
 起点课堂会员权益
起点课堂会员权益工程师开始做PM的活了,那PM在干嘛
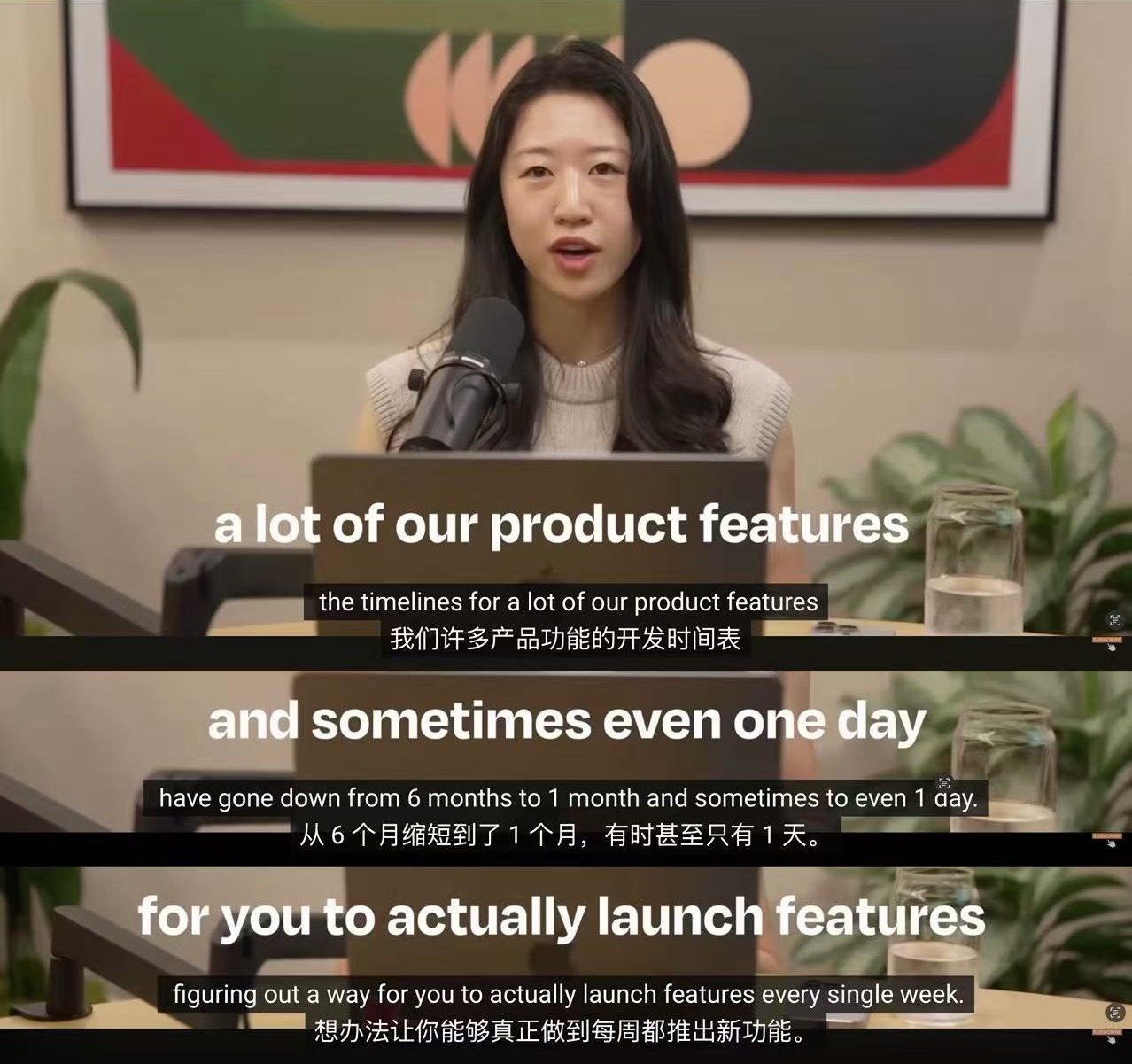
Anthropic的工程师能在短短一周内完成从用户反馈到功能上线的全过程,甚至无需PM介入。这背后隐藏着怎样的产品逻辑?Claude Code的产品负责人Cat Wu揭示了他们的秘密:一张清晰的Agent产品演进地图。从单任务成功到大规模并发,每个决策都能在这张地图上找到坐标。

你上次从用户反馈到功能上线,用了多久?
