
 起点课堂会员权益
起点课堂会员权益AI数字人为何还没走出“恐怖谷”与“成本坑”?——从0-1的实现到1-N的迷局深度复盘
2025 年数字人行业处于特殊节点,技术突破但商业普及未至。本文从技术架构、成本结构、交互体验、商业模式等多维度深度剖析其生存状态,探讨其面临的挑战与未来进化方向。

2025年的数字人行业,正处在一个充满悖论的历史节点。
一方面,技术侧的0到1早已突破。在过去几年,我们目睹了像“柳夜熙”这样的超写实虚拟KOL一夜之间席卷网络,凭借赛博朋克美学与传统文化的碰撞,在短短几小时内收割百万粉丝;我们见证了深圳福田区的政务数字员工在服务场景中的落地,它不仅拥有了面孔,更接入了DeepSeek等大模型的大脑,能够处理复杂的文档与政务需求。从可灵AI到NVIDIA的ACE引擎,生成式AI与实时渲染技术的结合,似乎已经为数字人的爆发备好了所有的火药。
然而,另一方面,商业侧的1到N——那个让数字人像智能手机或微信一样普及的“大规模爆发时刻”——却迟迟未到。对于大多数普通用户而言,数字人依然是发布会上的炫技表演,或者是只会机械复读的替身。中小企业主在面对动辄数万元的定制费用时望而却步,而C端用户在与数字员工交互时,常常因为几秒钟的延迟或眼神的空洞而感到“恐怖谷”效应的不适。
为什么技术的热度无法转化为市场的广度?为什么在SaaS和AI大模型满天飞的今天,拥有一个真正好用的数字分身依然是少数人的特权?本文将剥离掉资本市场的浮沫,从技术架构、成本结构、交互体验以及商业模式四个维度,深度复盘数字人产业在2025年的真实生存状态。
一、技术底座的割裂:“皮囊”易得,“灵魂”难寻
在讨论“普及”之前,我们必须先厘清“数字人”这个产品的本质。
在2025年的市场上,虽然都被冠以“数字人”之名,但从底层技术架构来看,存在着两条截然不同甚至互相鄙视的技术路线。这种技术路线的割裂,直接导致了用户体验的参差不齐和认知混乱。
我们要一个“生成的视频”,还是一个“渲染的角色”?
1. 2D视频派:基于Diffusion Transformer的降维打击
以HeyGen、可灵AI)、D-ID为代表的“2D派”,在2024-2025年间实现了爆发式增长。
- 技术原理:这派技术不构建三维模型,而是利用深度学习(如GANs或Diffusion Transformers)直接处理像素。它们通过学习海量的真人说话视频,建立音频与嘴型、面部肌肉的映射关系。当用户输入一段文字或音频时,算法驱动一张静态照片或一段预录视频,使其“动”起来。
- 核心优势(0到1的突破):门槛极低。用户不再需要昂贵的动捕设备,甚至不需要懂3D建模。只需一张照片,几分钟就能生成一段口型精准、表情自然的视频。Kuaishou的可灵AI 2.0模型甚至引入了3D时空注意力机制,使得生成的视频在物理规律和运动连贯性上达到了电影级质感。
- 致命缺陷(1到N的阻碍):不可交互性与视角锁定。这类数字人本质上是“视频流”。它们无法在虚拟空间中转身、行走或与环境互动。在直播或实时服务场景中,一旦涉及到复杂的实时反馈,2D模型往往会露馅,或者需要预录海量素材进行拼接,导致成本指数级上升。此外,所谓的“实时”往往是伪实时,受限于视频生成的推理速度,延迟问题始终是达摩克利斯之剑。
2. 3D引擎派:基于UE5与Volumetric的重资产构建
以Epic Games的Metahuman、NVIDIA ACE以及World Labs的Marble为代表的“3D派”,走的是一条完全不同的硬核路线。
- 技术原理:这是传统的游戏开发逻辑的AI化升级。它们构建完整的骨骼(Rigging)、网格(Mesh)和材质(Texture),并在Unreal Engine 5等引擎中通过光线追踪(Ray Tracing)进行实时渲染。NVIDIA的Audio2Face技术解决了面部动画的自动化问题,让AI可以直接驱动3D模型的面部肌肉 。
- 核心优势:真正的沉浸感与全场景适应性。3D数字人可以真正生活在虚拟世界中。它们可以行走、抓取物体,光影会随着环境变化而变化。World Labs提出的“空间智能”(Spatial Intelligence)概念,正是基于这种3D世界的构建能力,让数字人不仅有“脸”,还有对物理空间的感知能力。
