
 起点课堂会员权益
起点课堂会员权益不会算法只用EXCEL如何构建RFM会员价值模型
编辑导语:RFM模型是与用户价值相关的常见模型之一。那么,RFM模型具体应该如何应用?如果非专业数据师,又该如何利用常见工具Excel来计算RFM值、得出有效数据呢?本文作者就介绍了用Excel来构建RFM模型的方法,让我们来看一下。

一、引言
如果你听过客户关系管理(CRM),那么你大概率上也曾听到过RFM模型。在精细化运营的今天,在解决如何更好的挖掘用户价值之前,首先要解决的问题是如何衡量用户价值?
和用户价值有关的模型非常多,除了RFM模型之外,还有客户生命周期价值模型(CLV模型)、客户生命周期模型(AARRR模型)等。不同的模型切入的角度以及具体的应用不同,我们今天主要讲的是RFM模型。
本文主要分为两个部分:一是理论部分,简单告诉大家RFM模型是什么?能够给生意带来什么帮助?二是计算部分,如何只用EXCEL就可以计算RFM值并得出用户分层数据。
二、理论部分
1. RFM模型有什么用?
举例来说:某品牌经过10年的运营,拥有了500万的注册会员,这个数字是明确且可统计的。在这500万的注册会员中有400万的注册会员产生过购买行为。那么这400万产生过购买行为的会员中,有多少会员是品牌的忠诚用户?有多少会员已经流失?又有多少会员即将流失?
针对这些不同类型的用户,如何才能实现快速获取并快速定制运营方案?甚至可以直接设置自动化精准定向营销呢?
RFM模型可以给你解答这一系列的问题,只有掌握了品牌会员的不同分类以及价值,才能够有针对性地设计运营活动,从而提高最终的成交转化。
2. 什么是RFM模型?
根据美国数据库营销研究所Arthur Hughes教授的研究表明,在客户的数据库中有三个要素,这三个要素构成了分析用户价值的重要指标:
- R (Recency) : 最近一次交易时间间隔;
- F(Frequency) : 消费频率;
- M(Monetary): 消费金额。
RFM模型即是这三个单词的首字母组合。
R (Recency) : 最近一次交易时间间隔,指的是消费者最后一次成交距统计时间的间隔。
例如消费者最后一次的交易时间是2021年3月6日,统计时间是2021年4月6号,那么间隔时间R=30天,即消费者最后一次成交发生的时间距统计时间的间隔是30天。
F(Frequency) : 消费频率,指的是在统计时间段内,消费者的消费次数。
例如统计时间是2021年的1月到3月,消费者在这期间一共消费了5次,那么正常情况下F=5。
有人可能会问:如果这5次消费行为中,有两次消费行为(两笔订单)发生在很短的时间内,例如10分钟以内,那么F=5还是F=4更合理呢?
笔者认为这需要根据公司的具体业务形态拟定。我们在定义F值的时候之所以会有这样的顾虑是因为通常情况下,我们把消费者在很短时间内多次下单的行为看做是一次消费行为,消费者拆单可能是为了凑满减满赠等。
回到问题的本源:我们统计F这个指标主要是为了衡量消费者的活跃性,哪种方式更能够代表行业特征或公司业务形态就采用哪种方式。当然业务特殊(例如生鲜外卖)或是为了统计方便,也可以直接把F=消费次数,不考虑消费时间间隔极短的情况。
M(Monetary): 消费金额,指的是在统计时间段内,消费者的累计消费金额。
