
 起点课堂会员权益
起点课堂会员权益【伊利亚】一句话戳醒我:7.8 万亿烧尽的 AI 狂欢,连神坛都没站稳就被数据墙掀了!
本文深入探讨了AI行业从堆料狂欢到研究文艺复兴的转变,揭示了算力并非万能的真相,并提出了小团队在新研究时代下的逆袭策略。
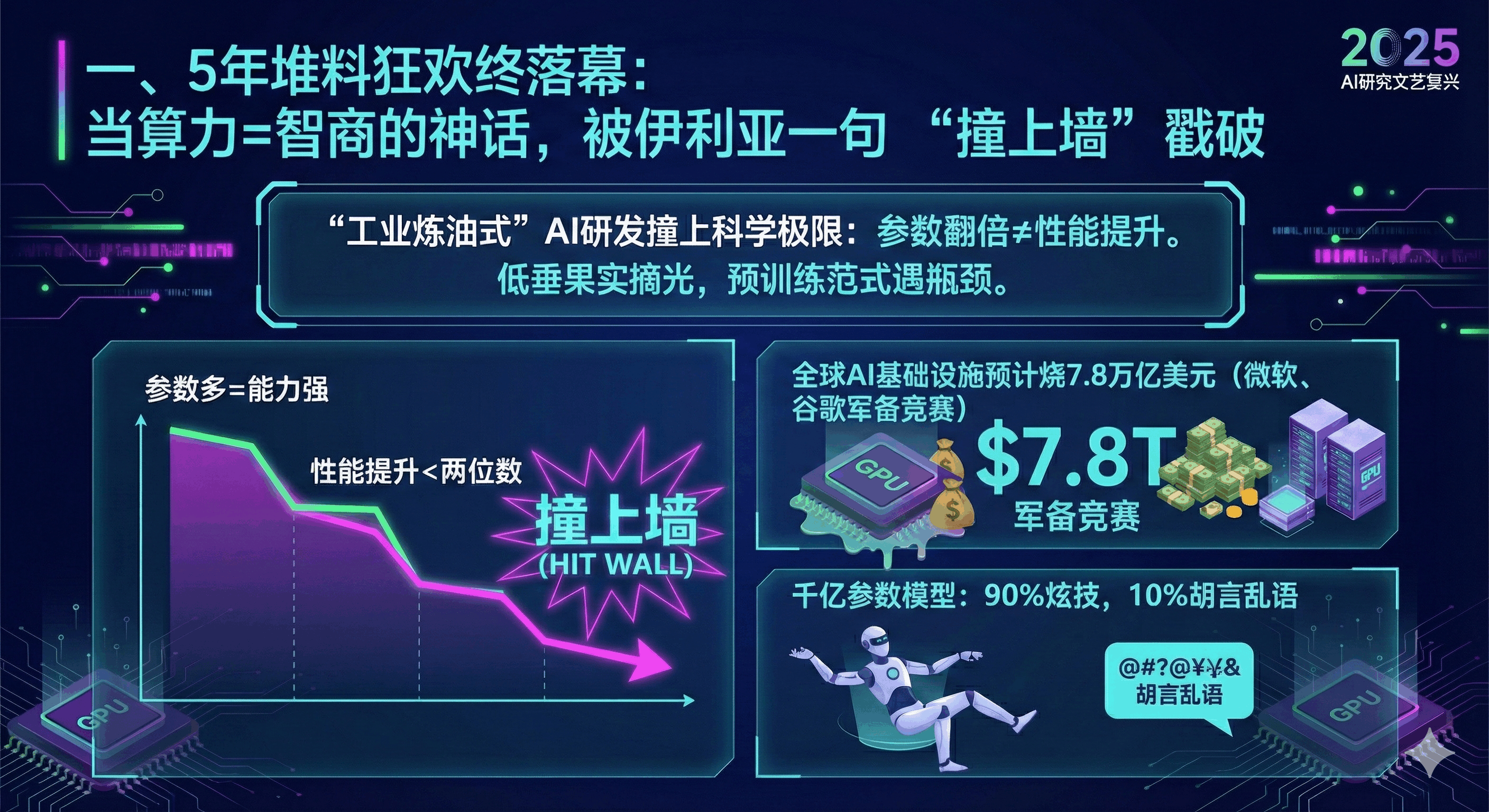
一、5 年堆料狂欢终落幕:当算力 = 智商的神话,被伊利亚一句 “撞上墙” 戳破
2020 到 2025 这 5 年,AI 行业像被按下了 “堆料快进键”:巨头们信奉 “参数多 = 能力强”,拼着砸钱买 H100、建千兆瓦数据中心,仿佛只要算力堆到极致,智能就会自动涌现。全球 AI 基础设施预计要烧到 7.8 万亿美元,微软、谷歌带头掀起 “军备竞赛”,连产品经理的 KPI 都变成了 “模型参数破万亿”。但听完伊利亚的访谈我才猛然惊醒:这种 “工业炼油式” 的 AI 研发,早就走进了死胡同。他直言不讳的 “我们撞上了墙”,不是芯片不够用,而是预训练范式的科学极限 —— 低垂的果实早被摘光,翻倍预算再也换不来两位数的性能提升。
