- 成功率 = (总请求 – 错误)/ 总请求
- 平均响应时间
业务指标(结合业务规则):
- 各渠道(移动、联通、电信)发送量
- 各模板(验证码、通知、营销)成功率
- 各省份用户发送情况
- 高峰时段流量分布
4.3 AI第一个妙用:预测性监控——像天气预报一样预测故障
传统监控的局限:传统的监控像是“事后诸葛亮”。它只会说:“现在下雨了,快收衣服!”但这时候衣服已经湿了。
智能预测的魅力:智能监控更像是“天气预报”。它会说:“根据云层变化,2小时后可能下雨,建议提前做好准备。”
AI是怎么做到的?
学习历史规律AI会分析过去几个月的数据,学习系统的正常模式:
- 工作日和周末的模式不同
- 白天和晚上的流量不同
- 促销期和平常期表现不同
- 系统更新前后的变化规律
提前发现异常当实际数据开始偏离“正常区间”时,AI能提前预警
时间:14:30 当前成功率:98.2% 正常区间:[98.5%, 99.8%] 结论:虽然还在“合格线”以上,但已偏离正常模式 预警:预计1小时后可能降至97%以下,建议提前检查
4.4 AI的边界:什么做,什么不做
很重要的一点是:AI不是万能的。在我们的设计中,AI有明确的边界:
AI做的(高价值决策):
- 分析趋势,预测风险
- 关联多个指标,找到根因
- 从历史中学习模式
- 生成解决方案建议
AI不做的(重复性工作):
- 逐条检查原始日志(量太大)
- 执行具体修复操作(风险太高)
- 完全自动做决策(需要人工确认)
- 替代人类专家(而是增强人类)
小结:给运维一双“慧眼”
如果说传统的监控系统给了运维人员“显微镜”(能看到细节),那么智能分析层就是给了他们“望远镜”(能看到趋势)和“X光机”(能看到内部关联)。
AI不是要取代运维人员,而是要增强他们的能力:
- 让新人能有老师傅的经验
- 让人脑能从重复劳动中解放
- 让决策能有数据支撑
- 让预防能走在故障前面
这就是智能分析层的核心价值:不是追求技术的酷炫,而是实实在在解决运维的痛点,让运维工作从“救火队”变成“预防站”,从“成本中心”变成“价值创造者”。
当AI成为运维团队的“第二大脑”,人们就能专注于更有创造性的工作,而机器则负责那些重复、繁琐但必要的任务。这样的人机协作,才是智能运维的真正意义所在。
本文由 @耶格 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


