
 起点课堂会员权益
起点课堂会员权益从0到1搭建医疗AI产品评测体系(一)
医疗AI产品经理常遇实验室指标与临床实效错位的困境。为填补此鸿沟,需建立全面评测体系。本文剖析了医疗AI产品力的三层架构及核心评测指标,助您理解如何打造高效实用的医疗AI产品。

1.为什么我们需要一套全面的医疗AI产品评测体系?
每一位深耕医疗AI的产品经理,或许都经历过这样的“至暗时刻”:我们在离线测试集上跑出了近乎完美的AUC或F1分数,满怀信心地将模型推向临床,却迎来了医生们接踵而至的抱怨与投诉。面对这种落差,我们往往习惯性地将其归咎于“模型泛化性不足”或“数据长尾效应”。
然而,真正深层次的问题在于“评价语境的错位”——即“实验室指标”与“临床实效”之间的断层。
医疗场景的复杂度远超通用领域,这种错位并非仅仅是数据分布的差异,更在于我们忽略了临床决策中那些不可量化却至关重要的因素:
- 输入端的噪声容忍度: 测试集往往是“精修”的黄金标准数据,而临床现场充满了各种“脏数据”——影像中的伪影、不同品牌设备的参数差异、病历中模糊的口语化描述,模型能否在这些干扰下依然表现稳健?
- 决策维度的单一性 vs 复杂性: 模型通常针对单一病种训练,而真实的患者往往伴随多病共存。一个在肺结节检测上满分的模型,如果忽略了旁边的严重肺炎或伪影干扰,在医生眼中就是“添乱”。一个在超声甲状腺结节测试集中检出率很高的模型却无法识别桥本这种弥漫性病变。
- 交互的容错与效率: 在NLP问答中,模型给出的“正确答案”如果缺乏同理心,或者在急救场景下输出过于冗长,不仅无法辅助诊疗,甚至可能引发医患纠纷或延误时机。
我们太习惯盯着实验室里的“数字”,却忽略了临床现场的“实效”。为了填补这道鸿沟,我们需要跳出单一维度的模型指标,建立一套真正能还原产品全貌的分层评测体系。
2.AI产品力的三层架构:从引擎到座舱
决定一台车好坏的,绝不仅仅是发动机参数,而是整车的综合体验。医疗AI产品力同样可以拆解为三个核心模块:
第一层:模型层(核心引擎)——决定“上限”
就像汽车的发动机,我们关注马力(AUC/Accuracy)和扭矩(敏感性/特异性)。这是驱动AI产品运行的原动力,解决的是“准不准”的基础能力问题。但光有大马力引擎如果装在三蹦子上,不仅跑不快,还可能导致翻车。
第二层:架构层(底盘与传动)——决定“下限”