在其他条件相同的情况下,R/F/M值具备如下特征:
- R值越小,用户价值越高,1年前在本店消费过的用户,价值肯定没有1天前在本店消费过的客户价值高。
- F值越大,用户越活跃且忠诚,也就是说经常购买的用户肯定比偶尔购买的用户价值要高。
- M值越大,用户价值越高。M值体现的是用户的购买力,购买力越高的用户价值自然也越大。
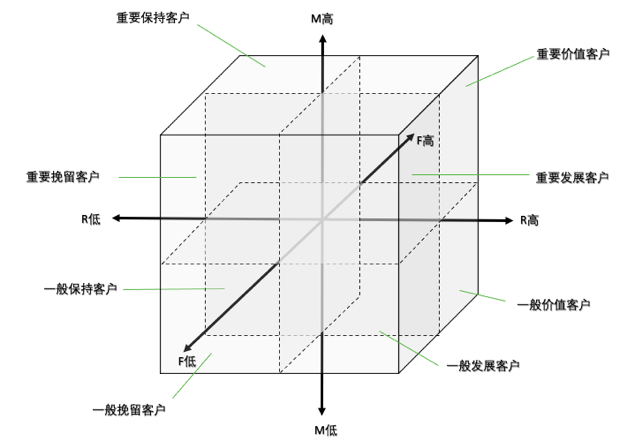
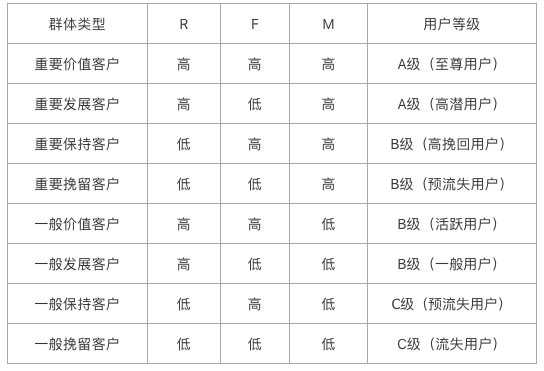
我们基于RFM三个值,可以构建出一个三维的坐标体系,把用户分成8个层级,如下图所示:
用表格的形式展现更便于理解:
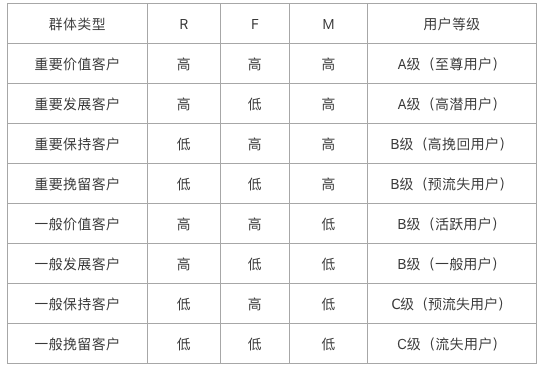
整理成这样的形式就比较好理解了,我们把所有的用户,从RFM三个维度切分成了8种不同的类型。
3. RFM模型的应用场景
简单举几个例子来说明不同类型的用户,运营策略的不同。
1)针对【重要价值客户】
即RFM值均高的用户,我们通常称之为“至尊用户”,也是整个品牌用户群体中金字塔顶端的那一拨人,购买频率高,金额贡献高,而且频繁光顾店铺。
针对这波用户,运营的主要策略是:保持稳定增长,“至尊用户”的数量不要出现流失,并且能够不断从下层用户中往上输送新的“至尊用户”。很多公司都会针对这波用户出具一些特殊的权益,例如专属服务或“专属生日礼盒”等。
2)针对【重要挽留用户】
即很久没有进行复购,但之前的购物金额以及购物频率都很高的用户,如果放任不管,这波用户很可能随着时间的流逝而流失。
运营的主要策略是复购,可通过发放专属权益、针对性折扣、赠品等一系列的定向优惠形式使得这波用户重新光临店铺,对比拉新的成本,重新让这波用户再次回购的成本要低的多了。
3)针对【一般价值客户】
即RF值高但是M值小的用户,比较活跃但是成交金额比较低的用户。一般这类用户我们会称之为活跃用户,而且价格敏感型居多。
运营的主要策略是针对这波用户提高他们的客单价,可以通过定向搭配购、加钱换购等形式不断提高该波用户的客单价,商品购物篮推荐也是非常有用的。
这些运营策略仅供抛砖引玉,不同公司业务模式不同,因此在定义【用户等级】以及主要的运营策略过程中,需要根据业务的实际情况进行拟定,不可直接照搬。
三、如何构建RFM模型?
“道理我懂了,关键是怎么落地呢?”作为一名运营,尤其是公司有专业的数据分析团队以及CRM团队的运营来说,一般情况下,知道用户分层定义的逻辑就可以了。
日常工作中,运营做的更多的是,知道本公司的用户是如何分类的,每一种类型的定义是什么?针对不同的人群应该出具何种运营策略,这些运营策略实施的效果如何?并且如何不断优化运营策略……更多的重心是放在数据的应用上,对于模型的构建以及算法的应用,知道的不多。
而且通常情况下,一家公司的会员模型构建完成后,在相当长的一段时间内不会有任何的调整(除非业务模式发生变化)。
那么问题来了。
公司规模比较小或者项目初期,公司没有CRM部门、没有数据分析部门,很多工作需要运营去张罗的时候,如何能够利用RFM模型对现有人群做分层管理呢?
不懂算法、不会Python、不会SQL、统计学也不太好的情况下,只是利用Excel,如何能够把手头上已有的用户人群来进行分层打标签呢?