我曾天真以为 “更大模型 = 更好体验”,直到做企业服务时发现:客户要的不是能写诗歌的 AI,而是能稳定修 bug、不出错的工具。那些千亿参数模型,90% 的时间在炫技,10% 的时间在胡言乱语,反而需要我们投入更多人力监督,完全背离了 “降本增效” 的初衷。
二、两大死穴戳穿谎言:数据挖空了,模型偏科到离谱
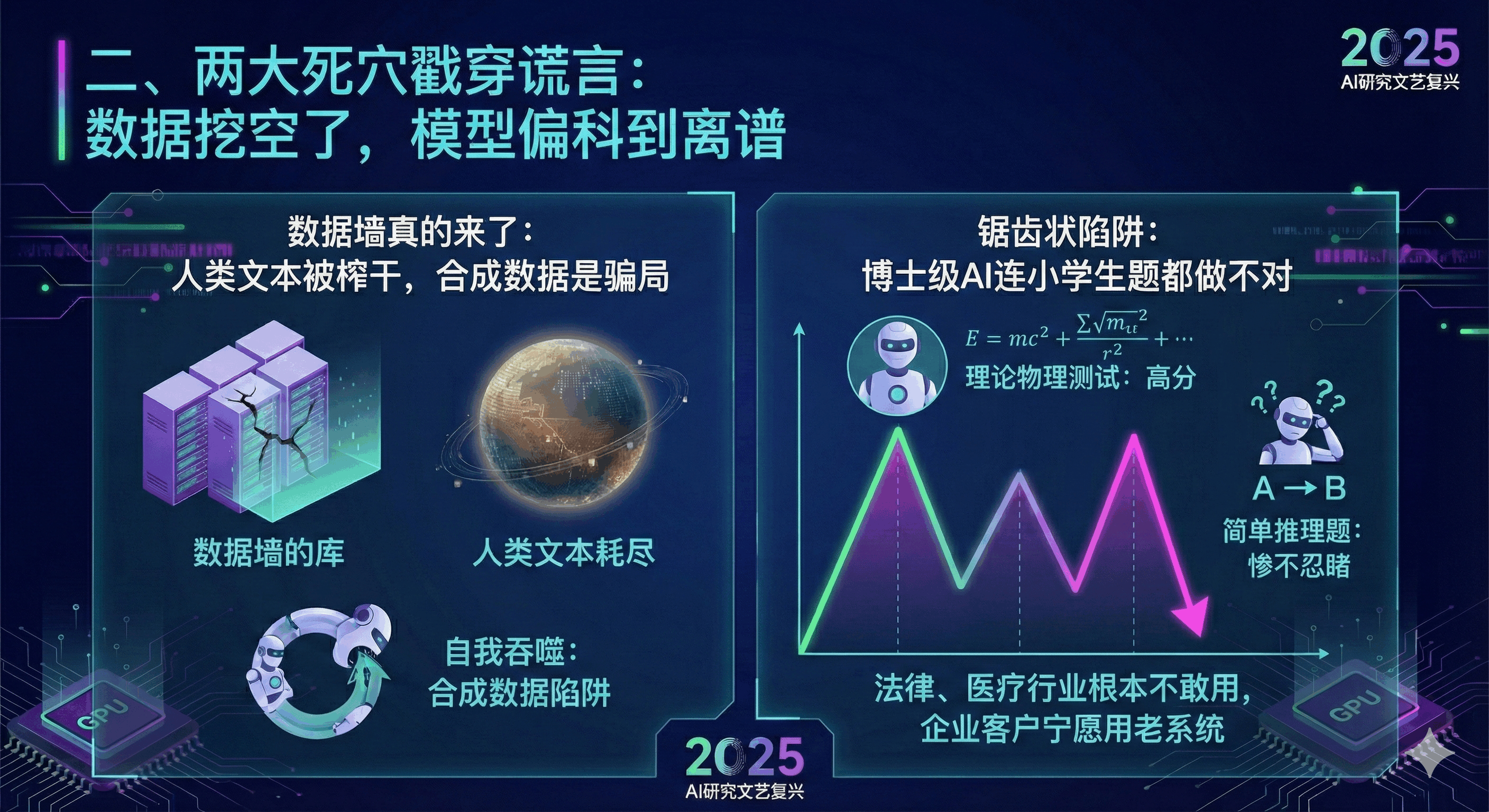
伊利亚的访谈让我看清了规模化时代的两个致命问题,这也是我做产品时最头疼的痛点:
数据墙真的来了:人类文本被榨干,合成数据是骗局
“文本数据是有限的,我们已经爬完了整个互联网”—— 伊利亚这句话颠覆了行业共识。Epoch AI 的预测更扎心:按当前节奏,公共人类文本 2026-2032 年就会耗尽,部分模型 2025 年已触顶。
过去我们做产品,总想着 “多喂数据就能优化效果”,但现在才发现:互联网的高质量知识矿脉已经挖空了。
更坑的是 “合成数据”—— 用 AI 生成的文本训练新 AI,就像让学生抄同学的作业再交差,只会陷入 “自我吞噬”:模型越来越偏爱安全废话,砍掉创新表达,5 代之后就变成 “语法满分、毫无洞察” 的平庸机器。
锯齿状陷阱:博士级 AI 连小学生题都做不对