- 致命缺陷:算力吞噬兽。要实时渲染一个照片级的UE5数字人,对显卡的要求极高(通常需要RTX 4090级别或云端A100集群)。这导致其难以在移动端普及。用户手机的算力根本跑不动如此复杂的资产,必须依赖昂贵的云端像素流推送,这直接推高了运营成本,限制了大规模推广。
“空心人”现象:大模型时代的记忆缺失
如果说“皮囊”的制作已经有解,那么“灵魂”的构建则是目前最大的技术瓶颈。风平智能(Fengping AI)在融资近亿元后的市场观察中尖锐地指出:90%的玩家仍停留在“壳阶段”。
这种“壳阶段”的典型表现是:
- 无状态的交互:大多数数字员工没有长期记忆。你今天告诉它你的名字和喜好,明天再来,它依然把你当陌生人。这是因为底层的LLM(大语言模型)虽然通晓天文地理,但缺乏针对特定用户的个性化记忆模块(Vector Database/Memory Stream)。
- 业务逻辑的断层:浦发银行的“小浦”虽然接入了AI,但在处理具体银行业务时,依然需要复杂的后台API对接。大模型可以生成漂亮的对话,但不敢让它直接操作转账。这种“能聊不能做”的尴尬,使得数字人在B端场景中往往沦为“高级吉祥物”。
缺乏“空间智能”:World Labs的Fei-Fei Li教授强调,真正的智能不仅是语言,更是对三维世界的理解。目前的数字人大多是“悬浮”在背景图上的,它们不知道身后的椅子能不能坐,也不知道桌上的杯子有多重。这种与环境的割裂感,潜意识里告诉用户:这是假的。
洞察:
技术侧的“0到1”解决了“像不像人”的问题,但“1到N”的卡点在于“是不是人”。在大规模普及前,我们必须解决低成本的实时渲染和带记忆的连续交互这两个核心技术难题。
二、成本结构的黑箱:谁在为昂贵的“数字员工”买单?
在很多企业主的幻想中,数字人是一次性投入、无限次使用的廉价劳动力。然而,数字人的成本结构远比雇佣一个真人要复杂,且充满了隐形的“陷阱”。
资本性支出:从免费到天价的阶梯
数字人的制作成本呈现出极端的两极分化。这种分化让市场充满了迷惑性信息。
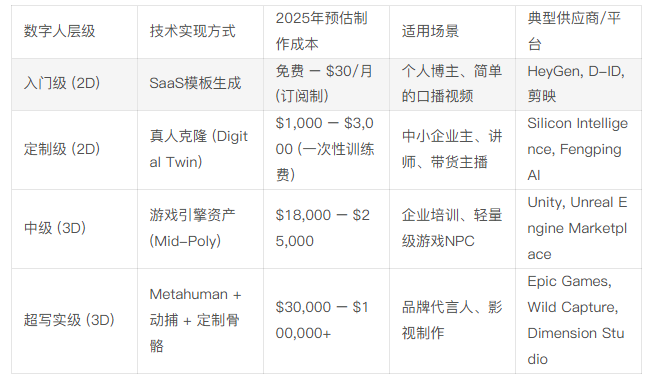
深度解析:
- SaaS的甜蜜陷阱:HeyGen等平台虽然打出了“免费开始”的旗号,但真正的商业功能(如高清导出、去水印、API调用)都锁定在昂贵的企业版中。对于希望大规模部署的企业来说,按分钟计费的模式(Usage-Based Pricing)可能比雇人还贵。Metronome的报告指出,企业采用按量付费往往是为了“防御性”地管理AI成本,因为AI推理的成本波动极大。
- “引擎税”的征收:对于希望自建3D数字人的企业,2024年Epic Games推行的“非游戏行业席位制收费”(每席位$1,850)无疑增加了研发成本。这意味着每一位参与数字人制作的艺术家、程序员都需要购买昂贵的软件许可,这对于中小型工作室是沉重的负担。
运营支出:看不见的“电费”与“算力费”
如果说制作费是买车的钱,那么运营费就是油钱。而数字人这辆车,是著名的“油老虎”。
1. 推理成本:每一次对话,数字人都在燃烧显卡。
- ASR(听):将语音转文字。
- LLM(想):调用GPT-4或DeepSeek生成回复。按Token计费。
- TTS(说):将文字转合成语音。ElevenLabs等高质量语音合成价格不菲。
- Audio2Face(动):实时驱动面部模型。
- 每一分钟的交互,背后都是数次API调用。对于高频互动的直播场景,这种持续的Token消耗是惊人的。
2. 流媒体传输成本:对于云端渲染的3D数字人,必须通过像素流(Pixel Streaming)将视频画面推送到用户终端。这相当于在看一场永不间断的4K Netflix直播,对带宽的消耗极大。相比之下,传统的Web页面或App几乎不占带宽。
3.人力维护成本:这可能是最讽刺的一点。深圳福田区的管理办法中明确规定,每位政务AI数字员工都有“监护人”。这意味着,企业不仅要花钱买AI,还要花钱雇人看着AI。虽然AI处理文档效率提升了90%,但“监护人”的存在说明AI尚未实现完全的无人值守(Unattended Automation),人力成本并没有完全归零,只是发生了转移。
洞察:
数字人尚未普及的根本经济原因在于ROI的倒挂。在低端市场,它比真人便宜,但效果差(僵硬、弱智);在高端市场,它效果好,但比真人还贵(制作+算力+维护)。
三、体验的鸿沟:为什么我们依然讨厌和机器说话?
