
 起点课堂会员权益
起点课堂会员权益Karpathy教你搭「第二大脑」:三个文件夹就够了
Andrej Karpathy 提出的个人知识库方案,摒弃了复杂的数据库与专用软件,仅用三个文件夹和一个规则文件,便实现了 AI 对知识的自动化整理与关联。这一极简架构不仅降低了知识管理的门槛,更通过自然语言指令将规则与执行分离,让知识库在不断的问答中实现复利增长。文章深入剖析了该系统的设计逻辑与操作细节,为知识工作者提供了一种高效、可持续的知识管理范式。
Karpathy 前两天发了条帖子,教大家怎么用 AI 搭建个人知识库。252K 浏览,4.1 万人收藏。
他的方案简单到让人怀疑:三个文件夹 + 一个规则文件。没有数据库,没有专用软件,没有花哨的插件。就是纯文本文件,让 AI 帮你整理成一个不断进化的个人维基。
Nick Spisak 把 Karpathy 的思路拆解成了一个 7 分钟就能跟做的完整教程。我读完之后觉得,这可能是目前最实用的 AI 知识管理方案——因为它没有任何门槛。
想想看,你有多少好文章读完就忘了?多少灵感记在某个角落再也没翻过?多少次想引用一个数据,却怎么也找不到当初在哪看的?这套系统就是为了解决这些问题。
Nick Spisak 原帖:252K 浏览,1.8K 转发
01 三个文件夹
整个系统的骨架,就是三个文件夹:
my-knowledge-base/
raw/ (原始素材——文章、笔记、截图)
wiki/ (AI 整理后的知识库)
outputs/ (AI 生成的回答、报告、研究)
raw/ 是你的素材抽屉。文章、笔记、截图、会议记录,什么都往里扔,不用整理。wiki/ 是 AI 替你维护的知识百科。outputs/ 存你向 AI 提问后得到的分析和报告。
没有需要安装的软件,没有需要注册的账号。就这三个文件夹。
这就好比你家里有三个抽屉:一个专门放收到的信件和账单(raw/),一个放你整理好的家庭档案(wiki/),一个放你基于这些档案做出的决策记录(outputs/)。你只管往第一个抽屉塞东西,AI 会帮你把它们归档到第二个抽屉,然后在你需要做决策的时候从第二个抽屉里提取信息放到第三个。
Karpathy 被问到他的工具栈时,原话是这么说的:
我尽量保持极简和扁平。就是一个嵌套的 .md 文件目录。
02 往里塞东西
大多数人卡在第一步:创建完文件夹,然后盯着空的 raw/ 目录发呆——不知道该放什么。
答案是:什么都放。把文章复制粘贴成 .md 或 .txt 文件。把截图和图表存进去。把笔记软件里的东西导出来。会议记录、研究论文、项目文档、攒了几个月的书签——全扔进去。
不要整理,不要重命名,不要清理格式。那是 AI 的活。
Nick 自己的内容管道里有 17 个原始素材文件——竞品分析、数据报告、剪藏文章。没有一个是手动整理的。
我自己试了一下,把最近三个月读过的文章、做过的研究、记过的笔记全扔进了一个 raw/ 文件夹。一共大概 40 多个文件,有的是 Markdown,有的是纯文本复制粘贴,有的甚至就是截图。乱七八糟的。但这恰恰是重点——你不需要在输入阶段花任何精力。
03 自动采集
Karpathy 没提到的一个加速技巧是:自动化采集。
Vercel Labs 刚发布了 agent-browser,一个免费的命令行工具,让你的 AI 代理控制真实浏览器。GitHub 上已经超过 2.6 万星。安装只要两行命令:
npm install -g agent-browseragent-browser install
用起来也很直接——告诉 AI「抓取这个网页,存到 raw/ 里」,agent-browser 会打开页面、提取文字、保存文件,你连浏览器都不用打开。
关键优势:它比 Playwright MCP 省 82% 的 token 消耗。同样的会话预算,能抓取 5-6 倍的页面。而且它能处理那些复制粘贴搞不定的场景——JavaScript 动态加载的页面、需要登录的内容、需要滚动和点击「加载更多」的长文章。
你的 raw/ 文件夹可以自己填满自己。
