
 起点课堂会员权益
起点课堂会员权益开源模型越来越落后?Meta甩出全新Llama 3应战
就在当地时间4月18日,Meta的Llama 3正式亮相了,Meta还透露他们目前正在开发一款超过4000亿参数的Llama 3模型。我们不妨来看看本文的分享。

如同闷了很久,突然下的一场雨——Llama 3终于来了。
美国当地时间4月18日,Meta公司推出其开源大语言模型“Llama”(直译是“羊驼”)系列的最新产品——Llama 3。更准确地说,是发布了Llama 3系列的两个版本:包含80亿参数的Llama 3 8B和包含700亿参数的Llama 3 70B。
Meta表示,Llama 3在性能上实现了重大跃迁。并称它为“迄今为止最强的开源大模型”。就其参数量而言,Llama 3 8B和Llama 3 70B是目前市场上表现最佳的生成式AI模型之一,这两款模型都是在两个专门构建的含24000个英伟达GPU的集群上训练的,在15万亿个Token上预训练的。
除此之外,Meta透露,他们目前正在开发一款超过4000亿参数的Llama 3模型。这款模型不仅能用多种语言进行对话,还能处理更多数据,理解图像及其他非文本模式,力求使Llama 3系列与Hugging Face的Idefics2等开源模型保持同步。
消息一出便引起热议,埃隆·马斯克(Elon Musk)在杨立昆(Yann LeCun)的X下面评论:“还不错(Not bad)。”
英伟达高级研究经理、具身智能负责人Jim Fan认为即将推出的Llama 3-400B+模型将是社区获得GPT-4级别模型的重要里程碑。
“这将为许多研究项目和初创企业带来新的发展机遇。Llama-3-400B目前还在训练中,希望在接下来的几个月能有所提升。这样强大的模型将开启大量研究的可能性。期待整个生态系统中创新活力的大爆发!”Jim Fan在X写到。

Meta在一篇博客文章中表示:“我们的近期目标是让Llama 3支持多语种和多模态输入,拓宽处理的上下文范围,并继续在核心功能如推理和编程方面提升性能。未来我们还将推出更多功能。”
同时,Llama 3将在亚马逊、微软、谷歌云等云平台得到启用,并得到英伟达等芯片巨头和戴尔的硬件支持。并基于Llama 3升级了人工智能助手Meta AI,Meta将其称为“免费使用的最智能AI助手”。
Llama 3的主要亮点有:
- 使用超过15万亿token进行训练,是Llama 2数据集规模的7倍以上;