规模化时代的另一个谎言,是 “参数够多 = 通用智能”。但伊利亚举的例子太扎心了:模型能搞定理论物理测试,却修不好 “改 A bug 出 B bug” 的循环;MMLU 得分超 85% 的模型,在 225 道简单推理题上惨不忍睹。
这正是最崩溃的点:花大价钱接入千亿模型,结果它能写复杂报告,却算不清简单的库存逻辑;能翻译外文,却理解不了用户的模糊需求。这种 “偏科绝症” 让 AI 在关键场景完全不靠谱 —— 法律、医疗行业根本不敢用,企业客户宁愿用老系统,也不想冒 “AI 乱决策” 的风险。
三、研究文艺复兴:伊利亚说的 “黄金时代”,小团队的机会来了
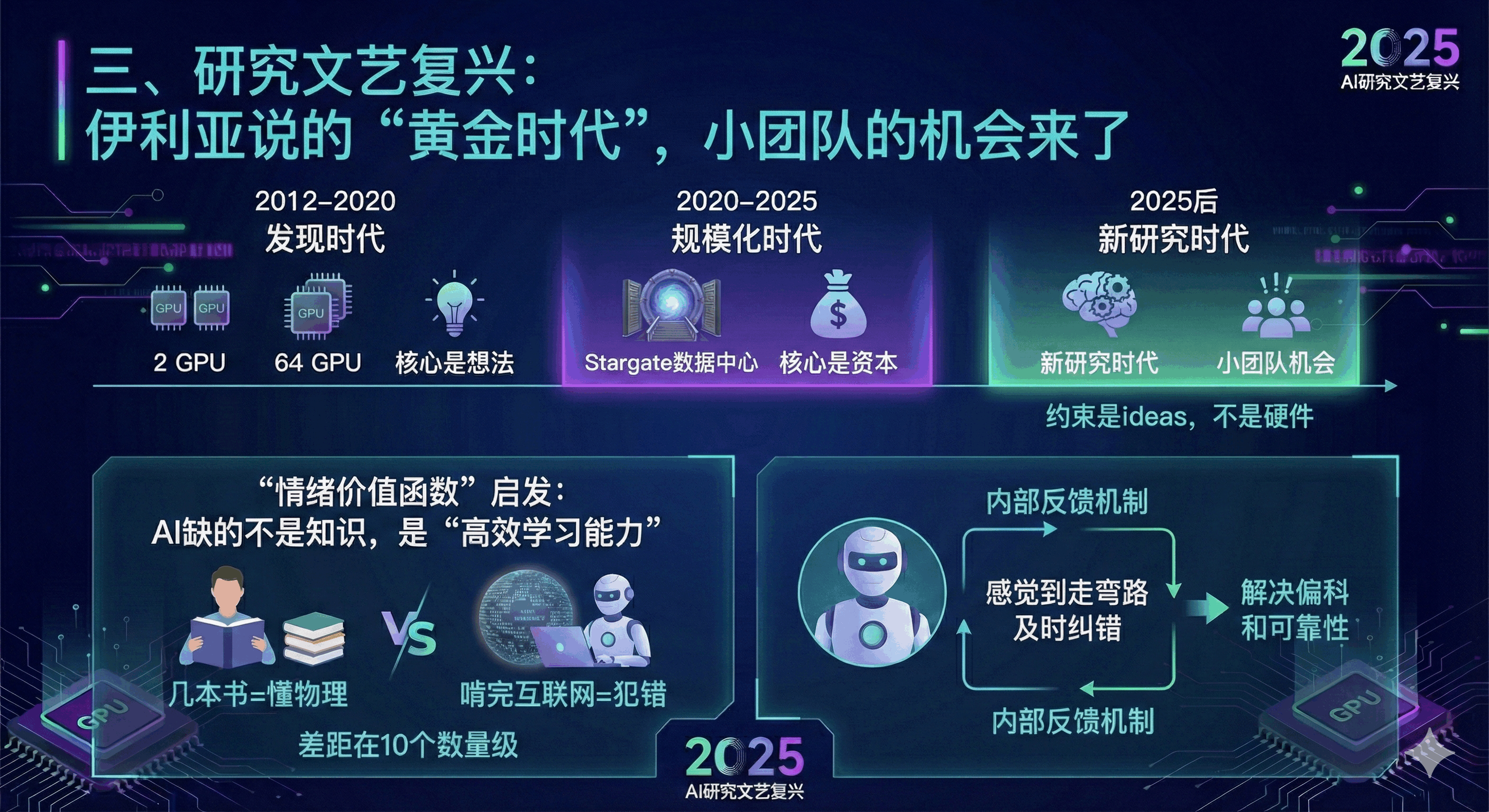
“我们重新进入了研究的黄金时代”—— 伊利亚的这句话,让我看到了 AI 产品的新方向。他把行业分成三个阶段,戳破了 “算力神话”:
- 2012-2020(发现时代):AlexNet 用 2 块 GPU、Transformer 用 64 块 GPU 改变行业,核心是想法;
- 2020-2025(规模化时代):堆算力堆数据,核心是资本;
- 2025 后(新研究时代):约束条件是 ideas,不是硬件。