数字人之所以还在“恐怖谷”徘徊,核心在于当下的交互体验不仅未能超越真人,甚至在很多维度上是一种降级。
延迟:互动的杀手
人类的对话是毫秒级的博弈。我们会在对方话音未落时点头,在停顿的瞬间插话。然而,2025年的数字人架构中,普遍存在1-3秒的交互延迟。
- 技术链路:用户说话 -> 云端识别 -> LLM思考 -> TTS合成 -> 视频驱动 -> 传输回用户。
- 体验崩溃点:这几秒的空白(Dead Air)是致命的。在这几秒钟里,数字人通常会维持一个尴尬的“待机动画”(微弱的呼吸或眨眼),这种违和感瞬间打破了沉浸感,提醒用户:“你在和一个程序对话。”哪怕画面再逼真,这种节奏的断裂感也会让用户产生心理排斥。
恐怖谷效应的新变种:行为恐怖谷
传统的恐怖谷是指外貌“像人又不像人”带来的恐惧。现在的数字人面临的是“行为恐怖谷”。
- 眼神的空洞:虽然Kling-Avatar等模型在唇形同步上做到了极致(GSB评分优异),但微表情(Micro-expressions)依然是短板。人类在思考时眼球会微动,在撒谎时瞳孔会变化,在共情时眉毛会微蹙。目前的AI很难在实时交互中精准合成这些潜意识层面的信号。
- 动作的机械:浦发银行的“小浦”虽然能办理业务,但在面对用户愤怒或焦急的情绪时,依然保持着标准的职业假笑。这种情绪反馈的错位(Emotional Dissonance),比面无表情更让人恼火。
质量评估的混沌:GSB标准的局限
快手团队在Kling-Avatar的研究中引入了GSB(Good-Same-Bad)评估体系,试图量化视频生成的质量 。
- Good:视频连贯,符合物理规律。
- Same:与基准模型持平。
- Bad:出现画面崩坏、动作鬼畜。
然而,这套标准更多关注的是视觉层面的合格,而非交互层面的优秀。对于一个C端用户来说,数字人不仅要“不崩坏”,还要“懂我”。目前的评估体系中,严重缺乏对“情感共鸣”、“记忆连续性”和“语境理解”的量化指标。这导致市面上充斥着大量GSB评分很高,但用户聊两句就想关掉的“高分低能”产品。
四、商业战场的突围:中国式的“实用主义”与西方的“工具主义”
尽管普及受阻,但全球的科技公司并未坐以待毙。在2025年的商业版图上,我们看到了两种截然不同的突围路径,分别以中国和美国市场为代表。
中国模式:直播间里的“数字劳工”
在中国,数字人的落地具有极强的实用主义色彩,最核心的战场是电商直播。
代表玩家:硅基智能、风平智能、腾讯、快手。
商业逻辑:极致的降本增效。一个真人主播不能24小时工作,会生病,会跳槽。而像硅基智能提供的AIGC数字人,可以手持商品,用多国语言全天候直播。风平智能更是打出了“让AI替你打工”的口号,专注于IP智造和短视频带货。
市场现状:这是一场红海战争。硅基智能声称拥有南京等地的巨大市场份额,而风平智能则在融资后加速产品矩阵优化。这些数字人不需要通过图灵测试,只要能卖货就行。
成功关键:场景的容错率高。直播间本身就是强干扰环境,用户关注的是商品而非主播的微表情。加上手机屏幕较小,掩盖了数字人的许多瑕疵。因此,中国市场的“1到N”在直播带货领域其实已经悄然完成。
西方模式:SaaS化的“视频PPT”
在欧美市场,以HeyGen、Synthesia为代表的公司更倾向于将数字人打造为生产力工具。
- 代表玩家:HeyGen, Synthesia, NVIDIA (底层支持)。
- 商业逻辑:内容生产的民主化。它们的目标不是替代直播主播,而是替代视频制作团队。企业用它来制作入职培训视频、营销邮件(Vidyard集成)或多语言产品介绍。
- 市场现状:HeyGen通过API和企业级服务(SSO、审计日志)切入大客户市场,强调数据安全和品牌一致性。
局限:这种模式本质上是“视频生成的进化”,而非“数字生命的诞生”。它解决了信息传递的效率问题,但没有解决情感连接的问题。
五、信任与伦理的迷雾:我们敢把灵魂交给AI吗?