- 在至少9个基准测试中展现出领先的性能;
- 数学能力优秀, Llama 3在推理、代码生成和指令遵循等方面取得了显著进步;
- Llama 3的错误拒绝率大幅降低;
- 配备了Llama Guard 2、Code Shield等新一代的安全工具。
一、超4000亿参数规模,超15万亿的训练token
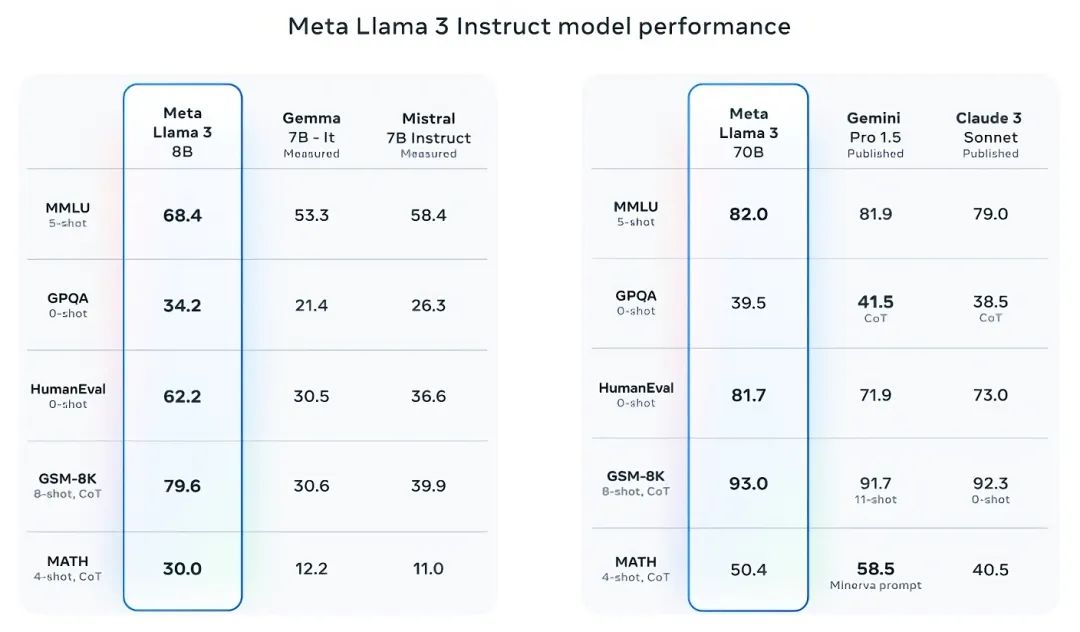
Llama 3 在9项标准测试基准上都有着更好的表现,如都在70亿参数级的Mistral 7B模型和Google Gemma 7B模型等。
这9个基准测试包括MMLU(测试知识水平)、ARC(测试技能获取)、DROP(测试对文本块的推理能力)、GPQA(涉及生物、物理和化学的问题)、HumanEval(代码生成测试)、GSM-8K(数学应用问题)、MATH(数学基准)、AGIEval(问题解决测试集)和BIG-Bench Hard(常识推理评估)。

来源:Meta
Llama 3 70B在MMLU、HumanEval和GSM-8K上战胜了Gemini 1.5 Pro,虽然它可能无法与Anthropic的最高性能模型Claude 3 Opus相比,但在五个基准测试(MMLU、GPQA、HumanEval、GSM-8K和MATH)上表现优于Claude 3系列中的Claude 3 Sonnet。
来源:Meta
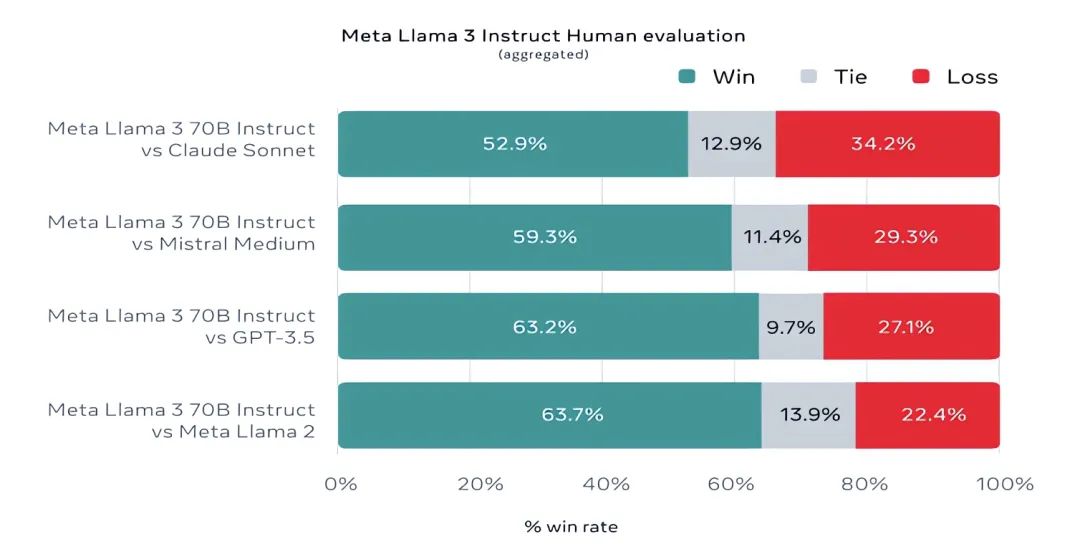
值得一提的是,Meta还开发了自己的测试集,涵盖了从编程和创意写作到推理和摘要的各种用例。Meta 表示,他们构建了一个新的、高质量的人类评估集,包括涵盖 12 个关键场景的 1800 个提示词。这些场景包括寻求建议、头脑风暴、分类、闭卷问答、开卷问答、编程、创意写作、信息提取、塑造角色形象、推理、改写和总结。在这个评估集中的测试显示,70B 版本的 Llama 3 在指令调优后,在对比 Claude Sonnet、Mistral Medium、GPT-3.5 和 Llama 2 的比赛中,其胜率分别达到了 52.9%、59.3%、63.2%、63.7%。
来源:Meta
Meta表示,Llama 3有着更高的“可控性”,基本不会拒绝回答问题。同时在涉及历史和STEM领域(如工程和科学)的题目以及一般编程建议上更高的准确性。这要得益于一个包含15万亿token的集合(约7500亿个单词),它是Llama 2训练集的7倍。
那么,数据来自哪里?
