
 起点课堂会员权益
起点课堂会员权益企业级知识图谱的实体架构治理实践
知识图谱的真正难点不在于技术实现,而在于企业知识的治理与落地。电信行业的多源异构数据、频繁变更的业务规则、复杂的同义词体系,让知识图谱面临节点爆炸、规则冲突、版本混乱等多重挑战。本文深度解析企业知识图谱治理的五大核心关卡——从切片准则、打标体系到别名确认、冲突处理和重复校验,揭示如何打造既灵活又可控的知识管理基础设施。

很多人以为知识图谱的核心,是让 AI 多识别几个实体、多连几条边。但真正做进电信业务之后会发现,这根本不是瓶颈。
图谱真正难的,是抽出来的东西能不能被治理。
今天叫正式名,明天叫营销名,客服口语里又叫另一个名字;同一个活动,不同系统里上了两版文档;同一条办理规则,新政策和旧政策还可能打架。
这篇只说一件事:知识进入图谱之前,企业系统一定要经历以下几关
企业知识图谱治理五大关卡全景流程图:
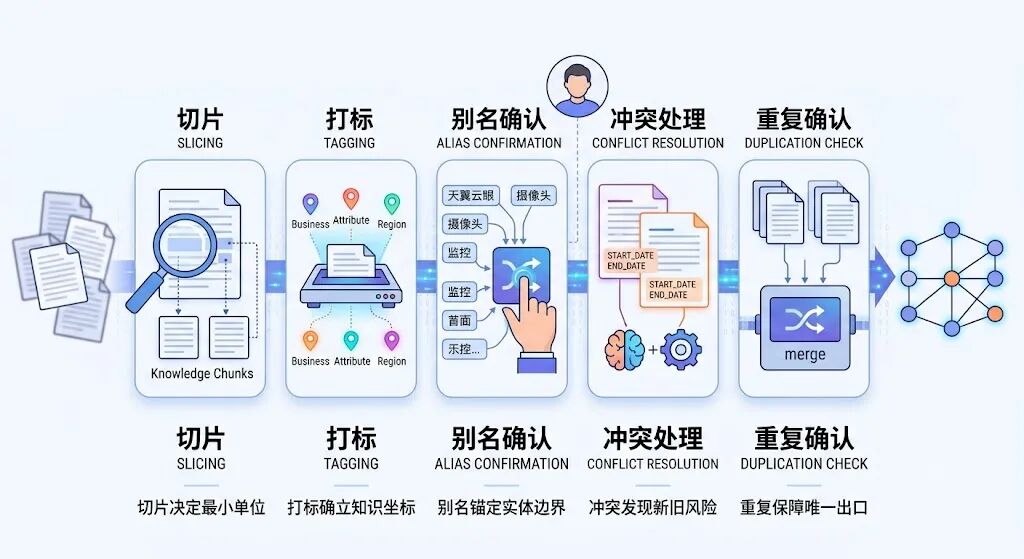
一、切片不是切文档,是守住入关口
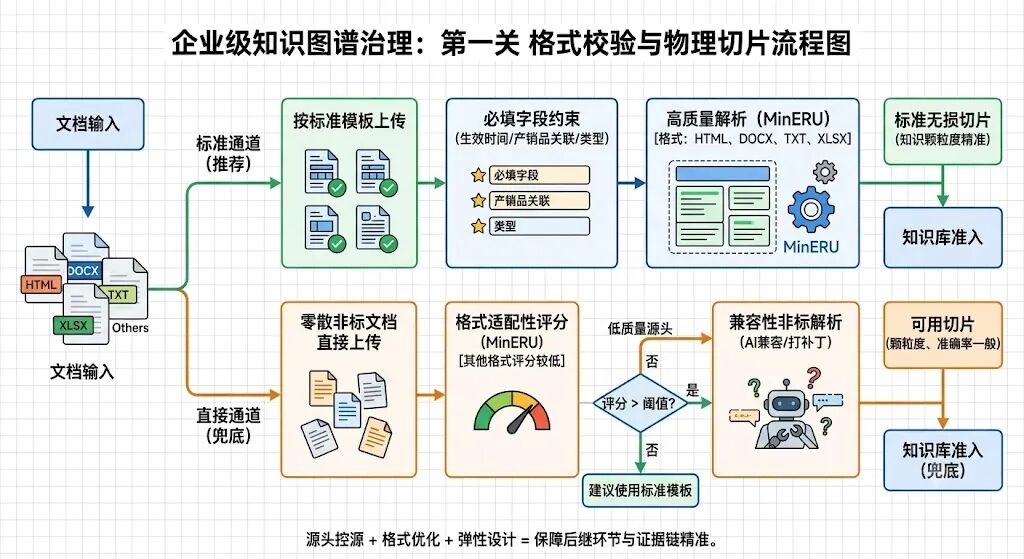
文档进来,第一件事不是马上让 AI 抽实体,而是先启动我们的“格式校验与物理切片”机制。
这一步听起来很技术,但它作为知识的入关口,直接决定后面所有环节的质量上限。
切得太大:
整篇营销政策变成一个知识块,AI 抽取时定位不到具体规则,问答证据链也只能粗糙地写“见某某文档”。切得太碎:上下文断裂,AI 失去语义理解,抽出来的实体关系就会变成一盘散沙。
为了破解“到底怎么切”这个问题,我们没有搞一刀切,而是在底层做了一套更细的治理逻辑:
标准模板指引 + 格式适配性评分
格式适配:先知道什么文档好切
在开发前期,我们对企业常见文档格式做了多轮适用性分析,用“文档打标与切片效果”作为硬性评分标准。
评测下来,目前依托mineru 引擎,系统对HTML、DOCX、TXT、XLSX这四种格式的切片和语义解析效果最好,其他格式表现相对一般。
标准模板:从源头把关键字段要回来
基于这个评估,我们制定了每类文档的标准模板,并给出推荐上传格式。
模板里强制规范了一些核心必填字段:
- 文档生效时间
- 是否关联产销品
- 产销品类型
双通道:既要严谨,也要给一线留活口
标准通道:按标准模板上传。切片更稳定,打标和关联产销品准确率更高。