当然,不用 agent-browser 也完全没问题。最原始的方法——复制粘贴到文本文件——同样有效。关键不是采集方式有多花哨,而是你有一个地方统一存放这些素材。很多人的问题不是没有好的信息来源,而是信息散落在浏览器书签、微信收藏、备忘录、各种 App 里,从来没有被集中处理过。
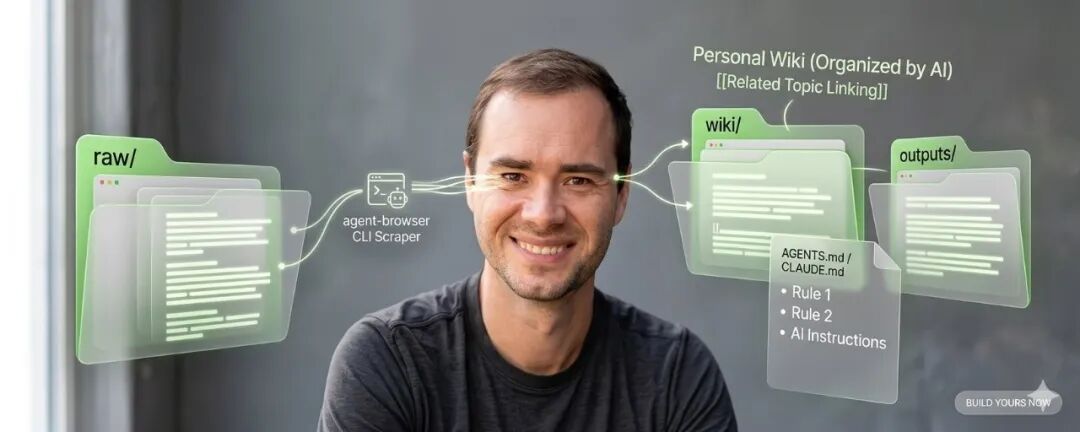
Karpathy 的知识库系统:三个文件夹 + 一个规则文件
04 规则文件
这是整个系统里最容易被跳过、但最重要的一步。
在项目根目录创建一个文件,叫 CLAUDE.md(或者 AGENTS.md、README.md,名字不重要,内容才重要)。这个文件就是 AI 的操作手册——告诉它你的知识库是关于什么的,应该怎么组织。
一个最小可用的模板长这样:
# 知识库规则
## 这是什么关于 [你的主题] 的个人知识库。
## 目录结构
– raw/ 存原始素材,不要修改这些文件
– wiki/ 存整理后的维基,由 AI 全权维护
– outputs/ 存生成的报告和分析
## 维基规则
– 每个主题一个 .md 文件
– 每个文件开头是一段摘要
– 用 [[主题名]] 格式互相链接
– 维护一个 INDEX.md 索引文件
– 有新素材时更新相关文章
这就是整个系统的灵魂。没有数据库,没有插件,就一个文本文件告诉 AI 游戏规则。
写规则文件的时候,有几个细节值得注意。首先,「我的兴趣」那一部分特别重要——它告诉 AI 在整理素材的时候应该侧重什么角度。同样一篇关于 AI 的文章,一个做投资的人和一个做产品的人,关注的要点完全不同。这个部分就是你的「视角过滤器」。其次,维基规则里的「互相链接」是关键——它强制 AI 在整理每篇文章的时候思考「这和其他已有知识有什么关系」,这才是知识管理的核心价值所在。
我自己每个项目也这么用——一个 CLAUDE.md 文件定义 AI 的行为边界和工作方式。这个思路完全一样。
为什么这么简单的东西这么管用?因为大语言模型天生擅长理解自然语言指令。你不需要用数据库的查询语法,不需要写代码定义数据结构,你只需要用人话告诉它「这是什么、怎么组织」,它就能执行。这才是 AI 时代知识管理的范式转换——规则用人话写,执行交给机器。
05 让 AI 编译维基
打开 Claude Code(或 Cursor,或任何能读取本地文件的 AI 编程工具),指向你的项目目录,然后说:
读取 raw/ 里的所有内容。然后按照 CLAUDE.md 的规则,在 wiki/ 里编译成一个维基。先创建 INDEX.md,再按主题各建一个 .md 文件。把相关主题链接起来。给每个来源写摘要。
然后走开,让它干活。
等它跑完,你会发现 wiki/ 文件夹里多了一堆整理好的文章——你没发现的关联被串起来了,你忘了自己存过的东西被写成了摘要,还有一个索引文件让你几秒钟内找到任何内容。
重要的是:你不要手动编辑维基。那是 AI 的活。你只负责读、提问,AI 负责维护。
这一步最让我惊讶的是 AI 发现关联的能力。我扔进去的 40 多个文件里,有几篇关于 AI 编程工具的评测和几篇关于开发者生产力的研究论文——我自己从来没把它们联系在一起。但 AI 在编译维基的时候,把它们交叉引用了,生成了一篇叫「AI 工具对开发效率的实证研究」的维基文章,把散落在不同来源里的数据点串成了一条完整的论证链。
这就是「第二大脑」的真正价值——不是帮你记住东西,而是帮你发现你自己没注意到的联系。
06 越问越聪明
当你的维基积累到 10 篇以上文章时,开始向它提问:
「根据 wiki/ 里的所有内容,我对这个领域的理解有哪三个最大的盲区?」
「来源 A 和来源 B 对这个概念的说法有什么不同?分歧在哪?」
「只用知识库里的素材,给我写一个 500 字的关于某话题的简报。」
AI 会跨所有维基文章进行检索,给你基于你自己收集的素材的回答——不是网上随便搜来的。
然后把这些回答也存回知识库。扔进 outputs/ 或者让 AI 更新相关维基文章。每一个问题都让下一个回答更好。这就是复利循环。
