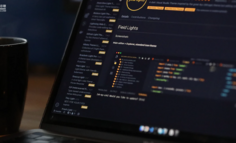
Claude 三件套:从想清楚,到看得见,到做出来。它要把”想法变产品”全包了
Anthropic 用 Claude、Claude Design、Claude Code 构建了一条从想法到产品的 AI 流水线。这套组合拳让产品经理在一天内完成从需求梳理、原型设计到代码落地的全流程,将传统耗时一个月的验证周期压缩到 8 小时。本文深度解析这条颠覆性的生产链路如何重构产品开发逻辑。

 起点课堂会员权益
起点课堂会员权益