过去我们总被 “没算力没数据” 困住,但现在发现:巨头忙着建 5000 亿的 Stargate 数据中心,根本没精力做算法创新;而我们只要抓住 “样本高效学习” 这个核心,就能弯道超车。
伊利亚的 “情绪价值函数” 假设给了我很大启发:AI 缺的不是知识,而是像人类少年一样的 “高效学习能力”—— 人类读几本书就能懂物理,AI 却要啃完整个互联网还犯错,差距在 10 个数量级。未来的 AI 产品,不该再追求 “喂更多数据”,而是让 AI 拥有 “内部反馈机制”:比如思考时能 “感觉到” 自己走弯路,及时纠错,这才是解决偏科和可靠性的关键。
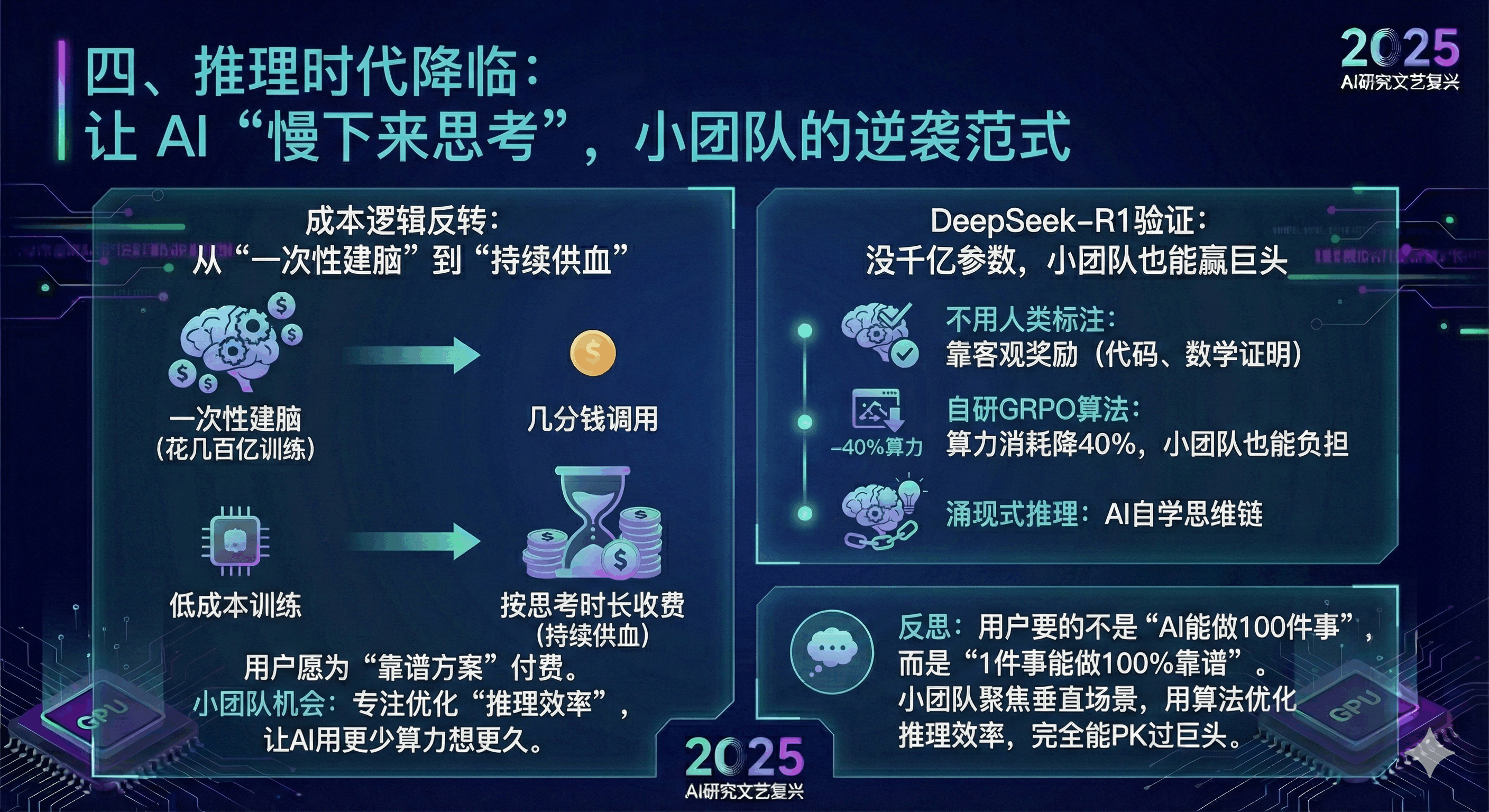
四、推理时代降临:让 AI “慢下来思考”,小团队的逆袭范式
伊利亚的访谈明确了下一个方向:AI 要从 “快思考”(模式匹配)转向 “慢思考”(逻辑推理)。这对我们做产品来说,是彻底的思路革新 —— 不再比 “谁的模型大”,而是比 “谁的 AI 想得更清楚”。
成本逻辑反转:从 “一次性建脑” 到 “持续供血”