直接通道:允许上传零散文档。效果会打折,但 AI 会尽量兼容和补丁处理,保证业务不因为“格式不完美”就卡死。
切片和准入不是单纯的技术动作。它是在回答一个关键业务问题:企业知识的最小可复用单元是什么?
二、打标不是分类,是给知识定坐标
切完之后,系统不要求人工盲目穷举细粒度实体,而是基于“Schema-First(架构先行)”理念,在系统后台维护一套高弹性的标签框架:每一个知识块都要被打上标签。
我们系统里有三类标签:业务标签、属性标签、区域标签。
- 业务标签:这段知识属于哪条业务线。(宽带、移动、终端、加装包……)
- 属性标签:这段知识是什么类型的内容。(产品信息、办理规则、适用人员……)
- 区域标签:这段知识在哪些地域生效。(全国、省、市、区……)
这里最容易误解的是:标签不是实体,标签是坐标。
给一段内容打上“宽带”“办理规则”“某省某市”,不是要把这几个词都变成图谱核心节点,而是告诉系统:这段内容属于什么业务范围,应该走哪条抽取逻辑,后续关联哪些产销品,在哪些地域生效。
系统支持在运营过程中随时一键增删标签,并支持产品经理针对特定的新标签直接编写和在线微调 Prompt,驱动大模型进行特定维度的自适应提取。
实体定义的标准:实体节点完全由“业务标签”与“属性标签”进行切分定义,且实体数量与边界由“别名机制”死死锁住。
当然,打标还有一个更深的作用:它是后续冲突识别的前提。
三、别名确认要防止节点爆炸
打完标之后,AI 开始从切片内容里抽取实体。
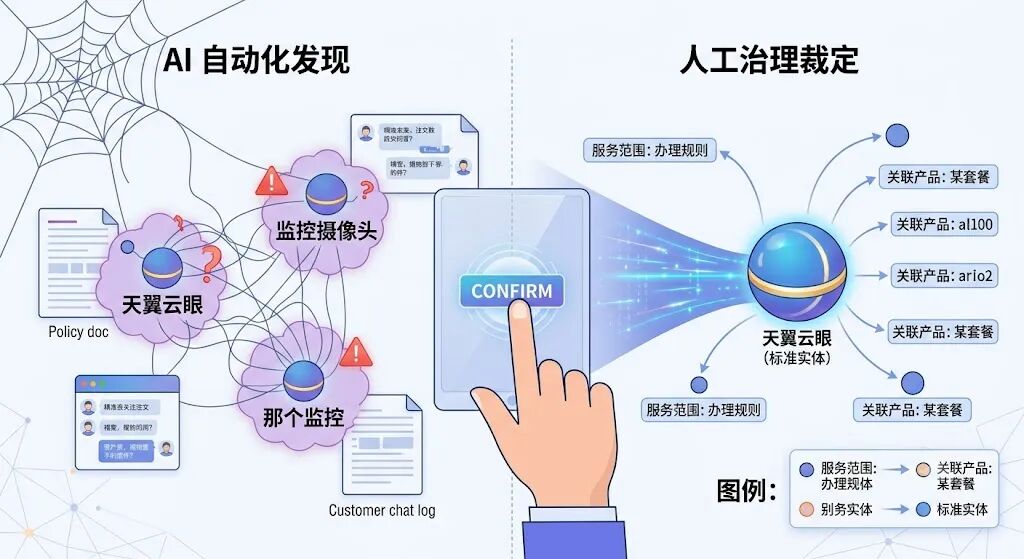
这时会出现一个电信业务里非常普遍的问题:同一个东西,有多个叫法。
一篇文档里写“天翼云眼”,另一篇文档里写“摄像头”,客服问答里用户可能说“那个监控”。
如果系统不处理,图谱里就会出现三个节点,全都指向同一个产品。后续挂在这三个节点上的规则、活动、关系,也会跟着分裂成三份。
因此,我们的系统通过“置信度打分引擎”进行分流,对置信度高、中低评分的同义词分区,依靠运营人员对中低置信度的数据在后台进行手工确认,确保图谱数据的 100% 干净和高确定性:
AI 自动合并口语化噪音(如自动提示[天翼云眼]与[摄像头]为同义别名)。运营人员点击确认后,多少个别名统一收敛到对应的标准实体节点上,完美终结节点爆炸。
四、冲突确认处理的是版本风险
电信业务的政策迭代很快。
新活动上线,老活动还没完全下线;同一个产品在不同地市有本地化规则;同一个套餐,前后两版文档里的适用条件可能不一样。
