
 起点课堂会员权益
起点课堂会员权益一文看懂VLA:自动驾驶的下一个范式
VLA(视觉语言动作模型)正在颠覆自动驾驶的底层逻辑。这项源自机器人领域的技术,通过整合视觉感知、语言推理与动作控制,让车辆首次具备'理解世界'的能力。从谷歌DeepMind的RT-2到小鹏VLA 2.0的量产落地,本文将深度解析这一技术如何跨越行动鸿沟,以及它面临的泛化挑战与安全考验。

上一篇文章也提到,VLM的输出仅停留在语言层面,无法直接驱动车辆执行动作,存在行动鸿沟。为了弥补这个断层,VLA应运而生。
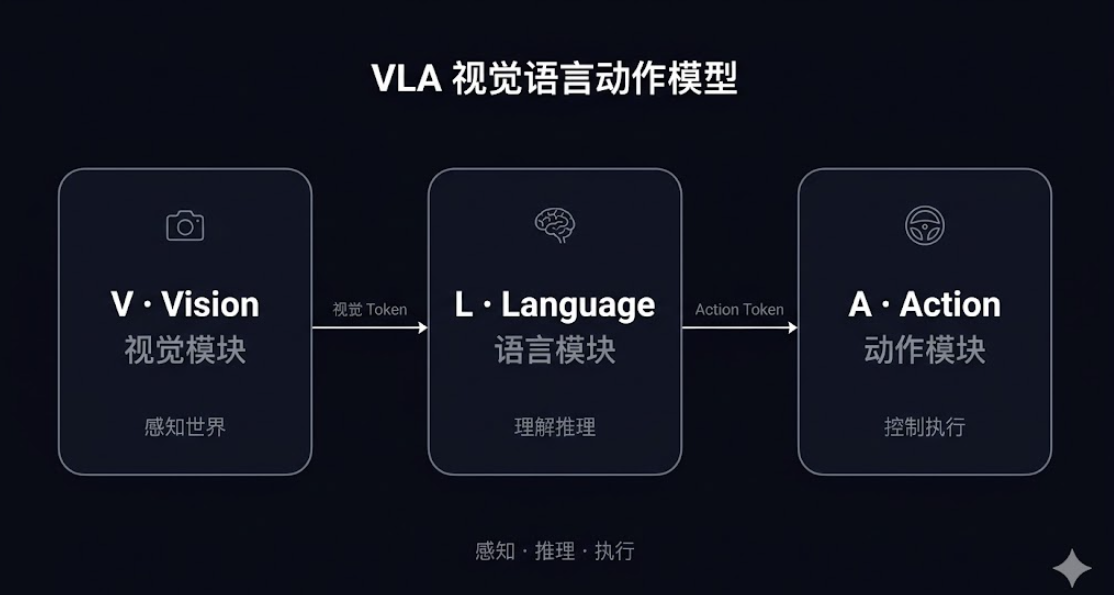
VLA(Vision-Language-Action Model,视觉语言动作模型),就是在VLM基础上引入动作输出能力的端到端模型。它将视觉感知、语言推理、动作控制三者统一在同一个模型框架内,实现从多模态输入到驾驶控制指令的完整闭环。
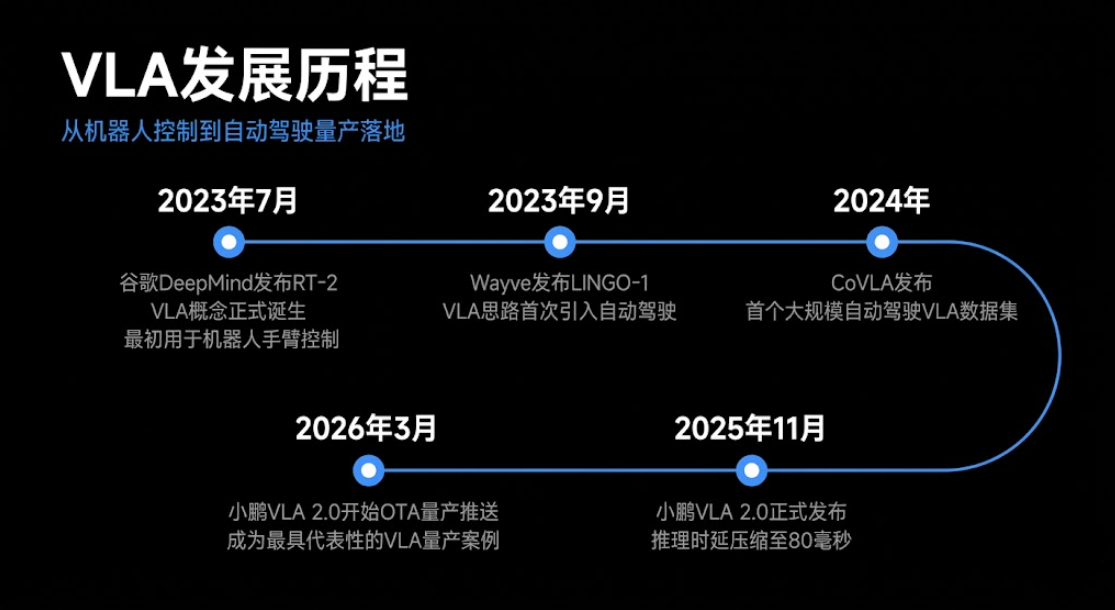
有意思的是,VLA这个概念最早出现在机器人控制领域。2023年7月,谷歌DeepMind发布RT-2,VLA概念正式诞生,最初用于机器人手臂的抓取控制。
