
 起点课堂会员权益
起点课堂会员权益B端用户画像——ID Mapping
编辑导语:ID mapping的建立有助于帮助营销人员获得渠道有效性的反馈,进而可以帮助营销人员进行更加精准的投放,在获得用户画像反馈之后,也能进一步提升用户体验。本篇文章里,作者就B端用户画像中的ID mapping做了总结和梳理,一起来看一下。

一、引言
在《一篇文章让你掌握企业画像》一文中,提到企业画像对于“达到一定用户规模的面向中小型客户的SaaS产品公司”是很有必要的。不过,建立企业画像的基础,首先是用户ID mapping的问题。今天我们就来讲讲这个话题。
二、为什么要做ID mapping
假设这样一个场景:
- 第一天,客户张三在公司电脑上看了一下产品详情页;
- 第二天,他在手机上关注了公司的一个微信公众号;
- 第三天,张三在手机上看了三篇微信公众号文章;
- 第四天,张三在手机上下载了一个产品说明文档,下载的时候他输入了自己的邮箱;
- 第五天,张三在公司电脑上申请了试用,试用的时候他用的账户就是他的邮箱,并且同时输入了手机号;
- 第六天,他用手机拨打了客服热线,咨询一个产品问题。
如果没有ID mapping,客服人员就无从知道他已经看过产品、公众号,试用过产品,无法在第一时间准确获得张三的购买意向。并且随着营销渠道越来越多,如果不去识别碎片化的个人,客户的行为就被割裂,从客户角度考虑会影响客户体验。
从公司角度,我们也无法知道评估营销渠道的有效性,即客户买这个产品到底是因为只是看产品详情页,还是看了公众号,还是二者皆有。
三、如何做B端的ID mapping
既然需要解决,我们或可采取两个方案并举。
方案1:在营销阶段尽可能多地捕捉用户信息,比如在下载产品说明文档或者试用时,不仅要求客户填写邮箱,还需要填入手机号。这也是为什么很多B端产品的下载或者申请demo要求用户输入更多信息的原因。当然,这个方案的缺点是客户很可能在这个阶段就放弃继续探索。
方案2:可参照目前C端的用户画像中的解决方案,利用一定的规则把割裂的行为串联起来。仍然以上述用户张三为例,在不同行为中,张三留下了不同的标识,利用不同行为中共同的标识,可以很容易地找到行为间的关联关系,下图红色所示:
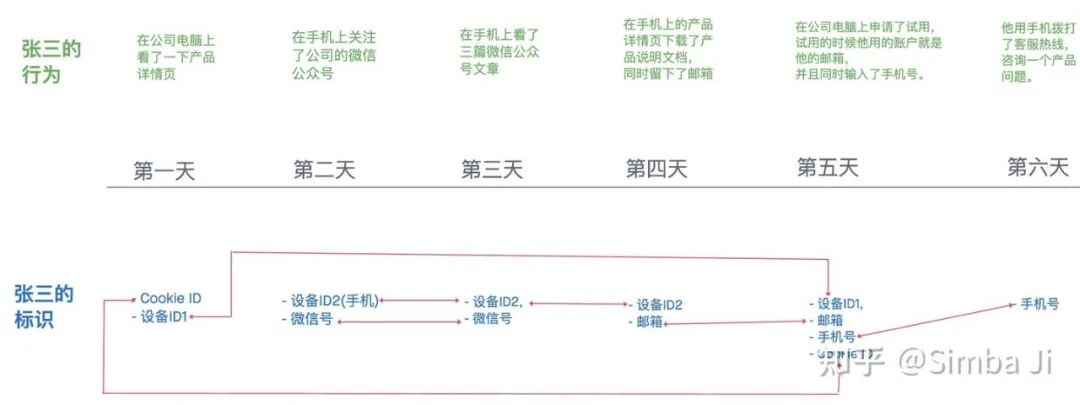
第一天,获取了一个用户,我们把Cookie ID 和设备ID1 作为用户标识保存起来,创建用户001。
第二天,又获取了一个用户,我们把设备ID2和微信号作为用户标识保存,创建用户002。
第三天,我们发现这个用户的设备ID2和微信号和用户002相同,我们初步判断两个行为背后是一个人。于是把这两个行为关联到一个人上。
第四天,我们发现这个用户的设备ID2和用户002的设备ID2相同,我们初步判断两个行为背后可能是一个人,于是把第四天留下的邮箱作为用户002的标识保存起来。至此,用户001 和用户002 还未建立联系。
第五天,我们发现用户邮箱和用户002相同,设备ID1和cookieID 和用户001相同。判断用户001和用户002可能是一个人。于是将用户001 和用户002 合并。
合并后的用户拥有以下ID:
- Cookie:Cookie ID;
- 设备号:设备ID1,设备ID2;
- 微信:微信号;
- 邮箱:邮箱;
- 手机:手机号。
第六天,我们发现,手机号和合并后的用户一致,于是判断打电话的行为和过去的行为背后是一个人。
细心的读者可能会发现,你这有漏洞呀,比如第三天和第四天的行为,设备ID2很可能是被多人使用的,如果是这样,邮箱和微信号之后无法建立联系,在后面也就无法把用户001 和用户002 关联起来了呀。
为解决这个问题,就需要我们从业务角度建立一些规则。这里就以笔者曾经使用过的Segment 为例说明(Segment号称是#1 CDP-Customer Data Platform to Manage Customer Data)。