规模化时代是 “花几百亿训练,几分钱调用”;推理时代是 “低成本训练,按思考时长收费”。比如让 AI 解决复杂工程问题,可能要生成 10000 个推理 token,成本从 1 分钱涨到几美元,但用户愿意为 “靠谱方案” 付费 —— 这正是小团队的机会:不用砸钱训练大模型,专注优化 “推理效率”,让 AI 用更少算力想更久,就能做出差异化产品。
DeepSeek-R1 验证:没千亿参数,小团队也能赢巨头
2025 年 DeepSeek-R1 的爆发,给我们打了强心针。这家资源远不如微软、谷歌的公司,用纯 RL(强化学习)实现了逆袭,核心突破太值得产品人借鉴:
- 不用人类标注:靠 “代码能运行、数学证明成立” 的客观奖励训练,避开标注噪声和高成本;
- 自研 GRPO 算法:把算力消耗降了 40%,小团队也能负担;
- 涌现式推理:AI 自己学会了 “思维链”,不用我们手把手教。
这让我反思:我们做 AI 产品,是不是太执着于 “堆功能”?其实用户要的不是 “AI 能做 100 件事”,而是 “1 件事能做 100% 靠谱”。小团队聚焦某个垂直场景,比如 “AI 数学推理”“代码纠错”,用算法优化推理效率,完全能 PK 过巨头的 “万能模型”。
五、两大阵营生死赌局:我们该站哪一队?
