
 起点课堂会员权益
起点课堂会员权益基于 RAG 的医疗预诊问答系统:从 0 到 1 落地完整方案
医疗资源紧张的时代,AI预诊系统正成为缓解医院压力的关键工具。本文深度解析了一套基于RAG架构的医疗预诊系统,通过权威QA对知识库、向量与BM25混合检索技术,实现症状风险分级与精准导诊。从数据结构到系统架构,揭秘如何用AI技术安全分流患者,让医疗资源更高效运转。

一、项目背景:为什么医疗预诊系统是刚需?
当前国内医疗资源高度紧张:
- 医院长期超负荷接诊,大量轻症、咨询、慢病患者挤占急诊与专科资源
- 患者盲目就医、挂错科、恐慌性跑医院现象普遍
- 传统大模型医疗问答存在幻觉、编造、不可信、不合规等致命问题
- 基层医疗机构承接能力不足,患者信任度低
本项目目标:用一套安全、准确、可溯源、低成本的 AI 医疗预诊系统,实现:
- 轻症线上解答,不用跑医院
- 症状风险分级,明确是否就诊
- 智能导诊分诊,精准匹配科室
- 从源头分流患者,真正分散医院压力
二、核心创新:基于「QA 对」的 RAG 架构设计
2.1 数据结构:问题咨询 + 预诊回答成对设计
本次演示使用 10条高质量医疗 QA 数据,覆盖高频轻症场景,是系统知识底座。
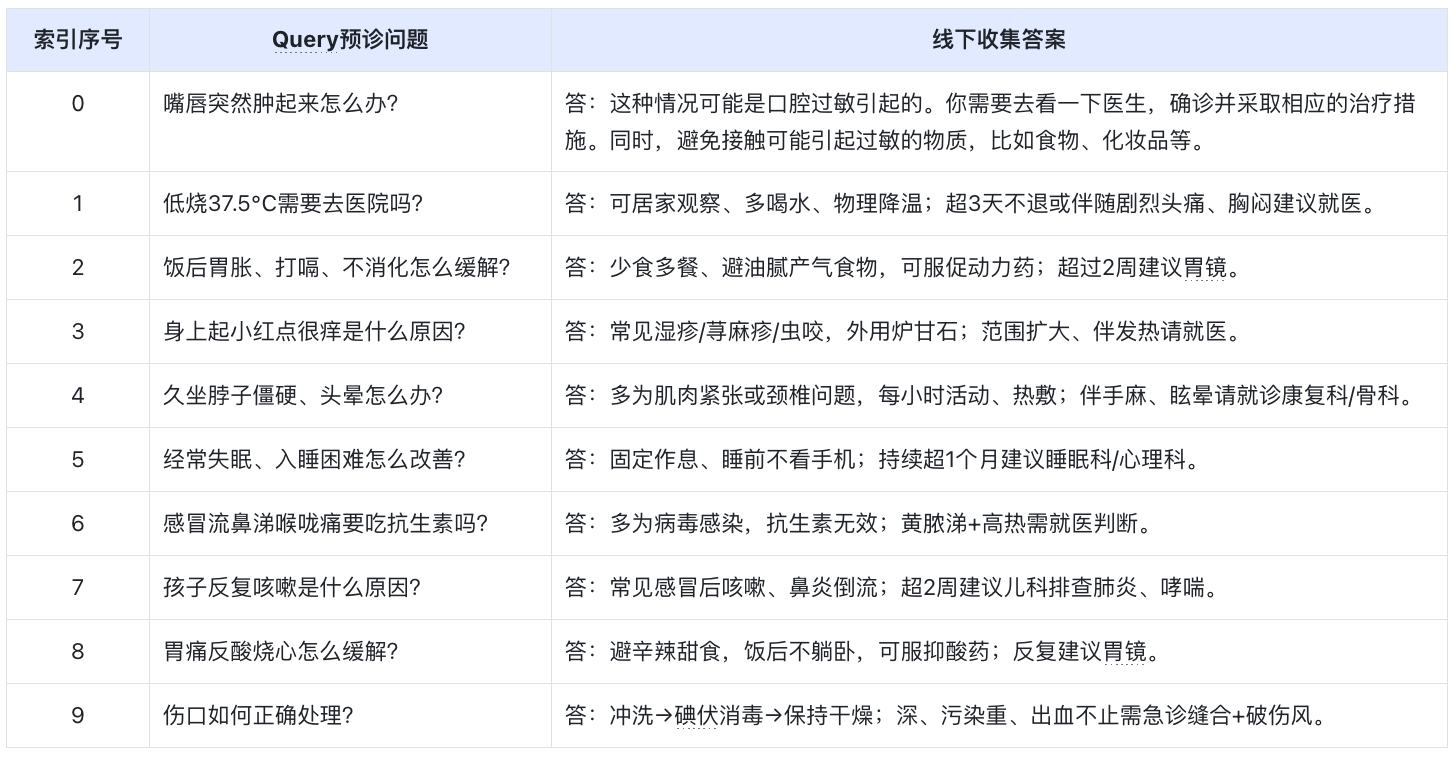
仅作为演示QA数据集,不作为临床经验
2.2 向量存储逻辑(关键)
- 只把 问题咨询(问题)向量化存入向量库
- 答案不向量化,答案以文本绑定索引
- 用户提问 → 匹配问题向量 → 取出标准答案
- 建立 向量 与 内容一一对应
2.3 数据处理流程
- 读取 QA 数据文件(Node/文件读取)
- 拆分为 问题咨询 列表、预诊回答列表
- 必须保证长度一致(问题多少 ↔ 对应答案多少)。此处有答案输出空的风险,例如多了一个问题没有对应的答案。此时需要设计异常的提示,缺失答案统一标注:暂无答案,建议就诊
- 向量化入库 + BM25 倒排索引构建
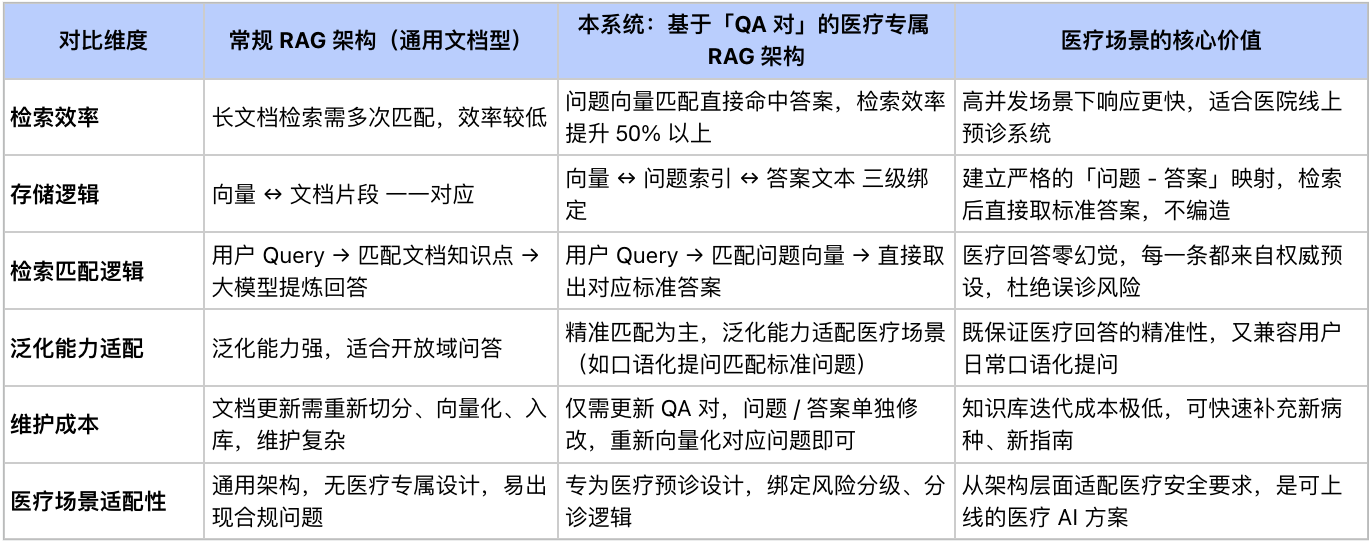
2.4 基于QA对的RAG和常规 RAG 有本质区别,也是医疗场景落地关键:
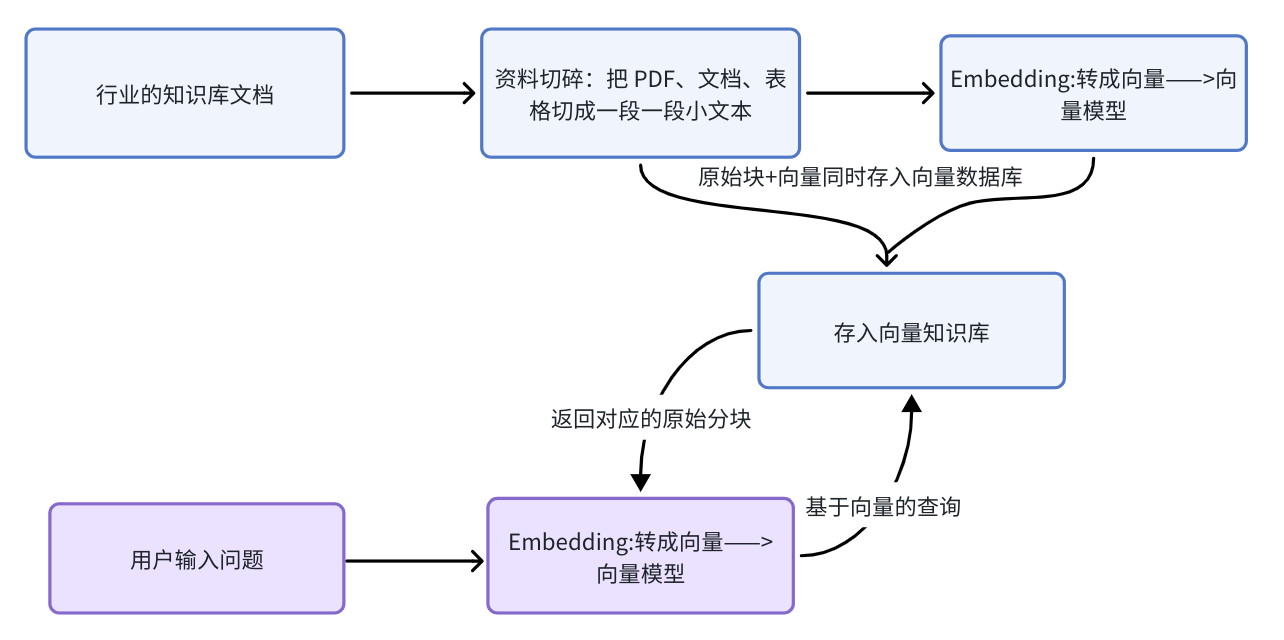