Anthropic的工程师,用一周。期间没有找PM对齐,没有排期会议,没有需求文档。
这不是特例。Cat Wu是Claude Code的产品负责人,她在接受Lenny Rachitsky采访时说:她团队里有工程师,能从Twitter上看到一条用户反馈,到产品从设计到上线,全链路独立完成,几乎不需要PM介入。
那PM在干嘛?
Cat Wu的答案,和你预想的大概不一样。
先说为什么PRD不管用了
传统产品流程有个前提:你调研完、写完PRD、对齐完所有人,6个月后交付的时候,技术边界跟你最初设计时差不多。这个前提在大多数产品里是对的。
在Anthropic不是。
Cat Wu做了一件很具体的事来说明这件事。从2024年10月开始,每次有新模型发布,她就让Claude Code给Excalidraw加一个表格功能,然后看它能走多远。
Sonnet 3.5 new:失败。后面几个版本:还是失败。2025年6月Opus 4:开始偶尔能成,成功率够稳定,Anthropic拿它做了Claude 4发布会的预录演示。2026年,Opus 4.6:可以在几千名开发者面前直播,不需要预录,不担心翻车。
同一个prompt,两年,从必然失败到可以直播。
METR测量的Agent任务时间上限,同期从21分钟跳到了将近12小时。16个月,41倍。
在这个速度下,6个月路线图意味着什么?你PRD写完的那一刻,所有建立在当前技术边界上的假设,可能已经不成立了。
所以Anthropic不是不规划,是规划的单位缩了。他们把短期探索叫”side quest”——在正式路线图之外,工程师下午自己跑一个假设,PM用Claude Code三小时做出原型直接测。Claude Code桌面版、待办事项功能、AskUserQuestion工具,这几个功能都是side quest跑出来的,没有一个是季度规划会上提出来的。
为什么能这么快——有一张地图
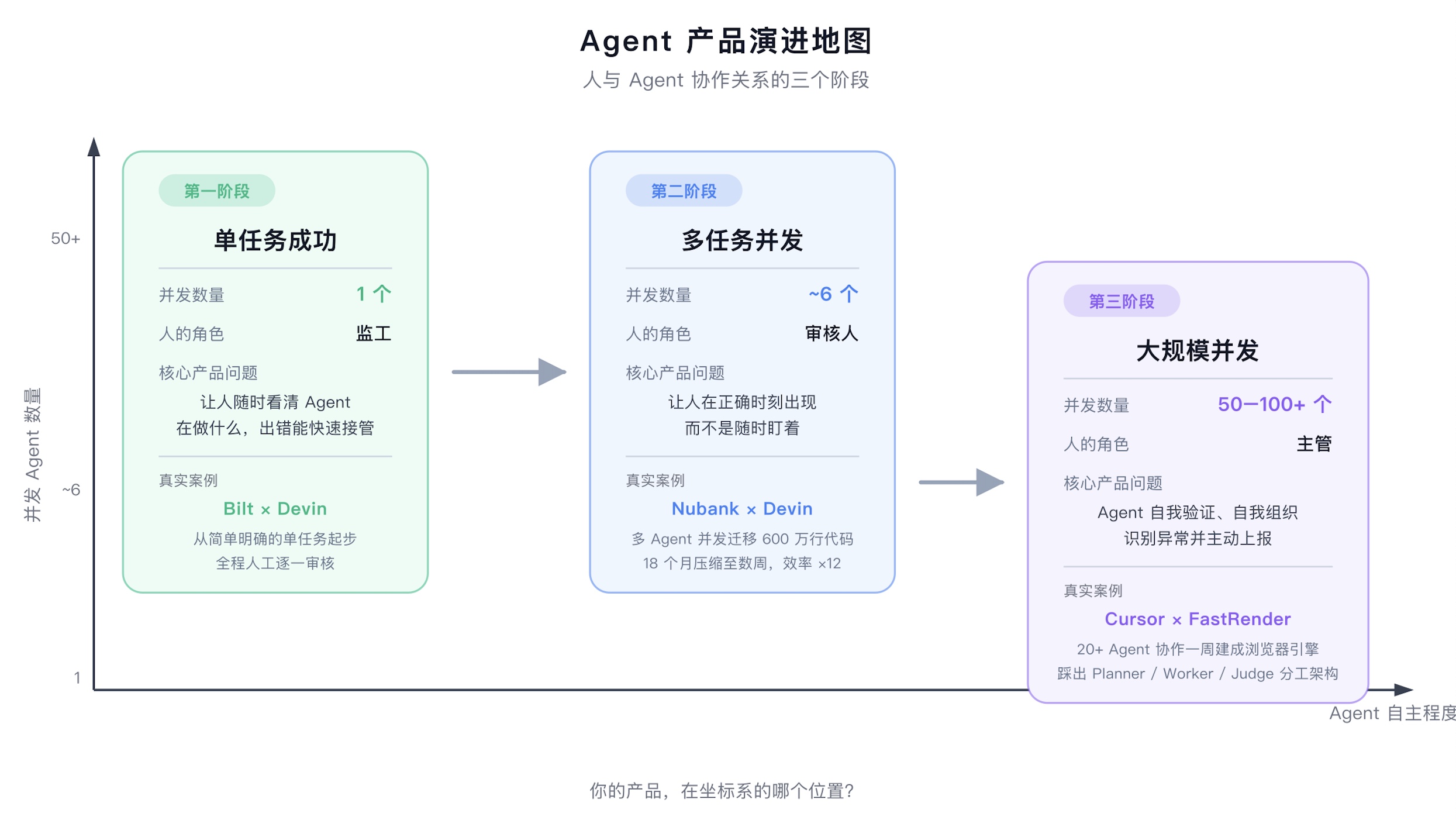
不只是因为没有PRD。背后是Anthropic对Agent产品有一张演进地图,每次产品决策都能在上面找到位置,不用从头对齐。
地图分三个阶段。
第一阶段:单任务成功
Agent能不能从一个清晰的指令出发,稳定完成一件事?
2024年末Claude Code刚出来时,产品逻辑是线性的:你给指令,Agent做,你检查,没问题继续。人一直在旁边盯着。这个阶段产品要解决的问题只有一个:出错了你能快速知道、快速接管。