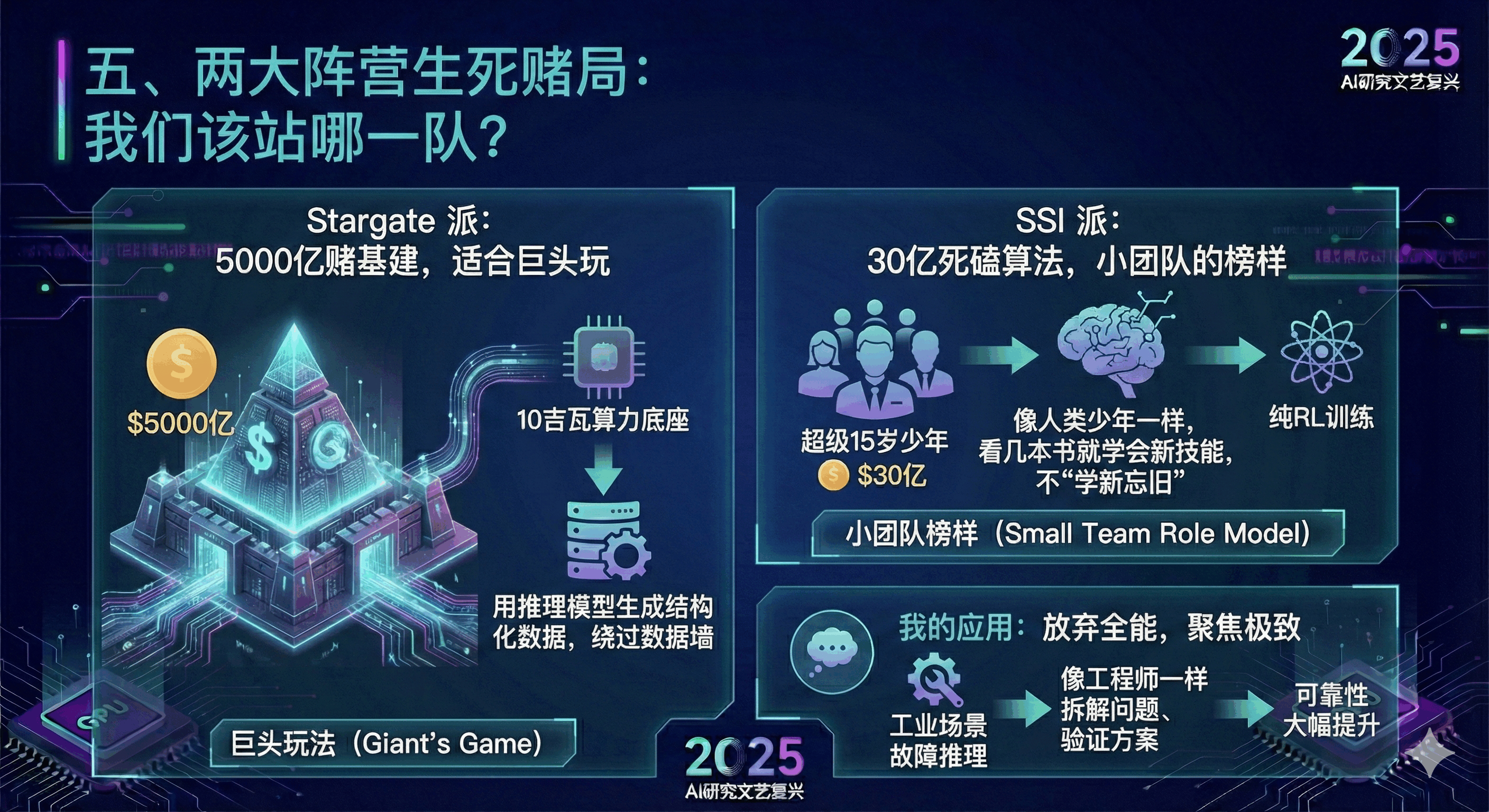
伊利亚访谈后,行业分裂成两大阵营,这也决定了 AI 产品的不同方向:
Stargate 派:5000 亿赌基建,适合巨头玩
OpenAI、软银搞的 Stargate 数据中心,花 5000 亿建 10 吉瓦算力底座,赌的是 “用推理模型生成结构化数据,绕过数据墙”,同时抢占主权算力市场。这种重资产玩法,小团队根本玩不起,也没必要跟风 —— 我们不可能比巨头更有钱,只能换赛道。
SSI 派:30 亿死磕算法,小团队的榜样
伊利亚离开 OpenAI 创办的 SSI,走了 “反行业” 路线:不做产品、不接订单,30 亿融资全砸在 “超级 15 岁少年” 目标上 —— 让 AI 像人类少年一样,看几本书就学会新技能,不 “学新忘旧”。
这给我们的启发是:小团队要 “放弃全能,聚焦极致”。我现在调整了产品方向:不再做通用 AI 助手,而是专注 “工业场景故障推理”,用纯 RL 训练模型,让它能像工程师一样拆解问题、验证方案,虽然场景窄,但可靠性大幅提升。
六、产品人终极反思:2025 后,AI 产品该怎么玩?