这里和大家分享两种只用EXCEL就可以计算的方法。
1. 数据源准备
在开始之前我们需要准备好分析用的源始数据 。
我们能够方便获得的是店铺在一定时间内的交易数据,包含:用户名、订单编号、订单金额、订单时间等字段的数据。我们利用交易数据可以提取到我们需要的RFM数据,利用简单的IF函数和数据透视表就可以实现了。
因为Excel表格太大拖不动的缘故,我选择了网站2018年-2020年,2年的交易数据,对他们进行处理后得到如下数据:
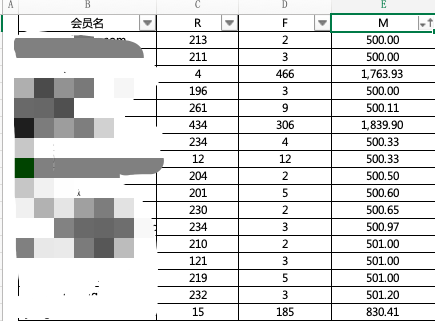
对会员ID做了模糊化处理,一共得到19万条的用户数据,分别知道每一个会员的RFM对应的值是多少。
2. 数据计算方法
在我们知道每一名用户对应的R/F/M值以后,我们需要知道RFM三个数值分别是多少才算是高 or 低?
1)方法一:四分位数法
① 四分位数理论
四分位数是统计学分位数中的一种,把所有数值从低到高(或者从高到底)排列并分成四等份,处于三个分割点位置的数值就是四分位数。
一般表示为:
- Q1:样本排列中处于25%位置的数字;
- Q2:又称为中位数,指的是样本排列中处于50%位置,即中间位置的数据;
- Q3:样本排列中处于75%位置的数字。
假设样本数据项数一共是N:
- 则Q1的位置数值=(N+1)/4;
- Q2的位置数值=(N+1)/2;
- Q3的位置数值=3(N+1)/4。
如果(N+1)恰好是4的倍数,则确定四分位数比较简单,如果不是4的倍数,相关位置的四分位数就应该是相邻两个数值的标志值的平均数。
权数的大小取决于两个数值距离的远近,距离越近权数越大,距离越远,权数越小,权数之和等于1。
例如一组样本数据如下所示:
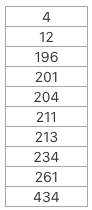
N=10,则Q1的位置=11/4=2.75(12和196两个数值);Q2的位置=5.5;Q3的位置=8.25。
则有:
- Q1=0.25*第2项+0.75*第3项=0.25*12+0.75*196=150;
- Q2=0.5*第5项+0.5*第6项=0.5*204+0.5*211=207.5;
- Q3=0.75*第8项+0.25*第9项=0.75*234+0.25*261=240.75。
在对应到RFM值的时候,我们可以定义为50%位置以下的数据值为【低】,即小于207.5的数值为低,50%位置以上的数据值为【高】,即大于207.5的数值为高。
也可以定义为75%位置以下的数据值为【低】,即小于240.75的数值为低,75%位置以上的数据值为【高】,即大于240.75的数值为高。
笔者的一般做法是:这两种划分位置都算一下,最后看结果,根据二八原则来确定选择哪一种高低分类更合理。
② 四分位数的应用
笔者直接按照“75%位置以下的数据值算低,75%以上的数据值算高”的方式来分别计算RFM三个数值的高低。
先算【R】值,因为R值越小越好,所以R值我们这边先按【倒序】排列,如此可得:
- N=1096,Q3的位置=3(N+1)/4=822.75;
- Q3=0.75*第822项+0.25*第823项=0.75*274+0.25*273=273.75。
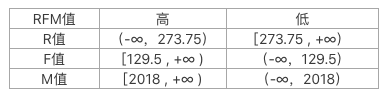
所以,R值≥273.75的值定性为低,R值<273.75的值定性为高,即距离统计时间越短的用户,价值越高。
计算【F】值:
- N=158,Q3的位置=3(N+1)/4=119.25;
- Q3=0.75*第119项+0.25*第120项=0.75*129+0.25*131=129.5。
所以,F值≥129.5的值定性为高,F值<129.5的值定性为低。
计算【M】值:
N=26387,Q3的位置=3(N+1)/4=19791,恰好是4的倍数,故Q3=第19791项=2018。所以M值≥2018的值定性为高,M值<2018的值定性为低。
三个数值都计算好之后,整理如下:
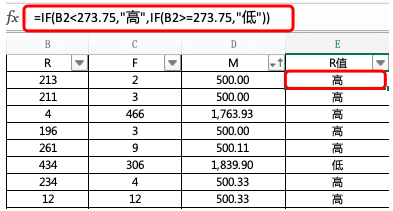
如此,我们通过简单的IF函数就可以计算出每一名用户R值的属性了,如下图所示:
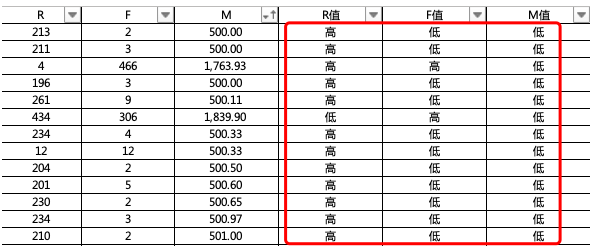
按照相同的方式为F值和M值作出高低定义,结果如下:
然后我们根据如下表格,对所有的用户进行分层:
就可以得到各个用户的标签了,如下图所示:

2)方法二:评分法
评分法就是先将RFM的价值按照从低到高划分为1-5分,然后对每一个RFM的值进行打分,这样每一个RFM值都在1-5分之间,然后分再分别算出RFM三个数值各自的平均值,高于平均值的定性为“高”,反之定性为“低”。
我们用同样的一组数据来实操给大家看一下。
我们先给RFM三个数值进行打分,结合业务的具体特点,笔者做出如下定义:
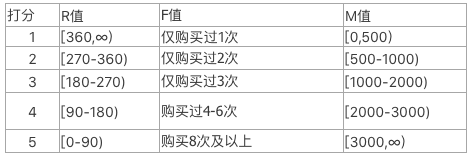
有人会问了,我怎么知道小于90天的就是5分呢?