Bilt是一个典型的第一阶段入场方式。2025年2月他们开始用Devin,起点很克制:只把有明确范围、步骤清晰的简单任务交给Agent,人工全程审核结果。不是因为保守,是因为这是正确的起点——先搞清楚Agent在哪些事情上是可靠的,再往下走。
第二阶段:多任务并发
到2025年底,标准场景变成了同时跑6个任务。
6个任务在跑,你没法全盯着。你能做的是等它们跑完,然后一件件确认:这个对,这个不对,这个重做。你的角色变了——不是监工了,是审核人。
产品要解决的问题也变了:不是怎么让Agent操作更顺,是怎么让你知道什么时候该去看一眼。
Nubank的案例把这个阶段说得最清楚。他们要迁移一个累积了8年、600万行代码的遗留ETL系统,原计划是1000名工程师花18个月。引入Devin之后,一个工程师可以同时监管多个Devin,每个Devin负责一批迁移任务。工程师的工作从写代码变成了验收结果——哪些迁移对了,哪些有问题,哪些要重来。原来估算18个月的工程,几周之内完成了,效率提升12倍。这就是第二阶段的产品逻辑:人不在过程里,人在结果里。
第三阶段:大规模并发
下一步是同时跑50个、乃至几百个Agent。
本地机器内存撑不住,得远端跑。界面不能再是任务列表,你没精力逐条看几百条更新。这个阶段,Agent得能自己验证自己的工作,识别哪些地方需要你介入,把反复犯的错记住不再重犯。
你和Agent的关系,不是用工具了,是管团队。
Cursor在2026年1月做了一个激进的实验:让Agent在一周内从零搭出一个完整的浏览器引擎,项目代码超过100万行。他们尝试了几种多Agent协作架构,最后跑通的是三层分工:Planner持续探索代码库、分解任务,Worker独立执行各自的任务,Judge在每个周期末判断继续还是回退。
他们也踩到了第三阶段最典型的坑:20个平级Agent抢资源会互相卡死;Agent之间没有明确分工就会变保守,主动回避难题。这些不是技术bug,是产品设计问题——Agent团队需要的是组织架构,不只是更多算力。
有了这张地图,每个功能决策都能找到位置。这是帮用户从第一阶段走到第二阶段,还是在解决第二阶段的信息过载,还是在给第三阶段铺路——想清楚这个,决策成本大幅下降。
工程师能独立上线功能,不是绕开了产品判断,是产品判断已经内化在这张地图里了。
“简单的事”,是比你想象的更难做到的选择
Anthropic还有一条从上到下都在讲的原则:做那个有效的简单解法。
听起来废话,实际上反本能。
Claude Code早期有个待办事项功能,当时模型不会可靠地自动勾选完成的项目。团队的解法是每隔几条消息给Agent发个提醒,催它更新列表。有效,但是hack。新模型出来,这个行为成了原生能力,那段提醒代码直接删掉了。