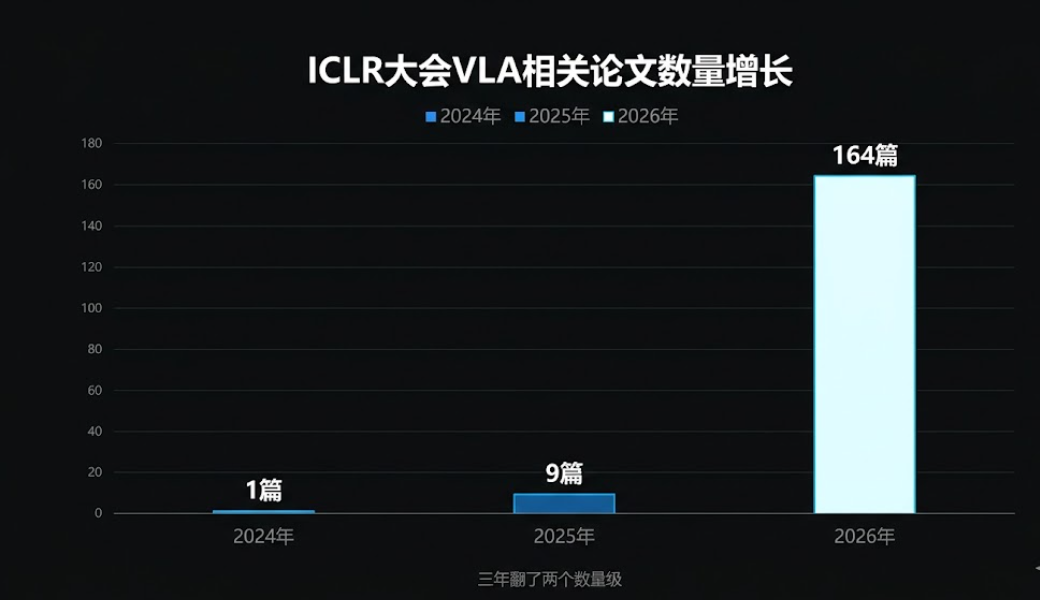
在具身智能领域,RT-2的发布迅速引发了学术界的关注。在AI领域最权威的三大会议之一ICLR中,2024年VLA相关论文仅有1篇,2025年增至9篇,到2026年直接飙升到164篇,三年翻了两个数量级,这说明全球学界已在集体押注这一方向。
学术验证之后,工业界随即跟进。2023年9月,Wayve发布LINGO-1,VLA思路第一次被引入自动驾驶。此后学术界和工业界同步提速——2024年,CoVLA构建了第一个大规模自动驾驶VLA数据集,推动了VLA在自动驾驶领域的系统化研究。2025年11月,小鹏VLA 2.0发布,并于2026年3月开始OTA量产推送,成为目前最具代表性的VLA自动驾驶量产案例。
VLA的三个模块:V、L、A分别是什么
V——Vision(视觉模块)
Vision模块是VLA的眼睛,负责感知车辆周围的物理世界,并将这些原始信息转化成模型能够理解的格式。
它的感知系统由摄像头和多种传感器共同构成。
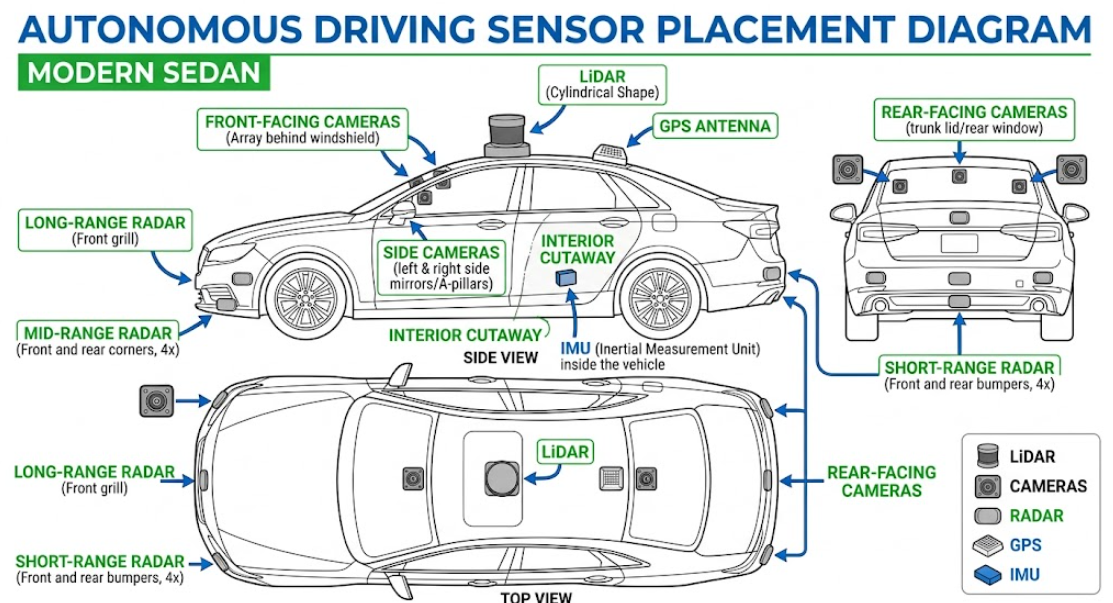