Segment 有一个 three Identity Resolution rules——即三大用户标识识别规则,分别是:
1)Block Values. 管理员可设置某些值为无效值,比如公司内部用的测试账户ID,某些一眼看上去无效的账户ID,比如0000@000.com。
2)Limit:即管理员可以设置某个类型的ID一个用户最多在多长时间内可以拥有几个。比如cookie ID设为一天最多可以有10个,我想除非是测试,否则没有哪个正常的用户会一天清理缓存重新生成cookie 超过10次。比如设备ID, 我们估计一下换手机换电脑的频率,一个用户一年应该不会超过2次,可以设Limit 为2个每年。
这其中当然有误差,所以我们也要看具体业务场景。作为用户画像工具,我们应该允许管理员灵活设置。
3)Priority:即当某类标识ID超出Limit规定的数量时,priority决定由哪个标识留下作为新创建用户的标识。
引用原文例子说明一下,假如系统设立的limit 和 priority 分别如下:
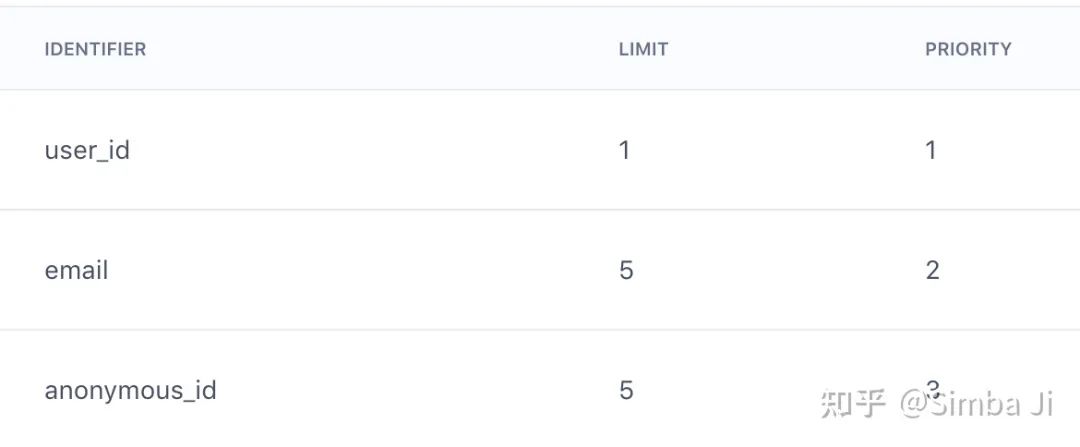
假设系统中已有一个用户, user id为abc,拥有邮箱tom@tom.com。此时又来了一个新用户,user id是 def, 同样拥有邮箱tom@tom.com。因为user_id的limit 为1,而user_id的优先级高于email,那么我们对email 进行降级,只利用user id def 来查找是否有已有用户存在,如果没有,就新建一个用户,user_id为def。
我们用这三个规则套路一下张三的例子:
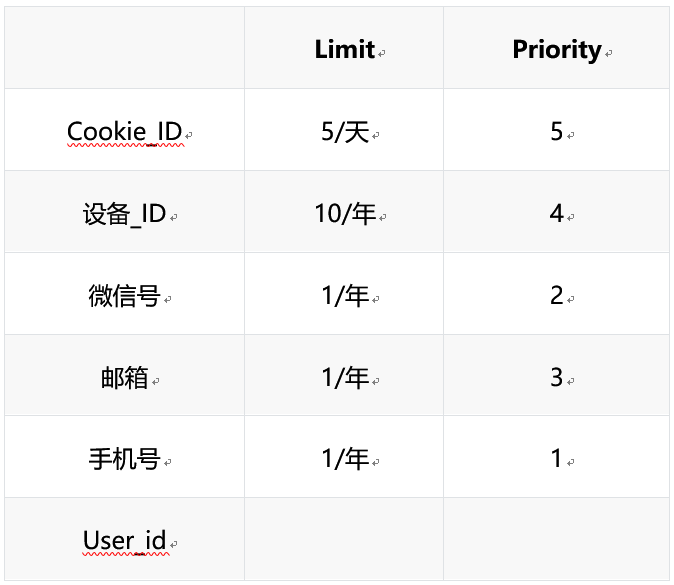
第一天,我们把Cookie ID 和设备ID1 作为用户标识保存起来,创建用户001;第二天,我们把设备ID2和微信号作为用户标识保存,创建用户002;第三天,我们发现这个用户的微信号和用户002相同,微信号只能有一个,我们把这两个行为关联到一个人用户002上。
第四天,我们发现这个用户的设备ID2和用户002的设备ID2相同,因为用户002目前还没有邮箱,把第四天留下的邮箱作为用户002的标识保存起来。
第五天,我们发现用户邮箱和用户002相同,而邮箱只能有一个,所以把行为关联到002上,同时增加了手机号。并且发现设备ID1和cookieID 和用户001相同。且cookie ID 和设备ID 的limit可以是多个,于是将用户001 和用户002 合并。
第六天,发现打电话进来的用户手机号和合并后的用户一致,于是判断打电话的行为和过去的行为是一个人。
当然,识别碎片化的人还可能会有更多场景,这里我们只是学习其中一种,我们还经常遇到比如APP弹出一个加密的被识别出来的可能匹配的账户,让用户确认,是否合并两个用户,这也是一种方法,这其中要同时考虑信息安全和客户体验。
四、总结
本文讲述了B端用户画像中ID mapping的必要性,并以Segment为案例,提供了一个相对比较通用的解决方法供大家参考。但实际上ID Mapping的方法还有很多,大家也可以参考《阿里/网易/美团/58用户画像中的ID体系建设》学习。如有纰漏,欢迎指正。
参考文章
Segment帮助中心:
https://segment.com/docs/personas/identity-resolution/identity-resolution-settings/
作者:Simba,混迹于国内外大厂的B端产品经理;IT老兵,终生学习者;“数据人创作者联盟”成员。
本文由@一个数据人的自留地 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议








好文章居然没人赞,我来顶一下!!!!