
 起点课堂会员权益
起点课堂会员权益评分算法(3):服务分策略设计的3个方法
按照服务分的更新机制,服务分可以分为两类:一类是每次服务后更新,一类是定期更新。在介绍了服务分的设计场景和思路之后,本文作者对服务分策略设计的具体方法展开了分析和总结,包括:归一化、权重设计和归因。

一、服务分分类
1. 服务后更新
服务后更新顾名思义,比如每次打车后根据用户的评价进行服务分的调整,滴滴就是这么做的。记不清哪里看的了(反正肯定不是两年前看的内部文档),滴滴的服务分主要部分会根据好评、差评和默认好评去打分,每次用户打分会对应分值的变化。
这样的好处是可以及时更新,服务者会有及时反馈。
当然,局限性也很明显。乘客的好评不能完全评价司机的服务能力,比如司机接单少业绩差、高峰期不愿意出门等。而如果平台派单问题导致乘客体验下降,差评由司机承担也不公平。与此同时,全靠好评会造成司机索要好评的问题,对服务质量也有影响。
2. 定期更新
定期更新是本文的重点,也是上一篇文章重点讨论的内容。因为用了更复杂的计算机制,可以涵盖更多的数据,比如上一篇文章提到的,服务分的三部分构成:员工属性、SOP执行情况、业绩结果。这里面涉及了多种策略设计的方法。
二、归一化
员工属性和SOP执行情况的数据各种各样,比如有没有某个资格证是0和1;某个资格证分等级,则可能是(1,2,3);电话的通话时长是一个大于等于零的小数;服务次数是一个非负整数。
为了将这些不同类型的数据融合,需要进行归一化,这些方法我在《产品逻辑之美》中也写过。
线性函数是一种简单的归一化方式,就是直接除以数据中的最大值,让所有值都在0~1之间,并保留原有的变化性质。用公式表示为:
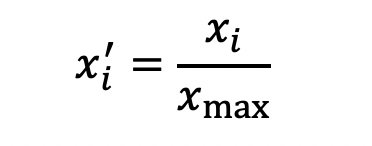
这样的处理方法受极值的影响比较大。而且如果大部分分值比极值低很多,则低分值将没有区分度,以阅读量为例,如果最大阅读量的文章的阅读量为10万,而大部分文章阅读量集中在500左右。这样直接除以极大值处理后,大部分内容分值都趋近于0,缺乏区分度。
这个时候就需要在使用线性函数处理前,对数值进行对数处理,用公式表示为:
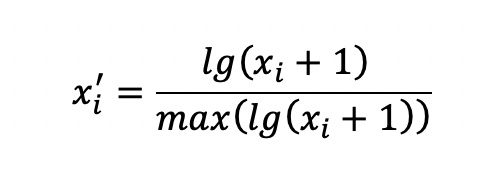
对数处理后的数据结果表示原始数据数量级的大小,在互联网数据中,长尾分布的案例比较多,使用对数函数转换是一种非常有效的方法。除了对数函数,也可以根据数据的分布,使用其他函数来改变数据的分布性质,比如多项式函数,这里就不再赘述。
z分数(z-score)标准化也是常用的一种归一化方法。在一组数据中,x为某一具体分数,μ为平均数,σ为标准差,用公式表示为:
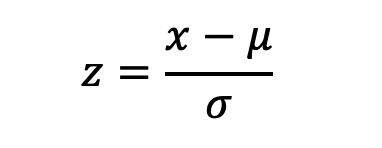
z代表着原始分数和母体平均值之间的距离,以标准差为单位计算。在原始分数低于平均值时,z则为负数,反之则为正数。当然,z分数标准化处理的隐含前提是数据符合正态分布,或者类似正态分布。如果数据分布和正态分布差距明显时,用z分数标准化则可能会有问题。
当然,z标准化后的数据也需要处理一下,这个就根据正态函数的性质处理了。
比如下面的公式就可以控制在0~1之间,而这个公式的数学含义就不展开讨论了,感兴趣可以自己推导一下。
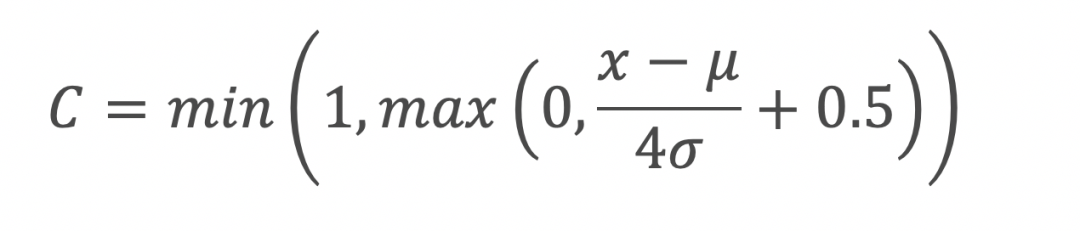