这一层负责将引擎的动力平稳地转化为轮上的速度。在医疗AI产品中,它对应的是工程架构的稳定性、推理延迟、对不同硬件环境的适配能力,以及面对脏数据和并发请求时的容错机制。它解决的是“跑得稳不稳”的问题,确保模型在任何复杂的临床“路况”下都不趴窝。
第三层:交互层(智能座舱)——决定“体验”
这是用户直接接触的部分。就像驾驶舱的布局、座椅的舒适度、仪表盘的可读性。在医疗AI产品中,它对应的是辅助诊断结果的呈现方式、可解释性、以及与医生工作流(Workflow)的融合程度。它解决的是“用得顺不顺”的问题,直接决定了医生是把AI当成“得力副驾”还是“碍事累赘”。
3.核心评测指标解释
1. 模型层
分类任务
分类任务的指标都是建立在混淆矩阵基础上建立的,首先需要对这个矩阵非常熟悉,通常我们把关注的样本类别作为正样本,比如我们要做一个良恶性分类,通常把恶性样本归为正样本(阳性),良性样本归为负样本(阴性)。
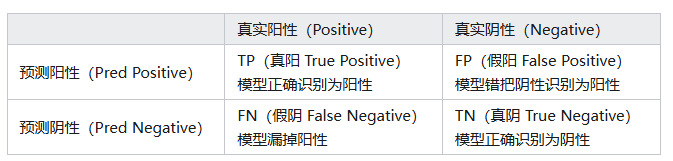
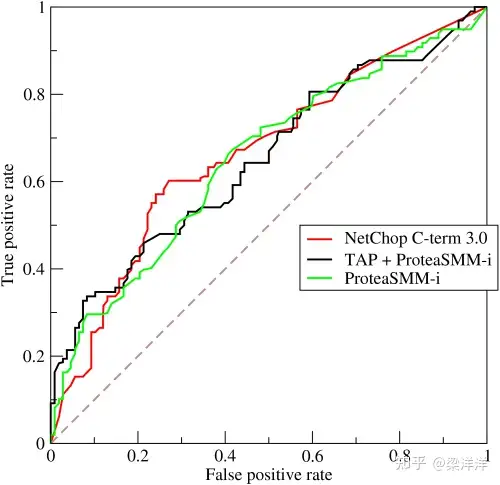
实际评测模型表现的时候,通常分为两个维度:第一个是对模型综合分类能力的评估(与阈值选取无关),这类指标不需要预设阈值,而是通过遍历所有可能的阈值(从0到1),来评估模型的整体排序能力和泛化潜力。最常用的就是AUC值,它代表以假阳性率(FPR=FP / (FP + TN))为横轴,真阳性率(TPR=TP / (TP + FN))为纵轴绘制曲线(ROC)围成的面积。
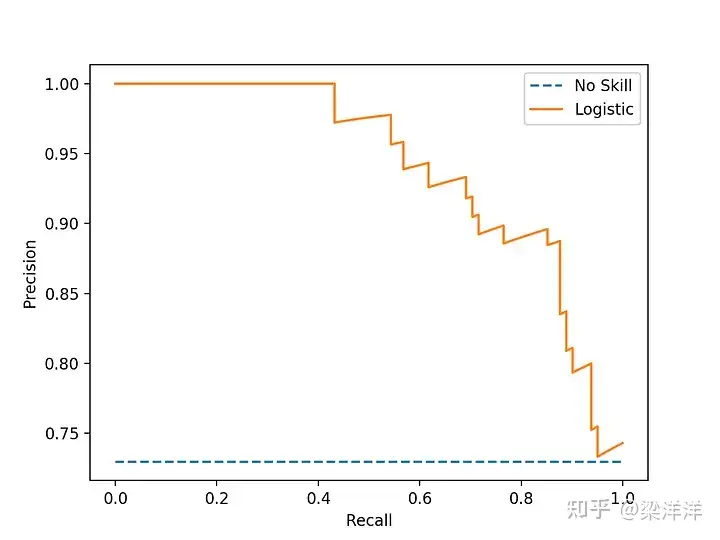
但是ROC曲线在样本分布不均的时候就有问题了,比如正样本非常多,负样本特别少的情况下结果会看起来虚高,这个时候就推荐用PR曲线,它是以召回率(Recall=TP/(TP+FN))为横轴,精确率(Precision=TP/(TP+FP))为纵轴绘制的曲线,该曲线下的面积即为AP值(通常通过积分或插值计算)。与AUC-ROC不同,AP值高度关注正样本的表现。在正样本极少(如<1%)的情况下,AP比AUC更能真实反映模型的有效性。
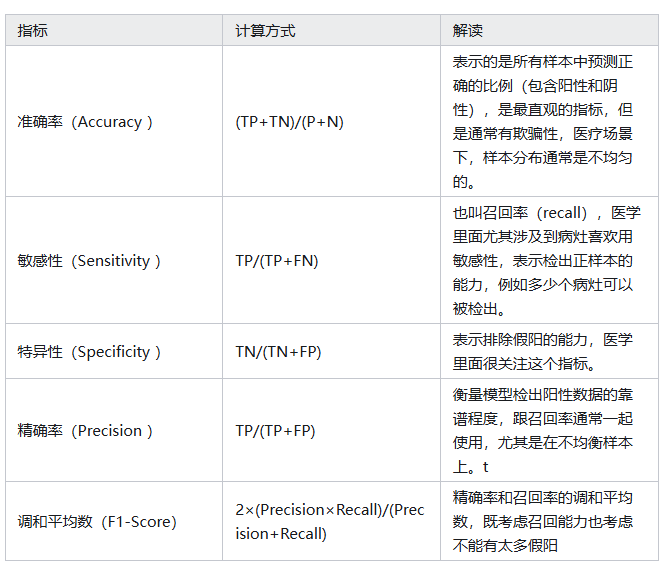
第二个维度就是给定具体的分类阈值(Threshold)进而计算出来的指标,常用的有以下几个:
除了医学影像相关的,大部分医疗AI任务都是分类任务,用这套分类指标足以覆盖大多数场景。
图像分割
图像分割(Image Segmentation)是一种计算机视觉任务,它的目标是把图像中的每个像素分类或标记,从而把图像分成不同的区域或物体。通常在医疗影像分析场景上使用,本质也是分类只不过是像素级别的分类,医学分割任务常用 Dice 作为评估指标,其计算方法如下:
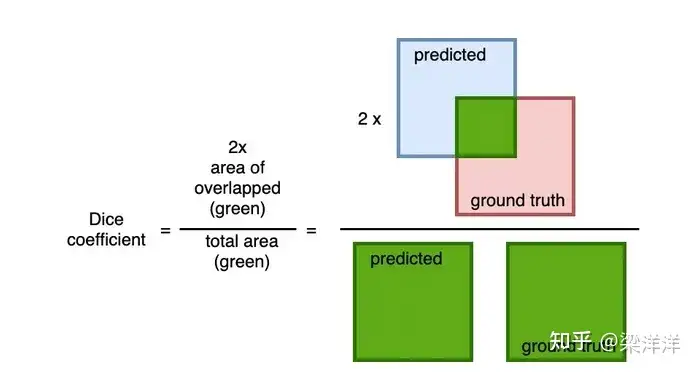
*Dice通常也作为分割任务训练中的损失指标, 定义为 1 — Dice_Coefficien
为什么不采用分类指标比如准确率、召回率这些?因为在分割任务中目标和背景的空间关系很重要,我们不能只考虑目标像素的数量,而不考虑预测的形状和重叠情况。另外一个重要的原因是目标区域比如某个病灶通常占整个图像的比例很低,假设有一张 100×100 的图像,要分割一个小的病灶区域(比如 5×5 的像素块),如果模型全预测为背景,也就是把 25 个病灶像素预测错了,但剩下 9975 个背景依然算预测对了,看起来99.75% 的准确率挺高其实模型啥也没学到。
目标检测
目标检测是预测与真实目标的重叠程度的任务,输出是目标的边界框 + 类别标签,所以评估他的表现时必须考虑位置精度,通常以IoU作为核心指标,IoU类似dice也是一个计算重叠度的指标,但是没有像素级别的分类,对于小目标或长条目标,用Dice 预测对微小偏移会非常敏感。
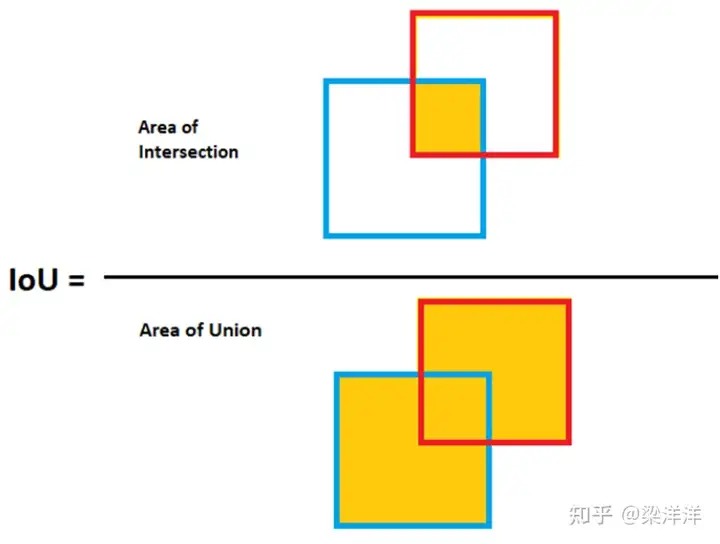
其他指标如Precision / Recall/mAP(多目标检测)也经常用于辅助评估检测模型的性能,这几个指标在分类任务中已经介绍过,不再重复赘述。
回归任务
回归任务不像分类那样非黑即白,它是对连续数值的预测。在医疗场景中,使用的比较少,主要指标就是平均绝对误差(MAE)、均方误差(MSE)和均方根误差(RMSE)。
2. 架构层
模型层关注的是“算法的理论上限”,那么架构层关注的就是“工程落地的下限”。就像汽车的底盘,平时看不见,但决定了车子在烂路上会不会散架。架构层主要有以下几个核心指标:
- 延迟:发起请求到获得AI结果的占用时间,有时候医生点一下按钮,转圈超过3秒,焦虑感就会倍增。对于急诊或实时诊断的超声场景,高延迟的产品几乎没有价值。