这和传统的搜索引擎有本质区别。Google 给你的是全世界的信息;你的知识库 AI 给你的是基于你自己精选的素材的分析。前者广但浅,后者窄但深。当你需要在某个领域做出判断的时候,后者的价值远远大于前者。
而且这个循环真的会越转越快。当你的维基有 50 篇文章的时候,AI 回答的质量和第一次只有 5 篇文章时完全不可同日而语。因为它的「上下文」不断在膨胀——你在主动帮它建立一个越来越完整的世界模型。
07 月度体检
告诉你的 AI:
检查整个 wiki/ 目录。找出文章之间的矛盾。找出被提到但没有解释的概念。列出所有没有 raw/ 来源支撑的结论。建议 3 篇能填补空白的新文章。
为什么要做体检?有人在 Karpathy 帖子下面指出了一个很现实的问题:「当输出被存回去的时候,错误也会复利增长。」
确实如此。如果 AI 写了一个小错误,你把它存回知识库,下一次的回答就会建立在这个错误之上。月度体检就是防止这种雪球效应的安全网。
这就像给你的投资组合做定期审计。复利是双向的——正确的知识会复利增长,错误的知识也会。不做体检,你的「第二大脑」可能会变成一个自信满满但频繁出错的顾问。
08 工具不重要
Karpathy 帖子下面一半的回复都在推荐 Obsidian 插件。Lex Fridman 用 Obsidian + Cursor。已经有三家创业公司在做专门的知识库工具。
但你知道 Karpathy 自己怎么说的吗?「就是一个嵌套的 .md 文件目录。」
装了 47 个插件的 Obsidian,就是下一个 Notion 陷阱。你花在配置工具上的时间,比花在真正使用知识库上的时间还多。纯文本文件 + 一个好的规则文件,90% 的情况下会跑赢那些花哨的工具。
这话不是空说的——Nick 说他在几十个客户的项目里亲眼验证过。
别再找完美的工具了。开始搭建。
我认为这是整篇文章里最有价值的观点。我们在知识管理领域见过太多「工具痴迷症」——每换一个新工具就要花一周迁移数据、两周学习功能、三周配置工作流。等你终于把工具搞明白了,你已经忘了当初为什么要做知识管理。
纯文本文件永远不会过时。十年后不管什么操作系统、什么 AI 模型,.md 文件照样能打开。你能对 Notion 或 Obsidian 的插件生态说同样的话吗?
09 对我们意味着什么
这个方案让我想到一个更大的趋势:AI 正在把「个人知识管理」从工具问题变成结构问题。
过去十年,我们在知识管理上走了一条弯路。从 Evernote 到 Notion 到 Obsidian,每一代工具都在增加功能、增加复杂度,让你相信你需要更强大的软件。结果呢?大多数人的笔记软件里积灰比知识多。
Karpathy 的方案把这件事拉回了原点:你不需要更好的工具,你需要一个好的结构——然后让 AI 做剩下的苦力。
这和软件工程里的一个老道理一模一样:好的架构比好的代码重要。你可以用最简陋的工具写出优秀的软件,但如果架构是错的,再华丽的代码也救不了。知识管理也是一样——三个文件夹的架构,比 Notion 的一万个功能更有用。
几个值得记住的要点:
- 简单胜过复杂——三个文件夹 + 一个规则文件,胜过任何花哨的应用
- 让 AI 做整理——你负责输入原始素材和提问,AI 负责组织和维护
- 复利效应——每一次提问和输出都让知识库更聪明,但别忘了定期体检纠错
4.1 万人收藏了 Karpathy 的帖子。收藏和真正受益之间的距离,就是一个周末的搭建时间。
选一个你感兴趣的主题,建三个文件夹,把手头的素材扔进去,让 AI 接管剩下的。
4.1 万人收藏了 Karpathy 的帖子。但收藏从来不等于行动。这个周末,花两个小时搭起来,往后每一天它都在替你工作。这可能是 2025 年你能做的回报率最高的时间投资之一。
数据来源:Nick Spisak (@NickSpisak_), https://x.com/nickspisak_/status/2040448463540830705
本文由人人都是产品经理作者【深思SenseAI】,微信公众号:【深思SenseAI】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