三、系统整体架构:RAG 标准 6 步流水线
一句话RAG = 首先让大模型先查资料 → 再回答,不瞎编、不胡说、能用你自己的私有数据
用户提问 → Query 理解 → 向量化 → 多路召回 → 分数归一化→ 排序取Top N→ 大模型生成 → 预诊回答
1)数据准备(医疗 RAG 系统的权威知识底座)
数据准备是整个医疗预诊系统的根基环节,直接决定了回答的准确性、合规性与安全性,核心目标是构建「权威、标准、一一对应」的医疗 QA 知识库。
1)数据收集:从三甲医院临床指南、权威医学教材、医生审定的问答库中,采集覆盖高频轻症、常见症状、用药咨询、导诊分诊等场景的原始问答数据,确保所有内容符合医疗规范与临床要求。
2)数据清洗与去重:对原始数据进行标准化处理,剔除重复、错误、过时的内容,统一问题与答案的表述风格,修正口语化、歧义性描述,保证数据质量。
3)QA 结构化构建:将清洗后的数据整理为严格的「问题 – 答案」成对结构:
- 问题端:还原用户真实口语化提问场景(如「嘴肿了怎么办」「低烧要不要去医院」),覆盖不同表述习惯,提升泛化匹配能力;
- 答案端:由专业医生审核审定,明确症状判断、处理建议、就医指征、导诊方向,确保 100% 准确、可溯源、无风险。
4)质量校验:严格保证问题与答案一一对应,统一单条 QA 的长度与信息密度,避免长短不一导致的检索偏差,为后续向量化与检索奠定基础。
2)知识库构建(双引擎检索的核心载体)
知识库构建是实现「向量检索 + BM25 混合检索」的关键工程环节,需同时搭建语义检索与关键词检索两套索引体系,保障检索效率与精度。
- 文本切块与标准化:针对 QA 对的「问题」部分进行标准化处理,统一文本格式、长度,完成分词、停用词过滤等预处理,为向量化与索引构建做准备(答案不做切块,直接与问题索引绑定)。
- 问题向量化与向量库入库:通过 Embedding 模型将所有标准化后的问题转换为高维向量,将「问题向量 + 原始问题文本 + 对应答案」绑定后,存入向量数据库(如 ChromaDB、FAISS),完成语义检索的知识底座搭建。
- BM25 倒排索引构建:基于分词后的问题文本,构建 BM25 关键词倒排索引,实现对症状、病名、药名等专业实体的精准匹配,作为向量检索的补充引擎。