普通 RAG 对这些冲突并不敏感。因为 RAG 的工作方式是临时检索:用户问什么,它就找相关片段。至于两篇文档之间有没有打架,它不会主动判断。
当一篇新文档进来,系统不只是抽里面写了什么,还要判断它会不会影响图谱里已有的知识。
冲突不能让 AI 拍板,因为很多冲突不是简单的“谁对谁错”。新政策是完全覆盖旧政策,还是只对某个地市补充?两条规则是真冲突,还是只是表述不同?这些都需要运营人员确认。
所以我们在边和节点上引入了 时间戳节点,当新老政策、多源文档之间发生规则和办理限制冲突时,系统不再做简单的前后覆盖,让运营人员一键确认“新老交替的时间断点”,实现知识的时间轴版本化。——不删除旧版本,以便后期追溯历史文档,而是通过版本的更迭更新图谱。
当然,系统AI识别的内容也不一定就是完美的,必须要有可手工修改的余量。
五、重复确认不是去重,是保留唯一口径
最后一关,处理的是多源文档带来的知识冗余,我们的做法和上面的冲突场景类似。
同一份营销政策,可能在不同系统里上传过多次。同一个客服口径,可能同时出现在培训材料、FAQ、政策说明里。
这不是异常,这是企业知识管理的常态。
如果这些内容都无脑进图谱,问答时系统会同时命中多个版本。证据链看起来很全,实际是在堆砌重复内容。
系统要从两个维度查重:语义查重和图拓扑查重。针对多渠道进来的内容重复文档进行自动聚类合并,保障图谱链路的唯一性。
重复确认的价值,不是让图谱变小,而是让图谱里的每条知识只有一个标准出口。
这五关,组成了图谱的骨架
- 切片:决定知识颗粒度
- 打标:给知识定坐标
- 别名确认:锁定实体边界
- 冲突确认:处理版本风险
- 重复确认:保障唯一性
任何一道缺失,图谱都会以不同方式失控:节点爆炸、规则串联、版本混乱、证据链发散。
更麻烦的是,这些问题在日常问答里不会明显报错。它们只会让 AI 的回答看起来差不多但不完整,或者偶尔答对,却说不清为什么对。
AI 负责发现候选,人工负责裁定边界。AI 冲锋,人工当裁判,这就涉及到了另一个问题——企业的架构需要新增该岗位的运营人员,图谱不是做完就好了,需要不断维护,这也是我们下一步想要完善的点,是否能通过Agent完成这一系列操作。
本文由 @是AD 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自 unsplash,基于CC0协议





- 目前还没评论,等你发挥!