即便技术完美、成本低廉,横亘在数字人普及之路上的最后一道关卡是信任。
“复活”的诱惑与禁忌
利用AI“复活”逝者在2025年已成为现实。有些哀悼者使用硅基智能等公司的技术数字化逝去的亲人。这虽然带来了情感慰藉,但也引发了巨大的伦理争议:
- 所有权问题:逝者的数字形象归谁所有?家属?平台?
- 尊严问题:如果“复活”的亲人被用来推销商品,这是否是对死者的亵渎?
这种伦理上的不确定性,让主流社会对数字人的深度应用保持警惕。
“监护人”制度的启示
深圳福田区的“监护人”制度揭示了一个核心法律困境:责任归属。
如果一个AI理财顾问给出了错误的投资建议导致用户亏损,谁负责?是AI开发商?是部署AI的银行?还是那个不仅没看住AI、可能还在摸鱼的“人类监护人”?
只要责任主体不明确,大企业就不敢将核心业务(如医疗诊断、大额金融交易)完全交给数字人。这就限制了数字人只能做“端茶倒水”的边缘工作,无法触及高价值场景,自然也就无法获得高价值回报,从而陷入“低效能-低投入”的死循环。
六、破局展望:从“复读机”到“智能体”的进化之路
数字人要实现从“1到N”的大规模普及,不能仅仅依赖更逼真的皮肤,而需要一场从内到外的彻底进化。
空间智能(Spatial Intelligence):让数字人落地
World Labs的尝试指明了一个方向:世界模型。数字人需要理解物理世界。未来的数字人不再是视频里的贴片,而是能感知光影、重力和物体关系的实体。当数字人能真正“看见”并“理解”它所处的环境时,交互的真实感将产生质的飞跃。
边缘计算(Edge AI):把大脑装进手机
要解决成本和延迟问题,必须将算力下沉。NVIDIA的RTX AI PC和手机端侧大模型(如高通、苹果的NPU)是关键。当用户的手机就能实时渲染3D数字人并运行7B参数的小模型时,云端推理的高昂成本将不复存在,延迟也将降低到毫秒级。那才是数字人真正普及的时刻。
Agentic AI:从对话到行动
数字人必须从“聊天机器人”进化为“代理人(Agent)”。它不仅要能陪聊,还要能帮我订票、发邮件、做Excel。当浦发银行的“小浦”能直接帮我抢到理财产品,而不是告诉我理财产品的条款时,用户才会真正离不开它。
结语
2025年的数字人,像极了2006年的智能手机——硬件已经就绪,但杀手级的“iPhone时刻”尚未到来。
我们有完美的渲染引擎(UE5),有强大的大脑(LLM),有高效的生产线(Kling/HeyGen),但它们依然是散落的珍珠,缺乏一根将其串联起来的线。这根线,可能是更低廉的端侧算力,可能是更具空间感的交互设计,也可能是一套完善的法律伦理框架。
对于产品经理而言,现在的机会不在于造出更帅更美的模型,而在于寻找那个“由于缺乏情感连接而效率低下”的场景,并用“有记忆、懂业务、低延迟”的数字人去填补它。
数字人不会取代人类,但会使用数字人的人,终将取代那些拒绝拥抱变化的人。这场从0到1的战役已经结束,而通往1到N的征途,才刚刚开始。
本文由 @DaisyXX 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供





- 目前还没评论,等你发挥!