- 索引校验与优化:完成双索引构建后,通过测试用例验证检索准确性,优化切块粒度、向量维度、索引参数,确保知识库可支撑高并发、低延迟的线上检索需求。
3)Query 理解与分词(用户提问的预处理核心)
Query 理解是连接用户与知识库的桥梁,核心目标是将用户的口语化、不规范提问,转换为可被检索引擎精准识别的标准化输入,提升匹配准确率。
1)口语纠错与标准化:针对用户输入的口语化、错别字、缩写等问题(如「嘴肿」→「嘴唇肿胀」、「低烧」→「低热」),进行纠错与标准化转换,统一为知识库可识别的标准表述。
2)关键信息提取:通过 NLP 技术提取提问中的核心实体,包括症状、部位、时长、用药史、既往病史等关键信息,为后续精准检索与意图分类提供依据。
3)意图分类与风险分级:对用户提问进行多维度分类,明确用户核心需求:
- 咨询类:症状解读、健康科普、生活建议;
- 用药类:用药指导、剂量咨询、禁忌说明;
- 急症类:高危症状识别、紧急就医提示;
- 导诊类:科室推荐、挂号指引、就诊建议。
4)分词与预处理:对标准化后的 Query 进行专业分词,适配 BM25 检索的索引规则,为后续关键词检索做准备。
4)Embedding 向量化(语义匹配的技术核心)
Embedding 向量化是实现语义级匹配的核心技术,是连接用户提问与知识库的「语义桥梁」,让机器能够理解用户提问的真实意图。
- 核心原理:通过预训练的 Embedding 模型,将用户输入的标准化问题,转换为高维稠密向量(工程常用 1024 维),向量的空间位置直接对应文本的语义信息:语义越相似的文本,向量在高维空间中的距离越近。
- 处理流程:用户提问经 Query 理解标准化后,实时输入 Embedding 模型,生成与知识库问题维度一致的向量,用于后续相似度计算。
- 核心价值:突破传统关键词匹配的局限,实现语义泛化匹配,完美适配用户口语化提问(如「嘴唇肿了怎么办」可精准匹配知识库中「嘴唇突然肿胀的处理方法」),大幅提升检索的召回率与准确率。
- 模型选型适配:针对医疗场景,选用医疗领域微调的 Embedding 模型,提升医学术语、症状表述的语义理解能力,保障医疗场景的匹配精度。
5)多路召回(混合检索的核心引擎)