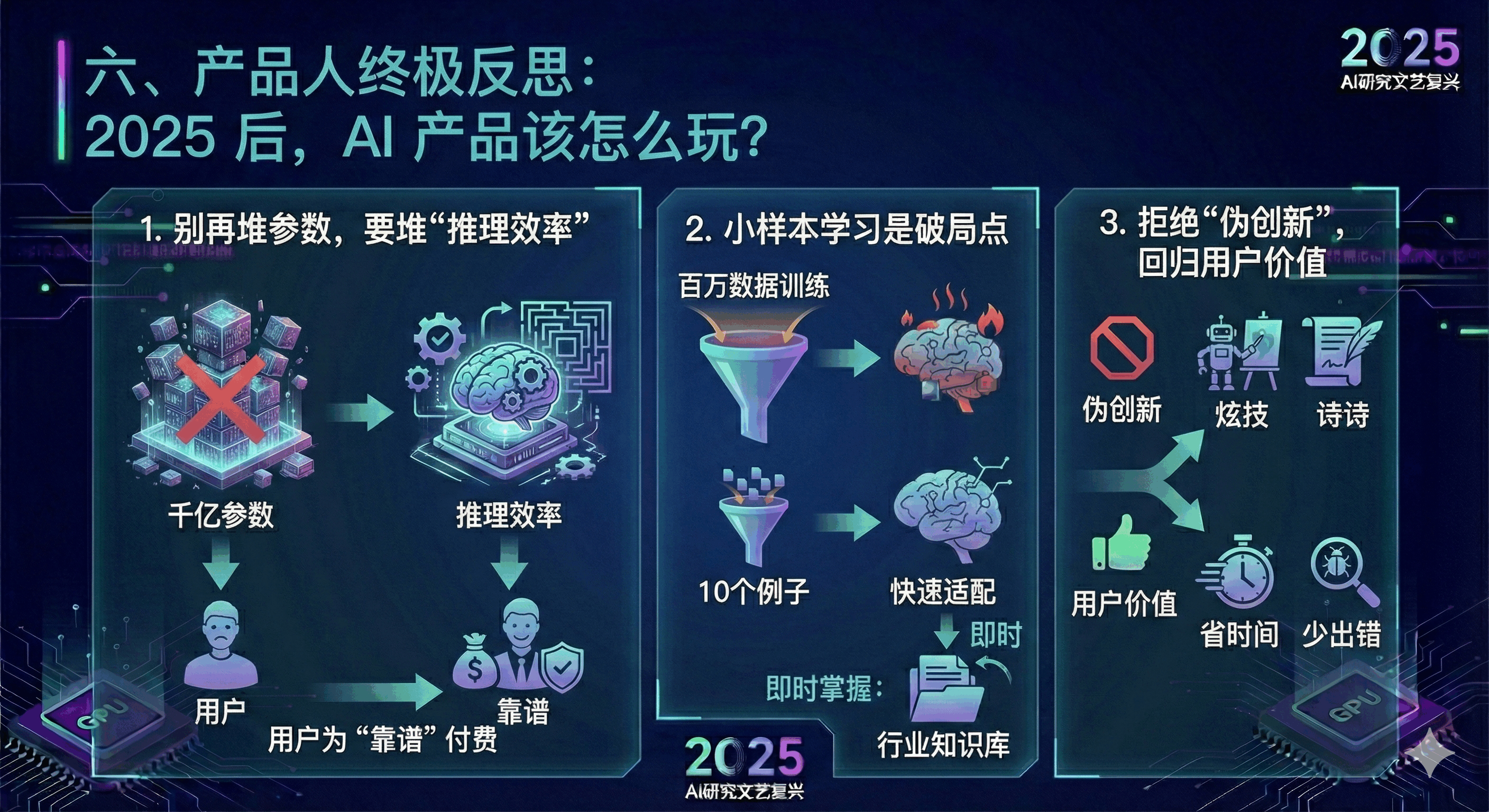
读完伊利亚的访谈,我彻底放弃了 “追逐大模型” 的执念,总结了 3 条实操建议,适合所有 AI 产品人:
别再堆参数,要堆 “推理效率”
用户为 “靠谱” 付费,不为 “参数” 付费。比如做客服 AI,不用接入千亿模型,而是优化推理逻辑,让它能 10 步内定位用户问题,比 “能说会道但解决不了问题” 的大模型更受欢迎;
小样本学习是破局点
数据墙下,能让 AI 看 10 个例子就学会新任务的产品,会碾压需要百万数据训练的竞品。我们正在做 “行业知识库快速适配” 功能,客户只需上传 100 份文档,AI 就能学会专业推理。
拒绝 “伪创新”,回归用户价值
过去我们总在做 “AI 写诗”“AI 画画” 的炫技功能,但用户真正需要的是 “AI 帮我省时间、少出错”。