摄像头围绕车身一圈布置——前方1至3个,左右两侧各1至2个,后方1个,车顶有时还装有广角摄像头,确保360度无死角覆盖。
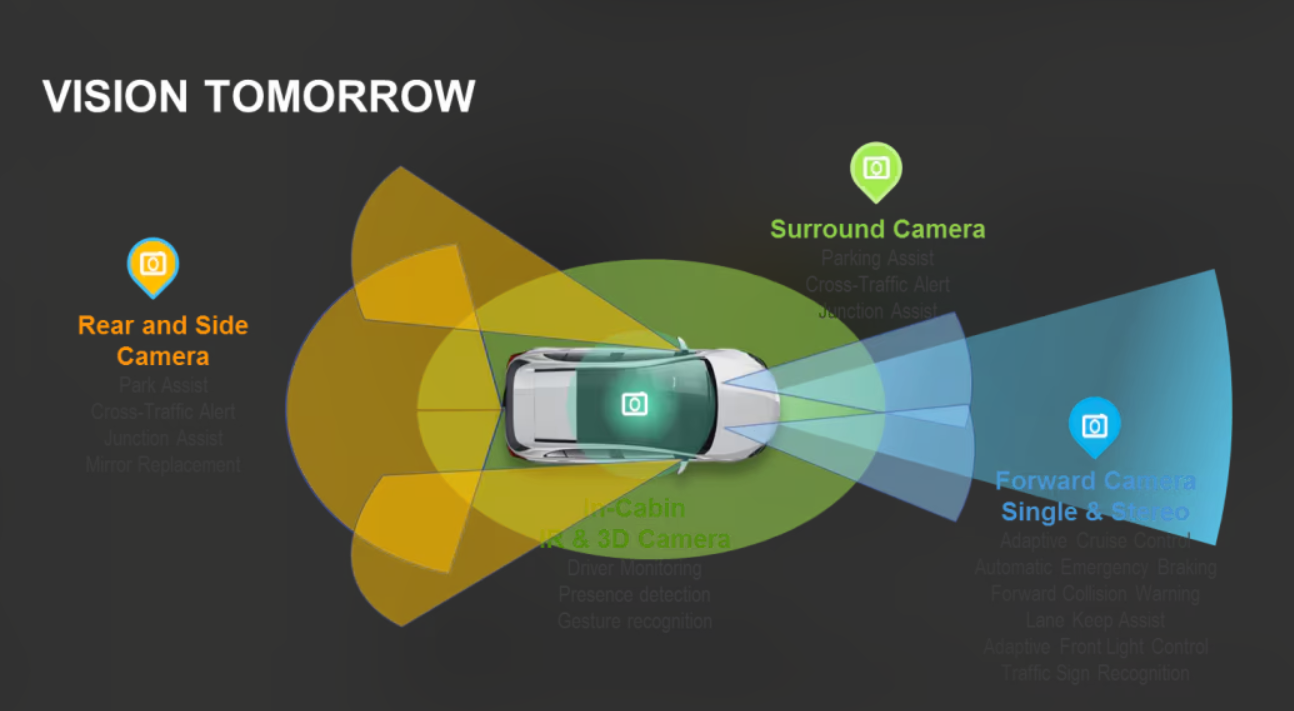
传感器方面,主要包括四种:
LiDAR(激光雷达)装在车顶正中央,像旋转的圆柱体,每秒向四周发射数百万条激光束,生成密密麻麻的彩色点云图,能精确呈现物体的三维形状、距离和地面起伏,探测范围360度,距离100至200米。

RADAR(毫米波雷达)藏在车头保险杠和车尾角落,通常4至6个,输出的是距离加速度的数据图,能测算前方最远200米、侧方60至80米内物体的距离和移动速度,雨雾天和黑夜依旧可用。
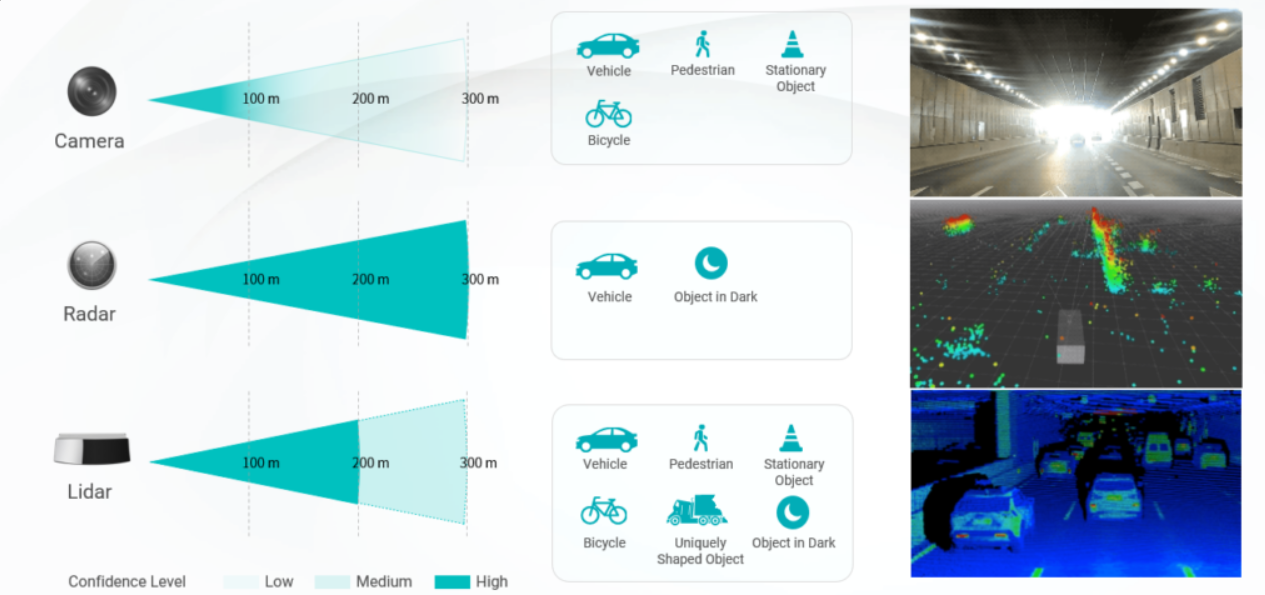
IMU(惯性测量单元)藏在车内,包含加速度计和陀螺仪——加速度计感知车辆加速、减速、刹车时的力度变化,陀螺仪感知车辆转弯的角度,两者合在一起让车知道自己在怎么运动。
GPS负责全球定位,告诉车辆自己在地球上的位置。
四种传感器互相补充——摄像头看不清的,LiDAR来补;LiDAR被雨雪干扰的,RADAR来补;GPS信号弱的,IMU来推算。即使在极端天气下,车辆也不会完全”失明”。