三、权重设计
当数据归一化之后就要进行加权求和,加权求和的公式是很常见的,如下所示:
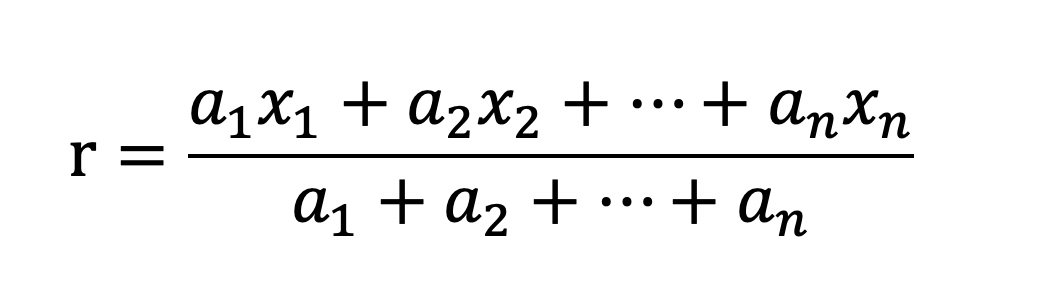
这里需要考虑到如何设计权重。主要有以下几种思路。
1. 信息权重
从信息的角度,如果一个信息出现的概率越小,则信息量越大,一个信息越常见,则信息量越小。那么比如某个证书是否取得这个数据。取得证书的人越多,取得后的权重应该越少。这里的权重需要设计出一个函数,函数值和比例负相关。比如最简单的线性函数如下:
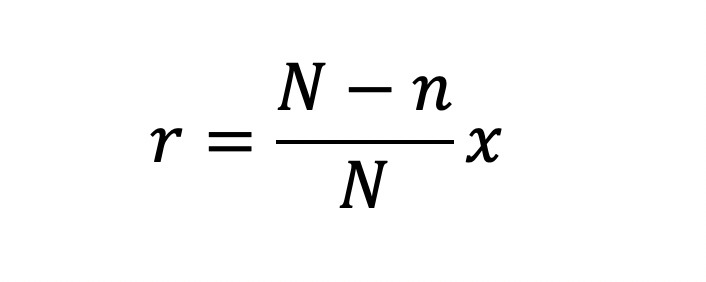
2. 置信度权重
置信度提权的原理是“数据量越大,信息越靠谱”,平均值、打分等方法都有比较好的效果,比如平均时长,平均评分。如下所示,N代表数据的数量,score代表原始打分。
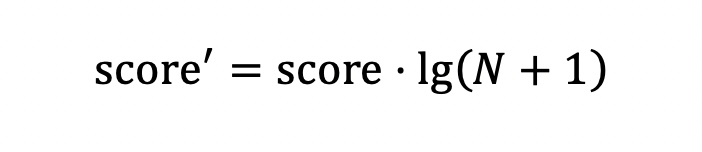
3. 时间衰减
时间衰减降权,顾名思义,让过去的信息权重更低,最近的信息权重更高。因为行为具有连续性,所以最新的行为包含了更大的信息量。下面的公式是最常见的时间衰减公式,也是物体降温和自然衰变的公式,其中t是数据发生时间到现在的时间差。
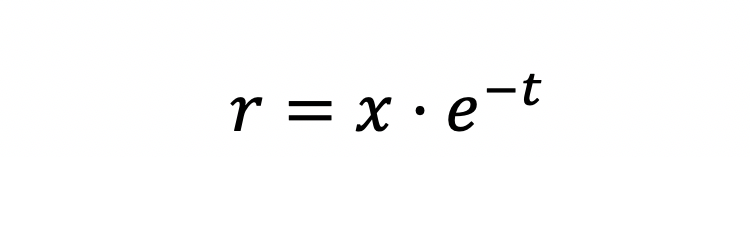
4. 业务权重
当然,不同因素之间彼此哪个更重要,的确是一个业务问题,需要和业务方共同商定。业务方不一定需要给出具体的权重,可以给出优先级,根据优先级确定具体的数学规则。这里的方法不展开讲了,核心是达成共识。
四、归因
归因本质上是确定清楚具体的服务人员的贡献。因为一个服务的结果(比如是否下单)背后是多因素的,服务人员只是多个环节中的一环。
归因是策略分析中最复杂的问题,但是也有很多系统性的归因方法。数学功底比较好的同学我推荐系统看下《基本有用的计量学》。那这里长话短说,我去掉复杂的数学语言,艰难表述下也是两种书中提到的方法。
第一种就是回归算法,多个因素的话,可以使用多元线性回归和逻辑回归,如果需要考虑时序上的区别,时间序列的算法也可以考虑。每种算法都有对应的数学假设,在使用前要确保业务场景符合数学假设。
第二种就是找到一个指标找到一个参考标准,具体服务者的数据和参考基线的数据差是对应的贡献值。比如配送员的配送准时率,参考标准可以是同配送站准时率的均值。每个配送员计算后,再用这个差值作为配送时效分值计算的基础数据,进行归一化和后续的加权求和。
还有一些更复杂的衡量因果效应的方法,还是建议去阅读专业书籍。本文已经有太多公式了,再加真要没阅读量了。
小结
关于服务分一共写了三期文章,这是B端策略的一个重要课题,但是在整个产品经理的业务范围内,还是一个非常窄的选题。大部分同学可能对这个选题不感兴趣,但希望这些内容可以帮助到工作中涉及到服务分和服务者绩效衡量的同学。
#相关阅读#
#专栏作家#
潘一鸣,公众号:产品逻辑之美,人人都是产品经理专栏作家。毕业于清华大学,畅销书《产品逻辑之美》作者;先后在多家互联网公司从事产品经理工作,有很多复杂系统的构建实践经验。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议










这个就比上一篇好多了。略牛逼