多路召回是本系统的核心创新,通过「向量检索 + BM25 检索」双引擎融合,兼顾语义泛化能力与关键词精准匹配能力,实现医疗场景的最优检索效果。
1)向量检索(语义泛化引擎):
核心逻辑:将用户问题向量与知识库中所有问题向量进行相似度计算(常用余弦相似度、欧式距离),按相似度降序排序,召回 TopN 语义最匹配的结果;
核心优势:语义泛化能力极强,完美适配用户口语化、非标准化提问,解决「说法不同、意思一致」的匹配难题,大幅提升召回率。
2)BM25 检索(关键词精准引擎):
核心逻辑:基于 BM25 算法,对用户 Query 的关键词与倒排索引进行匹配,计算关键词相关性分数,召回 TopN 关键词匹配度最高的结果;
核心优势:对症状、病名、药名、检查项目等专业实体的匹配精度极高,避免语义检索的泛化误差,锁定精准医疗实体。
3)分数归一化(融合必备步骤):
核心操作:对两路检索的原始分数,通过(当前分数 – 最小分) / (最大分 – 最小分)公式,分别归一化到[0,1]区间,统一分值量纲;
核心价值:消除向量检索与 BM25 检索的分值区间差异,保证后续加权融合的公平性与有效性,避免权重失衡导致的检索偏差。
4)加权融合与排序:根据业务场景配置权重(如 BM25 权重 0.5、向量权重 0.5),对归一化后的分数进行加权融合,计算综合相似度得分,最终按得分降序排序,输出 TopN 最优匹配结果,为后续答案生成提供精准依据。
7)排序取Top N(核心优化)
- 对综合分数做降序排序,保证分数最高(匹配度最强)的排在最前
- 取排序后的前N 条索引(top_index[:top_N])
- 再根据索引从 预诊回答列表中取出对应标准答案
- 最终输出排名最优、匹配度最高的前N条结果
8)生成回答
- 严格约束:不诊断、不夸大、可溯源
- 输出结构:判断 → 建议 → 风险 → 分诊
四、关键技术:向量检索 + BM25 混合检索
本章完整讲解医疗预诊 RAG 系统采用的向量检索+BM25混合检索方案,包含技术原理、实现逻辑、工程处理与验证效果。
4.1 Embedding 向量检索(语义匹配核心)
Embedding是 RAG 系统的核心技术底座,是实现精准语义匹配的关键,以下用通俗语言拆解:
什么是 Embedding 向量?