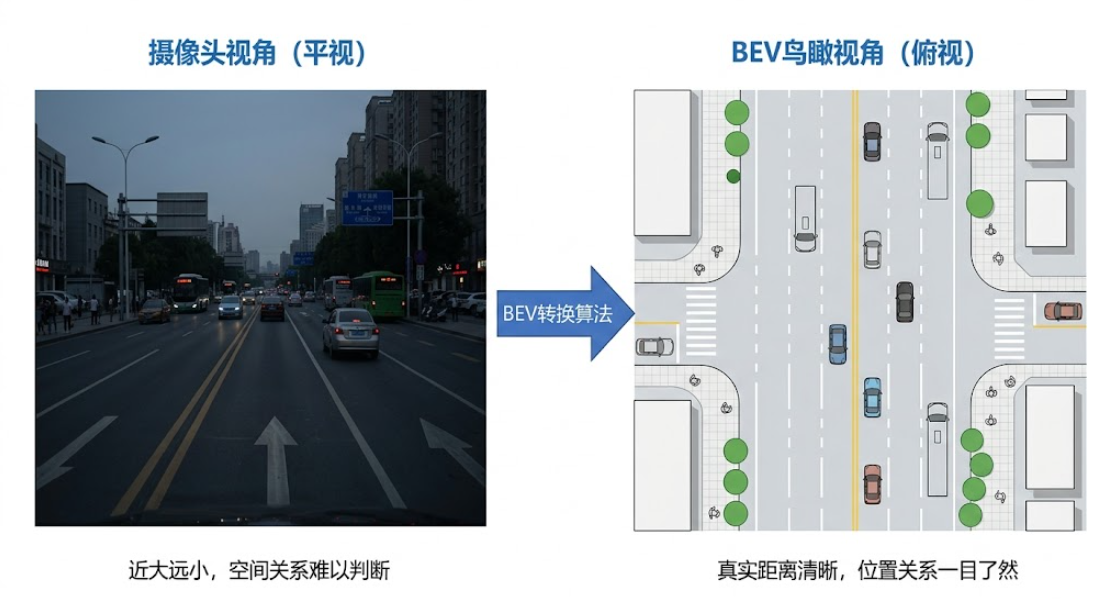
但采集到画面和数据还不够,Vision模块还需要把这些原始信息转化成模型能够理解的格式。摄像头拍到的是平视画面,系统会通过算法将其转化为BEV(鸟瞰图)——从正上方俯视的视角,让车辆和行人之间的真实距离一目了然。
随后,视觉编码器将这些画面转化为视觉Token,也就是模型内部能够处理的数字格式,供Language模块进行理解和推理。
L——Language(语言模块)
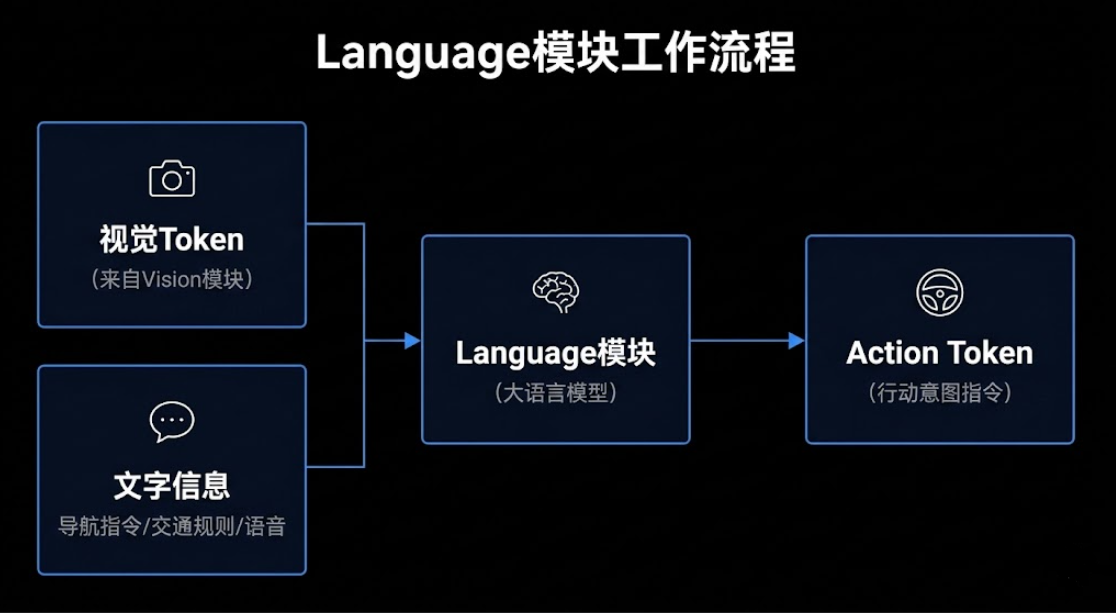
Language模块是VLA的大脑,负责理解Vision模块传来的视觉信息,并结合语言指令做出推理和决策。它的核心是大语言模型,比如LLaMA、Qwen等。
Language模块同时接收两类信息:一类是来自Vision模块的视觉信息,摄像头和传感器采集到的画面,经过视觉编码器处理之后,已经转化成Language模块能够读懂的格式;另一类是文字信息,包括你设定的导航目的地、系统内置的交通规则,或者你直接对车说的话。