- 并发:系统每秒能处理的请求数,比如病灶检测模型可以同时处理多少个数据。
- 资源利用率:模型运行所需的显存、内存及CPU占用率,过高说明不稳定,过低又浪费,尤其在医院本地部署模型的场景下需额外关注。
- 鲁棒性:模型鲁棒性(Model Robustness)指的是一个模型在面对各种干扰、噪声、异常或未见过的数据时,仍然能够保持性能稳定的能力。这是实验室最难测出来的,典型场景是医学影像分析任务,存在大量的高伪影、高噪声图像是难免的,能否保持高鲁棒性也是考量模型性能的重要指标之一。
3. 交互层
坦白讲,这其实是最容易被算法工程师忽略,而产品经理最该发力的地方。
- 临床采纳率:医生实际点击、引用或保留AI结果的比例,在AI辅助写病历或生成报告结论时,如果AI生成了一段话,医生直接点击“插入报告”,这就是一次有效采纳, 用户最终的“行为”才是衡量AI是否真正产生价值的“金标准”。模型AUC再高,如果采纳率低,说明AI给出的结果肯定不是医生想要的(比如废话太多,或者幻觉不对等)。
- 修改率:医生在采纳AI结果后,但是做了修改的比例。尤其是对于生成式AI(LLM)场景中,如果AI写了100字,医生删改了80字,虽然最终用了,但这并没有显著提高效率。即使采纳率高,如果修改率也高,说明AI解决问题不彻底,对用户来讲没有明显的效率提升。
- 交互耗时:使用AI后的全流程耗时 vs 不使用AI的全流程耗时对比。比如肺结节检测模型虽然帮医生画出了结节,但假阳比较多的情况下医生为了确认每个结节是对是错,需要反复确认,可能导致总阅片时间反而增加了。
- 可解释性:不仅仅告诉医生是什么,还要告诉医生为什么,这个尤其在医疗场越来越讲究“循证”的背景下显得极为重要,但是目前这个也是比较难解决的一个点。
4.结语
我们对医疗AI评测体系重要性的框架、指标做了初步的总结,在实际应用中应当结合具体的产品场景和技术架构来选择相应的评估指标和评测方法,比如NLP任务和CV任务的评价测指标和评测方法就有很大差别,在LLM基础上的Agent和RAG技术架构会产生很多其他的中间评测指标,很难笼统的一次讲完,接下来我将针对具体的医疗AI产品形态,拆解更详细的评测流程。
本文由 @Leo 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