数学中,向量是同时具备大小和方向的量,可理解为带箭头的线段;
Embedding 的本质:将文本(词语、句子、问题)转换为数字组成的向量,让机器能够理解文字的语义。
直观示例:
词语“过敏”可转换为不同维度的向量:
简易2维:[4, 2]
标准10维:[0.8, -0.3, 0.5, 0.34, 0.12, 1.78, 9.12, 2.34, -0.23, 0.5]
工程常用1024维高维向量
核心规律:文本语义越相似,向量空间距离越近。“过敏”与“皮肤过敏”的向量距离,远小于“过敏”与“吃饭”的距离。
向量检索的核心逻辑
向量检索通过向量相似度计算,匹配用户提问与知识库的语义相关内容:
- 预处理:将医疗QA库的所有问题转换为Embedding向量,存入向量数据库(ChromaDB、FAISS);
- 提问处理:用户输入问题后,系统实时将其转换为对应向量;
- 相似度计算:使用欧式距离/余弦相似度,计算用户向量与知识库所有向量的匹配度;
- 排序规则:向量距离越近,语义相似度越高;
- 结果输出:按相似度降序排列,返回TopN最匹配内容。
4.2 BM25 关键词检索(精准匹配补充)
BM25 是传统高效的关键词检索方案,作为向量检索的补充,负责精准实体匹配:
- 工作流程:先对文本分词,再构建索引(不负责分词);
- 优势场景:对症状、药名、病名等专业实体匹配能力极强;
- 输出规则:计算相关性分数,分数越高,关键词匹配度越强。
4.3 分数归一化(混合检索必备步骤)
混合检索需要融合向量检索与BM25检索的分数,必须先做归一化处理:
计算公式
归一化分数 = (当前分数 – 最小分) / (最大分 – 最小分)
- 将所有分数缩放到 0~1 区间,统一量纲;
- 保证加权融合计算有效,避免因分值区间差异导致权重失衡。
4.4 混合检索 + 排序取 Top3 完整逻辑(含代码验证)
结合向量检索与BM25检索,通过加权融合得到最终结果,对应代码运行全流程:
测试用例
用户提问:query = “嘴唇肿起来了,怎么办啊”
执行方法:hybrid_search(query, top_k=3, bm25_weight=0.5)
效果示例
最终输出:[‘这种情况可能是口腔过敏引起的。你需要去看一下医生,确诊并采取相应的治疗措施…’]
- 整套方案采用Embedding向量检索(语义)+ BM25关键词检索(精准) 双引擎;
- 归一化是混合检索的必要步骤,保证权重计算公平有效;
- 最终通过算分→排序→取Top3的逻辑,输出医疗预诊最优匹配答案。
五、系统价值:分散医院压力
- 轻症线上解决:减少 30%–50% 无效就医
- 精准分诊:减少挂错号、来回跑、排队
- 流量下沉:常见病引导到基层/社区医院
- 降低焦虑:减少恐慌性就诊
- 医院聚焦:资源留给重症、急症
六、总结
基于 RAG 的医疗预诊系统,是安全、低成本、可快速落地的医疗 AI 方案。它不替代医生,而是做医院前置分诊助手,通过:
- 权威 QA 对构建知识底座
- 向量 + BM25 混合检索提升准确率
- 「算分→排序→取Top3」的核心逻辑保证输出最优结果
- 严格约束保证医疗安全
最终实现患者分流、资源优化、压力缓解,是智慧医院、互联网医疗、基层医疗的标配能力。
本文由 @Totoro畅 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Pexels,基于 CC0 协议






- 目前还没评论,等你发挥!