这里推荐三种方式:
- 经验法,根据自己对业务所积累的经验来进行划分,当然也可以参考行业的常规定义;
- 将数据进行5等分,分成5个区间块,每一个区间范围分别从高到低进行打分;
- 有点复杂,举例来说:要算F值的划分,可以利用数据透视知道不同的购买次数对应的会员人数是多少?然后对购买次数进行分组,看会员数的占比情况,不断调整分组步长来进行划分。也就是说统计历史数据,看F值对应的会员人数占比分别是多少(F=2的在历史数据中的会员人数占比)?掌握F的数据分布情况后再进行打分。
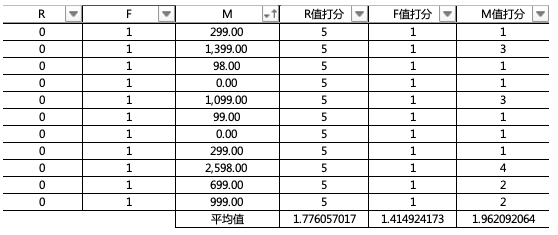
根据上表,我们对RFM三个数值分别进行打分,同样用的是IF公式,我们将会得到如下表格:

然后分别算出R值的平均值是1.78,F值的平均值是1.41,M值的平均值是1.96。
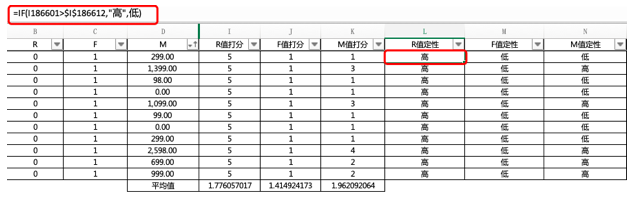
如果某一用户的R值大于整列的平均值,则定性为“高”,如果低于平均值,则定性为“低”,如下图所示:
之后的步骤就同方式一所介绍的一样了,根据RFM值高低的不同,将所有的用户分成8个类型即可。
这里介绍的两种方法是只要通过EXCEL的形式就可以计算出来的,针对规模较小,或者是没有数据分析部的公司。
而一般情况下,构建RFM模型常用的是K-means聚类算法来进行人群RFM值的定义与划分,但是K-means对于运营人员来说有些吃力了,多是数据分析工程师具备的技能了。
还是那句老话,运营通常情况下,会用就可以了,当然如果能知道这个模型的计算逻辑就更好了。
分享结束,欢迎交流~~~
本文由 @Trinity 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于 CC0 协议










你好,四分位计算那里不太懂,Q3=0.75*第822项+0.25*第823项,为啥是0.75和0.25呢?
“看F值对应的会员人数占比分别是多少(F=2的在历史数据中的会员人数占比)?掌握F的数据分布情况后再进行打分。” 这里能否再讲讲,知道了F的数据分布,在打分时应该按照什么方法打分呢? 非常感谢(*^▽^*)!
供应商关系管理 又有什么 用户价值模型可以参考。有研究嘛
自己的工作没有涉及到供应商管理,所以完全没有研究呢,抱歉~~
感谢lz,请教个问题:四分位数法里的rfm各自的样本量n为啥不一样呢?
我是去重来统计的,例如一组R值可能是:1,1,1,1,2,3,3,6,30,60这样,然后我对于重复的数值是做了去重处理的,看的是每一个RFM去重之后的值的分布情况;因为如果不去重的话,划分出来的区间数据会大量向重复数值倾斜,尤其是M值。不知道这样文字表述是否能明白?
理解了!感谢lz分享,受益匪浅!