这个模式反复出现。Anthropic的系统提示词曾针对大量模型局限性做了工程调整,Opus 4.6上线之后删掉了20%。
说白了就是:你现在做的那个绕路方案,下一代模型出来可能直接没用。那你为什么要把精力押在上面?
那PM在Agent时代真正该做什么
回到最开始那个问题:如果工程师能自己上线功能,PM在干嘛。
Cat Wu说的是三件具体的事。
第一件:建eval体系
eval这个词听起来像测试工程师的活。但Cat Wu说这件事PM必须自己主导。原因很直接:eval的核心不是跑测试,是定义”什么叫产品做对了”。这个定义只有懂业务、懂用户的人才能给,不是算法能帮你想的。
没有eval,每次模型升级你只能靠感觉判断好不好。有了eval,工程师上线前就能看到数据。这是Anthropic能以天为单位迭代的隐形基础——不是工具,是判断力的系统化。
第二件:培养model taste
model taste说的是:你能感知到模型在什么情况下表现好、什么情况下会失手,能判断能力边界在哪里。
Cat Wu给了三个具体方式。遇到模型产出你没预料到的结果,别直接纠正,先让它解释自己的逻辑——这能帮你实时标定能力边界。找到那些既懂技术又懂业务的人,把他们的反馈当基准。建一个最小的eval集合,几个核心用例,答错了就说明出了大问题。
第三件:定义人介入的边界
Cat Wu说过一个反直觉的结论:95%的自动化成功率是不够的。
为什么?如果Agent有5%的概率出错,但你不知道是哪5%,你就得把100件事全检查一遍。效率优势全消失了。
真正有用的自动化,是让系统识别出那5%出了问题,主动推给你,让你只处理那5%。
怎么定义”出错”,怎么设计”需要你介入”的提示,怎么让Agent验证自己的工作——这些是产品问题,不是技术问题。工程师最难替代你的地方,就在这里。
坐标系比工具更重要
我认识一个做了十几年产品的PM,最近在一家制造业公司主导AI项目。他最大的困惑不是工具怎么选,是说不清楚用户和Agent的关系应该是什么——是监工,是审核人,还是主管。
这个困惑,是大多数企业AI产品现在真实的处境。不是技术不够,是没有坐标系。
Anthropic给了一张。三个阶段,每个阶段人的角色、产品的核心问题都不一样。你在哪个阶段,决定了所有的取舍。
METR的数据在那里:16个月,41倍。指数还在涨。
你的产品,在这张地图的哪个位置?
本文由 @Ve观产品 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议





- 目前还没评论,等你发挥!