Meta透露,这些数据来自“公开可获得的资源”,并包含了比Llama 2训练数据集中多4倍的代码量,且为了满足未来多语言的需求,Llama 3的预训练数据集中包含超过5%的高质量非英语数据,涵盖了30多种语言。Meta 预计,非英语语种的性能可能与英语有所差异。
Meta还使用了AI合成数据创建用于Llama 3模型训练的更长文档,虽然这种方法由于潜在的性能缺陷而备受争议。
“虽然我们今天发布的模型只针对英语输出进行了微调,但数据的增多帮助模型更好地识别差异和模式。”Meta在博客中写道。
许多生成式AI供应商将训练数据视为竞争优势,因此常常保密相关信息。此外,训练数据细节可能触发知识产权相关的诉讼,这也是他们不愿透露太多的一个原因。最近的报道称,Meta为了在AI领域保持竞争力,一度使用受版权保护的电子书进行训练。
目前Meta和OpenAI因涉嫌未经授权使用版权数据进行训练,正面临包括喜剧演员Sarah Silverman在内的作者提起的法律诉讼。
Meta近期计划推出Llama 3的新功能,包括更长的上下文窗口和更强大的性能,并将推出新的模型尺寸版本和公开Llama 3的研究论文。
二、Llama 3 要素拆解
Meta一直强调创新、扩展和优化的重要性。因此在开发 Llama 3 时,Meta 遵循了这一设计哲学,专注于四个核心要素:
- 模型架构:Llama 3使用了标准的纯解码器Transformer架构,并在 Llama 2的基础上进行了改进。它引入了一个128K token的tokenizer,大幅提升了语言编码效率。Meta 在开发中还加入了分组查询关注(Grouped Query Attention, GQA),以提高模型在处理 8B 至 70B 大小模型的推理效率。训练时,模型处理高达 8192 token 的序列,且设计了掩码机制以防止注意力机制跨越文档边界。
- 数据工程:Meta构建了一个大型且高质量的训练数据集,规模是Llama 2的七倍,代码量是四倍。Llama 3的训练涵盖了超过15T的 token,包括超过5%的高质量非英语数据,支持30多种语言。Meta采用了启发式过滤器、NSFW过滤器、语义重复数据删除以及文本分类器等方法来确保数据质量,并进行了大量实验以评估混合不同来源数据的最佳方法。
- 扩大预训练规模:Meta制定了详细的Scaling Law来最大化预训练数据的利用,这有助于优化模型性能,尤其是在如代码生成等关键任务上。在实际训练过程中,Llama 3的性能通过在达到15T token的训练量后还在对数线性增长,表现出其持续的学习能力。为了训练大规模模型,Meta结合了数据并行化、模型并行化和管道并行化技术,并在16K GPU上实现了高达400 TFLOPS的计算利用率。
- 指令微调优化:为了优化Llama 3的聊天和编码等使用场景,Meta 创新了其指令微调方法,结合了监督微调、拒绝采样、近似策略优化和直接策略优化等技术。这些技术不仅提升了模型在复杂任务中的表现,还帮助模型在面对难解的推理问题时能生成正确的解答路径。
在安全性方面,Meta的责任体现在采用了最高级别的系统级(system-level)方法来开发、部署Llama模型,希望将其作为一个更大系统的核心部分,赋予开发者主导设计的权力。此外,Meta 还对经过指令微调的模型进行了红队测试。
Llama Guard模型可提供及时的安全响应能力,可以根据需求调整,以适应新的安全标准。Meta还推出了CyberSecEval 2和Code Shield,分别用于增强对潜在安全风险的评估和提高对不安全代码的过滤能力。
在AI技术迅速发展的今天,Meta通过不断更新的《负责任使用指南》(RUG)和多种云服务工具,引导开发者负责任地使用和部署LLM,确保内容的安全与合规。
同时,Meta披露,Llama 3即将在亚马逊云(AWS)、Databricks、谷歌云、Hugging Face、Kaggle、IBM WatsonX、微软云Azure、NVIDIA NIM和Snowflake等多个平台上推出。这一过程得到了AMD、AWS、戴尔、英特尔和英伟达等公司的硬件支持。
在英伟达的加持下,Meta的工程师在一个包含24,576个英伟达H100 Tensor Core GPU的计算机集群上训练了Llama 3。为了推动生成式AI技术,Meta 计划在其基础设施中使用35万块H100芯片。
英伟达已经推出了支持Llama 3的各种平台,包括云服务、数据中心、边缘计算和个人电脑。开发者可以在英伟达的官网试用Llama 3,企业用户可以通过NeMo框架利用自己的数据对Llama 3进行优化。
Llama 3还可在英伟达的Jetson Orin模块上运行,这对机器人开发和边缘计算设备极为重要。此外,NVIDIA RTX和 GeForce RTX GPU能够加速Llama 3的推理过程,这使得它也适用于工作站和个人电脑。
近期,开源和闭源之争再次引发行业内的激烈讨论。开源模型会越来越落后?Meta用Llama 3给出了回应。
Meta的这次表态,也显得意味深长:“我们致力于开放式人工智能生态系统的持续增长和发展,以负责任的方式发布我们的模型。我们一直坚信,开放会带来更好、更安全的产品、更快的创新和更健康的整体市场。这对Meta和社会都有好处。”
Llama这只羊驼,仍在狂奔中睥睨对手。
作者:苏霍伊;编辑:王博
原文标题:开源模型越来越落后?Meta甩出全新Llama 3应战|甲子光年
来源公众号:甲子光年(ID:jazzyear),立足中国科技创新前沿阵地,动态跟踪头部科技企业发展和传统产业技术升级案例。
本文由人人都是产品经理合作媒体 @甲子光年 授权发布,未经许可,禁止转载。
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