接收这两类输入之后,Language模块不是输出一段语言描述,而是输出Action Token——一种结构化的行动意图指令,直接传给Action模块解码成方向盘转角、油门、刹车等控制信号。这是VLA和VLM最根本的区别:VLM说出来但不会动,VLA的Language模块说完了直接传给手脚执行。
但Language模块需要理解的语言,远不止”在下一个路口左转”这么简单。
在自动驾驶数据标注工作中,标注人员会用一句话描述当前场景的问题,比如”前方行人通过,自车未减速,具有VRU碰撞风险”。这类描述会直接作为训练数据进入Language模块。
模型看到类似场景时,就能理解潜在的风险并做出正确判断。Language模块的语言理解能力,很大程度上正是来自这类真实场景的语义标注积累。
A——Action(动作模块)
Action模块是VLA的手脚,负责把Language模块输出的Action Token转化成车辆真正能执行的控制信号。
它的输出有两种形式:一种是直接的底层控制量,包括方向盘转角、油门踩多少、刹车力度;另一种是未来几秒的行驶轨迹,也就是规划出接下来车要走的路径,再交给底层控制器执行。
Action模块是整个VLA闭环里最后也是最关键的一环。Vision看懂了世界,Language想清楚了该怎么做,但如果Action模块输出的动作不够精准、不够平滑,前面两个模块做得再好也没有意义。它直接决定了乘客坐在车里的真实感受——是顺畅的行驶,还是急刹和抖动。
VLA的优点
减少模块间的信息损耗
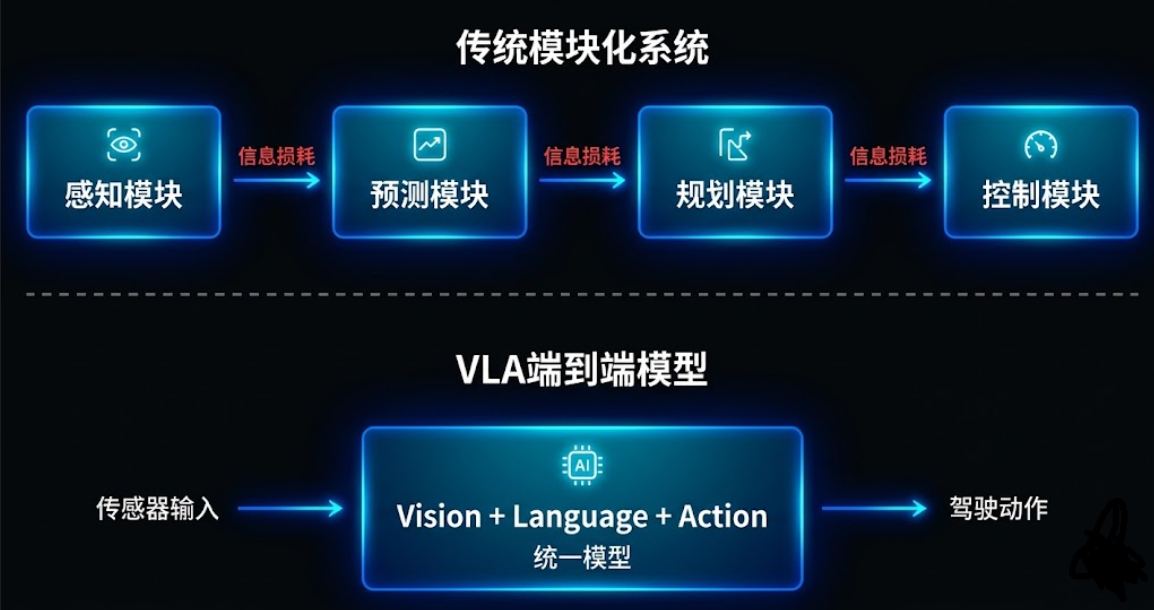
以前自动驾驶把感知、预测、规控分成好几个独立模块,信息每传一次就可能出错,出了问题也很难定位是哪个环节的锅。
VLA把它们统一在一个模型里,信息直接流通,减少了中间传递带来的误差。
能理解复杂的语义场景
传统端到端模型遇到训练数据里没出现过的情况,往往直接失效。VLA继承了大语言模型的常识推理能力,能理解”前方是学校要减速”、”交警在路口指挥要让行”这类语义,处理复杂和陌生场景的能力更强。
决策更全面、执行更稳定
VLA生成动作时,不只看当前这一帧画面,还会综合考虑当前车速、历史动作等状态信息,因此在复杂路况下表现更稳定,也能更好地完成需要连续多步骤的长距离驾驶任务。
响应速度更快
与传统模块化系统相比,VLA省去了模块间的信息传递等待,整体响应更快。但加入语言推理层之后计算量也随之增加,速度不一定比纯端到端更快。这也是为什么小鹏VLA 2.0专门去掉了语言转译层,把推理时延压缩到80毫秒,在速度和智能之间找到平衡。