七、个人展望
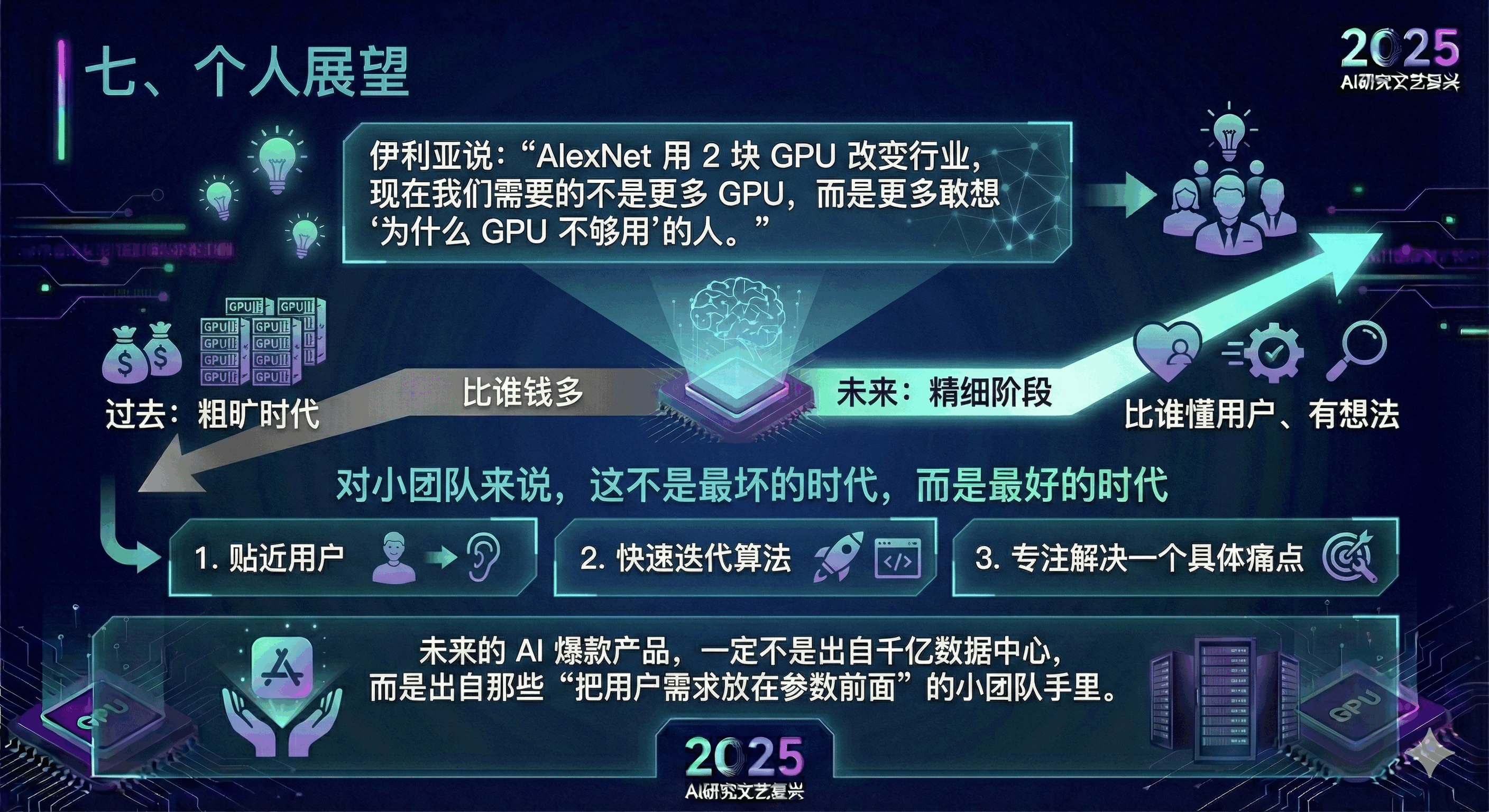
伊利亚说:“AlexNet 用 2 块 GPU 改变行业,现在我们需要的不是更多 GPU,而是更多敢想‘为什么 GPU 不够用’的人。” 这句话点醒了我:AI 行业终于告别了 “比谁钱多” 的粗旷时代,回到了 “比谁懂用户、有想法” 的精细阶段。
对小团队来说,这不是最坏的时代,而是最好的时代 —— 我们没有千亿预算,但我们能贴近用户,能快速迭代算法,能专注解决一个具体痛点。
未来的 AI 爆款产品,一定不是出自千亿数据中心,而是出自那些 “把用户需求放在参数前面” 的小团队手里。
本文由 @王俊 Teddy 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