VLA面临的挑战
尽管VLA在自动驾驶领域展现出巨大潜力,但目前仍面临两个尚未完全解决的核心挑战。
模型泛化能力不足
VLA能处理好它”见过”的世界,但现实道路的复杂程度远超任何训练数据集。换一个城市、换一种天气、遇到施工临时导改或交警打手势,模型往往束手无策。
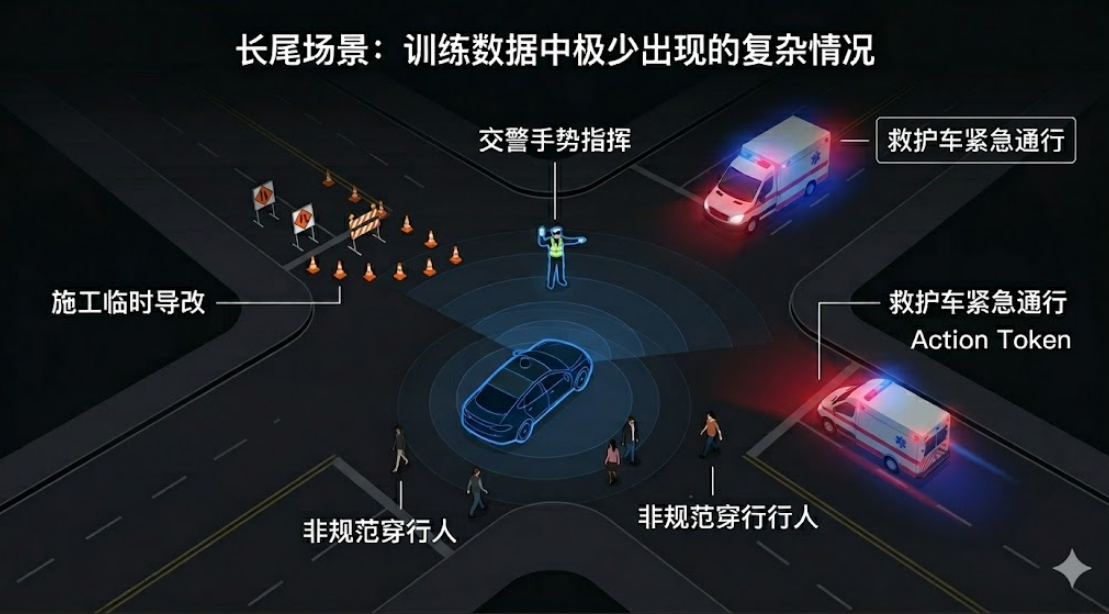
更深层的原因在于,仿真环境和真实道路之间始终存在差距——光线、物体纹理、其他车辆的行为模式都和现实有细微不同,模型在仿真里学到的东西无法百分之百迁移到真实道路上。
行业目前的应对方向是两条腿并行:持续扩大真实场景的数据采集范围,同时借助仿真平台生成极端场景数据作为补充。但这条路成本高、周期长,是一场持续的消耗战。
安全可靠性有待验证
VLA的语言推理能力让它比传统端到端更聪明,但聪明不等于安全。传感器在强光、雨雾、硬件故障等极端条件下可能出现感知失效,语言推理模块在高度模糊的场景下也可能输出错误判断,最终导致危险的控制指令。
因此工程层面需要额外的机制兜底——模型置信度低于阈值时,接管机制立刻提醒驾驶员介入;主模型异常时,Fallback机制立即切换到保守策略,比如减速靠边停车。
换句话说,VLA的智能负责应对常规和复杂场景,安全机制负责在模型失效时守住最后一道防线。
总的来看,不论是小鹏VLA 2.0的量产落地、理想MindVLA的发布,还是ICLR上VLA相关论文三年翻了两个数量级,都在指向同一个方向——VLA正在成为自动驾驶的下一个核心范式。
但这条路还远没有走完。
从技术层面看,VLA仍在快速迭代。如何进一步缩小仿真与现实的差距、如何让模型在更少数据的情况下适应新城市新场景、如何在保持智能推理能力的同时把推理速度压得更低——这些问题还没有标准答案,各家车企和研究机构都在用自己的方式探索。
从行业层面看,VLA的意义不只是让车开得更好。它让自动驾驶系统第一次真正具备了”理解世界”的能力,而不只是”执行规则”。这个转变,或许才是从辅助驾驶走向真正无人驾驶最关键的一步。
值得关注的是,VLA的底层框架同样适用于机器人、无人机等其他需要感知世界并做出行动的物理设备。自动驾驶只是它落地最快的场景,但不会是终点。
本文由 @小王的智驾科普 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


